Recognition: 3 theorem links
· Lean TheoremDecocted Experience Improves Test-Time Inference in LLM Agents
Pith reviewed 2026-05-10 19:45 UTC · model grok-4.3
The pith
Decocted experience, by distilling past interactions into coherent context, improves LLM agent performance at test time without extra compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Effective context construction for experience-augmented LLM agents critically depends on decocted experience: extracting essence from experience, organizing it coherently, and retrieving salient information to build effective context. The paper studies how to derive context from experience, how performance scales with accumulated experience, what characterizes good context, and which data structures best support context construction, validating the approach across reasoning and agentic tasks including math reasoning, web browsing, and software engineering.
What carries the argument
Decocted experience, the process of extracting the essence from accumulated experience, organizing it coherently, and retrieving salient information to construct effective context for guiding the model's reasoning.
If this is right
- LLM agents achieve higher performance when context is built from decocted experience instead of raw accumulated logs.
- Performance improves as more experience is accumulated provided it is decocted into coherent, retrievable form.
- Data structures that enable coherent organization and salient retrieval are required for effective context construction.
- The benefits appear on mathematical reasoning, web browsing, and software engineering tasks.
- Context construction serves as a complementary scaling axis to increased test-time computation.
Where Pith is reading between the lines
- Agent designs may benefit from dedicated modules that automatically distill raw interaction history before storage.
- The emphasis on distillation over volume suggests similar processing could help in-context learning with long histories.
- Retrieval-augmented systems could see gains by applying decocting to their external knowledge stores before use.
Load-bearing premise
The observed performance gains come specifically from the decocted form of the experience rather than from total experience volume, retrieval method, or task-specific prompt engineering.
What would settle it
An experiment that keeps experience volume, retrieval method, and prompts fixed but replaces decocted experience with raw unprocessed logs and finds no performance difference on math reasoning, web browsing, or software engineering tasks.
Figures









read the original abstract
There is growing interest in improving LLMs without updating model parameters. One well-established direction is test-time scaling, where increased inference-time computation (e.g., longer reasoning, sampling, or search) is used to improve performance. However, for complex reasoning and agentic tasks, naively scaling test-time compute can substantially increase cost and still lead to wasted budget on suboptimal exploration. In this paper, we explore \emph{context} as a complementary scaling axis for improving LLM performance, and systematically study how to construct better inputs that guide reasoning through \emph{experience}. We show that effective context construction critically depends on \emph{decocted experience}. We present a detailed analysis of experience-augmented agents, studying how to derive context from experience, how performance scales with accumulated experience, what characterizes good context, and which data structures best support context construction. We identify \emph{decocted experience} as a key mechanism for effective context construction: extracting essence from experience, organizing it coherently, and retrieving salient information to build effective context. We validate our findings across reasoning and agentic tasks, including math reasoning, web browsing, and software engineering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that effective context construction for LLM agents depends critically on 'decocted experience'—extracting essence from experience, organizing it coherently, and retrieving salient information. The authors analyze experience-augmented agents by studying context derivation from experience, how performance scales with accumulated experience, what characterizes good context, and which data structures best support context construction. They position context as a complementary scaling axis to test-time compute and validate the findings across math reasoning, web browsing, and software engineering tasks.
Significance. If the empirical results hold after addressing controls, the work could be significant for LLM agent research by identifying a mechanism for leveraging experience to improve inference efficiency without parameter updates or naive compute scaling. The multi-domain validation and focus on context construction mechanisms provide a foundation for more principled agent design and could influence future work on experience management in AI systems.
major comments (2)
- Abstract: The abstract asserts validation across math reasoning, web browsing, and software engineering tasks but supplies no details on baselines, metrics, statistical tests, or experimental controls, preventing assessment of whether the data supports the central claim.
- Experiments section: The central claim requires that performance gains are specifically attributable to the decocted form of experience (essence extraction + coherent organization + salient retrieval) rather than confounds such as total experience volume (token count), retrieval method, or task-specific prompt engineering. No ablations or matched baselines isolating these factors are described.
minor comments (2)
- Introduction: The neologism 'decocted experience' would benefit from an explicit early definition or etymological note to aid reader comprehension.
- Related work: Consider citing prior literature on context compression in LLMs and experience replay mechanisms in agentic RL to better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the clarity and rigor of our claims. We address each major comment below and have prepared revisions to the manuscript.
read point-by-point responses
-
Referee: Abstract: The abstract asserts validation across math reasoning, web browsing, and software engineering tasks but supplies no details on baselines, metrics, statistical tests, or experimental controls, preventing assessment of whether the data supports the central claim.
Authors: We agree that the abstract would benefit from greater specificity to help readers evaluate the claims at a glance. In the revised version, we have expanded the abstract to reference the main baselines (standard ReAct-style agents and raw experience accumulation), primary metrics (task success rate and inference efficiency), and note that results are reported as averages over multiple runs with statistical details provided in the Experiments section. Space constraints limit full enumeration of controls in the abstract, but these are now explicitly summarized there. revision: yes
-
Referee: Experiments section: The central claim requires that performance gains are specifically attributable to the decocted form of experience (essence extraction + coherent organization + salient retrieval) rather than confounds such as total experience volume (token count), retrieval method, or task-specific prompt engineering. No ablations or matched baselines isolating these factors are described.
Authors: We acknowledge this point and the need for tighter isolation of the decocted experience mechanism. While the original experiments include comparisons to raw experience and alternative context formats, they did not fully control for matched token budgets or systematically vary retrieval methods across domains. We have conducted additional ablation studies that (i) truncate experience to equal token lengths, (ii) compare semantic, keyword, and random retrieval under fixed budgets, and (iii) hold prompt engineering constant. These results, which support the specific contribution of decocting, will be added to the Experiments section with corresponding tables and analysis in the revision. revision: yes
Circularity Check
No significant circularity: empirical analysis without derivations or self-referential reductions
full rationale
The paper is an empirical study of experience-augmented LLM agents that identifies 'decocted experience' via analysis of how context is derived from experience, performance scaling, and validation across math, web, and SE tasks. No equations, parameters, or derivation chains appear that reduce by construction to inputs; claims rest on experimental observations rather than self-definition, fitted predictions, or self-citation load-bearing steps. The work is self-contained against external benchmarks with no circularity.
Axiom & Free-Parameter Ledger
invented entities (1)
-
decocted experience
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe identify decocted experience as a key mechanism for effective context construction: extracting essence from experience, organizing it coherently, and retrieving salient information to build effective context.
-
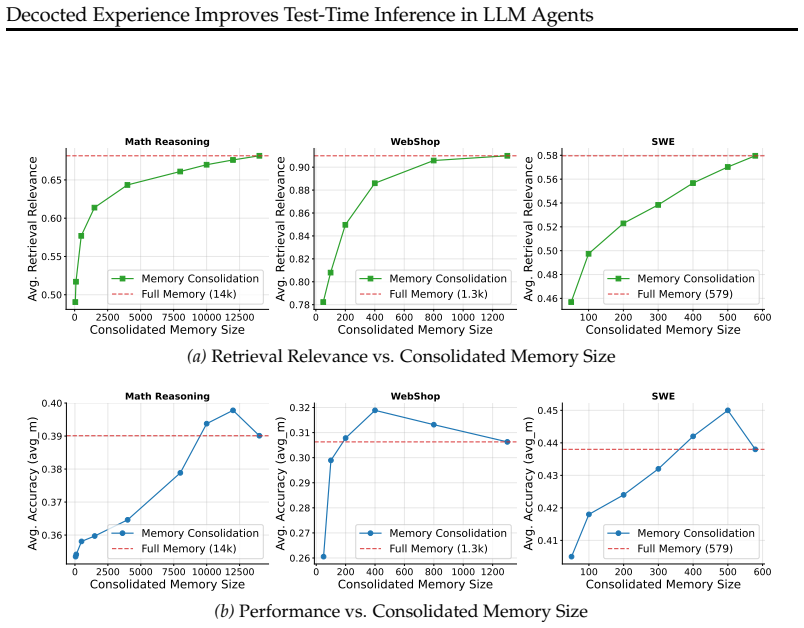
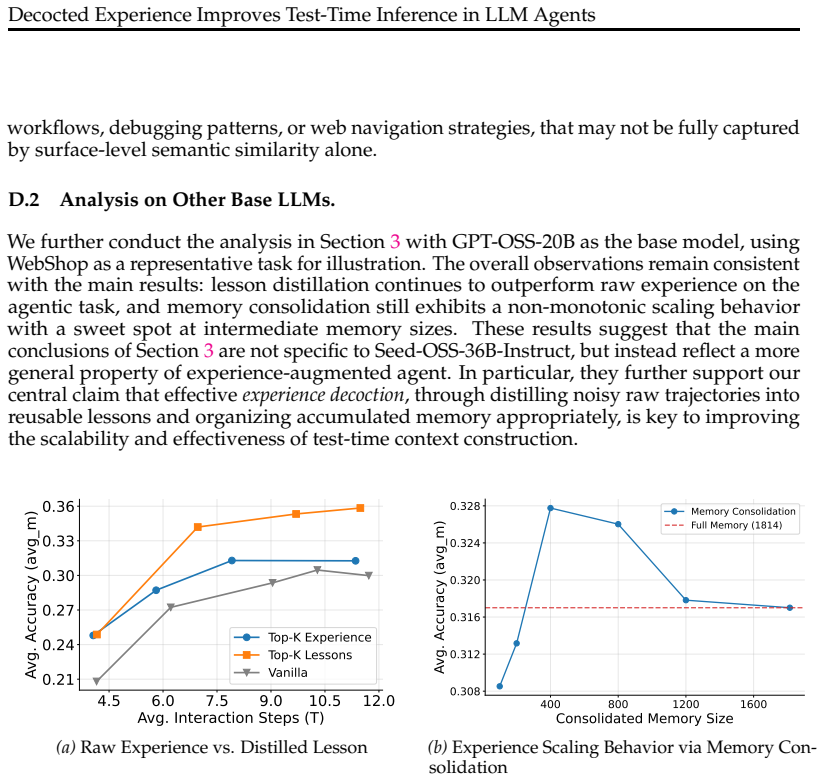
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclearMemory consolidation exhibits a sweet spot at intermediate memory sizes... relevance–diversity tradeoff
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearProposition 4.1 (Context Efficiency Bound)... E[τ|X=x,C=c] ≤ H(Y|X=x) - I(Y;C=c|X=x) / h
Forward citations
Cited by 1 Pith paper
-
SkillOS: Learning Skill Curation for Self-Evolving Agents
SkillOS is an RL recipe that learns to curate reusable skills for self-evolving LLM agents, outperforming memory-free and memory-based baselines while generalizing across executors and domains.
Reference graph
Works this paper leans on
-
[1]
15 Alireza Rezazadeh, Zichao Li, Wei Wei, and Yujia Bao. From isolated conversations to hierarchical schemas: Dynamic tree memory representation for llms.arXiv preprint arXiv:2410.14052, 2024. 15 Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. A systematic survey of prompt engineering in large language models: ...
-
[2]
arXiv preprint arXiv:2507.07957 , year=
2, 16 Yu Wang and Xi Chen. MIRIX: Multi-agent memory system for LLM-based agents.arXiv preprint arXiv:2507.07957, 2025. 15 Yu Wang, Ryuichi Takanobu, Zhiqi Liang, Yuzhen Mao, Yuanzhe Hu, Julian McAuley, and Xiaojian Wu. Mem-α: Learning memory construction via reinforcement learning.arXiv preprint arXiv:2509.25911, 2025. 15 Zora Zhiruo Wang, Jiayuan Mao, D...
-
[3]
2, 15, 16 Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models. InAdvances in Neural Information Processing Systems, 2024. 1 Zhiheng Xi, Yiwen Ding, Wenxiang Chen, Boyang Hong, Honglin Guo, Junzhe Wang, Dingwen Yang, Chenyang ...
work page internal anchor Pith review arXiv 2024
-
[4]
arXiv preprint arXiv:2507.02259 , year=
17 Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdi- nov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pp. 2369–2380, 2018. 15 Shunyu Yao, Howard Chen, John Yang, and Karthi...
-
[5]
1 Guibin Zhang, Muxin Fu, and Shuicheng Yan. Memgen: Weaving generative latent memory for self-evolving agents.arXiv preprint arXiv:2509.24704, 2025a. 15 Kai Zhang, Xiangchao Chen, Bo Liu, et al. Agent learning via early experience.arXiv preprint arXiv:2510.08558, 2025b. 16 Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar K...
-
[6]
A more recent line of work seeks to train LLMs tolearnmemory management
builds a multi-agent controller that routes across specialized memory types such as episodic, semantic, and procedural memory. A more recent line of work seeks to train LLMs tolearnmemory management. MemGen (Zhang et al., 2025a) interleaves reasoning with generated latent memory, whereas Mem-α (Wang et al., 2025), MemAgent (Yu et al., 2025a), and Memory-R...
2025
-
[7]
Task Description: A one-two sentence summary of the type of problems this strategy applies to
-
[8]
Strategy: A step-by-step detailed problem-solving strategy that could consist of various different ways to tackle similar problems
-
[9]
# Important: The strategy should be extremely detailed, covering multiple different ways to solve the problem
Pitfalls: Common mistakes or misconceptions to avoid when solving this type of problems (if applicable). # Important: The strategy should be extremely detailed, covering multiple different ways to solve the problem. Prompt Template: Lesson Distillation (WebShop) You are a shopping strategy synthesizer analyzing past web shopping attempts. Review the shopp...
-
[10]
Task Description: A one-two sentence summary of the type of shopping task this strategy applies to
-
[11]
Action Workflow: A step-by-step detailed problem-solving strategy to complete the purchase, including step-level actions and the summarization of the observations at each step
-
[12]
Pitfalls: Common mistakes or pitfalls to avoid when solving this type of shopping task (if applicable). 19 Decocted Experience Improves Test-Time Inference in LLM Agents # Important: The workflow should include clear action steps (e.g., CLICK, TYPE, SELECT) and observations at each step. Prompt Template: Lesson Distillation (SWE) You are a debugging strat...
-
[13]
Task Description: One-two sentence summary of the issue type and code base area
-
[14]
Strategy: Step-by-step detailed agent workflow structured as an action sequence (followed by successful attempts)
-
[15]
number theory
Pitfalls: Common mistakes to avoid. If a failed attempt is available, explain the specific wrong turn and how to avoid it. # Important: The workflow should include clear action steps and observations at each step. Prompt Template: Experience-based Inference You are an expert at solving complex reasoning problems, while leveraging few-shot experience. You ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.