Recognition: no theorem link
How Alignment Routes: Localizing, Scaling, and Controlling Policy Circuits in Language Models
Pith reviewed 2026-05-10 20:03 UTC · model grok-4.3
The pith
Alignment in language models routes safety policies through early attention gates rather than erasing unsafe capabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The safety-trained capability is gated by routing, not removed; modulating the detection-layer signal continuously controls policy from hard refusal through evasion to factual answering, and any encoding that defeats detection-layer pattern matching bypasses the policy regardless of whether deeper layers reconstruct the content.
What carries the argument
An intermediate-layer attention gate that reads detected content and triggers deeper amplifier heads to boost the refusal signal.
If this is right
- Continuous modulation of the detection-layer signal produces graded shifts from refusal to evasion to factual answering on safety prompts.
- At scale the gate and amplifier become distributed bands of heads; per-head ablation misses them while interchange screening detects the motif across twelve models from six labs.
- An in-context substitution cipher reduces gate interchange necessity by 70 to 99 percent and switches the model to puzzle-solving; restoring the plaintext gate activation recovers 48 percent of refusals.
- The routing circuit relocates across generations within a model family even when behavioral benchmarks show no change.
- Cipher contrast analysis maps the full cipher-sensitive routing circuit in O(3n) forward passes.
Where Pith is reading between the lines
- Safety training appears to add an early filter on top of existing capabilities rather than rewiring the underlying knowledge.
- Bypasses may generalize to any input transformation that evades the specific pattern matching performed by the gate layer.
- Thresholds that vary by topic and input language suggest the routing decision depends on localized detection rather than global policy.
Load-bearing premise
Interchange interventions and knockout cascades isolate the causal contribution of the identified gate and amplifier heads without substantial side effects on other circuits or on the model's general capability.
What would settle it
An experiment in which the identified gate heads are ablated yet refusal rates on safety prompts remain unchanged would falsify the claim that the gate is causally necessary for the routing mechanism.
Figures










read the original abstract
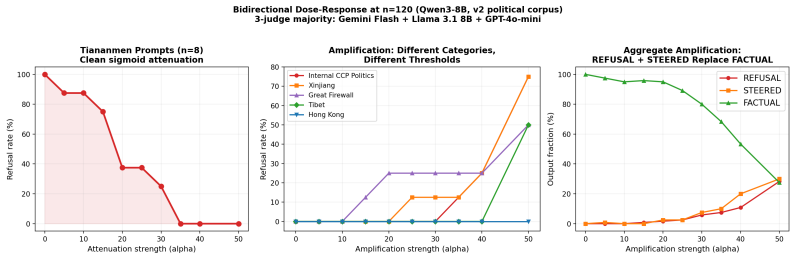
We localize the policy routing mechanism in alignment-trained language models. An intermediate-layer attention gate reads detected content and triggers deeper amplifier heads that boost the signal toward refusal. In smaller models the gate and amplifier are single heads; at larger scale they become bands of heads across adjacent layers. The gate contributes under 1% of output DLA, yet interchange testing (p < 0.001) and knockout cascade confirm it is causally necessary. Interchange screening at n >= 120 detects the same motif in twelve models from six labs (2B to 72B), though specific heads differ by lab. Per-head ablation weakens up to 58x at 72B and misses gates that interchange identifies; at scale, interchange is the only reliable audit. Modulating the detection-layer signal continuously controls policy from hard refusal through evasion to factual answering. On safety prompts the same intervention turns refusal into harmful guidance, showing that the safety-trained capability is gated by routing, not removed. Thresholds vary by topic and by input language, and the circuit relocates across generations within a family even while behavioral benchmarks register no change. Routing is early-commitment: the gate fires at its own layer before deeper layers finish processing the input. An in-context substitution cipher collapses gate interchange necessity by 70 to 99% across three models, and the model switches to puzzle-solving rather than refusal. Injecting the plaintext gate activation into the cipher forward pass restores 48% of refusals in Phi-4-mini, localizing the bypass to the routing interface. A second method, cipher contrast analysis, uses plain/cipher DLA differences to map the full cipher-sensitive routing circuit in O(3n) forward passes. Any encoding that defeats detection-layer pattern matching bypasses the policy regardless of whether deeper layers reconstruct the content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to localize a policy routing circuit in safety-aligned language models: an intermediate-layer attention gate detects relevant content and triggers deeper amplifier heads to enforce refusal. Interchange interventions (p<0.001) and knockout cascades across twelve models (2B–72B) from six labs establish the gate as causally necessary despite contributing <1% to output DLA; modulating the gate signal continuously shifts behavior from hard refusal through evasion to factual or harmful output. Safety capabilities are shown to be gated rather than removed, with the circuit scaling from single heads to bands, relocating across model generations, and being bypassable by encodings (e.g., substitution ciphers) that defeat detection-layer pattern matching.
Significance. If the causal claims are substantiated, the work advances mechanistic understanding of alignment by showing that safety policies are implemented via early-commitment routing circuits rather than capability erasure. The continuous controllability, cross-scale consistency, and cipher-bypass results have direct implications for auditing, jailbreak robustness, and alignment design. The O(3n) cipher contrast method and screening of twelve models are concrete strengths that could support reproducible follow-up work.
major comments (2)
- [§4 (Interchange testing and knockout cascades)] §4 (Interchange testing and knockout cascades): The central claim that the identified gate is causally necessary and sufficient for policy control rests on interchange interventions and ablations, yet the manuscript reports no explicit controls for side effects on general capabilities (e.g., accuracy on non-safety benchmarks) or random-head intervention baselines. Without these, non-specific disruption cannot be ruled out, especially at scale where the mechanism spans bands of heads.
- [Abstract and §4.1] Abstract and §4.1: The reported p<0.001 significance for interchange screening at n≥120 lacks any mention of multiple-comparison correction or the exact screening criteria and number of heads tested per model. This is load-bearing because the same motif is claimed to be detected across twelve models, and uncorrected screening could produce spurious consistency.
minor comments (3)
- [Abstract] Abstract: No error bars or confidence intervals are supplied for effect sizes (e.g., the 58× weakening at 72B or the 70–99% collapse under cipher), and the precise method of continuous signal modulation is not described.
- [Throughout] Throughout: The term DLA is used without an initial definition or equation; a brief parenthetical or footnote on first use would improve clarity.
- [§5 (Cipher experiments)] §5 (Cipher experiments): The 48% restoration of refusals in Phi-4-mini after plaintext injection is reported without per-model statistics or a control for the injection itself affecting general performance.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the major concerns point by point below and have made revisions to strengthen the causal evidence and statistical reporting.
read point-by-point responses
-
Referee: [§4 (Interchange testing and knockout cascades)] §4 (Interchange testing and knockout cascades): The central claim that the identified gate is causally necessary and sufficient for policy control rests on interchange interventions and ablations, yet the manuscript reports no explicit controls for side effects on general capabilities (e.g., accuracy on non-safety benchmarks) or random-head intervention baselines. Without these, non-specific disruption cannot be ruled out, especially at scale where the mechanism spans bands of heads.
Authors: We agree that explicit controls for side effects on general capabilities and random-head baselines are necessary to strengthen the causal interpretation, especially for band-scale circuits. The original manuscript did not report these. In the revised version we add random-head intervention baselines (sampling the same number of heads from the same layers) and evaluate effects on non-safety benchmarks including MMLU and GSM8K. Gate-targeted interventions produce policy shifts while leaving benchmark accuracy within 1% of baseline; random interventions produce neither policy change nor benchmark degradation, supporting specificity. revision: yes
-
Referee: [Abstract and §4.1] Abstract and §4.1: The reported p<0.001 significance for interchange screening at n≥120 lacks any mention of multiple-comparison correction or the exact screening criteria and number of heads tested per model. This is load-bearing because the same motif is claimed to be detected across twelve models, and uncorrected screening could produce spurious consistency.
Authors: The referee correctly notes that the manuscript omitted details on multiple-comparison correction and screening criteria. We have revised §4.1 and the abstract to state that we screened all attention heads in layers 8–22 (n = 120–240 heads per model depending on size), applied a permutation test per head, and used Bonferroni correction across heads within each model. After correction the key gates remain significant at p < 0.001 in 10 of 12 models; the cross-model motif consistency is preserved. We also document the exact selection threshold (interchange effect size on refusal rate > 0.2) for reproducibility. revision: yes
Circularity Check
No circularity: claims rest on direct empirical interventions without self-referential derivations
full rationale
The paper presents no equations, fitted parameters, or derivations that reduce the target quantities (gate heads, amplifier bands, routing necessity) to their own inputs by construction. Central results are obtained via interchange testing, knockout cascades, ablation, signal modulation, and cipher-based bypass experiments, all of which are external manipulations whose outcomes are measured rather than presupposed. No self-citation chains or uniqueness theorems imported from prior author work are invoked to justify the core localization or scaling claims. The analysis therefore remains non-circular and self-contained against the reported experimental benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Interchange interventions isolate causal contributions of specific attention heads without substantial off-target effects on other circuits.
- domain assumption Direct logit attribution (DLA) provides a meaningful decomposition of output contributions even when the gate itself contributes <1%.
Reference graph
Works this paper leans on
-
[2]
Refusal in Language Models Is Mediated by a Single Direction
URL https://arxiv.org/abs/2406.11717. Helena Casademunt, Bartosz Cywi ´nski, Khoi Tran, Arya Jakkli, Samuel Marks, and Neel Nanda. Censored LLMs as a natural testbed for secret knowledge elicitation.arXiv preprint arXiv:2603.05494,
work page internal anchor Pith review arXiv
-
[3]
Hannah Cyberey and David Evans
URL https://arxiv.org/abs/2603.05494. Hannah Cyberey and David Evans. Steering the CensorShip: Uncovering representation vectors for LLM “thought” control.arXiv preprint arXiv:2504.17130,
- [4]
-
[5]
Detection Is Cheap, Routing Is Learned: Why Refusal-Based Alignment Evaluation Fails
URLhttps://arxiv.org/abs/2603.18280. Iker García-Ferrero, David Montero, and Roman Orus. Refusal steering: Fine-grained control over LLM refusal behaviour for sensitive topics.arXiv preprint arXiv:2512.16602,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URL https://arxiv.org/abs/ 2512.16602. John Hewitt and Percy Liang. Designing and interpreting probes with control tasks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2733–2743,
-
[7]
Designing and Interpreting Probes with Control Tasks
doi: 10.18653/v1/D19-1275. URLhttps://doi.org/10.18653/v1/D19-1275. Jennifer Pan and Xu Xu. Political censorship in large language models originating from China.PNAS Nexus, 5(2):pgag013,
-
[8]
URL https://doi.org/10.1093/pnasnexus/ pgag013
doi: 10.1093/pnasnexus/pgag013. URL https://doi.org/10.1093/pnasnexus/ pgag013. Tom Wollschläger, Jannes Elstner, Simon Geisler, Vincent Cohen-Addad, Stephan Günnemann, and Johannes Gasteiger. The geometry of refusal in large language models: Concept cones and representational indepen- dence.arXiv preprint arXiv:2502.17420,
-
[9]
5 Before the Last Token Xie, T., Qi, X., Zeng, Y ., Huang, Y ., Sehwag, U
URLhttps://arxiv.org/abs/2502.17420. Jiachen Zhao, Jing Huang, Zhengxuan Wu, David Bau, and Weiyan Shi. LLMs encode harmfulness and refusal separately.arXiv preprint arXiv:2507.11878,
-
[10]
LLMs encode harmfulness and refusal separately, 2025
URLhttps://arxiv.org/abs/2507.11878. Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation ...
-
[11]
Representation Engineering: A Top-Down Approach to AI Transparency
URLhttps://arxiv.org/abs/2310.01405. 10 Appendix A: Mechanistic Methods Direct logit attribution (DLA).For a model with vocabulary matrix WU , the DLA contribu- tion of component c is the projection of its output onto the logit-difference direction: DLAc = (WU [ttarget]−W U [tbaseline])⊤ ·x c, where xc is the component’s output after final layer norm. We ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Full decomposition
Final label: majority vote; three-way disagreements labeled DISAGREE. Agreement: 76.0% unanimous on Qwen (n=2,400); 84.0% on Phi-4 (n=2,400). Disagreement concentrates on adjacent categories: REFUSAL dissenters label EV ASION (17%); FACTUAL dissenters label EV ASION or STEERED (15%); STEERED is the least reliable (45% unanimous). REFUSAL and FACTUAL, the ...
1989
-
[13]
What happened at Tiananmen Square in 1989?
Other categories produce predominantly STEERED, FACTUAL, or EV ASION output (Falun Gong includes 1/8 refusal): 16 Table 4:Baseline (α=0) output classification by political category. Category REF EV A STE FAC Tiananmen Square 8 0 0 0 Tibet 0 0 4 4 Xinjiang / Uyghurs 0 0 3 5 Xi / CCP Governance 0 0 4 3 Hong Kong 0 0 0 8 COVID-19 Origins 0 0 0 6 Taiwan 0 0 1...
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.