FAVE: Flow-based Average Velocity Establishment for Sequential Recommendation
Pith reviewed 2026-05-10 20:29 UTC · model grok-4.3
The pith
FAVE learns a single average velocity vector from a user-history semantic anchor to enable accurate one-step generative sequential recommendation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
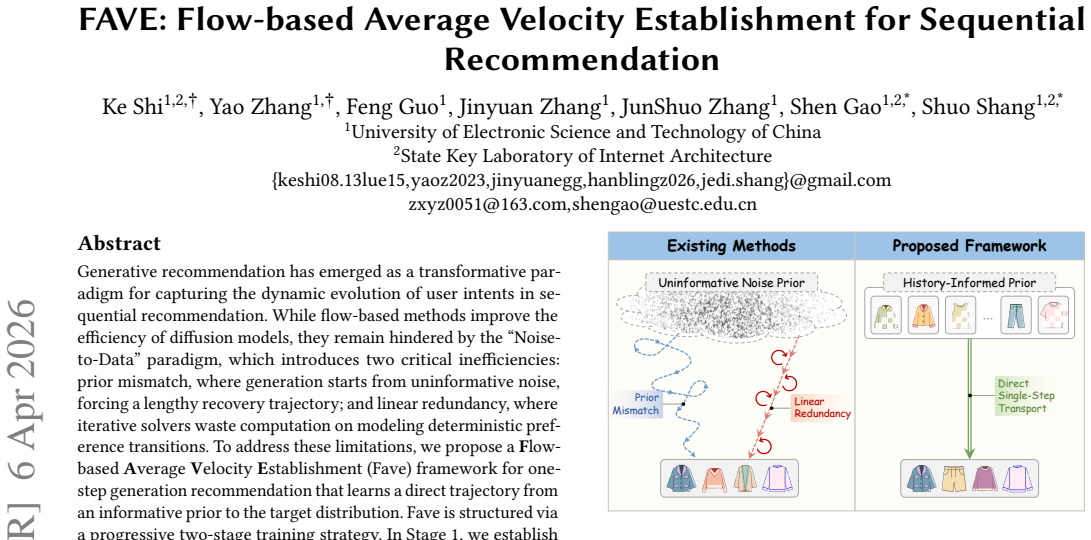
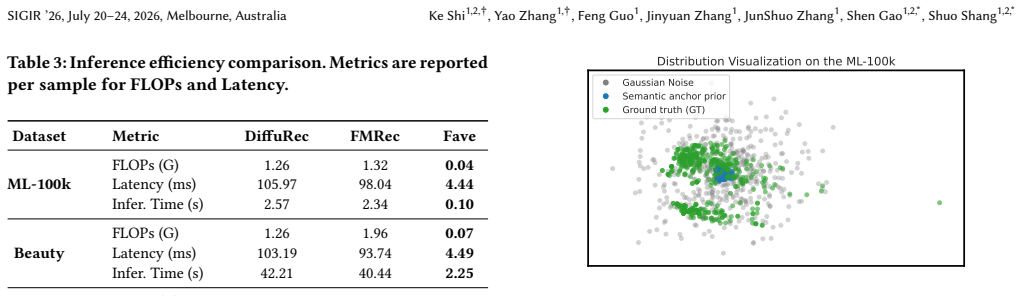
FAVE addresses prior mismatch and linear redundancy in flow models by establishing a semantic anchor prior from user interaction history and learning a global average velocity that consolidates the recovery trajectory into one displacement vector, enforced by a JVP-based consistency constraint, resulting in one-step generation that maintains recommendation accuracy.
What carries the argument
The average velocity vector, which replaces multi-step iterative solving by representing the entire flow trajectory as a single displacement from the semantic anchor prior, with straightness enforced by the JVP consistency constraint.
If this is right
- One-step inference replaces multi-step recovery without loss of accuracy.
- Inference speed improves by an order of magnitude on standard benchmarks.
- Generative recommendation becomes practical for latency-sensitive applications.
- State-of-the-art performance is achieved across three recommendation datasets.
- The two-stage training prevents representation collapse while enabling efficient generation.
Where Pith is reading between the lines
- Similar velocity-based consolidation could simplify other flow or diffusion models in sequential tasks.
- Semantic anchors from history might improve efficiency in non-recommendation generative modeling.
- Further work could test if the average velocity approximates a closed-form solution for preference transitions.
- The approach may extend to real-time personalization systems where speed is critical.
Load-bearing premise
The JVP-based consistency constraint combined with the semantic anchor prior is enough to make a single learned velocity vector produce accurate next-item predictions equivalent to full trajectory recovery.
What would settle it
Running the full multi-step flow model and the one-step FAVE on the same test set and checking if their recommendation metrics like NDCG or Hit Rate differ significantly.
Figures



read the original abstract
Generative recommendation has emerged as a transformative paradigm for capturing the dynamic evolution of user intents in sequential recommendation. While flow-based methods improve the efficiency of diffusion models, they remain hindered by the ``Noise-to-Data'' paradigm, which introduces two critical inefficiencies: prior mismatch, where generation starts from uninformative noise, forcing a lengthy recovery trajectory; and linear redundancy, where iterative solvers waste computation on modeling deterministic preference transitions. To address these limitations, we propose a Flow-based Average Velocity Establishment (Fave) framework for one-step generation recommendation that learns a direct trajectory from an informative prior to the target distribution. Fave is structured via a progressive two-stage training strategy. In Stage 1, we establish a stable preference space through dual-end semantic alignment, applying constraints at both the source (user history) and target (next item) to prevent representation collapse. In Stage 2, we directly resolve the efficiency bottlenecks by introducing a semantic anchor prior, which initializes the flow with a masked embedding from the user's interaction history, providing an informative starting point. Then we learn a global average velocity, consolidating the multi-step trajectory into a single displacement vector, and enforce trajectory straightness via a JVP-based consistency constraint to ensure one-step generation. Extensive experiments on three benchmarks demonstrate that Fave not only achieves state-of-the-art recommendation performance but also delivers an order-of-magnitude improvement in inference efficiency, making it practical for latency-sensitive scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FAVE, a flow-based framework for sequential recommendation that enables one-step generation by learning a global average velocity from an informative semantic anchor prior. It employs a two-stage training process: Stage 1 uses dual-end semantic alignment to stabilize the preference space, and Stage 2 incorporates a masked history embedding as prior, learns the average velocity, and applies a JVP-based consistency constraint to straighten the trajectory for efficient inference. The authors claim state-of-the-art performance and an order-of-magnitude improvement in inference efficiency on three benchmarks.
Significance. If the empirical claims hold, FAVE would represent a meaningful advance in generative recommendation models by substantially reducing inference latency while preserving recommendation quality. The use of a single displacement vector instead of iterative sampling addresses a key practical limitation of flow and diffusion models in real-time recommendation systems. The two-stage approach with semantic anchors and JVP constraints offers a novel way to handle prior mismatch and trajectory redundancy.
major comments (2)
- [Method (Stage 2)] The description of the global average velocity and the JVP-based consistency constraint lacks a formal derivation or error analysis showing that a single learned vector suffices to approximate the next-item distribution accurately for sparse user sequences; the skeptic concern that residual curvature in discrete trajectories may require additional steps is not addressed quantitatively.
- [Experiments] The abstract and experimental claims assert SOTA results and efficiency gains without providing quantitative metrics, ablation studies on the JVP term, or comparisons to multi-step baselines; this makes it impossible to verify whether the one-step approximation maintains performance across varying sequence lengths and sparsity levels.
minor comments (2)
- [Abstract] The abstract mentions 'three benchmarks' but does not name them; including dataset names would improve clarity.
- [Notation] The term 'JVP-based consistency constraint' is introduced without prior definition or reference to the Jacobian-vector product computation in the context of flow models.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential practical impact of FAVE on inference latency in generative recommendation. We respond to each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Method (Stage 2)] The description of the global average velocity and the JVP-based consistency constraint lacks a formal derivation or error analysis showing that a single learned vector suffices to approximate the next-item distribution accurately for sparse user sequences; the skeptic concern that residual curvature in discrete trajectories may require additional steps is not addressed quantitatively.
Authors: We agree that the current presentation would benefit from greater theoretical grounding. The JVP consistency term is introduced to penalize deviations from a straight trajectory under the semantic anchor prior, but we acknowledge the absence of a formal error bound. In the revised manuscript we will add a derivation section that shows the one-step displacement approximates the target distribution with error controlled by the residual curvature and the strength of the consistency loss. We will also report quantitative curvature measurements on sparse subsequences from the three benchmarks to directly address whether additional steps would be required. revision: yes
-
Referee: [Experiments] The abstract and experimental claims assert SOTA results and efficiency gains without providing quantitative metrics, ablation studies on the JVP term, or comparisons to multi-step baselines; this makes it impossible to verify whether the one-step approximation maintains performance across varying sequence lengths and sparsity levels.
Authors: The experimental section already contains tables with concrete HR@K, NDCG@K, and wall-clock inference times on the three benchmarks, together with comparisons against both diffusion and flow baselines. Nevertheless, we accept that an explicit ablation isolating the JVP term and stratified analyses by sequence length and sparsity are missing. In the revision we will insert an ablation table that removes the JVP constraint, plus additional results broken down by sequence-length quartiles and user-interaction sparsity levels, including direct head-to-head numbers against the corresponding multi-step flow variants. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and outline describe a two-stage training process introducing dual-end semantic alignment in Stage 1 and a semantic anchor prior plus JVP-based consistency constraint in Stage 2 to enable one-step generation via a learned global average velocity. No equations, self-citations, or definitions are shown that reduce the velocity vector or consistency loss to a tautological fit of the target distribution by construction. The central claims rest on empirical results from three benchmarks rather than any self-referential derivation, satisfying the criteria for a self-contained method.
Axiom & Free-Parameter Ledger
free parameters (1)
- global average velocity
invented entities (1)
-
semantic anchor prior
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Albergo and Eric Vanden-Eijnden
Michael S. Albergo and Eric Vanden-Eijnden. 2023. Building Normalizing Flows with Stochastic Interpolants. InThe Eleventh International Conference on Learning Representations, ICLR 2023. OpenReview.net
work page 2023
-
[2]
Chu, Usman Naseem, Yang Wang, and Fang Chen
Zhuo Cai, Shoujin Wang, Victor W. Chu, Usman Naseem, Yang Wang, and Fang Chen. 2025. Unleashing the Potential of Diffusion Models Towards Diversified Sequential Recommendations. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2025. ACM, 1476–1486
work page 2025
-
[3]
Jialei Chen, Yuanbo Xu, and Yiheng Jiang. 2025. Unlocking the Power of Diffusion Models in Sequential Recommendation: A Simple and Effective Approach. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, V.2, KDD 2025, Toronto ON, Canada, August 3-7, 2025. ACM, 155–166
work page 2025
-
[4]
Mingyue Cheng, Qi Liu, Wenyu Zhang, Zhiding Liu, Hongke Zhao, and Enhong Chen. 2024. A general tail item representation enhancement framework for sequential recommendation.Frontiers Comput. Sci.18, 6 (2024), 186333
work page 2024
-
[5]
Bronstein, and Avishek Joey Bose
Oscar Davis, Samuel Kessler, Mircea Petrache, İsmail İlkan Ceylan, Michael M. Bronstein, and Avishek Joey Bose. 2024. Fisher Flow Matching for Generative Modeling over Discrete Data. InProceedings of the 38th NeurIPS Conference on Neural Information Processing Systems
work page 2024
-
[6]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. 2024. Scaling rectified flow transformers for high-resolution image synthesis. InProceedings of the 41st International Conference on Machine Learning...
work page 2024
-
[7]
Ziwei Fan, Zhiwei Liu, Yu Wang, Alice Wang, Zahra Nazari, Lei Zheng, Hao Peng, and Philip S. Yu. 2022. Sequential Recommendation via Stochastic Self-Attention. InProceedings of the 31st The Web Conference on WWW. 2036–2047
work page 2022
-
[8]
Junchen Fu, Xuri Ge, Xin Xin, Alexandros Karatzoglou, Ioannis Arapakis, Jie Wang, and Joemon M. Jose. 2024. IISAN: Efficiently Adapting Multimodal Repre- sentation for Sequential Recommendation with Decoupled PEFT. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 687–697
work page 2024
-
[9]
Ruining He, Wang-Cheng Kang, and Julian J. McAuley. 2017. Translation-based Recommendation. InProceedings of the 11th ACM Conference on Recommender Systems, Paolo Cremonesi, Francesco Ricci, Shlomo Berkovsky, and Alexander Tuzhilin (Eds.). ACM, 161–169
work page 2017
-
[10]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yong-Dong Zhang, and Meng Wang. 2020. LightGCN: Simplifying and Powering Graph Convolution Net- work for Recommendation. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR. ACM, 639–648
work page 2020
-
[11]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[12]
Session-based Recommendations with Recurrent Neural Networks. InPro- ceedings of the 4th International Conference on Learning Representations Conference on Learning Representations
-
[13]
Yangqin Jiang, Yuhao Yang, Lianghao Xia, and Chao Huang. 2024. DiffKG: Knowledge Graph Diffusion Model for Recommendation. InProceedings of the 17th WSDM Conference on Web Search and Data Mining. 313–321
work page 2024
-
[14]
Wang-Cheng Kang and Julian J. McAuley. 2018. Self-Attentive Sequential Rec- ommendation. InProceedings of the 18th IEEE International Conference on Data Mining Conference, ICDM 2018. 197–206
work page 2018
-
[15]
Minu Kim, Yongsik Lee, Sehyeok Kang, Jihwan Oh, Song Chong, and Se-Young Yun. 2024. Preference Alignment with Flow Matching. InProceedings of the 38th Neural Information Processing Systems Conference on NeurIPS Conference on 2024
work page 2024
-
[16]
Gasnikov, and Alexander Korotin
Nikita Kornilov, Petr Mokrov, Alexander V. Gasnikov, and Alexander Korotin
-
[17]
InProceedings of the 38th NeurIPS Conference on Neural Information Processing Systems
Optimal Flow Matching: Learning Straight Trajectories in Just One Step. InProceedings of the 38th NeurIPS Conference on Neural Information Processing Systems
-
[18]
Hanyu Li, Jiayu Li, Weizhi Ma, Peijie Sun, Haiyang Wu, Jingwen Wang, Yuekui Yang, Min Zhang, and Shaoping Ma. 2025. CD-CDR: Conditional Diffusion- based Item Generation for Cross-Domain Recommendation. InProceedings of the 48th SIGIR Conference on Research and Development in Information Retrieval. 1789–1798
work page 2025
- [19]
-
[20]
Zihao Li, Aixin Sun, and Chenliang Li. 2024. DiffuRec: A Diffusion Model for Sequential Recommendation.ACM Trans. Inf. Syst.42, 3 (2024), 66:1–66:28
work page 2024
-
[21]
Xiao Lin, Xiaokai Chen, Chenyang Wang, Hantao Shu, Linfeng Song, Biao Li, and Peng Jiang. 2024. Discrete Conditional Diffusion for Reranking in Recom- mendation. InCompanion Proceedings of the ACM on Web Conference 2024, WWW 2024, Singapore, Singapore, May 13-17, 2024. ACM, 161–169
work page 2024
-
[22]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. 2023. Flow Matching for Generative Modeling. InProceedings of the 11th International Conference on Learning Representations ICRL 2023. Open- Review.net
work page 2023
- [23]
-
[24]
Chengkai Liu, Yangtian Zhang, Jianling Wang, Rex Ying, and James Caverlee
-
[25]
InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Flow Matching for Collaborative Filtering. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, 1765–1775
-
[26]
Feng Liu, Lixin Zou, Xiangyu Zhao, Min Tang, Liming Dong, Dan Luo, Xiangyang Luo, and Chenliang Li. 2025. Flow Matching Based Sequential Recommender Model. InProceedings of the 34th International Joint Conference on Artificial Intelligence, IJCAI 2025. ijcai.org, 3108–3116
work page 2025
-
[27]
Pan Liu, Xiaohua Tian, and Zhouhan Lin. 2024. Enable Fast Sampling for Seq2Seq Text Diffusion. InProceedings of the 2024 EMNLP Conference on Findings. 8495– 8505
work page 2024
-
[28]
Sijia Liu, Jiahao Liu, Hansu Gu, Dongsheng Li, Tun Lu, Peng Zhang, and Ning Gu. 2023. AutoSeqRec: Autoencoder for Efficient Sequential Recommendation. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management Conference, CIKM 2023. 1493–1502
work page 2023
-
[29]
Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel
-
[30]
Image-based recommendations on styles and substitutes. InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. 43–52
-
[31]
Preetum Nakkiran, Arwen Bradley, Hattie Zhou, and Madhu Advani. 2025. Step- by-Step Diffusion: An Elementary Tutorial.Found. Trends Comput. Graph. Vis. 17, 1 (2025), 1–75
work page 2025
-
[32]
Yong Niu, Xing Xing, Zhichun Jia, Ruidi Liu, Mindong Xin, and Jianfu Cui. 2024. Diffusion Recommendation with Implicit Sequence Influence. InProceedings of the 33rd ACM Web Conference on WWW 2024. 1719–1725
work page 2024
-
[33]
Yifang Qin, Wei Ju, Hongjun Wu, Xiao Luo, and Ming Zhang. 2024. Learning Graph ODE for Continuous-Time Sequential Recommendation.IEEE Trans. Knowl. Data Eng.36, 7 (2024), 3224–3236
work page 2024
-
[34]
Ruihong Qiu, Zi Huang, Hongzhi Yin, and Zijian Wang. 2022. Contrastive Learn- ing for Representation Degeneration Problem in Sequential Recommendation. InProceedings of the 15th ACM International Conference on Web Search and Data Mining, WSDM 2022, K. Selcuk Candan, Huan Liu, Leman Akoglu, Xin Luna Dong, and Jiliang Tang (Eds.). ACM, 813–823
work page 2022
-
[35]
Tran, Jonah Samost, Maciej Kula, Ed H
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Mahesh Sathiamoorthy. 2023. Recommender Systems with Generative Retrieval. InProceedings of the 36th NeurIPS Conference on Neural Information Processing Systems
work page 2023
-
[36]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[37]
InProceedings of the 28th ACM Conference on Information and Knowledge Management ,CIKM 2019
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Rep- resentations from Transformer. InProceedings of the 28th ACM Conference on Information and Knowledge Management ,CIKM 2019. 1441–1450
work page 2019
-
[38]
Jiaxi Tang and Ke Wang. 2018. Personalized Top-N Sequential Recommenda- tion via Convolutional Sequence Embedding. InProceedings of the 11th ACM International Conference on Web Search and Data Mining Conference on WSDM. 565–573
work page 2018
-
[39]
Dongsheng Wang, Yuxi Huang, Shen Gao, Yifan Wang, Chengrui Huang, and Shuo Shang. 2025. Generative Next POI Recommendation with Semantic ID. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, 2904–2914
work page 2025
-
[40]
Yifan Wang, Shen Gao, Jiabao Fang, Lisi Chen, Peng Han, and Shuo Shang. 2025. DRE: Generating Recommendation Explanations by Aligning Large Language Models at Data-Level. InDatabase Systems for Advanced Applications - Proceedings of the 30th International Conference, DASFAA 2025 (Lecture Notes in Computer Science). Springer, 286–302. FAVE: Flow-based Aver...
work page 2025
-
[41]
Yifan Wang, Shen Gao, Jiabao Fang, Rui Yan, Billy Chiu, and Shuo Shang. 2025. CESRec: Constructing Pseudo Interactions for Sequential Recommendation via Conversational Feedback. InFindings of the Association for Computational Lin- guistics: EMNLP. Association for Computational Linguistics, 16227–16239
work page 2025
-
[42]
Yuhao Wang, Ziru Liu, Yichao Wang, Xiangyu Zhao, Bo Chen, Huifeng Guo, and Ruiming Tang. 2024. Diff-MSR: A Diffusion Model Enhanced Paradigm for Cold-Start Multi-Scenario Recommendation. InProceedings of the 17th ACM International Conference on Web Search and Data Mining Conference on WSDM. 779–787
work page 2024
-
[43]
Yuanbo Xu, En Wang, Yongjian Yang, and Hui Xiong. 2024. GS-RS: A Generative Approach for Alleviating Cold Start and Filter Bubbles in Recommender Systems. IEEE Trans. Knowl. Data Eng.36, 2 (2024), 668–681
work page 2024
-
[44]
Yiyan Xu, Wenjie Wang, Fuli Feng, Yunshan Ma, Jizhi Zhang, and Xiangnan He
-
[45]
InProceedings of the 47th SIGIR Conference on Research and Development in Information Retrieval
Diffusion Models for Generative Outfit Recommendation. InProceedings of the 47th SIGIR Conference on Research and Development in Information Retrieval. 1350–1359
-
[46]
Zhengyi Yang, Jiancan Wu, Zhicai Wang, Xiang Wang, Yancheng Yuan, and Xiangnan He. 2023. Generate What You Prefer: Reshaping Sequential Recom- mendation via Guided Diffusion. InProceedings of the 36th Neural Information Processing Systems Conference on Neural Information Processing Systems, nips 2023
work page 2023
-
[47]
Yi Zhang, Yiwen Zhang, Yu Wang, Tong Chen, and Hongzhi Yin. 2025. Towards Distribution Matching between Collaborative and Language Spaces for Genera- tive Recommendation. InProceedings of the 48th SIGIR Conference on Research and Development in Information Retrieval. 2006–2016
work page 2025
-
[48]
Jujia Zhao, Wenjie Wang, Yiyan Xu, Teng Sun, Fuli Feng, and Tat-Seng Chua
-
[49]
InProceedings of the 47th SIGIR Conference on Research and Development in Information Retrieval
Denoising Diffusion Recommender Model. InProceedings of the 47th SIGIR Conference on Research and Development in Information Retrieval. 1370–1379
-
[50]
Yunqin Zhu, Chao Wang, Qi Zhang, and Hui Xiong. 2024. Graph Signal Diffusion Model for Collaborative Filtering. InProceedings of the 47th SIGIR Conference on Research and Development in Information Retrieval. 1380–1390
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.