Recognition: 1 theorem link
· Lean TheoremMultilingual Prompt Localization for Agent-as-a-Judge: Language and Backbone Sensitivity in Requirement-Level Evaluation
Pith reviewed 2026-05-10 19:58 UTC · model grok-4.3
The pith
Changing the judge's language can reverse which AI backbone performs best on agent development tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
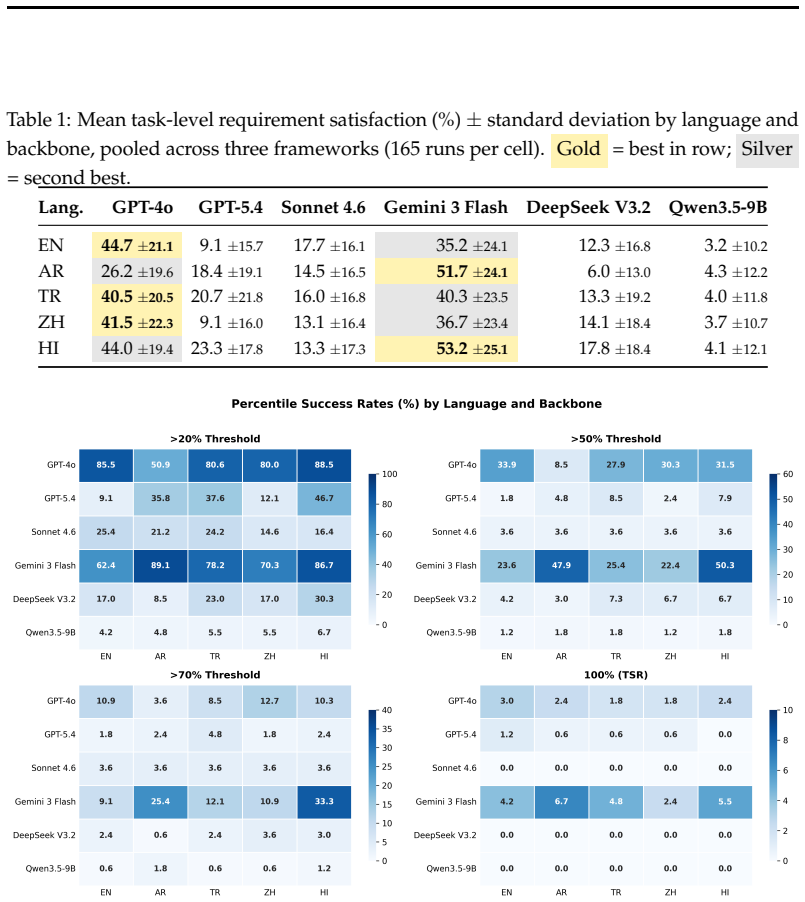
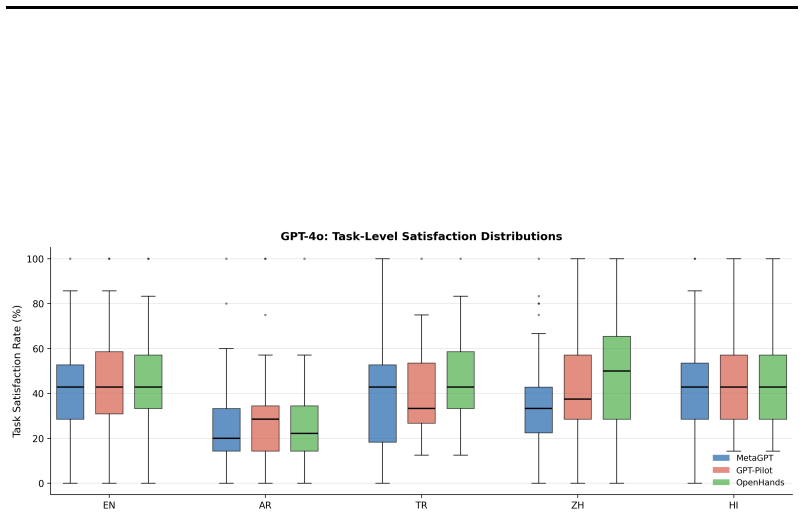
Localizing the Agent-as-a-Judge prompt stack across English, Arabic, Turkish, Chinese, and Hindi on 55 DevAI tasks shows that backbone and language interact: GPT-4o reaches the highest satisfaction in English at 44.72 percent while Gemini leads in Arabic at 51.72 percent and Hindi at 53.22 percent, with no backbone dominating all languages and inter-backbone agreement remaining modest at Fleiss kappa of at most 0.231. An ablation confirms that localizing judge-side instructions, not merely the benchmark content, drives the difference, as Hindi satisfaction falls from 42.8 percent to 23.2 percent under partial localization.
What carries the argument
The backbone-language interaction in requirement-level satisfaction judgments produced by fully localized judge prompts and translated task requirements.
Load-bearing premise
That translating requirements and judge instructions into other languages keeps their intended meaning and difficulty unchanged without introducing biases in how different models interpret the same requirements.
What would settle it
Re-running the full set of 4950 judgments after independent native-speaker re-translations of the prompts and checking whether the observed ranking inversions between backbones persist or disappear.
Figures






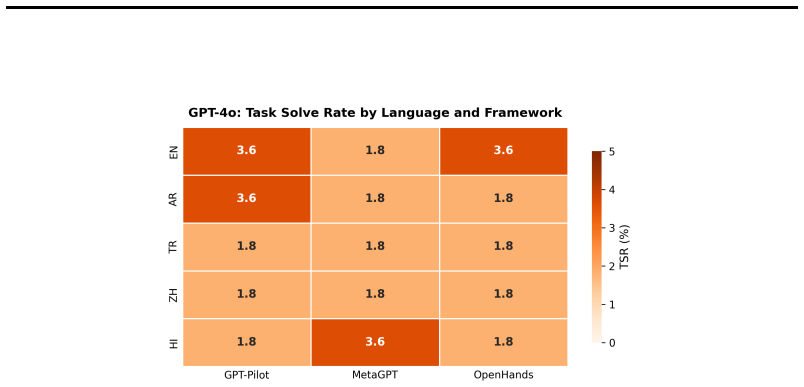
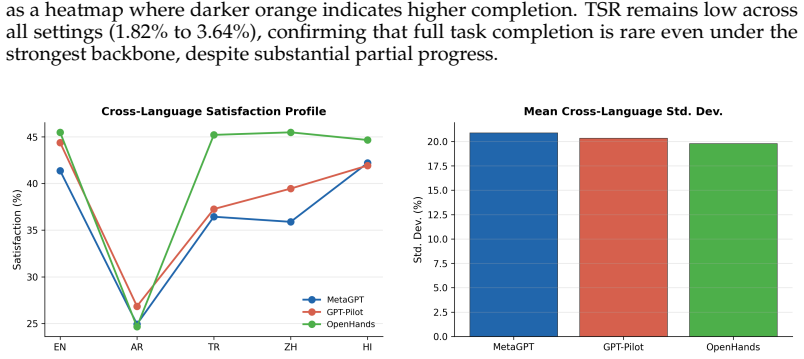
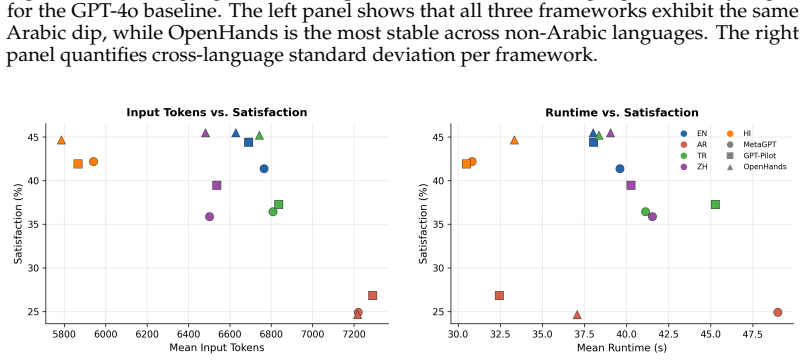
read the original abstract
Evaluation language is typically treated as a fixed English default in agentic code benchmarks, yet we show that changing the judge's language can invert backbone rankings. We localize the Agent-as-a-Judge prompt stack to five typologically diverse languages (English, Arabic, Turkish, Chinese, Hindi) and evaluate 55 DevAI development tasks across three developer-agent frameworks and six judge backbones, totaling 4950 judge runs. The central finding is that backbone and language interact: GPT-4o achieves the highest satisfaction in English (44.72\%), while Gemini leads in Arabic (51.72\%, $p<0.001$ vs.\ GPT-4o) and Hindi (53.22\%). No single backbone dominates across all languages, and inter-backbone agreement on individual requirement judgments is modest (Fleiss' $\kappa \leq 0.231$). A controlled ablation further shows that localizing judge-side instructions, not just benchmark content, can be decisive: Hindi satisfaction drops from 42.8\% to 23.2\% under partial localization. These results indicate that language should be treated as an explicit evaluation variable in agentic benchmarks. Full requirement-level judgments and runtime statistics are released for reproducibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study localizing the Agent-as-a-Judge prompt stack to five languages (English, Arabic, Turkish, Chinese, Hindi) and evaluating it on 55 DevAI tasks using three agent frameworks and six backbones for a total of 4950 runs. It claims that judge backbone and language interact strongly, with performance rankings inverting across languages (GPT-4o highest in English at 44.72%, Gemini highest in Arabic at 51.72% and Hindi at 53.22%, both p<0.001 vs GPT-4o), no backbone dominates universally, inter-backbone agreement is modest (Fleiss' κ ≤ 0.231), and that localizing judge instructions (not just content) is decisive as shown by a Hindi ablation (42.8% full vs 23.2% partial localization). The authors conclude that language should be treated as an explicit variable in agentic benchmarks and release the judgments for reproducibility.
Significance. If the results are robust to translation artifacts, this work is significant in demonstrating that standard English-centric evaluations may not generalize, providing evidence from a large-scale, controlled experiment with ablation and public data release. It contributes to the growing literature on multilingual LLM evaluation by focusing on agentic, requirement-level judging rather than simple QA.
major comments (2)
- [Methods (localization procedure)] The assumption that localized requirements and prompts preserve equivalent meaning and difficulty across languages is central to interpreting the ranking inversions as backbone-language interactions. The manuscript reports no quantitative validation such as back-translation BLEU scores, bilingual human ratings of semantic equivalence, or difficulty calibration for the 55 tasks in Arabic, Turkish, Chinese, and Hindi. This leaves open the possibility that observed differences (e.g., Gemini 53.22% in Hindi) arise from translation quality variations or language-specific requirement biases.
- [Results (ablation study)] While the ablation in Hindi shows a large drop from 42.8% to 23.2% satisfaction under partial localization, the paper does not specify what 'partial' entails in detail or provide controls to confirm that the partial version alters only the intended localization aspect without introducing other confounds.
minor comments (2)
- [Abstract] The list of the six judge backbones and three developer-agent frameworks is not provided in the abstract; including them would improve readability.
- [Abstract] The exact statistical test and correction method for the reported p<0.001 values should be stated explicitly.
Simulated Author's Rebuttal
Thank you for the detailed review. We have carefully considered the major comments and provide point-by-point responses below, along with planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods (localization procedure)] The assumption that localized requirements and prompts preserve equivalent meaning and difficulty across languages is central to interpreting the ranking inversions as backbone-language interactions. The manuscript reports no quantitative validation such as back-translation BLEU scores, bilingual human ratings of semantic equivalence, or difficulty calibration for the 55 tasks in Arabic, Turkish, Chinese, and Hindi. This leaves open the possibility that observed differences (e.g., Gemini 53.22% in Hindi) arise from translation quality variations or language-specific requirement biases.
Authors: We agree that the absence of quantitative validation (such as back-translation metrics or human equivalence ratings) is a limitation in the current manuscript. The ablation study provides some supporting evidence by demonstrating a substantial performance difference when only judge instructions are localized versus full localization, using the same underlying requirements. We will revise the Methods section to expand on the localization procedure as implemented, add an explicit discussion of this limitation, and release all original and localized prompts to facilitate independent verification by the community. revision: partial
-
Referee: [Results (ablation study)] While the ablation in Hindi shows a large drop from 42.8% to 23.2% satisfaction under partial localization, the paper does not specify what 'partial' entails in detail or provide controls to confirm that the partial version alters only the intended localization aspect without introducing other confounds.
Authors: We agree that greater specificity is required. We will update the manuscript to explicitly define the partial localization condition (translating only the task requirements while retaining English judge instructions and criteria) and include the exact prompt templates for both full and partial conditions. We will also add a comparison to the fully English baseline to help isolate the intended effect and address potential confounds. revision: yes
Circularity Check
No circularity: purely empirical measurements with direct statistical reporting
full rationale
The paper conducts controlled experiments localizing prompts and requirements across languages, then reports satisfaction percentages, p-values, and Fleiss' kappa computed from 4950 judge runs on 55 tasks. No equations, derivations, fitted parameters renamed as predictions, or self-citations that bear the load of the central claims exist. All results are direct counts and comparisons from the runs, making the derivation chain self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Statistical comparisons (p-values, Fleiss' kappa) are appropriately applied to the satisfaction scores and agreement metrics.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe localize the AAAJ prompt stack to five typologically diverse languages... backbone and language interact: GPT-4o achieves the highest satisfaction in English (44.72%), while Gemini leads in Arabic (51.72%) and Hindi (53.22%).
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Feldman, et al
Federico Cassano, Jacob Gouwar, Daniel Nguyen, Sydney Nguyen, Luna Phipps-Costin, Donald Pinckney, Ming-Ho Yee, Yangtian Zi, Carolyn Jane Anderson, Molly Q. Feldman, et al. MultiPL-E : A scalable and polyglot approach to benchmarking neural code generation. IEEE Transactions on Software Engineering, 49 0 (7): 0 3675--3691, 2023
2023
-
[3]
McEval : Massively multilingual code evaluation
Linzheng Chai, Shukai Liu, Jian Yang, Yuwei Yin, Ke Jin, Jiaheng Liu, Tao Sun, Ge Zhang, Changyu Ren, Hongcheng Guo, et al. McEval : Massively multilingual code evaluation. In International Conference on Learning Representations, 2025
2025
-
[4]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal A. Patwardhan, Lilian Weng, et al. MLE-Bench : Evaluating machine learning agents on machine learning engineering. arXiv preprint arXiv:2410.07095, 2024
work page Pith review arXiv 2024
-
[5]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Sumanth Doddapaneni, Mohammed Safi Ur Rahman Khan, Dilip Venkatesh, Raj Dabre, Anoop Kunchukuttan, and Mitesh M. Khapra. Cross-lingual auto evaluation for assessing multilingual LLM s. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 29297--29329, Vienna, Austria, 2025. Association fo...
-
[7]
Jack FitzGerald, Christopher Hench, Charith Peris, Scott Mackie, Kay Rottmann, Ana Sanchez, Aaron Nash, Liam Urbach, Vishesh Kakarala, Richa Singh, Swetha Ranganath, Laurie Crist, Misha Britan, Wouter Leeuwis, Gokhan Tur, and Prem Natarajan. MASSIVE : A 1m-example multilingual natural language understanding dataset with 51 typologically-diverse languages....
-
[8]
Xiyan Fu and Wei Liu. How reliable is multilingual LLM -as-a-judge? In Findings of the Association for Computational Linguistics: EMNLP 2025 , pp.\ 11040--11053, Suzhou, China, 2025. Association for Computational Linguistics. doi:10.18653/v1/2025.findings-emnlp.587. URL https://aclanthology.org/2025.findings-emnlp.587/
-
[9]
Annotation artifacts in natural language inference data
Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel Bowman, and Noah A Smith. Annotation artifacts in natural language inference data. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pp.\ 107--112, 2018
2018
-
[10]
Nizar Y. Habash. Introduction to Arabic Natural Language Processing, volume 10 of Synthesis Lectures on Human Language Technologies. Morgan & Claypool, 2010
2010
-
[11]
MetaGPT : Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. MetaGPT : Meta programming for a multi-agent collaborative framework. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[12]
Which is essential for chinese word segmentation: Character versus word
Chang-Ning Huang and Hai Zhao. Which is essential for chinese word segmentation: Character versus word. In Proceedings of the 20th Pacific Asia Conference on Language, Information and Computation, pp.\ 1--12, Huazhong Normal University, Wuhan, China, 2006. Tsinghua University Press. URL https://aclanthology.org/Y06-1001/
2006
-
[13]
Time to impeach LLM -as-a-judge: Programs are the future of evaluation
Tzu-Heng Huang, Harit Vishwakarma, and Frederic Sala. Time to impeach LLM -as-a-judge: Programs are the future of evaluation. arXiv preprint arXiv:2506.10403, 2025
-
[14]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Kilian Lieret, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-Bench : Can language models resolve real-world GitHub issues? arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Data contamination: From memorization to exploitation
Inbal Magar and Roy Schwartz. Data contamination: From memorization to exploitation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp.\ 157--165, 2022
2022
-
[16]
Ziyi Ni, Huacan Wang, Shuo Zhang, Shuo Lu, Ziyang He, Wang You, Zhenheng Tang, Yuntao Du, Bill Sun, Hongzhang Liu, et al. GitTaskBench : A benchmark for code agents solving real-world tasks through code repository leveraging. arXiv preprint arXiv:2508.18993, 2025
-
[17]
A syntactically expressive morphological analyzer for turkish
Adnan Ozturel, Tolga Kayadelen, and Isin Demirsahin. A syntactically expressive morphological analyzer for turkish. In Proceedings of the 14th International Conference on Finite-State Methods and Natural Language Processing, pp.\ 65--75, Dresden, Germany, 2019. Association for Computational Linguistics. doi:10.18653/v1/W19-3110. URL https://aclanthology.o...
-
[18]
GPT-Pilot : Your AI copilot for software development
Pythagora.io . GPT-Pilot : Your AI copilot for software development. GitHub repository, 2023. URL https://github.com/Pythagora-io/gpt-pilot
2023
-
[19]
mHumanEval : A multilingual benchmark to evaluate large language models for code generation
Nishat Raihan, Antonios Anastasopoulos, and Marcos Zampieri. mHumanEval : A multilingual benchmark to evaluate large language models for code generation. In Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics, 2025
2025
-
[20]
Cross-lingual LLM -judge transfer via evaluation decomposition
Ivaxi Sheth, Zeno Jonke, Amin Mantrach, and Saab Mansour. Cross-lingual LLM -judge transfer via evaluation decomposition. arXiv preprint arXiv:2603.18557, 2026. doi:10.48550/arXiv.2603.18557. URL https://arxiv.org/abs/2603.18557
-
[21]
Harman Singh, Nitish Gupta, Shikhar Bharadwaj, Dinesh Tewari, and Partha Talukdar. IndicGenBench : A multilingual benchmark to evaluate generation capabilities of LLM s on indic languages. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 11047--11073, Bangkok, Thailand, 2024. Associat...
-
[22]
MM-Eval : A multilingual meta-evaluation benchmark for LLM -as-a-judge and reward models
Guijin Son, Dongkeun Yoon, Juyoung Suk, Javier Aula-Blasco, Mano Aslan, Vu Trong Kim, Shayekh Bin Islam, Jaume Prats-Cristi \`a , Luc \'i a Tormo-Ba \ n uelos, and Seungone Kim. MM-Eval : A multilingual meta-evaluation benchmark for LLM -as-a-judge and reward models. arXiv preprint arXiv:2410.17578, 2024. doi:10.48550/arXiv.2410.17578. URL https://arxiv.o...
-
[23]
Ahilan Ayyachamy Nadar Ponnusamy
Atharv Sonwane, Eng-Shen Tu, Wei-Chung Lu, Claas Beger, Carter Larsen, Debjit Dhar, Simon Alford, Rachel Chen, Ronit Pattanayak, Tuan Anh Dang, et al. OmniCode : A benchmark for evaluating software engineering agents. arXiv preprint arXiv:2602.02262, 2026
-
[24]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. OpenDevin : An open platform for AI software developers as generalist agents. arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review arXiv 2024
-
[25]
Swe-compass: Towards unified evaluation of agentic coding abilities for large language models, 2025
Jingxuan Xu, Ken Deng, Weihao Li, Songwei Yu, Huaixi Tang, Haoyang Huang, Zhiyi Lai, Zizheng Zhan, Yanan Wu, Chenchen Zhang, et al. SWE-Compass : Towards unified evaluation of agentic coding abilities for large language models. arXiv preprint arXiv:2511.05459, 2025. doi:10.48550/arXiv.2511.05459. URL https://arxiv.org/abs/2511.05459
-
[26]
FLASK : Fine-grained language model evaluation based on alignment skill sets
Seonghyeon Ye, Doyoung Kim, Sungdong Kim, Hyeonbin Hwang, Seungone Kim, Yongrae Jo, James Thorne, Juho Kim, and Minjoon Seo. FLASK : Fine-grained language model evaluation based on alignment skill sets. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[27]
Xing, et al
Lianmin Zheng, Wei-Lin Chiang, Siyuan Sheng, Sihan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, et al. Judging LLM -as-a-judge with MT-Bench and Chatbot Arena . In Advances in Neural Information Processing Systems, 2024
2024
-
[28]
Agent-as-a-judge: Evaluate agents with agents
Mingchen Zhuge, Changsheng Zhao, Dylan R. Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, et al. Agent-as-a-judge: Evaluate agents with agents. arXiv preprint arXiv:2410.10934, 2024
-
[29]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[30]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[31]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[32]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.