Recognition: 2 theorem links
· Lean TheoremPassiveQA: A Three-Action Framework for Epistemically Calibrated Question Answering via Supervised Finetuning
Pith reviewed 2026-05-10 19:45 UTC · model grok-4.3
The pith
Supervised finetuning on structured information states trains models to choose answer, ask, or abstain based on query sufficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A finetuned planner that integrates structured information-state representations, knowledge graph-grounded context, and explicit modeling of missing variables produces decision behavior aligned with information sufficiency, yielding higher macro F1, improved abstention recall, and lower hallucination rates than baseline or enhanced RAG systems under constrained training.
What carries the argument
The finetuned planner that explicitly models missing variables and decision reasoning inside a three-action framework (Answer, Ask, Abstain) built on structured information-state representations.
Load-bearing premise
That supervised finetuning on structured information-state representations will yield generalizable decision rules for recognizing when information is insufficient.
What would settle it
Evaluation on a held-out QA dataset with deliberately incomplete queries where the finetuned planner shows abstention recall and hallucination rates no better than standard RAG baselines.
Figures
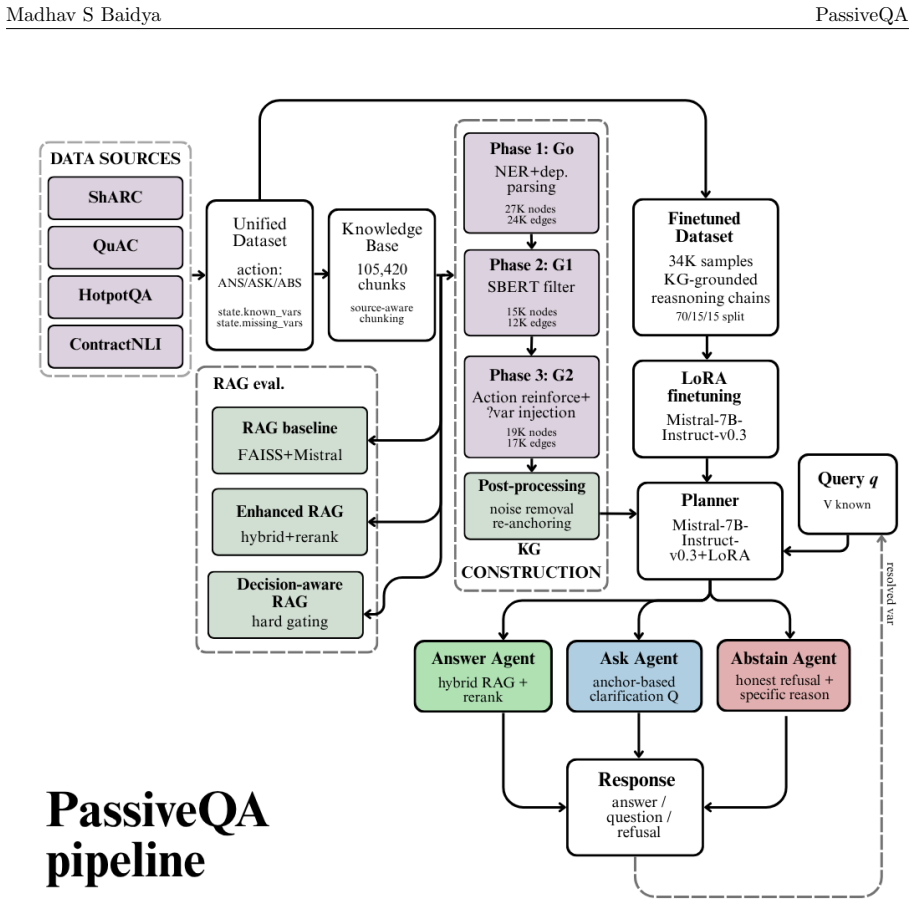

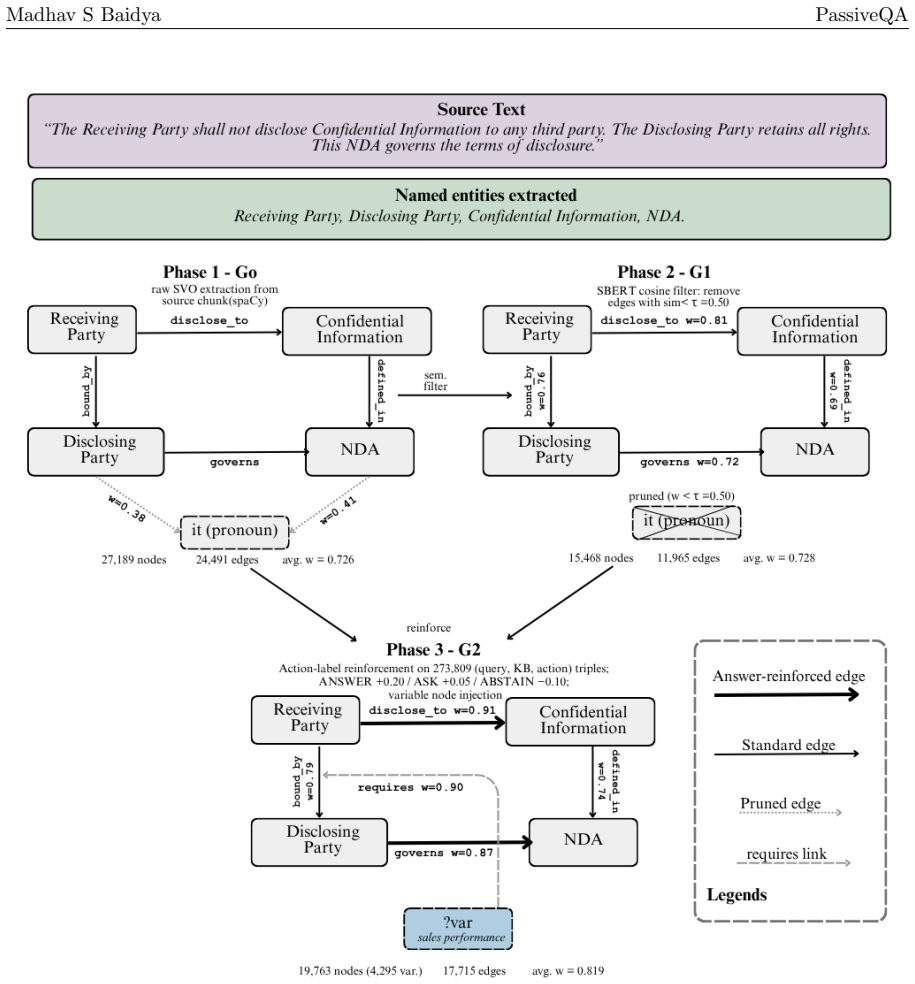

read the original abstract
Large Language Models (LLMs) have achieved strong performance in question answering and retrieval-augmented generation (RAG), yet they implicitly assume that user queries are fully specified and answerable. In real-world settings, queries are often incomplete, ambiguous, or missing critical variables, leading models to produce overconfident or hallucinated responses. In this work, we study decision-aware query resolution under incomplete information, where a model must determine whether to Answer, Ask for clarification, or Abstain. We show that standard and enhanced RAG systems do not reliably exhibit such epistemic awareness, defaulting to answer generation even when information is insufficient. To address this, we propose PassiveQA, a three-action framework that aligns model behaviour with information sufficiency through supervised finetuning. Our approach integrates structured information-state representations, knowledge graph-grounded context, and a finetuned planner that explicitly models missing variables and decision reasoning. Experiments across multiple QA datasets show that the finetuned planner achieves significant improvements in macro F1 and abstention recall while reducing hallucination rates, under a compute-constrained training regime. These results provide strong empirical evidence that epistemic decision-making must be learned during training rather than imposed at inference time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PassiveQA, a three-action (Answer/Ask/Abstain) framework for question answering under incomplete or ambiguous information. It argues that standard and enhanced RAG systems lack epistemic awareness and default to answer generation. The approach uses supervised finetuning on structured information-state representations combined with knowledge-graph-grounded context to train a planner that explicitly models missing variables and selects among the three actions. Experiments on multiple QA datasets are reported to yield improvements in macro F1 and abstention recall while reducing hallucination rates under a compute-constrained regime. The central thesis is that epistemic decision-making must be learned via finetuning rather than imposed at inference time.
Significance. If the empirical results are substantiated with clear baselines, label-generation details, and robustness checks, the work would provide useful evidence that supervised finetuning on explicit decision representations can improve reliability in underspecified QA settings. The structured three-action formulation and focus on information sufficiency are practical contributions that could inform more calibrated RAG pipelines, especially in resource-limited training scenarios.
major comments (3)
- [Abstract / §4] The abstract and introduction assert that the finetuned planner achieves 'significant improvements in macro F1 and abstention recall while reducing hallucination rates,' yet no quantitative results, specific dataset names, baseline comparisons, or statistical details are supplied in the provided text. Without these, the central empirical claim cannot be evaluated. (This is load-bearing for the paper's contribution.)
- [§3 (Method) / §4 (Experiments)] The claim that supervised finetuning produces generalizable epistemic decision behavior aligned with true information sufficiency rests on the assumption that the training labels for Answer/Ask/Abstain were generated independently of the model family and reflect genuine sufficiency. The manuscript does not describe the label creation process, any human validation, or inter-annotator agreement. If labels were produced by a similar LLM without external grounding, the learned policy may reproduce labeler biases rather than discover sufficiency. This directly affects the interpretation of the reported F1 and abstention gains.
- [§3.2 / §4] The framework relies on knowledge-graph-grounded context during both training and inference. The paper should include an ablation or robustness analysis showing performance when the KG context is incomplete or noisy at test time, as any mismatch would break the alignment the planner was trained to exploit. No such analysis is described.
minor comments (2)
- [Abstract] The term 'PassiveQA' is introduced without an explicit expansion or motivation for the name in the abstract or introduction.
- [§3] Notation for the three actions and information-state representation should be defined consistently with an equation or diagram early in §3 to aid readability.
Simulated Author's Rebuttal
We thank the referee for their valuable comments on the manuscript. We address each of the major concerns below and commit to making the suggested revisions to enhance the paper's clarity and completeness.
read point-by-point responses
-
Referee: [Abstract / §4] The abstract and introduction assert that the finetuned planner achieves 'significant improvements in macro F1 and abstention recall while reducing hallucination rates,' yet no quantitative results, specific dataset names, baseline comparisons, or statistical details are supplied in the provided text. Without these, the central empirical claim cannot be evaluated. (This is load-bearing for the paper's contribution.)
Authors: We agree that the abstract would benefit from including concrete quantitative results to substantiate the claims. In the revised version, we will incorporate specific performance metrics (e.g., macro F1, abstention recall, hallucination rates), dataset names, and baseline comparisons into the abstract and introduction, drawing from the detailed results in Section 4. revision: yes
-
Referee: [§3 (Method) / §4 (Experiments)] The claim that supervised finetuning produces generalizable epistemic decision behavior aligned with true information sufficiency rests on the assumption that the training labels for Answer/Ask/Abstain were generated independently of the model family and reflect genuine sufficiency. The manuscript does not describe the label creation process, any human validation, or inter-annotator agreement. If labels were produced by a similar LLM without external grounding, the learned policy may reproduce labeler biases rather than discover sufficiency. This directly affects the interpretation of the reported F1 and abstention gains.
Authors: We acknowledge the need for transparency in label generation. We will revise Section 3 to include a comprehensive description of the process used to create the training labels for the three actions, detailing how information sufficiency was assessed via the structured representations and KG context. This addition will clarify the grounding of the labels and allow readers to assess potential biases. revision: yes
-
Referee: [§3.2 / §4] The framework relies on knowledge-graph-grounded context during both training and inference. The paper should include an ablation or robustness analysis showing performance when the KG context is incomplete or noisy at test time, as any mismatch would break the alignment the planner was trained to exploit. No such analysis is described.
Authors: We concur that robustness to variations in KG quality is an important consideration. We will add an ablation experiment in the revised Section 4, where we evaluate the planner under conditions of incomplete or noisy KG context at inference time, to assess the impact on decision-making performance and provide insights into the framework's reliability. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes PassiveQA as a supervised finetuning framework on external QA datasets to train a planner for Answer/Ask/Abstain decisions using structured information-state representations. No equations, derivations, or self-referential definitions appear in the provided text. Results are presented as empirical improvements in macro F1, abstention recall, and hallucination reduction measured on multiple datasets under a compute-constrained regime. The central claims rest on standard finetuning practices and external data rather than any reduction to fitted parameters renamed as predictions, self-citation chains, or ansatzes smuggled via prior work. The derivation chain is self-contained and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Supervised finetuning on structured information-state representations will align model behavior with information sufficiency and reduce hallucinations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define the information state of q as S(q) = (Vknown, Vmissing, C) ... a∗(q) ≈ Answer if I(q)≈0, Ask if 0<I(q)<1 ∧ Vmissing recoverable, Abstain otherwise.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery theorem unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The finetuned planner achieves 55.6% macro F1 ... via LoRA on Mistral-7B with structured XML reasoning chains.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
u ttler, H., Lewis, M., Yih, W.-t., Rockt\
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., K\" u ttler, H., Lewis, M., Yih, W.-t., Rockt\" a schel, T., Riedel, S., and Kiela, D.\ (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 9459--9474
2020
-
[2]
Dense passage retrieval for open-domain question answering
Karpukhin, V., O g uz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and Yih, W.-t.\ (2020). Dense passage retrieval for open-domain question answering. In Proceedings of EMNLP 2020, pages 6769--6781
2020
-
[3]
REALM : Retrieval-augmented language model pre-training
Guu, K., Lee, K., Tung, Z., Pasupat, P., and Chang, M.-W.\ (2020). REALM : Retrieval-augmented language model pre-training. In Proceedings of ICML 2020
2020
-
[4]
Leveraging passage retrieval with generative models for open domain question answering
Izacard, G.\ and Grave, E.\ (2021). Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of EACL 2021, pages 874--880
2021
-
[5]
Improving language models by retrieving from trillions of tokens
Borgeaud, S., Mensch, A., Hoffmann, J., Cai, T., Rutherford, E., Millican, K., van den Driessche, G., Lespiau, J.-B., Damoc, B., Clark, A., et al.\ (2022). Improving language models by retrieving from trillions of tokens. In Proceedings of ICML 2022, pages 2206--2240
2022
-
[6]
The probabilistic relevance framework: BM25 and beyond
Robertson, S.\ and Zaragoza, H.\ (2009). The probabilistic relevance framework: BM25 and beyond. Foundations and Trends in Information Retrieval, 3(4):333--389
2009
-
[7]
ColBERTv2 : Effective and efficient retrieval via lightweight late interaction
Santhanam, K., Khattab, O., Saad-Falcon, J., Potts, C., and Zaharia, M.\ (2022). ColBERTv2 : Effective and efficient retrieval via lightweight late interaction. In Proceedings of NAACL 2022, pages 3715--3734
2022
-
[8]
Retrieval-Augmented Generation for Large Language Models: A Survey
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, M., and Wang, H.\ (2023). Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
J., Madotto, A., and Fung, P.\ (2023)
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y. J., Madotto, A., and Fung, P.\ (2023). Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1--38
2023
-
[10]
On faithfulness and factuality in abstractive summarization
Maynez, J., Narayan, S., Bohnet, B., and McDonald, R.\ (2020). On faithfulness and factuality in abstractive summarization. In Proceedings of ACL 2020, pages 1906--1919
2020
-
[11]
Alleviating hallucinations from knowledge misalignment in large language models via selective abstention learning
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., and Liu, T.\ (2025). Alleviating hallucinations from knowledge misalignment in large language models via selective abstention learning. In Proceedings of ACL 2025 (Long Papers)
2025
-
[12]
Goswami, S.\ and Kurra, S.\ (2025). HALT-RAG : A task-adaptable framework for hallucination detection with calibrated NLI ensembles and abstention. arXiv preprint arXiv:2509.07475
-
[13]
arXiv preprint arXiv:2510.24476 , year =
Li, Y., Fu, X., Verma, G., Buitelaar, P., and Liu, M.\ (2025). Mitigating hallucination in large language models: An application-oriented survey on RAG , reasoning, and agentic systems. arXiv preprint arXiv:2510.24476
-
[14]
Selective Classification for Deep Neural Networks In Advances in Neural Information Processing Systems (NeurIPS), pages 6327--6338
Geifman, Y.\ and El-Yaniv, R.\ (2017). Selective Classification for Deep Neural Networks In Advances in Neural Information Processing Systems (NeurIPS), pages 6327--6338
2017
-
[15]
The art of abstention: Selective prediction and error regularization for natural language processing
Xin, J., Tang, R., Yu, Y., and Lin, J.\ (2021). The art of abstention: Selective prediction and error regularization for natural language processing. In Proceedings of ACL-IJCNLP 2021, pages 1040--1051
2021
-
[16]
Post-abstention: Towards reliably re-attempting the abstained instances in QA
Varshney, N.\ and Baral, C.\ (2023). Post-abstention: Towards reliably re-attempting the abstained instances in QA . arXiv preprint arXiv:2305.01812
-
[17]
Do large language models know what they don't know? In Findings of ACL 2024
Yin, Z., Sun, Q., Guo, Q., Wu, J., Qiu, X., and Huang, X.\ (2024). Do large language models know what they don't know? In Findings of ACL 2024
2024
-
[18]
Gustafsson, Sean Wu, Anshul Thakur, and David A
Phillips, E., Gustafsson, F. K., Wu, S., Thakur, A., and Clifton, D. A.\ (2026). Entropy alone is insufficient for safe selective prediction in LLM s. arXiv preprint arXiv:2603.21172
-
[19]
Thibaud Gloaguen, Niels Mündler, Mark Niklas Müller, Veselin Raychev, and Martin T
Feng, S., Shi, W., Wang, Y., Ding, W., Balachandran, V., and Tsvetkov, Y.\ (2024). Don't hallucinate, abstain: Identifying LLM knowledge gaps via multi- LLM collaboration. In Proceedings of ACL 2024. arXiv preprint arXiv:2402.00367
-
[20]
Interpretation of natural language rules in conversational machine reading
Saeidi, M., Bartolo, M., Lewis, P., Singh, S., Rockt\" a schel, T., Sheldon, M., Bouchard, G., and Riedel, S.\ (2018). Interpretation of natural language rules in conversational machine reading. In Proceedings of EMNLP 2018, pages 2087--2097
2018
-
[21]
QuAC : Question answering in context
Choi, E., He, H., Iyyer, M., Yatskar, M., Yih, W.-t., Choi, Y., Liang, P., and Zettlemoyer, L.\ (2018). QuAC : Question answering in context. In Proceedings of EMNLP 2018, pages 2174--2184
2018
-
[22]
B.\ (2019)
Aliannejadi, M., Zamani, H., Crestani, F., and Croft, W. B.\ (2019). Asking clarifying questions in open-domain information-seeking conversations. In Proceedings of SIGIR 2019, pages 475--484
2019
-
[23]
Learning to ask good questions: Ranking clarification questions using neural expected value of perfect information
Rao, S.\ and Daum\' e III, H.\ (2018). Learning to ask good questions: Ranking clarification questions using neural expected value of perfect information. In Proceedings of ACL 2018, pages 2737--2746
2018
-
[24]
Towards end-to-end open conversational machine reading
Zhou, S., Ouyang, S., Zhang, Z., and Zhao, H.\ (2023). Towards end-to-end open conversational machine reading. In Findings of the Association for Computational Linguistics: EACL 2023, pages 2064--2076, Dubrovnik, Croatia. Association for Computational Linguistics
2023
-
[25]
QA-GNN : Reasoning with language models and knowledge graphs for question answering
Yasunaga, M., Ren, H., Bosselut, A., Liang, P., and Leskovec, J.\ (2021). QA-GNN : Reasoning with language models and knowledge graphs for question answering. In Proceedings of NAACL-HLT 2021, pages 535--546
2021
-
[26]
W.\ (2019)
Sun, H., Dhingra, B., Zaheer, M., Mazaitis, K., Salakhutdinov, R., and Cohen, W. W.\ (2019). Open domain question answering using early fusion of knowledge bases and text. In Proceedings of EMNLP-IJCNLP 2019, pages 4231--4242
2019
-
[27]
Y., Chen, X., Chen, J., and Ren, X.\ (2019)
Lin, B. Y., Chen, X., Chen, J., and Ren, X.\ (2019). KagNet : Knowledge-aware graph networks for commonsense reasoning. In Proceedings of EMNLP-IJCNLP 2019, pages 2829--2839
2019
-
[28]
A survey on retrieval and structuring augmented generation with large language models
Jiang, P., Ouyang, S., Jiao, Y., Zhong, M., Tian, R., and Han, J.\ (2025). A survey on retrieval and structuring augmented generation with large language models. arXiv preprint arXiv:2509.10697
-
[29]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W.\ (2021). LoRA : Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
QLoRA: Efficient Finetuning of Quantized LLMs
Dettmers, T., Pagnoni, A., Holtzman, A., and Zettlemoyer, L.\ (2023). QLoRA : Efficient finetuning of quantized LLM s. arXiv preprint arXiv:2305.14314
work page internal anchor Pith review arXiv 2023
-
[31]
L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.\ (2022)
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.\ (2022). Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems (NeurIPS), volume 35, pages 27730--27744
2022
-
[32]
D., Ermon, S., and Finn, C.\ (2023)
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and Finn, C.\ (2023). Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems (NeurIPS), volume 36
2023
-
[33]
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al.\ (2023). Mistral 7 B . arXiv preprint arXiv:2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
W., Salakhutdinov, R., and Manning, C
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W. W., Salakhutdinov, R., and Manning, C. D.\ (2018). HotpotQA : A dataset for diverse, explainable multi-hop question answering. In Proceedings of EMNLP 2018, pages 2369--2380
2018
-
[35]
D.\ (2021)
Koreeda, Y.\ and Manning, C. D.\ (2021). ContractNLI : A dataset for document-level natural language inference for contracts. In Findings of EMNLP 2021, pages 1907--1919
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.