Recognition: 2 theorem links
· Lean TheoremSpringdrift: An Auditable Persistent Runtime for LLM Agents with Case-Based Memory, Normative Safety, and Ambient Self-Perception
Pith reviewed 2026-05-10 19:06 UTC · model grok-4.3
The pith
Springdrift runtime lets LLM agents maintain cross-session context, diagnose their own bugs, and reconstruct decisions through auditable persistence and ambient self-perception.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
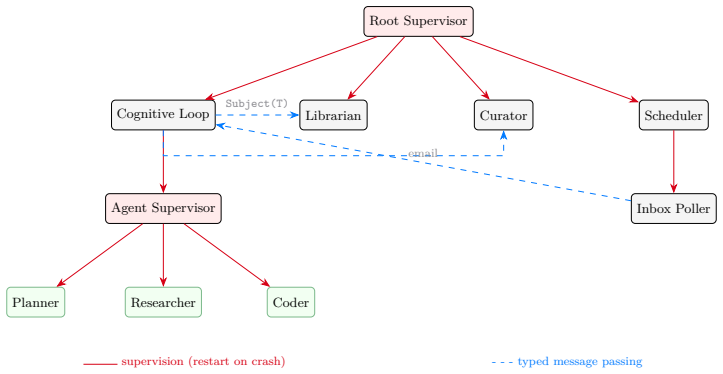
Springdrift integrates an auditable execution substrate using append-only memory and supervised processes with git-backed recovery, a case-based reasoning memory layer with hybrid retrieval, a deterministic normative calculus for safety gating that produces auditable axiom trails, and continuous ambient self-perception through a structured sensorium representation injected each cycle without requiring tool calls. These elements together support cross-session task continuity, cross-channel context maintenance, end-to-end forensic reconstruction of decisions, and self-diagnostic behaviour. In a single-instance deployment spanning 23 days and 19 operating days, the agent diagnosed its own bugs,
What carries the argument
The Springdrift runtime that combines append-only memory, case-based hybrid retrieval, deterministic normative calculus with axiom trails, and a sensorium for ambient self-perception to sustain long-lived agent operation.
If this is right
- LLM agents gain the ability to continue tasks and maintain context across separate sessions and communication channels without reset.
- All agent decisions become reconstructible end-to-end through append-only logs and traceable normative axiom trails.
- Agents can perform self-diagnosis of infrastructure bugs and failure modes without explicit human prompts.
- Safety constraints can be enforced through a deterministic calculus whose reasoning steps remain fully auditable.
- The design supports a category of persistent systems termed Artificial Retainers that operate with bounded autonomy in ongoing relationships.
Where Pith is reading between the lines
- If the architecture generalizes beyond one instance, it could lower the human oversight needed for multi-day autonomous tasks by letting agents handle their own continuity and basic troubleshooting.
- The same combination of auditable memory and self-perception might transfer to domains that demand high accountability, such as automated compliance or personal data management agents.
- Replicating the deployment with varied operators or task domains would help separate the contribution of the core features from implementation details.
Load-bearing premise
The self-diagnostic and context-maintenance behaviors seen in this one 23-day run with a single operator are caused mainly by the listed architectural features rather than by specific code choices, operator guidance, or chance.
What would settle it
Deploy a comparable LLM agent for a similar multi-week period without the case-based memory layer, normative calculus, or sensorium injection and check whether self-diagnosis of infrastructure bugs and unaided cross-channel continuity still appear at the same rate.
Figures



read the original abstract
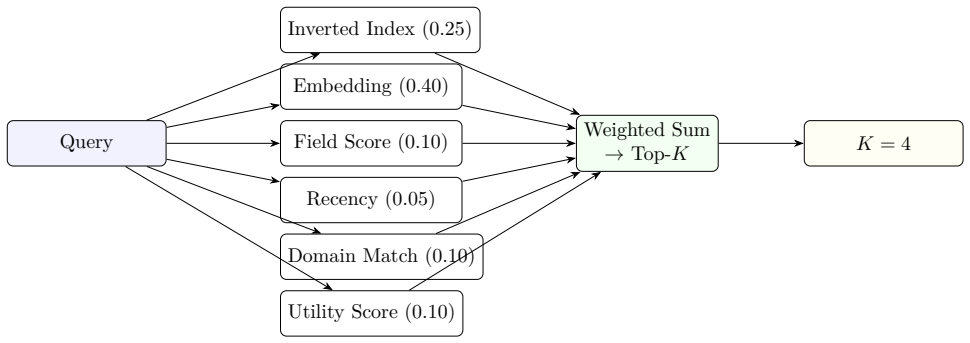
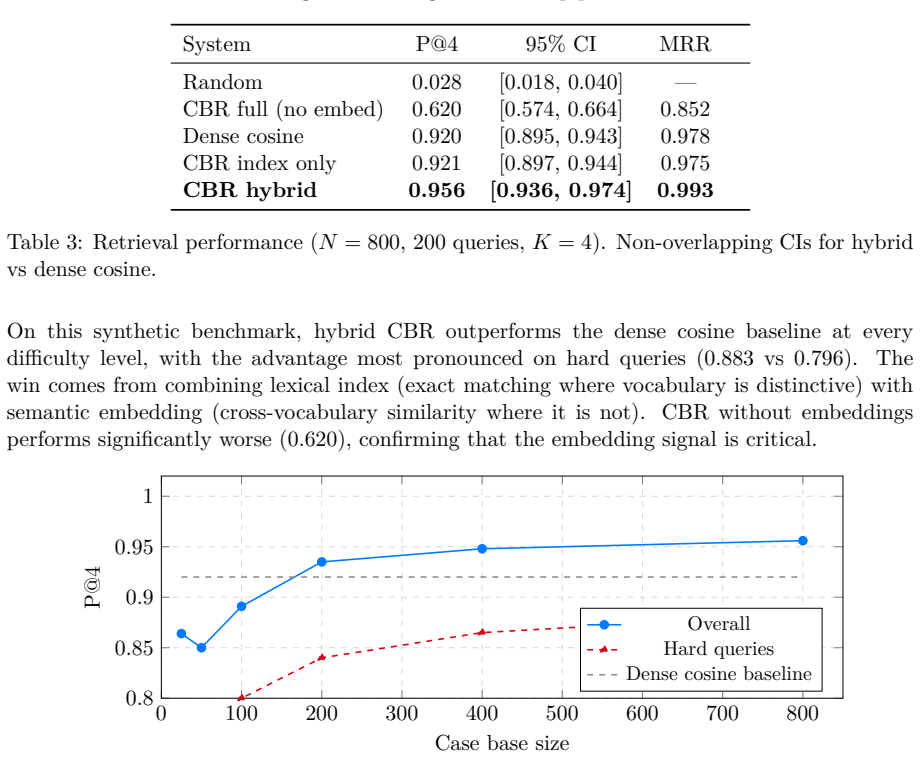
We present Springdrift, a persistent runtime for long-lived LLM agents. The system integrates an auditable execution substrate (append-only memory, supervised processes, git-backed recovery), a case-based reasoning memory layer with hybrid retrieval (evaluated against a dense cosine baseline), a deterministic normative calculus for safety gating with auditable axiom trails, and continuous ambient self-perception via a structured self-state representation (the sensorium) injected each cycle without tool calls. These properties support behaviours difficult to achieve in session-bounded systems: cross-session task continuity, cross-channel context maintenance, end-to-end forensic reconstruction of decisions, and self-diagnostic behaviour. We report on a single-instance deployment over 23 days (19 operating days), during which the agent diagnosed its own infrastructure bugs, classified failure modes, identified an architectural vulnerability, and maintained context across email and web channels -- without explicit instruction. We introduce the term Artificial Retainer for this category: a non-human system with persistent memory, defined authority, domain-specific autonomy, and forensic accountability in an ongoing relationship with a specific principal -- distinguished from software assistants and autonomous agents, drawing on professional retainer relationships and the bounded autonomy of trained working animals. This is a technical report on a systems design and deployment case study, not a benchmark-driven evaluation. Evidence is from a single instance with a single operator, presented as illustration of what these architectural properties can support in practice. Implemented in approximately Gleam on Erlang/OTP. Code, artefacts, and redacted operational logs will be available at https://github.com/seamus-brady/springdrift upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Springdrift, a persistent runtime for LLM agents featuring an auditable append-only memory substrate, case-based hybrid retrieval memory (compared to a cosine baseline), deterministic normative safety calculus with axiom trails, and ambient self-perception through continuous injection of a structured self-state sensorium. It reports on a 23-day single-instance deployment with one operator, during which the agent performed self-diagnosis of infrastructure bugs, failure mode classification, architectural vulnerability identification, and cross-channel context maintenance without explicit instructions. The work proposes the 'Artificial Retainer' concept for such systems and emphasizes that this is a descriptive case study rather than a quantitative benchmark evaluation, with code and logs to be released on GitHub.
Significance. If the behaviors observed in the deployment can be reliably linked to the proposed architectural features, the paper offers a valuable systems-level contribution to the design of long-lived, accountable LLM agents. The emphasis on auditability, forensic reconstruction, and normative safety addresses important practical concerns in deploying persistent agents. The open release of code and artefacts would allow the community to build upon this work. However, the single-instance nature limits the ability to generalize or confirm the causal role of the design choices.
major comments (2)
- [Deployment report (23-day single-instance)] The central illustration relies on attributing self-diagnostic and context-maintenance behaviors to the combination of append-only memory, case-based retrieval, normative calculus, and ambient sensorium. However, no ablation studies, multiple deployments, or detailed comparisons (beyond a brief cosine baseline mention) are provided to rule out contributions from the base LLM, specific Gleam/Erlang implementation, operator interactions via channels, or stochastic effects. This weakens the support for the claim that these properties 'support behaviours difficult to achieve in session-bounded systems'.
- [Abstract and introduction of Artificial Retainer] The distinction of 'Artificial Retainer' from software assistants and autonomous agents is conceptually interesting but lacks a formal definition or comparison table that would clarify the boundaries, especially regarding 'defined authority' and 'forensic accountability'.
minor comments (3)
- [Abstract] The hybrid retrieval is said to be 'evaluated against a dense cosine baseline' but no quantitative results, such as retrieval accuracy or latency metrics, are reported in the provided summary or abstract.
- [Implementation] Details on how the sensorium is structured and injected each cycle without tool calls would benefit from a diagram or pseudocode example to illustrate the ambient self-perception mechanism.
- [Overall] The manuscript would benefit from a dedicated limitations section that explicitly discusses potential alternative explanations for the observed behaviors.
Simulated Author's Rebuttal
We thank the referee for their constructive review and positive recommendation for minor revision. We address each major comment below with point-by-point responses, indicating planned changes to the manuscript.
read point-by-point responses
-
Referee: [Deployment report (23-day single-instance)] The central illustration relies on attributing self-diagnostic and context-maintenance behaviors to the combination of append-only memory, case-based retrieval, normative calculus, and ambient sensorium. However, no ablation studies, multiple deployments, or detailed comparisons (beyond a brief cosine baseline mention) are provided to rule out contributions from the base LLM, specific Gleam/Erlang implementation, operator interactions via channels, or stochastic effects. This weakens the support for the claim that these properties 'support behaviours difficult to achieve in session-bounded systems'.
Authors: We acknowledge that the single-instance deployment does not permit ablation studies or controlled comparisons to isolate causal contributions. The manuscript already positions the work explicitly as a descriptive case study rather than a benchmark evaluation, stating in the abstract that 'Evidence is from a single instance with a single operator, presented as illustration of what these architectural properties can support in practice.' We will expand the limitations and discussion sections to address potential confounding factors from the base LLM, the Gleam/Erlang substrate, channel-based operator interactions, and stochastic effects, while tempering claims about support for behaviors in session-bounded systems to reflect the illustrative nature of the observations. revision: partial
-
Referee: [Abstract and introduction of Artificial Retainer] The distinction of 'Artificial Retainer' from software assistants and autonomous agents is conceptually interesting but lacks a formal definition or comparison table that would clarify the boundaries, especially regarding 'defined authority' and 'forensic accountability'.
Authors: We agree that greater formalization would improve clarity. We will add a concise formal definition of the Artificial Retainer in the introduction and include a comparison table that explicitly contrasts it with software assistants and autonomous agents along the dimensions of persistent memory, defined authority, domain-specific autonomy, and forensic accountability, drawing directly from the distinctions already described in the manuscript. revision: yes
- Ablation studies, multiple deployments, or statistical comparisons to establish causal links between architectural features and observed behaviors, as these would require new experimental work outside the scope of the current single-instance case study.
Circularity Check
No circularity in derivation chain; paper is a descriptive case study without equations or predictions
full rationale
The paper presents a systems architecture for an LLM agent runtime and reports observations from a single 23-day deployment case study. No mathematical derivations, equations, fitted parameters, or predictive claims appear in the provided text or abstract. System behaviors (self-diagnosis, context maintenance) are attributed directly to the listed architectural features (append-only memory, case-based retrieval, normative calculus, sensorium injection) as design consequences, without reducing any result to a quantity defined by prior fitted values or self-referential equations. The new term 'Artificial Retainer' is introduced as a definitional category distinction, not a derived result. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The work is explicitly labeled a technical report and illustration rather than a controlled evaluation or formal derivation, rendering the circularity patterns inapplicable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Erlang/OTP supervised processes and git provide reliable recovery for long-running systems
invented entities (1)
-
Artificial Retainer
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
deterministic normative calculus... six Becker-inspired axioms... eight floor rules... 14-tier priority hierarchy
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
sensorium... structured self-state... injected each cycle
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Agentic Coding Needs Proactivity, Not Just Autonomy
Coding agents require a three-level proactivity taxonomy (Reactive, Scheduled, Situation Aware) evaluated by insight policy quality using Insight Decision Quality, Context Grounding Score, and Learning Lift.
-
Decision Evidence Maturity Model for Agentic AI: A Property-Level Method Specification
DEMM defines four executable evidence-sufficiency categories plus a conflicting category for agentic AI decisions and rolls per-property verdicts into a five-level maturity rubric.
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
Anthropic. On “emotion” concepts in AI models: Function without feeling, 2026a. URLhttps: //www.anthropic.com/research/emotion-concepts-function. Anthropic Research Blog. Anthropic. “emotion” concepts in AI models, 2026b. URLhttps://transformer-circuits. pub/2026/emotions/index.html. Transformer Circuits Thread. Yuntao Bai et al. Constitutional AI: Harmle...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
arXiv preprint arXiv:2603.15381 , year =
URLhttps://gleam.run. Emmanuel Dupoux, Yann LeCun, and Jitendra Malik. Why AI systems don’t learn and what to do about it: Lessons on autonomous learning from cognitive science.arXiv preprint arXiv:2603.15381,
-
[3]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Wenyue Hua et al. ACE: Adaptive curation and evaluation for reflective agents.arXiv preprint arXiv:2510.04618,
work page internal anchor Pith review arXiv
-
[4]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis et al. Retrieval-augmented generation for knowledge-intensive NLP tasks.arXiv preprint arXiv:2005.11401,
work page internal anchor Pith review arXiv 2005
-
[5]
Training language models to follow instructions with human feedback
URLhttps://crewai.com. Long Ouyang et al. Training language models to follow instructions with human feedback.arXiv preprint arXiv:2203.02155,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
MemGPT: Towards LLMs as Operating Systems
38 Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.arXiv preprint arXiv:2303.11366,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu et al. AutoGen: Enabling next-gen LLM applications via multi-agent conversation. arXiv preprint arXiv:2308.08155,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Memento: Fine-tuning LLM agents without fine-tuning LLMs.arXiv, 2025
Wangchunshu Zhou et al. Memento: Fine-tuning LLM agents without fine-tuning LLMs.arXiv preprint arXiv:2508.16153,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.