Recognition: no theorem link
GPIR: Enabling Practical Private Information Retrieval with GPUs
Pith reviewed 2026-05-10 19:54 UTC · model grok-4.3
The pith
GPIR makes private database queries practical on GPUs by redesigning kernels and data layouts to cut memory traffic and reach up to 297 times higher throughput than prior GPU systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
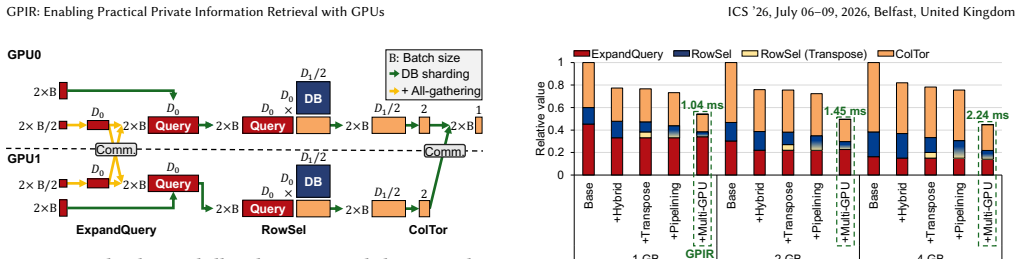
GPIR is a GPU PIR implementation built around a stage-aware hybrid execution model that switches between separate kernels for each primitive and fused kernels that keep all operations of a stage on-chip, paired with a transposed data layout and fine-grained pipelining for the RowSel matrix multiplications. The same design extends to multi-GPU configurations with negligible communication cost. On the evaluated hardware these techniques produce up to 297.2 times the throughput of the previous best GPU PIR system.
What carries the argument
The stage-aware hybrid execution model that fuses all operations inside each PIR phase into single kernels for on-chip reuse, together with the transposed-layout pipelining that aligns RowSel GEMMs to the surrounding NTT-driven data layout.
If this is right
- Multi-client PIR becomes feasible on both single and multi-GPU servers without the memory-traffic penalty that previously limited batch size.
- Database capacity can be increased in proportion to the number of GPUs while communication overhead remains negligible.
- The same kernel-fusion and layout techniques apply directly to any lattice-based protocol that alternates NTTs with large independent matrix multiplications.
- Practical deployment of private queries becomes realistic for cloud services that already have GPU clusters.
Where Pith is reading between the lines
- Similar hybrid scheduling could improve other GPU-heavy cryptographic workloads that suffer from working-set explosion under batching.
- The transposed-layout idea suggests that domain-specific data rearrangements may be a general lever for unlocking hardware acceleration in privacy protocols.
- Testing the same design on newer GPU generations with larger on-chip caches would reveal whether the gains widen or shift to different bottlenecks.
- Widespread adoption would lower the barrier to private queries in applications such as medical or financial record access.
Load-bearing premise
The hybrid execution model and transposed pipelining will actually remove the excess DRAM traffic caused by batching without introducing correctness errors or new performance limits that appear only at full implementation scale.
What would settle it
Measure DRAM bandwidth utilization and end-to-end throughput on the target GPU while varying client batch size; if the measured traffic stays high or throughput fails to scale as predicted, the central performance claim does not hold.
Figures







read the original abstract
Private information retrieval (PIR) allows private database queries; however, it is hindered by intense server-side computation and memory traffic. Numerous modern lattice-based PIR protocols consist of three phases: ExpandQuery (expanding a query into encrypted indices), RowSel (encrypted row selection), and ColTor (recursive "column tournament" for final selection). ExpandQuery and ColTor primarily perform number-theoretic transforms (NTTs), whereas RowSel reduces to large-scale independent matrix-matrix multiplications (GEMMs). GPUs are well suited for these tasks when combined with multi-client batching, which is necessary for high throughput. However, batching fundamentally reshapes the performance bottlenecks: while it amortizes database access costs, it expands working sets beyond the L2 cache capacity, causing divergent memory access behavior and excessive DRAM traffic. We present GPIR, a GPU-accelerated PIR system that rethinks kernel design, data layout, and execution scheduling. We introduce a stage-aware hybrid execution model that dynamically switches between operation-level kernels, which execute each primitive operation separately, and stage-level kernels, which fuse all operations within a stage into a single kernel to maximize on-chip data reuse. For RowSel, we resolve the mismatch between NTT-driven layouts and tiled GEMMs using a transposed-layout design with fine-grained pipelining. We further extend GPIR to multi-GPU systems, scaling throughput and database capacity with negligible communication overhead. GPIR achieves up to 297.2x higher throughput than PIRonGPU, the state-of-the-art GPU implementation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents GPIR, a GPU-accelerated implementation of lattice-based PIR that optimizes the three phases (ExpandQuery via NTTs, RowSel via GEMMs, ColTor via NTTs) through a stage-aware hybrid execution model (switching between operation-level and stage-level fused kernels) and a transposed-layout pipelining scheme for RowSel to reduce DRAM traffic under multi-client batching. It claims up to 297.2x throughput improvement over PIRonGPU and demonstrates multi-GPU scaling with low communication cost.
Significance. If the performance results are reproducible with full experimental details, the work could meaningfully advance practical server-side PIR by addressing batch-induced memory bottlenecks on GPUs, enabling higher throughput for privacy-preserving queries. The hybrid scheduling and layout optimizations represent a concrete systems contribution that could be adopted in other NTT/GEMM-heavy cryptographic workloads.
major comments (3)
- [§5] §5 (Performance Evaluation): The central claim of up to 297.2x higher throughput versus PIRonGPU is presented without any description of benchmark methodology, database sizes, batch sizes, security parameters (e.g., ring dimension, modulus), error bars, or ablation studies isolating the hybrid model and transposed pipelining; this prevents verification of the speedup and attribution to the proposed techniques.
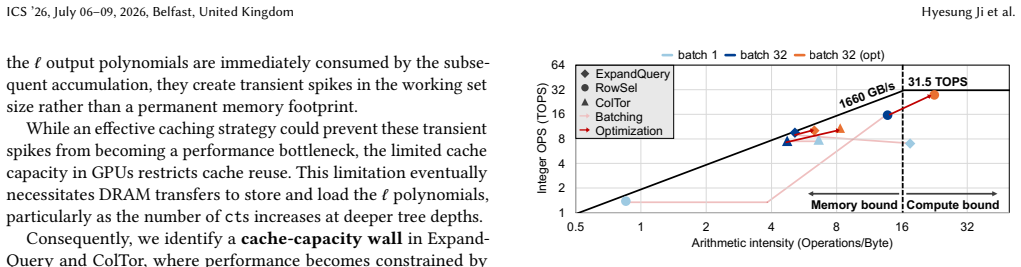
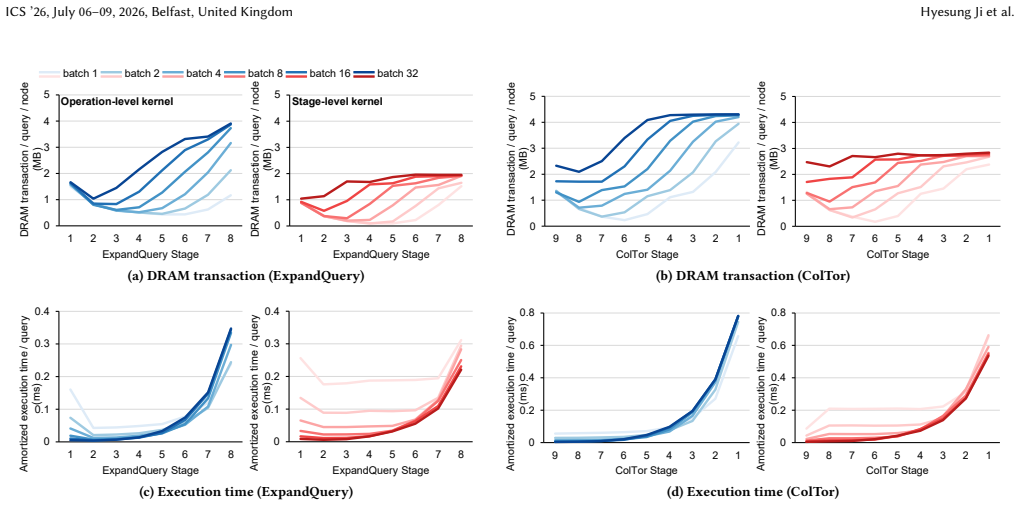
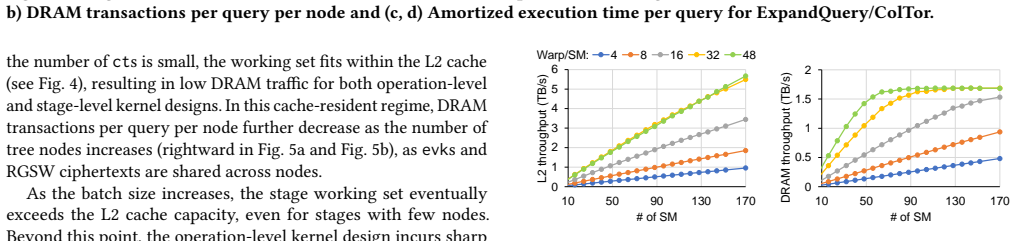
- [§3.2] §3.2 (Stage-aware Hybrid Execution Model): The assertion that stage-level kernels eliminate excess DRAM traffic by keeping intermediates on-chip lacks any quantitative memory-access analysis, cache-miss profiling, or working-set size measurements to confirm that fusion succeeds when batching expands data beyond L2 capacity.
- [§3.3] §3.3 (Transposed-layout Pipelining for RowSel): No pseudocode, kernel launch configuration, or arithmetic error analysis is supplied for the fine-grained NTT-GEMM pipelining; it is therefore unclear whether the layout transposition preserves NTT/GEMM semantics or merely shifts bandwidth bottlenecks.
minor comments (2)
- [Figure 2] Figure 2: The execution timeline diagram would be clearer with explicit annotations for on-chip data reuse points and DRAM access phases.
- [§4] §4 (Multi-GPU Extension): The communication overhead claim would benefit from a table showing scaling efficiency across different GPU counts and database partitions.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments highlight areas where additional details will improve clarity and verifiability. We will revise the manuscript to incorporate expanded experimental methodology, quantitative memory analysis, and implementation pseudocode. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [§5] §5 (Performance Evaluation): The central claim of up to 297.2x higher throughput versus PIRonGPU is presented without any description of benchmark methodology, database sizes, batch sizes, security parameters (e.g., ring dimension, modulus), error bars, or ablation studies isolating the hybrid model and transposed pipelining; this prevents verification of the speedup and attribution to the proposed techniques.
Authors: We agree that Section 5 requires more explicit experimental details to support reproducibility. In the revised manuscript we will add a dedicated 'Benchmark Methodology' subsection that specifies: database sizes (2^20 to 2^24 entries), batch sizes (1–4096 concurrent clients), security parameters (ring dimension N=4096, modulus q≈2^32, error distribution), hardware (NVIDIA A100 80 GB GPUs), number of runs (minimum 5) with standard deviation error bars, and the exact PIRonGPU baseline configuration used for the 297.2× result. We will also include ablation studies that isolate the contribution of the stage-aware hybrid scheduler versus pure operation-level kernels and the transposed-layout pipelining versus standard row-major layouts. revision: yes
-
Referee: [§3.2] §3.2 (Stage-aware Hybrid Execution Model): The assertion that stage-level kernels eliminate excess DRAM traffic by keeping intermediates on-chip lacks any quantitative memory-access analysis, cache-miss profiling, or working-set size measurements to confirm that fusion succeeds when batching expands data beyond L2 capacity.
Authors: We acknowledge the need for quantitative backing. The revision will augment §3.2 with memory-access analysis derived from NVIDIA Nsight Compute traces. We will report DRAM transaction counts, L2 cache miss rates, and working-set sizes for representative batch sizes, demonstrating that stage-level fusion reduces DRAM traffic by keeping intermediate NTT outputs within on-chip memory when the batched working set exceeds L2 capacity. These measurements will be presented alongside the throughput results to directly attribute the observed gains to reduced memory traffic. revision: yes
-
Referee: [§3.3] §3.3 (Transposed-layout Pipelining for RowSel): No pseudocode, kernel launch configuration, or arithmetic error analysis is supplied for the fine-grained NTT-GEMM pipelining; it is therefore unclear whether the layout transposition preserves NTT/GEMM semantics or merely shifts bandwidth bottlenecks.
Authors: We will add pseudocode (Algorithm X) and kernel launch parameters (thread-block size 256, grid dimensions derived from batch size and matrix dimensions) to §3.3. The description will clarify that the transposed layout is a pure reordering of data that preserves the algebraic semantics of both NTT and GEMM; the operations remain mathematically identical and incur no additional rounding error beyond the original fixed-point arithmetic. We will also include a short arithmetic-error bound analysis confirming that the pipelined schedule does not alter the final PIR result. revision: yes
Circularity Check
No circularity in empirical GPU systems optimization
full rationale
The paper describes concrete engineering techniques (stage-aware hybrid kernels, transposed-layout pipelining for RowSel, multi-GPU scaling) and reports measured throughput numbers against an external baseline (PIRonGPU). No equations, fitted parameters, or first-principles derivations are presented whose outputs reduce to the inputs by construction. Performance claims are external benchmark comparisons rather than self-referential predictions or self-citation chains. The work is self-contained as an implementation artifact whose validity rests on reproducible code and hardware measurements, not on any load-bearing internal definition or renaming.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GPU memory hierarchy and kernel launch overheads behave as described in vendor documentation and prior systems literature.
Reference graph
Works this paper leans on
-
[1]
Carlos Aguilar-Melchor, Joris Barrier, Laurent Fousse, and Marc-Olivier Killijian
-
[2]
XPIR: Private Information Retrieval for Everyone.Proceedings on Privacy Enhancing Technologies(2016), 155–174. doi:10.1515/popets-2016-0010
-
[3]
Ishtiyaque Ahmad, Yuntian Yang, Divyakant Agrawal, Amr El Abbadi, and Trin- abh Gupta. 2021. Addra: Metadata-private Voice Communication over Fully Un- trusted Infrastructure. InUSENIX Symposium on Operating Systems Design and Im- plementation. 313–329. https://www.usenix.org/conference/osdi21/presentation/ ahmad
2021
-
[4]
Asra Ali, Tancrède Lepoint, Sarvar Patel, Mariana Raykova, Phillipp Schoppmann, Karn Seth, and Kevin Yeo. 2021. Communication–Computation Trade-offs in PIR. InUSENIX Security Symposium. 1811–1828. https://www.usenix.org/conference/ usenixsecurity21/presentation/ali
2021
-
[5]
Sebastian Angel, Hao Chen, Kim Laine, and Srinath Setty. 2018. PIR with Com- pressed Queries and Amortized Query Processing. InIEEE Symposium on Security and Privacy. 962–979. doi:10.1109/SP.2018.00062
-
[6]
Jean-Philippe Bossuat, Rosario Cammarota, Jung Hee Cheon, Ilaria Chillotti, Benjamin R. Curtis, Wei Dai, Huijing Gong, Erin Hales, Duhyeong Kim, Bryan Kumara, Changmin Lee, Xianhui Lu, Carsten Maple, Alberto Pedrouzo-Ulloa, Rachel Player, Luis Antonio Ruiz Lopez, Yongsoo Song, Donggeon Yhee, and Bahattin Yildiz. 2024. Security Guidelines for Implementing ...
2024
-
[7]
Zvika Brakerski. 2012. Fully Homomorphic Encryption without Modulus Switching from Classical GapSVP. InAnnual Cryptology Conference. 868–886. doi:10.1007/978-3-642-32009-5_50
-
[8]
Brechy. 2025. Ethereum Privacy: Private Information Retrieval. https://pse.dev/ blog/ethereum-privacy-pir
2025
-
[9]
Alexander Burton, Samir Jordan Menon, and David J. Wu. 2024. Respire: High- Rate PIR for Databases with Small Records. InACM SIGSAC Conference on Computer and Communications Security (CCS). 1463–1477. doi:10.1145/3658644. 3690328
-
[10]
Yue Chen and Ling Ren. 2025. OnionPIRv2: Efficient Single-Server PIR.IACR Cryptology ePrint Archive(2025). https://eprint.iacr.org/2025/1142
2025
-
[11]
Zehao Chen, Zhaoyan Shen, Qian Wei, Hang Lu, and Lei Ju. 2026. Conflux: A High-Performance Keyword Private Retrieval System for Dynamic Datasets. InIEEE International Symposium on High Performance Computer Architecture (HPCA). 1–14. doi:10.1109/HPCA68181.2026.11408617
-
[12]
Zehao Chen, Honghui You, Qian Wei, Hang Lu, Lei Ju, and Zhaoyan Shen. 2025. SmartPIR: A Private Information Retrieval System using Computational Storage Devices. InIEEE/ACM International Symposium on Microarchitecture (MICRO). 1749–1762. doi:10.1145/3725843.3756060
-
[13]
Ilaria Chillotti, Nicolas Gama, Mariya Georgieva, and Malika Izabachène. 2020. TFHE: Fast Fully Homomorphic Encryption over the Torus.Journal of Cryptology 33 (2020), 34–91. doi:10.1007/s00145-019-09319-x
-
[14]
Wonseok Choi, Hyunah Yu, Jongmin Kim, Hyesung Ji, Jaiyoung Park, and Jung Ho Ahn. 2026. Theodosian: A Deep Dive into Memory-Hierarchy-Centric FHE Acceleration. InIEEE International Symposium on Performance Analysis of Systems and Software (ISPASS)
2026
-
[15]
Benny Chor, Eyal Kushilevitz, Oded Goldreich, and Madhu Sudan. 1998. Private Information Retrieval.J. ACM45, 6 (1998), 965–981. doi:10.1145/293347.293350
-
[16]
Ali Şah Özcan. 2024. PIRonGPU. https://github.com/Alisah-Ozcan/PIRonGPU
2024
-
[17]
Ali Şah Özcan and Erkay Savaş. 2024. HEonGPU: a GPU-based Fully Ho- momorphic Encryption Library 1.0.IACR Cryptology ePrint Archive(2024). https://eprint.iacr.org/2024/1543
2024
-
[18]
Xiang Cui, Yifeng Chen, Changyou Zhang, and Hong Mei. 2010. Auto-tuning Dense Matrix Multiplication for GPGPU with Cache. InIEEE 16th International Conference on Parallel and Distributed Systems. 237–242. doi:10.1109/ICPADS. 2010.64
-
[19]
Humble, Alexander McCaskey, Dmitry I
William J. Dally, Stephen W. Keckler, and David B. Kirk. 2021. Evolution of the Graphics Processing Unit (GPU).IEEE Micro41, 6 (2021), 42–51. doi:10.1109/MM. 2021.3113475
work page doi:10.1109/mm 2021
-
[20]
Alex Davidson, Gonçalo Pestana, and Sofía Celi. 2023. FrodoPIR: Simple, Scalable, Single-Server Private Information Retrieval.Proceedings on Privacy Enhancing Technologies(2023), 365–383. doi:10.56553/popets-2023-0022
-
[21]
Leo de Castro, Kevin Lewi, and Edward Suh. 2024. WhisPIR: Stateless Private Information Retrieval with Low Communication.IACR Cryptology ePrint Archive (2024). https://eprint.iacr.org/2024/266
2024
-
[22]
Junfeng Fan and Frederik Vercauteren. 2012. Somewhat Practical Fully Homo- morphic Encryption.IACR Cryptology ePrint Archive(2012). https://eprint.iacr. org/2012/144
2012
-
[23]
Craig Gentry. 2009. Fully Homomorphic Encryption Using Ideal Lattices. InACM Symposium on Theory of Computing. 169–178. doi:10.1145/1536414.1536440
-
[24]
Craig Gentry, Shai Halevi, and Nigel P. Smart. 2012. Homomorphic Evaluation of the AES Circuit. InAnnual International Conference on the Theory and Applications of Cryptographic Techniques. 850–867. doi:10.1007/978-3-642-32009-5_49
-
[25]
Craig Gentry, Amit Sahai, and Brent Waters. 2013. Homomorphic Encryp- tion from Learning with Errors: Conceptually-Simpler, Asymptotically-Faster, Attribute-Based. InAnnual International Cryptology Conference. 75–92. doi:10. 1007/978-3-642-40041-4_5
2013
-
[26]
Daniel Günther, Maurice Heymann, Benny Pinkas, and Thomas Schneider. 2022. GPU-accelerated PIR with Client-Independent Preprocessing for Large-Scale Applications. InUSENIX Security Symposium. 1759–1776. https://www.usenix. org/conference/usenixsecurity22/presentation/gunther
2022
-
[27]
Shai Halevi, Yuriy Polyakov, and Victor Shoup. 2019. An improved RNS variant of the BFV homomorphic encryption scheme. InCryptographers’ Track at the RSA Conference. 83–105. doi:10.1007/978-3-030-12612-4_5
-
[28]
Hong, Henry Corrigan-Gibbs, Sarah Meik- lejohn, and Vinod Vaikuntanathan
Alexandra Henzinger, Matthew M. Hong, Henry Corrigan-Gibbs, Sarah Meik- lejohn, and Vinod Vaikuntanathan. 2023. One Server for the Price of Two: Simple and Fast Single-Server Private Information Retrieval. InUSENIX Security Symposium. 3889–3905. https://www.usenix.org/conference/usenixsecurity23/ presentation/henzinger
2023
-
[29]
Hyesung Ji, Sangpyo Kim, Jaewan Choi, and Jung Ho Ahn. 2024. Accelerating Programmable Bootstrapping Targeting Contemporary GPU Microarchitecture. IEEE Computer Architecture Letters(2024). doi:10.1109/LCA.2024.3418448
-
[30]
Wonkyung Jung, Eojin Lee, Sangpyo Kim, Jongmin Kim, Namhoon Kim, Keewoo Lee, Chohong Min, Jung Hee Cheon, and Jung Ho Ahn. 2021. Accelerating Fully Homomorphic Encryption Through Architecture-Centric Analysis and Optimization.IEEE Access9 (2021), 98772–98789. doi:10.1109/ACCESS.2021. 3096189
-
[31]
Andrew Kerr, Duane Merrill, Julien Demouth, and John Tran. 2017. CUTLASS: Fast Linear Algebra in CUDA C++. https://developer.nvidia.com/blog/cutlass- linear-algebra-cuda
2017
-
[32]
Jaeseon Kim, Jeongeun Park, and Hyewon Sung. 2025. Private Information Retrieval based on Homomorphic Encryption, Revisited.IACR Cryptology ePrint Archive(2025). https://eprint.iacr.org/2025/729
2025
-
[33]
Sangpyo Kim, Hyesung Ji, Jongmin Kim, Wonseok Choi, Jaiyoung Park, and Jung Ho Ahn. 2026. IVE: An Accelerator for Single-Server Private Information Retrieval Using Versatile Processing Elements. InIEEE International Symposium on High Performance Computer Architecture (HPCA). 1–15. doi:10.1109/HPCA68181. 2026.11408461
-
[34]
Lee, Vijay Janapa Reddi, Gu-Yeon Wei, David Brooks, and G
Maximilian Lam, Jeff Johnson, Wenjie Xiong, Kiwan Maeng, Udit Gupta, Yang Li, Liangzhen Lai, Ilias Leontiadis, Minsoo Rhu, Hsien-Hsin S. Lee, Vijay Janapa Reddi, Gu-Yeon Wei, David Brooks, and G. Edward Suh. 2024. GPU-based Pri- vate Information Retrieval for On-Device Machine Learning Inference. InACM International Conference on Architectural Support for...
-
[35]
Ang Li, Shuaiwen Leon Song, Jieyang Chen, Jiajia Li, Xu Liu, Nathan R. Tallent, and Kevin J. Barker. 2020. Evaluating Modern GPU Interconnect: PCIe, NVLink, NV-SLI, NVSwitch and GPUDirect.IEEE Transactions on Parallel and Distributed Systems31 (2020), 94–110. doi:10.1109/TPDS.2019.2928289
-
[36]
Baiyu Li, Daniele Micciancio, Mariana Raykova, and Mark Schultz-Wu. 2024. Hintless Single-Server Private Information Retrieval. InAnnual International Cryptology Conference. 183–217. doi:10.1007/978-3-031-68400-5_6
-
[37]
Xiuhong Li, Yun Liang, Shengen Yan, Liancheng Jia, and Yinghan Li. 2019. A coordinated tiling and batching framework for efficient GEMM on GPUs. InACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. 229–241. doi:10.1145/3293883.3295734
-
[38]
Jilan Lin, Ling Liang, Zheng Qu, Ishtiyaque Ahmad, Liu Liu, Fengbin Tu, Trinabh Gupta, Yufei Ding, and Yuan Xie. 2022. INSPIRE: In-storage Private Information Retrieval via Protocol and Architecture Co-design. InInternational Symposium on Computer Architecture (ISCA). 102–115. doi:10.1145/3470496.3527433
-
[39]
Chenyang Liu, Xukun Wang, and Zhifang Zhang. 2026. VIA: Communication- Efficient Single-Server Private Information Retrieval. InIEEE Symposium on Security and Privacy. 1616–1634. doi:10.1109/SP63933.2026.00086
-
[40]
Ming Luo, Feng-Hao Liu, and Han Wang. 2024. Faster FHE-Based Single-Server Private Information Retrieval. InACM SIGSAC Conference on Computer and Communications Security (CCS). 1405–1419. doi:10.1145/3658644.3690233
-
[41]
Rasoul Akhavan Mahdavi, Sarvar Patel, Joon Young Seo, and Kevin Yeo. 2025. InsPIRe: Communication-Efficient PIR with Server-side Preprocessing.IACR Cryptology ePrint Archive(2025). https://eprint.iacr.org/2025/1352
2025
-
[42]
Samir Jordan Menon and David J. Wu. 2022. SPIRAL: Fast, High-Rate Single- Server PIR via FHE Composition. InIEEE Symposium on Security and Privacy. 930–947. doi:10.1109/SP46214.2022.9833700
-
[43]
Samir Jordan Menon and David J. Wu. 2024. YPIR: High-Throughput Single- Server PIR with Silent Preprocessing. InUSENIX Security Symposium. 5985–6002. https://www.usenix.org/conference/usenixsecurity24/presentation/menon
2024
-
[44]
Muhammad Haris Mughees, Hao Chen, and Ling Ren. 2021. OnionPIR: Re- sponse Efficient Single-Server PIR. InACM SIGSAC Conference on Computer and Communications Security (CCS). 2292–2306. doi:10.1145/3460120.3485381
-
[45]
Muhammad Haris Mughees and Ling Ren. 2023. Vectorized Batch Private Information Retrieval. InIEEE Symposium on Security and Privacy. 437–452. doi:10.1109/SP46215.2023.10179329 GPIR: Enabling Practical Private Information Retrieval with GPUs ICS ’26, July 06–09, 2026, Belfast, United Kingdom
-
[46]
NVIDIA Corporation. 2024. NVIDIA GH200 Grace Hopper Superchip. https: //www.nvidia.com/en-us/data-center/grace-hopper-superchip/
2024
-
[47]
NVIDIA Corporation. 2025. Nsight Compute 2025.3. https://developer.nvidia. com/nsight-compute
2025
-
[48]
NVIDIA Corporation. 2025. NVLink and NVSwitch. https://www.nvidia.com/en- us/data-center/nvlink/
2025
-
[49]
NVIDIA Corporation. 2026. CUDA Programming Guide. https://docs.nvidia.com/ cuda/cuda-programming-guide/
2026
-
[50]
Apple Machine Learning Research. 2024. Combining Machine Learning and Homomorphic Encryption in the Apple Ecosystem. https://machinelearning. apple.com/research/homomorphic-encryption
2024
-
[51]
Zihan Wang, Lutan Zhao, Ming Luo, Zhiwei Wang, Haoqi He, Wenzhe Lv, Xuan Ding, Dan Meng, and Rui Hou. 2025. ShiftPIR: An Efficient PIR System with Gravity Shifting from Client to Server. InACM SIGSAC Conference on Computer and Communications Security (CCS). 1143–1157. doi:10.1145/3719027.3765153
-
[52]
Yunming Xiao, Chenkai Weng, Ruijie Yu, Peizhi Liu, Matteo Varvello, and Alek- sandar Kuzmanovic. 2023. Demo: PDNS: A Fully Privacy-Preserving DNS. In ACM SIGCOMM Conference. 1182–1184. doi:10.1145/3603269.3610860
-
[53]
Yongseung Yu, Donghyun Son, Younghyun Lee, Sunghyun Park, Giha Ryu, Myeongjin Cho, Jiwon Seo, and Yongjun Park. 2023. Tailoring CUTLASS GEMM using Supervised Learning. InIEEE 41st International Conference on Computer Design (ICCD). 465–474. doi:10.1109/ICCD58817.2023.00077
-
[54]
Mingxun Zhou, Andrew Park, Wenting Zheng, and Elaine Shi. 2024. Piano: Extremely Simple, Single-Server PIR with Sublinear Server Computation. InIEEE Symposium on Security and Privacy. 4296–4314. doi:10.1109/SP54263.2024.00055
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.