Recognition: 2 theorem links
· Lean TheoremDiscovering Failure Modes in Vision-Language Models using RL
Pith reviewed 2026-05-10 19:17 UTC · model grok-4.3
The pith
An RL questioner agent automatically uncovers vision-language model blind spots by adapting queries to force errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a Reinforcement Learning-based framework to automatically discover the failure modes or blind spots of any candidate VLM on a given data distribution without human intervention. Our framework trains a questioner agent that adaptively generates queries based on the candidate VLM's responses to elicit incorrect answers, increasing question complexity by focusing on fine-grained visual details and distinct skill compositions as training progresses.
What carries the argument
The RL-trained questioner agent that conditions new queries on the candidate VLM's previous answers to drive progressive increases in query complexity and error elicitation.
If this is right
- VLMs exhibit previously undocumented weaknesses in skill compositions that become visible only through adaptive, escalating probes.
- The same framework applies across different VLM candidates without retraining the questioner from scratch.
- Failure mode discovery no longer depends on human-selected test cases or salient-object bias.
- Models can be ranked and improved by the specific failure modes the agent surfaces on a shared distribution.
Where Pith is reading between the lines
- The approach could be extended to other modalities or model types by swapping the candidate and keeping the questioner structure.
- Discovered modes might guide targeted data collection or fine-tuning to close specific gaps rather than broad retraining.
- If the questioner generalizes well, it could serve as a standard diagnostic tool run before deploying VLMs in new domains.
Load-bearing premise
The generated questions reveal genuine, generalizable model failures instead of artifacts created by the questioner's own training biases or limited data distribution.
What would settle it
Running the discovered failure modes on held-out image-question pairs or with human raters shows that the errors disappear or that random non-adaptive queries find the same modes at similar rates.
Figures





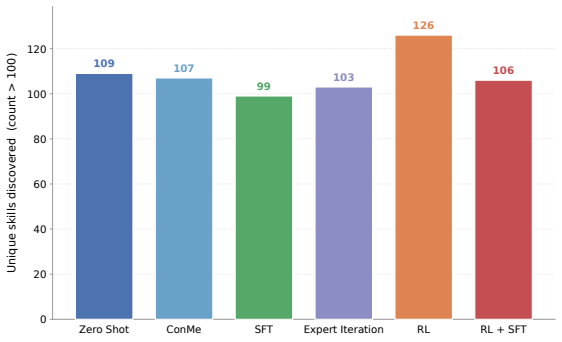




read the original abstract
Vision-language Models (VLMs), despite achieving strong performance on multimodal benchmarks, often misinterpret straightforward visual concepts that humans identify effortlessly, such as counting, spatial reasoning, and viewpoint understanding. Previous studies manually identified these weaknesses and found that they often stem from deficits in specific skills. However, such manual efforts are costly, unscalable, and subject to human bias, which often overlooks subtle details in favour of salient objects, resulting in an incomplete understanding of a model's vulnerabilities. To address these limitations, we propose a Reinforcement Learning (RL)-based framework to automatically discover the failure modes or blind spots of any ``candidate VLM'' on a given data distribution without human intervention. Our framework trains a questioner agent that adaptively generates queries based on the candidate VLM's responses to elicit incorrect answers. Our approach increases question complexity by focusing on fine-grained visual details and distinct skill compositions as training progresses, consequently identifying novel failure modes in which VLMs struggle. We demonstrate the broad applicability of our framework by showcasing its generalizability across various model combinations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an RL-based framework to automatically discover failure modes in vision-language models (VLMs) by training a questioner agent that adaptively generates queries to elicit incorrect answers from a candidate VLM. The agent increases query complexity over training by focusing on fine-grained visual details and skill compositions, with the goal of identifying novel blind spots (e.g., in counting, spatial reasoning, viewpoint understanding) without human intervention. The authors claim broad applicability by demonstrating generalizability across various model combinations.
Significance. If the generated queries are shown to be semantically coherent and visually grounded, the framework could offer a scalable alternative to manual failure-mode discovery, reducing human bias and enabling systematic exploration of VLM vulnerabilities. The adaptive RL approach represents a potentially useful methodological contribution for automated evaluation of multimodal models.
major comments (3)
- [§3] §3 (RL Framework): The reward is defined solely as the negative of the candidate VLM's accuracy on generated queries, with no explicit term for query validity, naturalness, or distributional similarity to human questions. This leaves open the possibility that the questioner converges on malformed or out-of-distribution prompts that any model would fail, rather than revealing genuine capability deficits. A human validation study or distributional matching loss would be required to substantiate the central claim.
- [§4] §4 (Experiments): While qualitative examples of discovered failure modes are presented, there are no quantitative metrics (e.g., human-rated query coherence scores, comparison of failure-mode coverage against human-identified baselines, or cross-model generalization statistics) that demonstrate the modes are novel and not training artifacts. Ablation on the progressive complexity schedule is also absent.
- [§5] §5 (Generalizability): The claim that the framework works across 'various model combinations' is supported only by a small number of VLM pairs; no statistical analysis or larger-scale transfer experiments are reported to support broad applicability.
minor comments (2)
- [Abstract] The abstract states that the method 'increases question complexity... as training progresses' but the precise mechanism (e.g., curriculum schedule or reward shaping) is not summarized; a one-sentence description would improve clarity.
- [§2] Notation for the questioner policy and VLM response function is introduced without an explicit equation reference in the early sections; adding a compact notation table would aid readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: §3 (RL Framework): The reward is defined solely as the negative of the candidate VLM's accuracy on generated queries, with no explicit term for query validity, naturalness, or distributional similarity to human questions. This leaves open the possibility that the questioner converges on malformed or out-of-distribution prompts that any model would fail, rather than revealing genuine capability deficits. A human validation study or distributional matching loss would be required to substantiate the central claim.
Authors: We acknowledge that the reward function relies solely on the negative accuracy of the candidate VLM and does not include an explicit penalty or reward for query naturalness or distributional alignment with human questions. The questioner is conditioned on the input image and prior responses, which provides some grounding in the visual content and data distribution. However, this does not fully address the concern about potential malformed outputs. In the revised manuscript, we will add a human validation study evaluating the semantic coherence, visual grounding, and naturalness of a sample of generated queries, along with a discussion of how the image-conditioned generation helps mitigate out-of-distribution issues. revision: yes
-
Referee: §4 (Experiments): While qualitative examples of discovered failure modes are presented, there are no quantitative metrics (e.g., human-rated query coherence scores, comparison of failure-mode coverage against human-identified baselines, or cross-model generalization statistics) that demonstrate the modes are novel and not training artifacts. Ablation on the progressive complexity schedule is also absent.
Authors: We agree that quantitative metrics would provide stronger evidence that the discovered failure modes are novel rather than artifacts. The current manuscript emphasizes qualitative examples to illustrate the types of blind spots found. In the revision, we will incorporate human-rated coherence scores for generated queries, a comparison of failure-mode coverage against a human-identified baseline set, and an ablation study removing the progressive complexity schedule to quantify its contribution to discovering more challenging failure modes. revision: yes
-
Referee: §5 (Generalizability): The claim that the framework works across 'various model combinations' is supported only by a small number of VLM pairs; no statistical analysis or larger-scale transfer experiments are reported to support broad applicability.
Authors: The manuscript reports results on multiple representative VLM pairs to illustrate applicability, with consistent patterns in the types of failure modes discovered. We recognize that a larger number of pairs and formal statistical tests would strengthen the generalizability claim. In the revised version, we will add statistical analysis (e.g., variance across pairs) of the existing results and expand the discussion of limitations and scope of applicability. Due to computational constraints, we are unable to run substantially larger-scale transfer experiments within the revision timeline. revision: partial
- Larger-scale transfer experiments across many additional VLM pairs, as expanding the experimental scope significantly exceeds available computational resources for the revision.
Circularity Check
No significant circularity; procedural framework with no self-referential derivations
full rationale
The paper proposes an RL-based procedural framework to train a questioner agent that generates queries eliciting VLM errors, with failure modes identified empirically from the resulting queries and responses. No equations, fitted parameters, or mathematical derivations are described that reduce to their own inputs by construction. The approach relies on standard RL training dynamics rather than any self-definition, fitted-input-as-prediction, or load-bearing self-citation chains. No uniqueness theorems, ansatzes, or renamings of known results are invoked in a circular manner. The central claim of discovering novel failure modes is an empirical outcome of the method, not a tautological reduction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We train the questioner using the Group Relative Policy Optimization (GRPO) algorithm... RQ = λscale·(δemb + δifreq)·VQ·(1−CQ)−λpenalty·(1−VQ)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a pipeline for failure taxonomy construction that categorizes generated questions by the cognitive skills required
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Vqa: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. InProceedings of the IEEE international conference on computer vision, pages 2425–2433, 2015
2015
-
[2]
Whatever next? predictive brains, situated agents, and the future of cognitive science.Behavioral and brain sciences, 36(3):181–204, 2013
Andy Clark. Whatever next? predictive brains, situated agents, and the future of cognitive science.Behavioral and brain sciences, 36(3):181–204, 2013. 18
2013
-
[3]
GRIT: Teaching MLLMs to Think with Images
Yue Fan, Xuehai He, Diji Yang, Kaizhi Zheng, Ching-Chen Kuo, Yuting Zheng, Sravana Jyothi Narayanaraju, Xinze Guan, and Xin Eric Wang. Grit: Teaching mllms to think with images. arXiv preprint arXiv:2505.15879, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
The vendi score: A diversity evaluation metric for machine learning.Transactions on Machine Learning Research, 2023
Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning.Transactions on Machine Learning Research, 2023. ISSN 2835-8856
2023
-
[5]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023
work page internal anchor Pith review arXiv 2023
-
[6]
Ling Fu, Zhebin Kuang, Jiajun Song, Mingxin Huang, Biao Yang, Yuzhe Li, Linghao Zhu, Qidi Luo, Xinyu Wang, Hao Lu, et al. Ocrbench v2: An improved benchmark for evaluating large multimodal models on visual text localization and reasoning.arXiv preprint arXiv:2501.00321, 2024
-
[7]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024
2024
-
[8]
Adver- sarial policies: Attacking deep reinforcement learning.arXiv preprint arXiv:1905.10615,
Adam Gleave, Michael Dennis, Cody Wild, Neel Kant, Sergey Levine, and Stuart Russell. Adversarial policies: Attacking deep reinforcement learning.arXiv preprint arXiv:1905.10615, 2019
-
[9]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18995–19012, 2022
2022
-
[10]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
Maarten Grootendorst. Bertopic: Neural topic modeling with a class-based tf-idf procedure. arXiv preprint arXiv:2203.05794, 2022
work page internal anchor Pith review arXiv 2022
-
[11]
Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision an...
2024
-
[12]
Visplay: Self-evolving vision-language models from images,
Yicheng He, Chengsong Huang, Zongxia Li, Jiaxin Huang, and Yonghui Yang. Visplay: Self-evolving vision-language models from images.arXiv preprint arXiv:2511.15661, 2025
-
[13]
Curiosity-driven red-teaming for large language models
Zhang-Wei Hong, Idan Shenfeld, Tsun-Hsuan Wang, Yung-Sung Chuang, Aldo Pareja, James Glass, Akash Srivastava, and Pulkit Agrawal. Curiosity-driven red-teaming for large language models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=4KqkizXgXU
2024
-
[14]
Irene Huang, Wei Lin, M Jehanzeb Mirza, Jacob A Hansen, Sivan Doveh, Victor Ion Butoi, Roei Herzig, Assaf Arbelle, Hilde Kuhene, Trevor Darrel, et al. Conme: Rethinking evaluation of compositional reasoning for modern vlms.arXiv preprint arXiv:2406.08164, 2024
-
[15]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, 19 Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Seed-bench: Benchmarking multimodal large language models
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. Seed-bench: Benchmarking multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13299–13308, 2024
2024
-
[17]
Core knowledge deficits in multi- modal language models
Yijiang Li, Qingying Gao, Tianwei Zhao, Bingyang Wang, Haoran Sun, Haiyun Lyu, Robert D Hawkins, Nuno Vasconcelos, Tal Golan, Dezhi Luo, et al. Core knowledge deficits in multi- modal language models. InInternational Conference on Machine Learning, pages 34379–34409. PMLR, 2025
2025
-
[18]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[19]
Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
2024
-
[20]
Egoschema: A diagnostic benchmark for very long-form video language understanding.Advances in Neural Information Processing Systems, 36:46212–46244, 2023
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding.Advances in Neural Information Processing Systems, 36:46212–46244, 2023
2023
-
[21]
Chartqapro: A more diverse and challenging benchmark for chart question answering
Ahmed Masry, Mohammed Saidul Islam, Mahir Ahmed, Aayush Bajaj, Firoz Kabir, Aaryaman Kartha, Md Tahmid Rahman Laskar, Mizanur Rahman, Shadikur Rahman, Mehrad Shahmo- hammadi, et al. Chartqapro: A more diverse and challenging benchmark for chart question answering. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19123–19151, 2025
2025
-
[22]
Vision language models are blind
Pooyan Rahmanzadehgervi, Logan Bolton, Mohammad Reza Taesiri, and Anh Totti Nguyen. Vision language models are blind. InProceedings of the Asian Conference on Computer Vision, pages 18–34, 2024
2024
-
[23]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615, 2025
work page internal anchor Pith review arXiv 2025
-
[25]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9568–9578, 2024
2024
-
[26]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788, 2020
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788, 2020. 20
2020
-
[27]
V?: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V?: Guided visual search as a core mechanism in multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13084–13094, 2024
2024
-
[28]
Evaluating object hallucination in large vision-language models
Li Yifan, Du Yifan, Zhou Kun, Wang Jinpeng, Xin Zhao Wayne, and Wen Ji-Rong. Evaluating object hallucination in large vision-language models. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023. URL https://openreview.net/forum?id= xozJw0kZXF
2023
-
[29]
Mm-vet: Evaluating large multimodal models for integrated capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. In International conference on machine learning. PMLR, 2024
2024
-
[30]
Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, et al. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15134–15186, 2025
2025
-
[31]
On evaluating adversarial robustness of large vision-language models.Advances in Neural Information Processing Systems, 36:54111–54138, 2023
Yunqing Zhao, Tianyu Pang, Chao Du, Xiao Yang, Chongxuan Li, Ngai-Man Man Cheung, and Min Lin. On evaluating adversarial robustness of large vision-language models.Advances in Neural Information Processing Systems, 36:54111–54138, 2023
2023
-
[32]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 21
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.