Recognition: no theorem link
The Energy Cost of Execution-Idle in GPU Clusters
Pith reviewed 2026-05-10 18:59 UTC · model grok-4.3
The pith
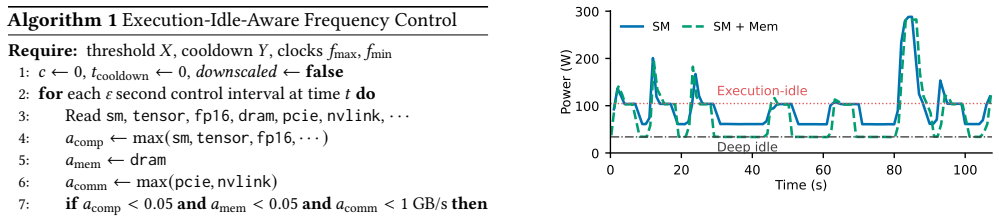
GPUs spend nearly 20% of execution time in a high-power low-activity state that wastes 10.7% of cluster energy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Execution-idle is a recurring low-activity yet high-power state in real GPU deployments that accounts for 19.7% of in-execution time and 10.7% of energy across diverse workloads and multiple GPU generations, indicating that future systems should reduce both its cost and the time spent in it.
What carries the argument
Execution-idle: the operating state in which GPUs remain at high power levels even when visible activity is near zero, measured via per-second telemetry.
If this is right
- Automatic downscaling of GPUs during detected execution-idle periods can reduce energy consumption at the cost of some performance overhead.
- Scheduling policies that deliberately introduce or exploit load imbalance can shorten the total time spent in execution-idle.
- Energy accounting models for GPU clusters must separately track execution-idle rather than assuming power scales directly with visible utilization.
- Hardware and software co-design should prioritize faster or lower-cost transitions out of execution-idle to improve overall efficiency.
Where Pith is reading between the lines
- Workload schedulers in production clusters could incorporate execution-idle detection to dynamically rebalance tasks and shrink exposure.
- Similar high-power low-activity states may appear in other accelerators, suggesting the need for cross-device power studies.
- Cloud billing could be adjusted to reflect actual energy drawn during execution-idle rather than assuming idle periods are cheap.
- Longer-term, GPU firmware might expose finer-grained power states that allow quicker exits from execution-idle without full downscaling.
Load-bearing premise
Per-second telemetry from the academic cluster accurately captures execution state boundaries and power draw without significant measurement error or workload-specific bias.
What would settle it
Controlled experiments that directly measure instantaneous power and activity counters on the same GPUs during periods labeled execution-idle versus true idle or full compute, checking whether power truly stays high while activity stays low.
Figures









read the original abstract
GPUs are becoming a major contributor to data center power, yet unlike CPUs, they can remain at high power even when visible activity is near zero. We call this state execution-idle. Using per-second telemetry from a large academic AI cluster, we characterize execution-idle as a recurring low-activity yet high-power state in real deployments. Across diverse workloads and multiple GPU generations, it accounts for 19.7% of in-execution time and 10.7% of energy. This suggests a need to both reduce the cost of execution-idle and reduce exposure to it. We therefore build two prototypes: one uses automatic downscaling during execution-idle, and the other uses load imbalance to reduce exposure, both with performance trade-offs. These findings suggest that future energy-efficient GPU systems should treat execution-idle as a first-class operating state.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the 'execution-idle' state in GPUs, where devices exhibit near-zero visible activity yet sustain high power draw. Using per-second telemetry from a large academic AI cluster, it reports that this state accounts for 19.7% of in-execution time and 10.7% of energy across diverse workloads and multiple GPU generations. The authors present two prototypes—one for automatic downscaling during execution-idle and one leveraging load imbalance to reduce exposure—both with performance trade-offs, and argue that future GPU systems should treat execution-idle as a first-class operating state.
Significance. If the measurements prove robust, the work identifies a substantial, recurring energy overhead in real GPU deployments that has received limited prior attention, with direct implications for data-center power optimization. The empirical scope across workloads and GPU generations, combined with concrete prototype implementations, strengthens the practical relevance. The study benefits from access to production cluster telemetry, enabling claims grounded in operational data rather than synthetic benchmarks.
major comments (3)
- [Methods] Methods section: The classification of execution-idle periods and attribution of power draw depends on per-second telemetry thresholds for utilization, kernel activity, and power without reported validation against higher-resolution tools (e.g., Nsight) or direct wattmeter traces. This measurement pipeline is load-bearing for the central 19.7% time and 10.7% energy claims; sampling granularity, lag, or workload-specific bias could systematically alter the reported fractions.
- [Results] Results section: The headline percentages are given as point estimates without error bars, confidence intervals, sensitivity analysis on classification thresholds, or statistical tests for consistency across workloads and GPU generations. This omission undermines evaluation of whether the figures are robust or sensitive to the exact definition of execution periods.
- [Prototype Evaluation] Prototype evaluation: The energy savings and performance trade-offs of the two prototypes are described qualitatively but lack quantitative metrics (e.g., measured energy reduction percentages, latency overheads, or comparison to baselines) that would allow assessment of their effectiveness relative to the identified overhead.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly state the exact telemetry fields and thresholds used to delimit execution-idle states for improved reproducibility.
- [Figures/Tables] Figure captions and table legends should include the precise definitions of 'in-execution time' and how idle periods were aggregated.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below. Where appropriate, we have revised the manuscript to incorporate additional analyses and clarifications.
read point-by-point responses
-
Referee: [Methods] Methods section: The classification of execution-idle periods and attribution of power draw depends on per-second telemetry thresholds for utilization, kernel activity, and power without reported validation against higher-resolution tools (e.g., Nsight) or direct wattmeter traces. This measurement pipeline is load-bearing for the central 19.7% time and 10.7% energy claims; sampling granularity, lag, or workload-specific bias could systematically alter the reported fractions.
Authors: We acknowledge that validation against higher-resolution tools like Nsight or direct wattmeter measurements would provide additional confidence in the classification. However, our study relies on production cluster telemetry at per-second granularity, which is the standard monitoring available across the entire cluster. Instrumenting individual workloads with Nsight is not feasible at this scale. To strengthen the analysis, we have conducted a sensitivity study varying the utilization and power thresholds and will include the results in the revised manuscript, demonstrating the stability of the reported fractions. We also add a discussion of potential limitations due to sampling granularity. revision: partial
-
Referee: [Results] Results section: The headline percentages are given as point estimates without error bars, confidence intervals, sensitivity analysis on classification thresholds, or statistical tests for consistency across workloads and GPU generations. This omission undermines evaluation of whether the figures are robust or sensitive to the exact definition of execution periods.
Authors: We agree that including measures of uncertainty and robustness would improve the presentation of the results. In the revised manuscript, we will report bootstrapped 95% confidence intervals for the 19.7% and 10.7% figures, computed across the diverse workloads and GPU generations. Additionally, we include sensitivity analysis on the classification thresholds and statistical tests to confirm consistency across subsets of the data. revision: yes
-
Referee: [Prototype Evaluation] Prototype evaluation: The energy savings and performance trade-offs of the two prototypes are described qualitatively but lack quantitative metrics (e.g., measured energy reduction percentages, latency overheads, or comparison to baselines) that would allow assessment of their effectiveness relative to the identified overhead.
Authors: The prototype evaluations were performed in a testbed environment. We recognize the value of quantitative metrics for assessing effectiveness. We will expand the evaluation section to include quantitative metrics from our experiments, such as measured energy reduction percentages, latency overheads, and comparisons to baseline configurations without the interventions. revision: yes
Circularity Check
Empirical measurement study with no circular derivation chain
full rationale
The paper reports observed fractions of time and energy spent in an execution-idle state directly from per-second cluster telemetry across workloads and GPU generations. No equations, fitted parameters, or predictions are presented that reduce by construction to the inputs; the two prototypes are built as engineering responses to the measurements rather than as derivations. Self-citations, if present, are not load-bearing for the central percentages or claims. The work is self-contained as an observational study against external benchmarks (real cluster logs), satisfying the criteria for score 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Per-second telemetry accurately distinguishes execution periods from true idle and correctly measures instantaneous power.
invented entities (1)
-
execution-idle state
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Luiz André Barroso and Urs Hölzle. 2007. The Case for Energy- Proportional Computing.Computer40, 12 (2007), 33–37. doi:10.1109/ MC.2007.443
2007
-
[2]
Sangjin Choi, Inhoe Koo, Jeongseob Ahn, Myeongjae Jeon, and Youngjin Kwon. 2023. EnvPipe: Performance-preserving DNN Train- ing Framework for Saving Energy. In2023 USENIX Annual Technical Conference (USENIX ATC 23). USENIX Association, Boston, MA, 851– 864.https://www.usenix.org/conference/atc23/presentation/choi
2023
-
[3]
The ml. energy benchmark: Toward automated inference energy measurement and optimization,
Jae-Won Chung, Jeff J. Ma, Ruofan Wu, Jiachen Liu, Oh Jun Kweon, Yux- uan Xia, Zhiyu Wu, and Mosharaf Chowdhury. 2025. The ML.ENERGY Benchmark: Toward Automated Inference Energy Measurement and Optimization. arXiv:2505.06371 [cs.LG]https://arxiv.org/abs/2505. 06371
-
[4]
Where do the joules go? diagnosing inference energy consumption,
Jae-Won Chung, Ruofan Wu, Jeff J. Ma, and Mosharaf Chowdhury. 2026. Where Do the Joules Go? Diagnosing Inference Energy Consumption. arXiv:2601.22076 [cs.LG]https://arxiv.org/abs/2601.22076
-
[5]
Mariana Toledo Costa, Antigoni Georgiadou, III White, James B., Bruno Villasenor Alvarez, Jordà Polo, Woong Shin, Philippe Olivier Alexandre Navaux, Bronson Messer, and Arthur Francisco Lorenzon. 2025. Characterizing the Impact of GPU Power Man- agement on an Exascale System. InProceedings of the SC ’25 Work- shops of the International Conference for High...
-
[6]
Advanced power flow controllers (apfc),
Electric Power Research Institute. 2026.Powering Intelligence: An- alyzing Artificial Intelligence and Data Center Energy Consumption. Technical Report 3002034696. Electric Power Research Institute (EPRI). https://www.epri.com/research/products/000000003002034696
-
[7]
Luke Emberson and Ben Cottier. 2025. GPUs Account for About 40% of Power Usage in AI Data Centers.https://epoch.ai/data-insights/gpus- power-usage-in-ai-data-centersEpoch AI analysis. 12
2025
-
[8]
Xiaobo Fan, Wolf-Dietrich Weber, and Luiz Andre Barroso. 2007. Power provisioning for a warehouse-sized computer.SIGARCH Comput. Archit. News35, 2 (June 2007), 13–23. doi:10.1145/1273440.1250665
-
[9]
Jared Fernandez, Clara Na, Vashisth Tiwari, Yonatan Bisk, Sasha Luc- cioni, and Emma Strubell. 2025. Energy Considerations of Large Language Model Inference and Efficiency Optimizations. InProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and M...
-
[10]
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. 2024. ServerlessLLM: Low- Latency Serverless Inference for Large Language Models. In18th USENIX Symposium on Operating Systems Design and Implementa- tion (OSDI 24). USENIX Association, Santa Clara, CA, 135–153.https: //www.usenix.org/conference/osdi24/pr...
2024
-
[11]
Sébastien Godard. 2025. sysstat: Performance Monitoring Tools for Linux.https://github.com/sysstat/sysstatIncludes the pidstat utility; accessed 2026-03-30
2025
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Alan Gray. 2024. Maximizing Energy and Power Efficiency in Applications with NVIDIA GPUs.https://developer.nvidia.com/blog/ maximizing-energy-and-power-efficiency-in-applications-with- nvidia-gpus/NVIDIA Technical Blog
2024
-
[14]
Alastair Green, Humayun Tai, Jesse Noffsinger, Pankaj Sachdeva, Arjita Bhan, and Raman Sharma. 2024. How Data Centers and the Energy Sector Can Sate AI’s Hunger for Power. https://www.mckinsey.com/industries/private-capital/our- insights/how-data-centers-and-the-energy-sector-can-sate- ais-hunger-for-powerMcKinsey & Company article
2024
-
[15]
Hewlett Packard Enterprise. 2026. Workload profiles | HPE iLO 5 User Guide. HPC profile disables power management to optimize sustained bandwidth and compute capacity
2026
-
[16]
Ali Jahanshahi, Hadi Zamani Sabzi, Chester Lau, and Daniel Wong
-
[17]
GPU-NEST: Characterizing Energy Efficiency of Multi-GPU Inference Servers.IEEE Computer Architecture Letters19, 2 (2020), 139–142. doi:10.1109/LCA.2020.3023723
- [18]
-
[19]
Gonzalez, Hao Zhang, and Ion Sto- ica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Sto- ica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
2023
-
[20]
Imran Latif, Alex C. Newkirk, Matthew R. Carbone, Arslan Munir, Yuewei Lin, Jonathan Koomey, Xi Yu, and Zhihua Dong. 2025. Single- Node Power Demand During AI Training: Measurements on an 8-GPU NVIDIA H100 System.IEEE Access13 (2025), 61740–61747. doi:10. 1109/ACCESS.2025.3554728
-
[21]
Alexandra Sasha Luccioni, Sylvain Viguier, and Anne-Laure Ligozat
-
[22]
Estimating the carbon footprint of BLOOM, a 176B parameter language model.J. Mach. Learn. Res.24, 1, Article 253 (Jan. 2023), 15 pages
2023
-
[23]
Sasha Luccioni, Yacine Jernite, and Emma Strubell. 2024. Power Hun- gry Processing: Watts Driving the Cost of AI Deployment?. InProceed- ings of the 2024 ACM Conference on Fairness, Accountability, and Trans- parency(Rio de Janeiro, Brazil)(FAccT ’24). Association for Computing Machinery, New York, NY, USA, 85–99. doi:10.1145/3630106.3658542
-
[24]
Leland McInnes, John Healy, and Steve Astels. 2017. hdbscan: Hierar- chical density based clustering.Journal of Open Source Software2, 11 (2017), 205. doi:10.21105/joss.00205
- [25]
- [26]
- [27]
-
[28]
Chenxu Niu, Wei Zhang, Yongjian Zhao, and Yong Chen. 2025. Energy Efficient or Exhaustive? Benchmarking Power Consumption of LLM Inference Engines.SIGENERGY Energy Inform. Rev.5, 2 (Aug. 2025), 56–62. doi:10.1145/3757892.3757900
-
[29]
NVIDIA. 2025. Driver Persistence.https://docs.nvidia.com/deploy/ driver-persistence/index.html
2025
-
[30]
NVIDIA. 2025. NVIDIA Blackwell B200 GPU.https://images.nvidia. com/aem-dam/Solutions/documents/HGX-B200-PCF-Summary.pdf
2025
-
[31]
NVIDIA Corporation. 2025. NVIDIA Multi-Instance GPU User Guide. https://docs.nvidia.com/datacenter/tesla/mig-user-guide/index.html
2025
-
[32]
NVIDIA Corporation. 2026. NVIDIA A100 Tensor Core GPU.https: //www.nvidia.com/en-us/data-center/a100/
2026
-
[33]
2026.NVIDIA Data Center GPU Manager (DCGM) Documentation.https://docs.nvidia.com/datacenter/dcgm/ latest/index.html
NVIDIA Corporation. 2026.NVIDIA Data Center GPU Manager (DCGM) Documentation.https://docs.nvidia.com/datacenter/dcgm/ latest/index.html
2026
-
[34]
NVIDIA Corporation. 2026. NVIDIA H100 GPU.https://www.nvidia. com/en-us/data-center/h100/
2026
-
[35]
NVIDIA Corporation. 2026. NVIDIA L40S GPU for AI and Graphics Performance.https://www.nvidia.com/en-us/data-center/l40s/
2026
-
[36]
2026.NVIDIA Management Library (NVML) API Reference Guide.https://docs.nvidia.com/deploy/nvml-api/index.html
NVIDIA Corporation. 2026.NVIDIA Management Library (NVML) API Reference Guide.https://docs.nvidia.com/deploy/nvml-api/index.html
2026
-
[37]
NVIDIA Corporation. 2026. NVIDIA RTX 6000 Ada Generation Graph- ics Card.https://www.nvidia.com/en-us/products/workstations/rtx- 6000/
2026
-
[38]
NVIDIA Corporation. 2026. NVIDIA RTX A6000.https://www.nvidia. com/en-us/products/workstations/rtx-a6000/
2026
-
[39]
NVIDIA Corporation. 2026. NVIDIA System Management Interface (nvidia-smi).https://docs.nvidia.com/deploy/nvidia-smi/
2026
-
[40]
Gabriele Oliaro, Xupeng Miao, Xinhao Cheng, Vineeth Kada, Mengdi Wu, Ruohan Gao, Yingyi Huang, Remi Delacourt, April Yang, Yingcheng Wang, Colin Unger, and Zhihao Jia. 2025. FlexLLM: Token- Level Co-Serving of LLM Inference and Finetuning with SLO Guaran- tees. arXiv:2402.18789 [cs.DC]https://arxiv.org/abs/2402.18789
-
[41]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Íñigo Goiri, Brijesh War- rier, Nithish Mahalingam, and Ricardo Bianchini. 2024. Characterizing Power Management Opportunities for LLMs in the Cloud. InProceed- ings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3(La Jolla, CA, USA)(ASP...
-
[42]
Pratikkumar Patel and Sreedhar Narayanaswamy. 2025. Optimize Data Center Efficiency for AI and HPC Workloads with Power Profiles.https://developer.nvidia.com/blog/optimize-data-center- efficiency-for-ai-and-hpc-workloads-with-power-profiles/
2025
-
[43]
Patterson, Joseph Gonzalez, Urs Hölzle, Quoc V
David Patterson, Joseph Gonzalez, Urs Hölzle, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David R. So, Maud Texier, and Jeff Dean. 2022. The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink.Computer55, 7 (2022), 18–28. doi:10.1109/MC.2022.3148714 13
-
[44]
Gon- zalez, Ion Stoica, and Harry Xu
Yifan Qiao, Shu Anzai, Shan Yu, Haoran Ma, Shuo Yang, Yang Wang, Miryung Kim, Yongji Wu, Yang Zhou, Jiarong Xing, Joseph E. Gonzalez, Ion Stoica, and Harry Xu. 2025. ConServe: Fine-Grained GPU Harvest- ing for LLM Online and Offline Co-Serving. arXiv:2410.01228 [cs.DC] https://arxiv.org/abs/2410.01228
-
[45]
Haoran Qiu, Weichao Mao, Archit Patke, Shengkun Cui, Saurabh Jha, Chen Wang, Hubertus Franke, Zbigniew Kalbarczyk, Tamer Başar, and Ravishankar K. Iyer. 2024. Power-aware Deep Learning Model Serving with 𝜇-Serve. In2024 USENIX Annual Technical Conference (USENIX ATC 24). USENIX Association, Santa Clara, CA, 75–93.https: //www.usenix.org/conference/atc24/p...
2024
-
[46]
Giampaolo Rodolà. 2026. psutil: Cross-platform lib for process and system monitoring in Python.https://github.com/giampaolo/psutil
2026
-
[47]
Yadwadkar, and Christos Kozyrakis
Francisco Romero, Qian Li, Neeraja J. Yadwadkar, and Christos Kozyrakis. 2021. INFaaS: Automated Model-less Inference Serv- ing. In2021 USENIX Annual Technical Conference (USENIX ATC 21). USENIX Association, 397–411.https://www.usenix.org/conference/ atc21/presentation/romero
2021
-
[48]
Siddharth Samsi, Dan Zhao, Joseph McDonald, Baolin Li, Adam Michaleas, Michael Jones, William Bergeron, Jeremy Kepner, De- vesh Tiwari, and Vijay Gadepally. 2023. From Words to Watts: Benchmarking the Energy Costs of Large Language Model Inference. arXiv:2310.03003 [cs.CL]https://arxiv.org/abs/2310.03003
-
[49]
Arman Shehabi, Sarah Josephine Smith, Alex Hubbard, Alexander Newkirk, Nuoa Lei, Md AbuBakar Siddik, Billie Holecek, Jonathan G. Koomey, Eric R. Masanet, and Dale A. Sartor. 2024.2024 United States Data Center Energy Usage Report. Technical Report. Lawrence Berkeley National Laboratory. doi:10.71468/P1WC7Q
- [50]
-
[51]
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Torrellas, and Esha Choukse. 2025. DynamoLLM: Designing LLM Inference Clusters for Performance and Energy Efficiency. In2025 IEEE International Sympo- sium on High Performance Computer Architecture (HPCA). 1348–1362. doi:10.1109/HPCA61900.2025.00102
-
[52]
Zhenheng Tang, Yuxin Wang, Qiang Wang, and Xiaowen Chu. 2019. The Impact of GPU DVFS on the Energy and Performance of Deep Learning: an Empirical Study. InProceedings of the Tenth ACM In- ternational Conference on Future Energy Systems(Phoenix, AZ, USA) (e-Energy ’19). Association for Computing Machinery, New York, NY, USA, 315–325. doi:10.1145/3307772.3328315
-
[53]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie- Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971 [cs.CL]https://arxiv. org/abs/2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [54]
-
[55]
Jiahao Wang, Jinbo Han, Xingda Wei, Sijie Shen, Dingyan Zhang, Chenguang Fang, Rong Chen, Wenyuan Yu, and Haibo Chen. 2025. KVCache Cache in the Wild: Characterizing and Optimizing KVCache Cache at a Large Cloud Provider. In2025 USENIX Annual Technical Conference (USENIX ATC 25). USENIX Association.https://www. usenix.org/conference/atc25/presentation/wang-jiahao
2025
-
[56]
Yuxin Wang, Yuhan Chen, Zeyu Li, Xueze Kang, Yuchu Fang, Yeju Zhou, Yang Zheng, Zhenheng Tang, Xin He, Rui Guo, Xin Wang, Qiang Wang, Amelie Chi Zhou, and Xiaowen Chu. 2025. BurstGPT: A Real-World Workload Dataset to Optimize LLM Serving Systems. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Dis- covery and Data Mining V.2 (KDD ’25). ACM, T...
- [57]
-
[58]
Lee, Bugra Akyildiz, Maximilian Balandat, Joe Spisak, Ravi Jain, Mike Rabbat, and Kim Hazelwood
Carole-Jean Wu, Ramya Raghavendra, Udit Gupta, Bilge Acun, New- sha Ardalani, Kiwan Maeng, Gloria Chang, Fiona Aga Behram, James Huang, Charles Bai, Michael Gschwind, Anurag Gupta, Myle Ott, Anas- tasia Melnikov, Salvatore Candido, David Brooks, Geeta Chauhan, Ben- jamin Lee, Hsien-Hsin S. Lee, Bugra Akyildiz, Maximilian Balandat, Joe Spisak, Ravi Jain, M...
-
[59]
xAI. 2026. Colossus: The World’s Largest AI Supercomputer.https: //x.ai/colossus
2026
-
[60]
Jie You, Jae-Won Chung, and Mosharaf Chowdhury. 2023. Zeus: Under- standing and Optimizing GPU Energy Consumption of DNN Training. In20th USENIX Symposium on Networked Systems Design and Im- plementation (NSDI 23). USENIX Association, Boston, MA, 119–139. https://www.usenix.org/conference/nsdi23/presentation/you
2023
-
[61]
Junyeol Yu, Jongseok Kim, and Euiseong Seo. 2023. Know Your Enemy To Save Cloud Energy: Energy-Performance Characteriza- tion of Machine Learning Serving. In2023 IEEE International Sympo- sium on High-Performance Computer Architecture (HPCA). 842–854. doi:10.1109/HPCA56546.2023.10070943
-
[62]
Shan Yu, Jiarong Xing, Yifan Qiao, Mingyuan Ma, Yangmin Li, Yang Wang, Shuo Yang, Zhiqiang Xie, Shiyi Cao, Ke Bao, Ion Stoica, Harry Xu, and Ying Sheng. 2025. Prism: Unleashing GPU Sharing for Cost- Efficient Multi-LLM Serving. arXiv:2505.04021 [cs.DC]https://arxiv. org/abs/2505.04021
-
[63]
Dingyan Zhang, Haotian Wang, Yang Liu, Xingda Wei, Yizhou Shan, Rong Chen, and Haibo Chen. 2025. BLITZSCALE: fast and live large model autoscaling with O(1) host caching. InProceedings of the 19th USENIX Conference on Operating Systems Design and Implementation (Boston, MA, USA)(OSDI ’25). USENIX Association, USA, Article 16, 19 pages
2025
-
[64]
Yijia Zhang, Qiang Wang, Zhe Lin, Pengxiang Xu, and Bingqiang Wang. 2024. Improving GPU Energy Efficiency through an Application- transparent Frequency Scaling Policy with Performance Assurance. In Proceedings of the Nineteenth European Conference on Computer Systems (Athens, Greece)(EuroSys ’24). Association for Computing Machinery, New York, NY, USA, 76...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.