Recognition: no theorem link
CLEAR: Unlocking Generative Potential for Degraded Image Understanding in Unified Multimodal Models
Pith reviewed 2026-05-10 18:48 UTC · model grok-4.3
The pith
Unified multimodal models can be trained to invoke their generative capacity for reasoning on degraded images while preserving clean-image performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that the disconnect between generation and reasoning in unified multimodal models stems from training regimes that never ask for generation during reasoning plus a non-optimizable decode-reencode pathway, and that CLEAR resolves it by first performing supervised fine-tuning on a degradation-aware dataset to establish the generate-then-answer pattern, then inserting a Latent Representation Bridge to replace the detour with a direct optimizable link, and finally applying Interleaved GRPO to jointly optimize text reasoning and visual generation under answer-correctness rewards, which yields substantially improved robustness on degraded inputs while preserving clean-image性能 and
What carries the argument
The Latent Representation Bridge, a direct optimizable connection between the generation and reasoning pathways that replaces the standard decode-reencode detour.
If this is right
- Models exhibit substantially higher robustness on degraded images across multiple standard benchmarks and three severity levels.
- Performance on clean images remains unchanged after the training changes.
- Task-driven optimization without pixel-level reconstruction produces intermediate visual states of higher perceptual quality.
- Text reasoning and visual generation can be jointly optimized under a shared answer-correctness reward.
Where Pith is reading between the lines
- The observed alignment between task-driven optimization and perceptual quality may generalize to other generative tasks where reconstruction losses are currently used.
- Direct bridging techniques could be tested on video or audio inputs to see whether generative pathways aid understanding when those modalities are degraded.
- The generate-then-answer pattern established by the initial fine-tuning step may reduce the need for separate pre-training stages in future unified models.
Load-bearing premise
That the Latent Representation Bridge and Interleaved GRPO can successfully direct the model's generative capacity toward reasoning on degraded inputs without introducing optimization instabilities or unintended trade-offs in generation quality.
What would settle it
Running the same models and benchmarks with and without CLEAR and observing no accuracy improvement on the degraded portions of MMD-Bench, or a drop in accuracy on the clean portions, would falsify the central claim.
Figures










read the original abstract
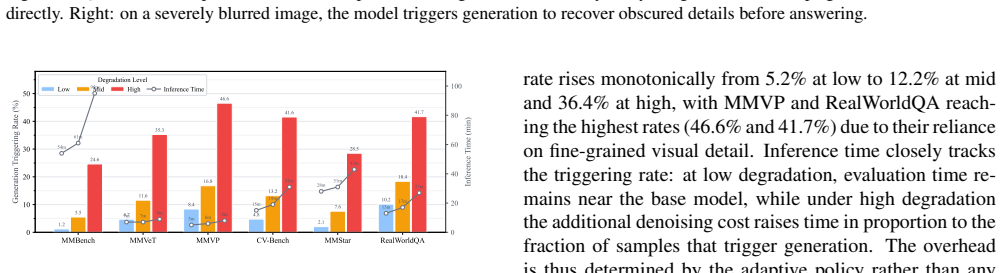
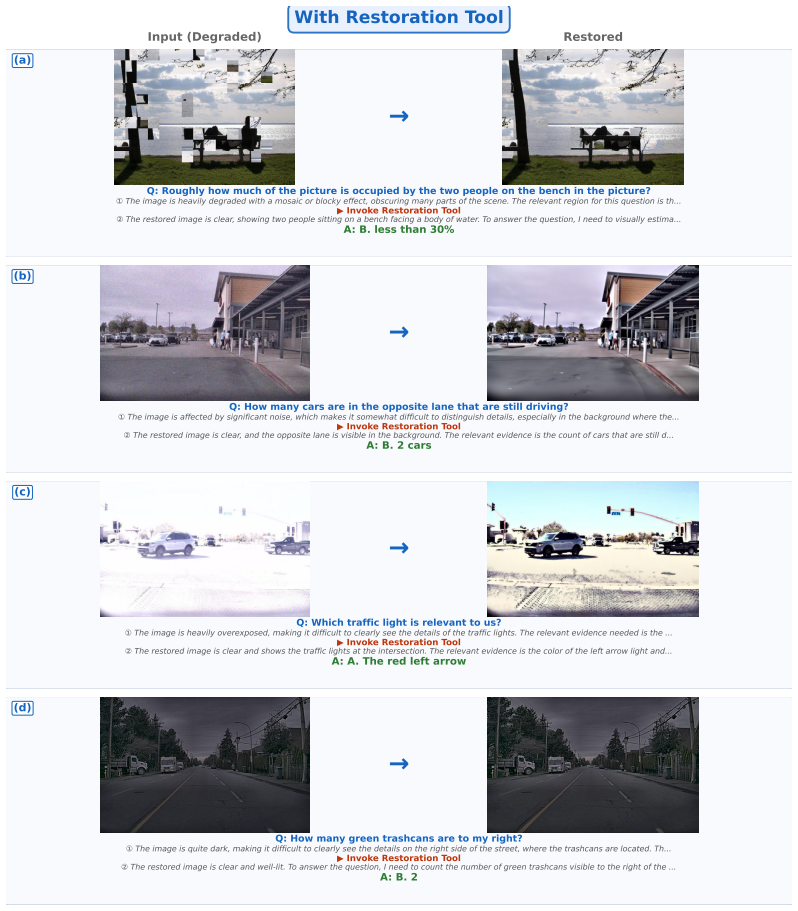
Image degradation from blur, noise, compression, and poor illumination severely undermines multimodal understanding in real-world settings. Unified multimodal models that combine understanding and generation within a single architecture are a natural fit for this challenge, as their generative pathway can model the fine-grained visual structure that degradation destroys. Yet these models fail to leverage their own generative capacity on degraded inputs. We trace this disconnect to two compounding factors: existing training regimes never ask the model to invoke generation during reasoning, and the standard decode-reencode pathway does not support effective joint optimization. We present CLEAR, a framework that connects the two capabilities through three progressive steps: (1) supervised fine-tuning on a degradation-aware dataset to establish the generate-then-answer reasoning pattern; (2) a Latent Representation Bridge that replaces the decode-reencode detour with a direct, optimizable connection between generation and reasoning; (3) Interleaved GRPO, a reinforcement learning method that jointly optimizes text reasoning and visual generation under answer-correctness rewards. We construct MMD-Bench, covering three degradation severity levels across six standard multimodal benchmarks. Experiments show that CLEAR substantially improves robustness on degraded inputs while preserving clean-image performance. Our analysis further reveals that removing pixel-level reconstruction supervision leads to intermediate visual states with higher perceptual quality, suggesting that task-driven optimization and visual quality are naturally aligned.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CLEAR, a framework to enable unified multimodal models to leverage their generative capabilities for understanding degraded images. It consists of three steps: (1) supervised fine-tuning (SFT) on a newly constructed degradation-aware dataset to establish a generate-then-answer reasoning pattern, (2) introduction of a Latent Representation Bridge to provide a direct, optimizable connection between generation and reasoning modules instead of decode-reencode, and (3) Interleaved GRPO, a reinforcement learning approach that jointly optimizes text reasoning and visual generation using answer-correctness rewards. The authors also introduce MMD-Bench, a benchmark covering three degradation severity levels across six standard multimodal tasks. Experiments demonstrate that CLEAR substantially improves performance on degraded inputs while preserving clean-image performance, and that removing pixel-level reconstruction supervision leads to higher perceptual quality in intermediate visual states.
Significance. If the empirical results are robust, this work addresses an important practical limitation in multimodal AI systems operating in real-world conditions with image degradations such as blur, noise, and poor lighting. By showing that generative capacity can be unlocked for reasoning without sacrificing clean performance, and that task-driven optimization aligns with perceptual quality, it could influence the design of future unified models. The MMD-Bench benchmark is a valuable contribution for evaluating robustness in this domain.
major comments (2)
- [Experiments] The central claim that the full three-step CLEAR pipeline is necessary to unlock generative potential for degraded image understanding relies on the contributions of the Latent Representation Bridge and Interleaved GRPO. However, no ablation studies are described that isolate these components from the baseline SFT on degradation-aware data. Without such controls, it remains possible that the reported gains on MMD-Bench are primarily due to the initial SFT stage, undermining the load-bearing assumption that the novel mechanisms are required to avoid the decode-reencode problem and enable joint optimization.
- [Abstract and Results] The abstract reports positive experimental outcomes on MMD-Bench but provides no details on baselines, statistical significance, ablation controls, or exact metrics and values. This makes it difficult to verify the soundness of the claim that CLEAR substantially improves robustness on degraded inputs while preserving clean-image performance.
minor comments (1)
- [Abstract] The term 'Interleaved GRPO' is introduced without expansion or reference in the abstract; a brief definition or citation would improve clarity for readers unfamiliar with the method.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and will revise the manuscript to incorporate additional experiments and clarifications as needed.
read point-by-point responses
-
Referee: [Experiments] The central claim that the full three-step CLEAR pipeline is necessary to unlock generative potential for degraded image understanding relies on the contributions of the Latent Representation Bridge and Interleaved GRPO. However, no ablation studies are described that isolate these components from the baseline SFT on degradation-aware data. Without such controls, it remains possible that the reported gains on MMD-Bench are primarily due to the initial SFT stage, undermining the load-bearing assumption that the novel mechanisms are required to avoid the decode-reencode problem and enable joint optimization.
Authors: We acknowledge that the manuscript does not present dedicated ablation studies that hold the SFT stage fixed while isolating the Latent Representation Bridge and Interleaved GRPO. Our reported results show cumulative gains across the three stages, but we agree this does not fully rule out that the primary benefit stems from degradation-aware SFT alone. In the revised version we will add explicit ablation experiments that compare (i) SFT-only, (ii) SFT + Latent Representation Bridge, (iii) SFT + Interleaved GRPO, and (iv) the full CLEAR pipeline on MMD-Bench, thereby directly quantifying the incremental value of each novel component. revision: yes
-
Referee: [Abstract and Results] The abstract reports positive experimental outcomes on MMD-Bench but provides no details on baselines, statistical significance, ablation controls, or exact metrics and values. This makes it difficult to verify the soundness of the claim that CLEAR substantially improves robustness on degraded inputs while preserving clean-image performance.
Authors: We agree that the abstract is too terse to convey the experimental details. We will revise the abstract to explicitly name the main baselines (base unified model and SFT-only), report representative metric values for both degraded and clean inputs, and indicate that improvements were consistent across multiple runs. The results section already contains full tables and figures; we will further annotate them with standard-error bars and note the number of evaluation runs to support claims of robustness. revision: yes
Circularity Check
No circularity: empirical pipeline with external benchmarks
full rationale
The paper outlines an empirical three-step training procedure (SFT on degradation-aware data, Latent Representation Bridge, Interleaved GRPO) evaluated on the newly constructed MMD-Bench across six standard multimodal benchmarks at multiple degradation levels. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation chain; the claims rest on reported robustness gains and perceptual-quality observations that are externally falsifiable against baselines and clean-image controls. The work is therefore self-contained against external benchmarks rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Unified multimodal models possess generative capacity that can aid understanding of degraded inputs when properly connected during training.
invented entities (2)
-
Latent Representation Bridge
no independent evidence
-
Interleaved GRPO
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2, 4, 6, 13
Improving generation quality of flow-based multimodal models via grpo.arXiv preprint, 2025. 2, 4, 6, 13
2025
-
[2]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforce- ment learning.arXiv preprint arXiv:2305.13301, 2023. 4
work page internal anchor Pith review arXiv 2023
-
[3]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024. 2, 3
work page internal anchor Pith review arXiv 2024
-
[4]
Simple baselines for image restoration, 2022
Liangyu Chen, Xiaojie Chu, Xiangyu Zhang, and Jian Sun. Simple baselines for image restoration, 2022. 8
2022
-
[5]
Simple baselines for image restoration
Liangyu Chen, Xiaojie Chu, Xiangyu Zhang, and Jian Sun. Simple baselines for image restoration. InEuropean Confer- ence on Computer Vision (ECCV), 2022. 3
2022
-
[6]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, and Feng Zhu. Are we on the right way for evaluating large vision-language models?arXiv preprint arXiv:2403.20330, 2024. 7, 15
work page internal anchor Pith review arXiv 2024
-
[7]
Visual-RFT: Visual Reinforcement Fine-Tuning
Liang Chen, Qiguang Bai, Kanzhi Xu, Jiahao Li, et al. R1-v: Reinforcing super generalization ability in vision language models with less than $3.arXiv preprint arXiv:2503.01785,
work page internal anchor Pith review arXiv
-
[8]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages...
2024
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. InProceedings of the 32nd ACM International Conference on Multimedia, pages 11198–11201, 2024. 7, 15
2024
-
[11]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bj ¨orn Ommer. Taming transformers for high-resolution image synthesis. InCVPR,
-
[12]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, and Rongrong Ji. Mme: A compre- hensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[13]
Benchmarking neu- ral network robustness to common corruptions and perturba- tions.Proceedings of the International Conference on Learn- ing Representations, 2019
Dan Hendrycks and Thomas Dietterich. Benchmarking neu- ral network robustness to common corruptions and perturba- tions.Proceedings of the International Conference on Learn- ing Representations, 2019. 2, 3
2019
-
[14]
Augmix: A simple data processing method to improve robustness and uncertainty
Dan Hendrycks, Norman Mu, Ekin D Cubuk, Barret Zoph, Justin Gilmer, and Balaji Lakshminarayanan. Augmix: A simple data processing method to improve robustness and uncertainty. InICLR, 2020. 3
2020
-
[15]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenyi Huang, Enfang Feng, Yufei Gao, et al. Vision-r1: Incentivizing reasoning capability in multimodal large lan- guage models.arXiv preprint arXiv:2503.06749, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[16]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding varia- tional bayes.arXiv preprint arXiv:1312.6114, 2013. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[17]
Photo-realistic single image super-resolution using a generative adversarial network
Christian Ledig, Lucas Theis, Ferenc Husz´ar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, and Wenzhe Shi. Photo-realistic single image super-resolution using a generative adversarial network. InCVPR, 2017. 5
2017
-
[18]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 4, 7, 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Chunyi Li, Jianbo Zhang, Zicheng Zhang, Haoning Wu, Yuan Tian, Wei Sun, Guo Lu, Xiaohong Liu, Xiongkuo Min, Weisi Lin, and Guangtao Zhai. R-bench: Are your large multimodal model robust to real-world corruptions?arXiv preprint arXiv:2410.05474, 2024. 2, 3, 7, 8, 14
-
[20]
Emerging Properties in Unified Multimodal Pretraining
Kunchang Li et al. Emerging properties in unified multi- modal pretraining.arXiv preprint arXiv:2505.14683, 2025. 2, 3, 4, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Swinir: Image restoration us- ing swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration us- ing swin transformer. InICCVW, 2021. 3 10
2021
-
[22]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxi- milian Nickel, and Matt Le. Flow matching for generative modeling. InICLR, 2023. 6, 13
2023
-
[23]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023. 2
2023
-
[24]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023. 6, 13
2023
-
[25]
MMBench: Is Your Multi-modal Model an All-around Player?
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. Mmbench: Is your multi-modal model an all-around player?arXiv preprint arXiv:2307.06281, 2023. 7, 14
work page internal anchor Pith review arXiv 2023
-
[26]
Unified-io 2: Scaling autoregressive multimodal models with vision, language, audio, and action.CVPR,
Jiasen Lu, Christopher Clark, Sangho Lee, Zichen Zhang, Savya Khosla, Ryan Marten, Derek Hoiem, and Aniruddha Kembhavi. Unified-io 2: Scaling autoregressive multimodal models with vision, language, audio, and action.CVPR,
-
[27]
Deep multi-scale video prediction beyond mean square error
Michael Mathieu, Camille Couprie, and Yann LeCun. Deep multi-scale video prediction beyond mean square error. In ICLR, 2016. 5
2016
-
[28]
On in- teraction between augmentations and corruptions in natural corruption robustness
Eric Mintun, Alexander Kirillov, and Saining Xie. On in- teraction between augmentations and corruptions in natural corruption robustness. InNeurIPS, 2021. 3
2021
-
[29]
OpenAI. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Gpt-4.1.https://openai.com/index/ gpt-4-1/, 2025
OpenAI. Gpt-4.1.https://openai.com/index/ gpt-4-1/, 2025. 4, 15
2025
-
[31]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, pages 8748–8763. PMLR,
-
[32]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, 2022. 2
2022
-
[33]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junx- iao Song, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 2, 3, 6, 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Zilun Zhang, Qian Zhao, Ruochen Zhang, et al. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615,
work page internal anchor Pith review arXiv
-
[35]
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai Charitha Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian- 1: A fully open, vision-centric exploration of multimodal llms.arXiv preprint arXiv:2406.16860, 2024. 7, 15
-
[36]
Eyes wide shut? exploring the visual shortcomings of multimodal llms.CVPR, 2024
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms.CVPR, 2024. 7, 15
2024
-
[37]
Diffusion model alignment us- ing direct preference optimization
Bram Wallace, Meiqi Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purber, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment us- ing direct preference optimization. 2024. 4
2024
-
[38]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Jun- yang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need.arXiv preprint arXiv:2409.18869, 2024. 2, 3
work page internal anchor Pith review arXiv 2024
-
[40]
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, and Ping Luo. Janus: Decoupling visual encoding for unified multimodal understanding and genera- tion.arXiv preprint arXiv:2410.13848, 2024. 2, 3
-
[41]
Yecheng Wu, Zhuoyang Zhang, Junyu Chen, Haotian Tang, Dacheng Li, Yunhao Fang, Ligeng Zhu, Enze Xie, Hongxu Yin, Li Yi, Song Han, and Yao Lu. Vila-u: a unified founda- tion model integrating visual understanding and generation. arXiv preprint arXiv:2409.04429, 2024. 3
-
[42]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[43]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities.arXiv preprint arXiv:2308.02490, 2023. 7, 14
work page internal anchor Pith review arXiv 2023
-
[45]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Mu- nawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. InCVPR, 2022. 3
2022
-
[46]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023. 2, 4, 7
2023
-
[47]
A tale of two features: Stable diffusion complements dino for zero-shot semantic correspondence.Advances in Neural Information Processing Systems, 36:45533–45547,
Junyi Zhang, Charles Herrmann, Junhwa Hur, Luisa Pola- nia Cabrera, Varun Jampani, Deqing Sun, and Ming-Hsuan Yang. A tale of two features: Stable diffusion complements dino for zero-shot semantic correspondence.Advances in Neural Information Processing Systems, 36:45533–45547,
-
[48]
Cooper: A unified model for cooperative perception and reasoning in spatial intelligence
Zefeng Zhang, Xiangzhao Hao, Hengzhu Tang, Zhenyu Zhang, Jiawei Sheng, Xiaodong Li, Zhenyang Li, Li Gao, Daiting Shi, Dawei Yin, et al. Cooper: A unified model for cooperative perception and reasoning in spatial intelligence. arXiv preprint arXiv:2512.04563, 2025. 2
-
[49]
Evaluating the robustness of mul- timodal large language models against image corruptions
Changqian Zhao et al. Evaluating the robustness of mul- timodal large language models against image corruptions. arXiv preprint, 2024. 3 11
2024
-
[50]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonza- lez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. InNeurIPS, 2024. 7
2024
-
[51]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Chunting Zhou, Lili Yu, Arun Babu, Kushal Tirumala, Michihiro Yasunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, and Omer Levy. Transfusion: Pre- dict the next token and diffuse images with one multi-modal model.arXiv preprint arXiv:2408.11039, 2024. 2, 3 12
work page internal anchor Pith review arXiv 2024
-
[52]
EXIT”.< /think> <answer>The text on the sign is “EXIT
Appendix This supplementary material is organized as follows. Ap- pendix A provides detailed derivations of the GRPO and Flow-GRPO objectives that underlie Interleaved GRPO. Appendix B describes the construction of MMD-Bench, including the 16 corruption types and six base bench- marks. Appendix C details the training data construc- tion pipeline and reaso...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.