Recognition: no theorem link
Multi-Modal Sensor Fusion using Hybrid Attention for Autonomous Driving
Pith reviewed 2026-05-10 18:40 UTC · model grok-4.3
The pith
MMF-BEV fuses camera and radar features in bird's-eye view using deformable attention to improve 3D object detection over single-sensor baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MMF-BEV builds a BEVDepth camera branch and a RadarBEVNet radar branch, each enhanced with Deformable Self-Attention, and fuses them via a Deformable Cross-Attention module. Evaluated on the View-of-Delft 4D radar dataset, the hybrid model consistently outperforms unimodal baselines and remains competitive with prior fusion methods across all object classes in both the full annotated area and near-range Region of Interest, supported by a two-stage training strategy that pre-trains the camera branch with depth supervision before joint training of radar and fusion modules.
What carries the argument
Deformable Cross-Attention module that aligns and fuses camera and radar features after each modality has been lifted into bird's-eye view with its own deformable self-attention.
If this is right
- The two-stage training stabilizes learning by first anchoring the camera branch with depth supervision before adding radar and fusion components.
- A per-distance sensor contribution analysis quantifies how radar and camera weighting changes with range, confirming complementarity.
- Performance gains hold across all object classes in both full annotated area and near-range ROI.
- The same deformable attention pattern can be applied to other BEV-based detection pipelines that need cross-modal alignment.
Where Pith is reading between the lines
- Extending the same deformable attention alignment to include LiDAR point clouds could test whether the framework scales to three-modality fusion without retraining the entire stack.
- Evaluating the model in rain or fog, where radar remains functional while camera degrades, would reveal whether the learned fusion weighting adapts to changing sensor reliability.
- Replacing the current backbone branches with newer single-modality detectors could isolate how much of the reported gain comes from the fusion module itself versus the underlying feature extractors.
Load-bearing premise
Deformable attention modules can align camera and radar features without introducing misalignment or losing critical information from either modality.
What would settle it
If re-running the experiments on the VoD dataset shows that MMF-BEV does not exceed the stronger of the camera-only or radar-only baselines in average precision for any object class in the near-range ROI, the benefit of the hybrid fusion would be refuted.
Figures






read the original abstract
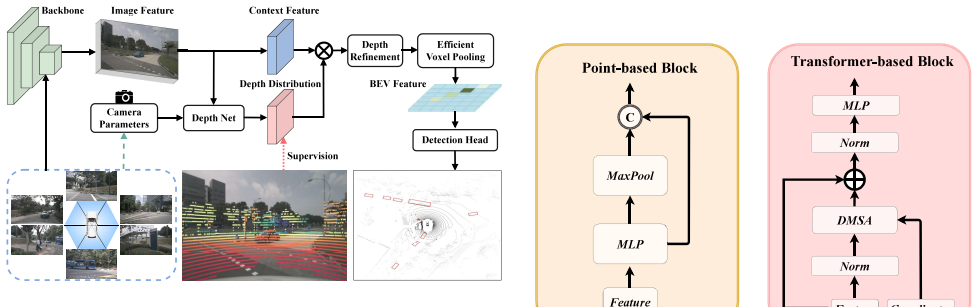
Accurate 3D object detection for autonomous driving requires complementary sensors. Cameras provide dense semantics but unreliable depth, while millimeter-wave radar offers precise range and velocity measurements with sparse geometry. We propose MMF-BEV, a radar-camera BEV fusion framework that leverages deformable attention for cross-modal feature alignment on the View-of-Delft (VoD) 4D radar dataset [1]. MMF-BEV builds a BEVDepth [2] camera branch and a RadarBEVNet [3] radar branch, each enhanced with Deformable Self-Attention, and fuses them via a Deformable Cross-Attention module. We evaluate three configurations: camera-only, radar-only, and hybrid fusion. A sensor contribution analysis quantifies per-distance modality weighting, providing interpretable evidence of sensor complementarity. A two-stage training strategy - pre-training the camera branch with depth supervision, then jointly training radar and fusion modules stabilizes learning. Experiments on VoD show that MMF-BEV consistently outperforms unimodal baselines and achieves competitive results against prior fusion methods across all object classes in both the full annotated area and near-range Region of Interest.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MMF-BEV, a BEV-based radar-camera fusion framework for 3D object detection. It augments a BEVDepth camera branch and a RadarBEVNet radar branch with Deformable Self-Attention modules and fuses them via Deformable Cross-Attention. A two-stage training procedure (camera pre-training followed by joint optimization) and a sensor contribution analysis are included. Experiments on the View-of-Delft (VoD) 4D radar dataset claim that the hybrid model consistently outperforms unimodal baselines and achieves competitive results against prior fusion methods across object classes in both the full annotated area and near-range ROI.
Significance. If the empirical results hold, the work provides a concrete example of hybrid attention for multi-modal BEV fusion together with an interpretable sensor-contribution analysis that quantifies per-distance modality weighting. The two-stage training strategy is a practical detail that aids reproducibility. These elements could be useful for practitioners seeking stable camera-radar fusion without requiring entirely new backbone architectures.
major comments (1)
- [Method (Deformable Cross-Attention module)] The central claim that Deformable Cross-Attention successfully aligns sparse radar geometry with dense camera semantics and thereby produces the reported gains rests on an unverified assumption. No quantitative alignment diagnostics (predicted offset statistics, pre-/post-fusion feature similarity, or failure-case analysis on distant/sparse objects) are supplied, even though the sensor contribution analysis and two-stage training are described. This is load-bearing for the outperformance claim.
minor comments (1)
- [Abstract] The abstract asserts consistent outperformance and competitive results yet contains no numerical values, tables, or error bars; readers must reach the experimental section to evaluate the magnitude of the improvements.
Simulated Author's Rebuttal
We thank the referee for the valuable feedback. We respond to the major comment as follows and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Method (Deformable Cross-Attention module)] The central claim that Deformable Cross-Attention successfully aligns sparse radar geometry with dense camera semantics and thereby produces the reported gains rests on an unverified assumption. No quantitative alignment diagnostics (predicted offset statistics, pre-/post-fusion feature similarity, or failure-case analysis on distant/sparse objects) are supplied, even though the sensor contribution analysis and two-stage training are described. This is load-bearing for the outperformance claim.
Authors: We acknowledge that the manuscript does not provide the quantitative alignment diagnostics mentioned, which would indeed strengthen the validation of the Deformable Cross-Attention module. The sensor contribution analysis offers supporting evidence by showing how the fusion leverages each modality's strengths at different distances, and the two-stage training stabilizes the learning of cross-modal features. To address this directly, we will add predicted offset statistics, pre- and post-fusion feature similarity metrics, and a dedicated failure-case analysis on distant and sparse objects in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical architecture evaluated on external dataset
full rationale
The paper describes an empirical multi-modal fusion architecture (MMF-BEV) that combines existing BEVDepth and RadarBEVNet branches with added deformable attention modules, trained in two stages on the external View-of-Delft dataset and evaluated with standard 3D detection metrics. No mathematical derivation, uniqueness theorem, or first-principles prediction is claimed; performance results are obtained via explicit training and benchmarking against unimodal and prior fusion baselines. All cited components (BEVDepth, RadarBEVNet, VoD) are external references, and the sensor contribution analysis is a post-hoc empirical quantification rather than a self-referential fit. The framework is self-contained against external benchmarks with no reduction of claims to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multi-class road user detection with 3+ 1d radar in the view-of-delft dataset,
A. Palffy, E. Pool, S. Baratam, J. F. Kooij, and D. M. Gavrila, “Multi-class road user detection with 3+ 1d radar in the view-of-delft dataset,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 4961–4968, 2022
2022
-
[2]
Bevdepth: Acquisition of reliable depth for multi-view 3d object detection,
Y . Li, Z. Ge, G. Yu, J. Yang, Z. Wang, Y . Shi, J. Sun, and Z. Li, “Bevdepth: Acquisition of reliable depth for multi-view 3d object detection,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 2, 2023, pp. 1477–1485
2023
-
[3]
Rcbevdet: Radar-camera fusion in bird’s eye view for 3d object detection,
Z. Lin, Z. Liu, Z. Xia, X. Wang, Y . Wang, S. Qi, Y . Dong, N. Dong, L. Zhang, and C. Zhu, “Rcbevdet: Radar-camera fusion in bird’s eye view for 3d object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 928–14 937
2024
-
[4]
Delving into localization errors for monocular 3d object detection,
X. Ma, Y . Zhang, D. Xu, D. Zhou, S. Yi, H. Li, and W. Ouyang, “Delving into localization errors for monocular 3d object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 4721–4730
2021
-
[5]
Towards deep radar perception for autonomous driving: Datasets, methods, and challenges,
Y . Zhou, L. Liu, H. Zhao, M. L ´opez-Ben´ıtez, L. Yu, and Y . Yue, “Towards deep radar perception for autonomous driving: Datasets, methods, and challenges,”Sensors, vol. 22, no. 11, p. 4208, 2022
2022
-
[6]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unpro- jecting to 3d,
J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unpro- jecting to 3d,” inEuropean conference on computer vision. Springer, 2020, pp. 194–210
2020
-
[7]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to- end object detection,”arXiv preprint arXiv:2010.04159, 2020
work page internal anchor Pith review arXiv 2010
-
[8]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
J. Huang, G. Huang, Z. Zhu, Y . Ye, and D. Du, “Bevdet: High-performance multi-camera 3d object detection in bird-eye-view,”arXiv preprint arXiv:2112.11790, 2021
work page internal anchor Pith review arXiv 2021
-
[9]
arXiv preprint arXiv:2203.17054 (2022)
J. Huang and G. Huang, “Bevdet4d: Exploit temporal cues in multi-camera 3d object detection,”arXiv preprint arXiv:2203.17054, 2022
-
[10]
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “Bevformer: Learning bird’s-eye-view representa- tion from multi-camera images via spatiotemporal trans- formers.(2022),”URL https://arxiv. org/abs/2203.17270, vol. 10, 2022
-
[11]
Petr: Posi- tion embedding transformation for multi-view 3d object detection,
Y . Liu, T. Wang, X. Zhang, and J. Sun, “Petr: Posi- tion embedding transformation for multi-view 3d object detection,” inEuropean conference on computer vision. Springer, 2022, pp. 531–548
2022
-
[12]
Petrv2: A unified framework for 3d percep- tion from multi-camera images,
Y . Liu, J. Yan, F. Jia, S. Li, A. Gao, T. Wang, and X. Zhang, “Petrv2: A unified framework for 3d percep- tion from multi-camera images,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 3262–3272
2023
-
[13]
Ex- ploring object-centric temporal modeling for efficient multi-view 3d object detection,
S. Wang, Y . Liu, T. Wang, Y . Li, and X. Zhang, “Ex- ploring object-centric temporal modeling for efficient multi-view 3d object detection,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 3621–3631
2023
-
[14]
Centerfusion: Center-based radar and camera fusion for 3d object detection,
R. Nabati and H. Qi, “Centerfusion: Center-based radar and camera fusion for 3d object detection,” inProceed- ings of the IEEE/CVF winter conference on applications of computer vision, 2021, pp. 1527–1536
2021
-
[15]
Craft: Camera-radar 3d object detection with spatio-contextual fusion transformer,
Y . Kim, S. Kim, J. W. Choi, and D. Kum, “Craft: Camera-radar 3d object detection with spatio-contextual fusion transformer,” inProceedings of the AAAI Confer- ence on Artificial Intelligence, vol. 37, no. 1, 2023, pp. 1160–1168
2023
-
[16]
Crn: Camera radar net for accurate, robust, efficient 3d perception,
Y . Kim, J. Shin, S. Kim, I.-J. Lee, J. W. Choi, and D. Kum, “Crn: Camera radar net for accurate, robust, efficient 3d perception,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 17 615–17 626
2023
-
[17]
Rcfusion: Fusing 4-d radar and camera with bird’s-eye view features for 3-d object detection,
L. Zheng, S. Li, B. Tan, L. Yang, S. Chen, L. Huang, J. Bai, X. Zhu, and Z. Ma, “Rcfusion: Fusing 4-d radar and camera with bird’s-eye view features for 3-d object detection,”IEEE Transactions on Instrumentation and Measurement, vol. 72, pp. 1–14, 2023
2023
-
[18]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Bei- jbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
2020
-
[19]
Center-based 3d object detection and tracking,
T. Yin, X. Zhou, and P. Krahenbuhl, “Center-based 3d object detection and tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11 784–11 793
2021
-
[20]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recog- nition, 2016, pp. 770–778
2016
-
[21]
Second: Sparsely embedded convolutional detection,
Y . Yan, Y . Mao, and B. Li, “Second: Sparsely embedded convolutional detection,”Sensors, vol. 18, no. 10, p. 3337, 2018. [22]ISO/PAS 8800:2024 — Road vehicles — Safety and verification framework for AI-enabled systems, International Organization for Standardization (ISO) Std., 2024, accessed: 2026-03-02. [Online]. Available: https://www.iso.org/standard/...
2018
-
[22]
MMDetection3D: OpenMMLab next- generation platform for general 3D object detection,
M. Contributors, “MMDetection3D: OpenMMLab next- generation platform for general 3D object detection,” https://github.com/open-mmlab/mmdetection3d, 2020
2020
-
[23]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,”arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Pointpillars: Fast encoders for object detec- tion from point clouds,
A. H. Lang, S. V ora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detec- tion from point clouds,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 12 697–12 705
2019
-
[25]
aimotive dataset: A multimodal dataset for robust autonomous driving with long-range perception,
T. Matuszka, I. Barton, ´A. Butykai, P. Hajas, D. Kiss, D. Kov ´acs, S. Kuns ´agi-M´at´e, P. Lengyel, G. N ´emeth, L. Pet˝oet al., “aimotive dataset: A multimodal dataset for robust autonomous driving with long-range perception,” arXiv preprint arXiv:2211.09445, 2022
-
[26]
(2024) Physical AI Autonomous Ve- hicles Dataset: Devkit and Documentation
NVIDIA NVlabs. (2024) Physical AI Autonomous Ve- hicles Dataset: Devkit and Documentation
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.