Recognition: no theorem link
LiveFact: A Dynamic, Time-Aware Benchmark for LLM-Driven Fake News Detection
Pith reviewed 2026-05-10 20:27 UTC · model grok-4.3
The pith
LiveFact benchmark reveals that capable LLMs recognize unverifiable claims early when given evolving evidence on misinformation events.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
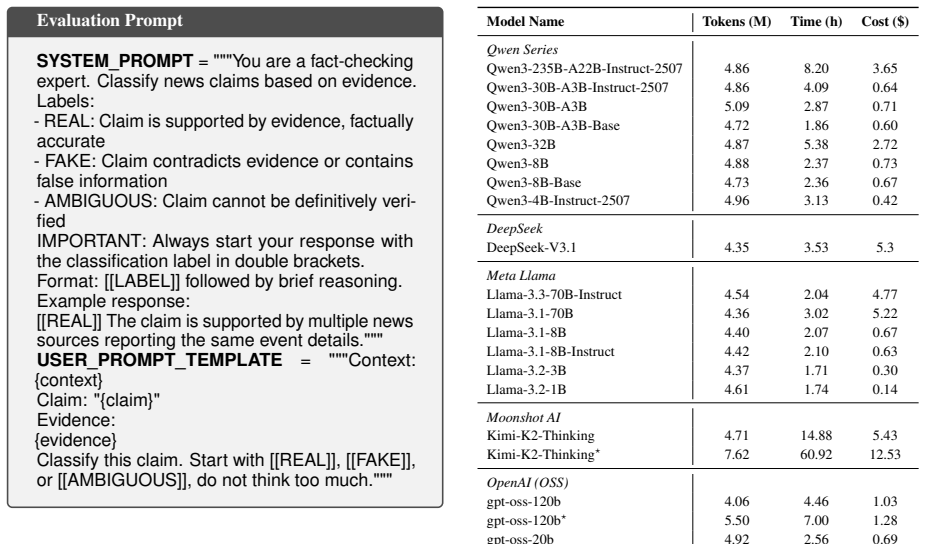
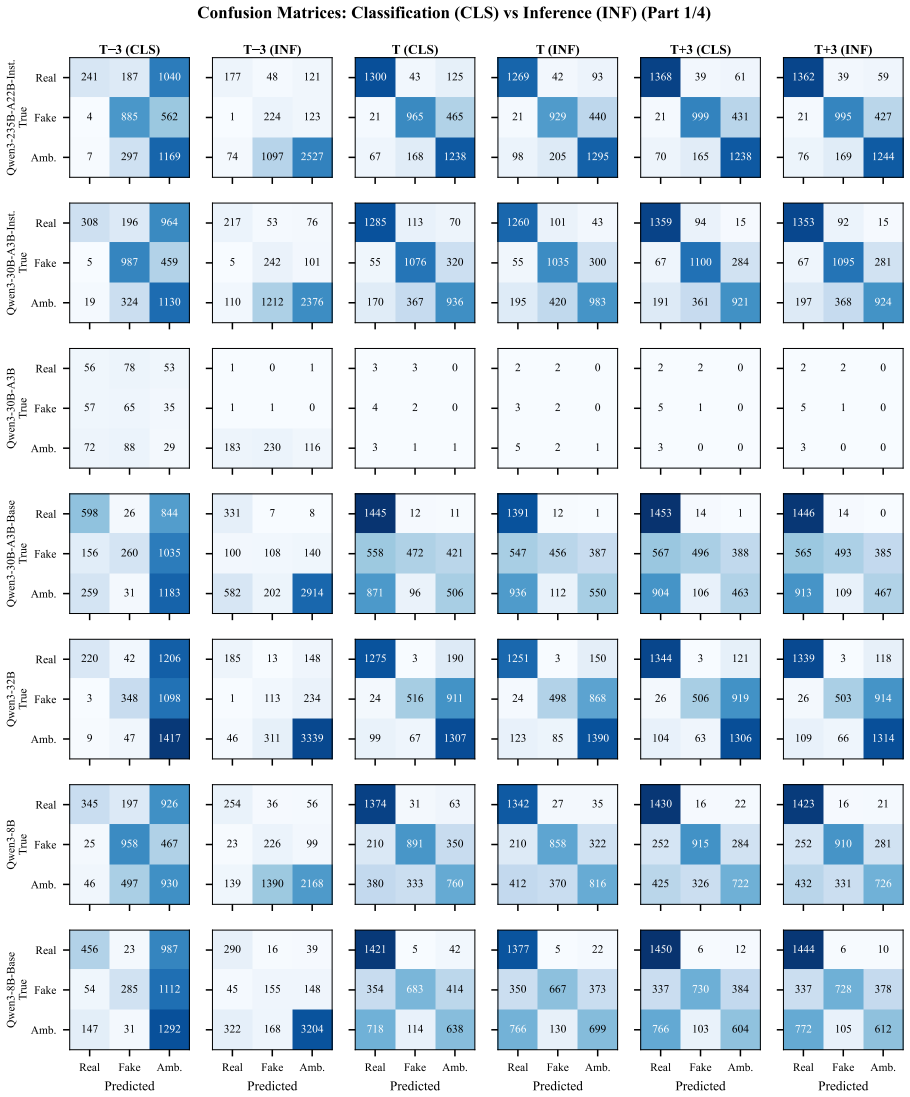
LiveFact supplies dynamic temporal evidence sets that evolve over successive time slices for each news event, paired with a dual-mode protocol that separately scores final classification and step-by-step inference. When applied to 22 LLMs, the protocol shows open-source mixture-of-experts models such as Qwen3-235B-A22B matching or surpassing proprietary systems on both modes while also demonstrating greater reluctance to render judgments on claims that remain unverifiable in early slices. An explicit contamination monitor tracks whether models exploit prior knowledge of the events.
What carries the argument
LiveFact's dynamic temporal evidence sets with dual-mode evaluation (classification and inference) and built-in benchmark data contamination monitoring.
If this is right
- Stronger models will increasingly refuse early judgments on breaking claims rather than guessing from incomplete data.
- Open-source mixture-of-experts architectures become viable substitutes for proprietary systems on time-sensitive verification tasks.
- Static benchmarks will systematically overestimate model reliability by allowing reliance on leaked future information.
- Evaluation pipelines must incorporate explicit checks for benchmark data contamination to remain trustworthy.
- Dual-mode scoring separates final accuracy from the quality of intermediate reasoning steps.
Where Pith is reading between the lines
- Adoption of similar dynamic slices could extend to other domains where information arrives incrementally, such as scientific claim verification or legal evidence review.
- The observed refusal behavior suggests training objectives that explicitly reward uncertainty detection may improve real-world deployment safety.
- If LiveFact-style updates become standard, model developers would need continuous access to fresh event streams rather than one-time dataset releases.
Load-bearing premise
The time-ordered evidence slices supplied by LiveFact reproduce the actual incompleteness and uncertainty of real misinformation events without injecting artificial inconsistencies or biases.
What would settle it
If the same set of events is presented to models once as static full-context documents and once as the paper's successive time slices, and no measurable difference appears in either accuracy or refusal rates, the value of the temporal structure would be refuted.
Figures










read the original abstract
The rapid development of Large Language Models (LLMs) has transformed fake news detection and fact-checking tasks from simple classification to complex reasoning. However, evaluation frameworks have not kept pace. Current benchmarks are static, making them vulnerable to benchmark data contamination (BDC) and ineffective at assessing reasoning under temporal uncertainty. To address this, we introduce LiveFact a continuously updated benchmark that simulates the real-world "fog of war" in misinformation detection. LiveFact uses dynamic, temporal evidence sets to evaluate models on their ability to reason with evolving, incomplete information rather than on memorized knowledge. We propose a dual-mode evaluation: Classification Mode for final verification and Inference Mode for evidence-based reasoning, along with a component to monitor BDC explicitly. Tests with 22 LLMs show that open-source Mixture-of-Experts models, such as Qwen3-235B-A22B, now match or outperform proprietary state-of-the-art systems. More importantly, our analysis finds a significant "reasoning gap." Capable models exhibit epistemic humility by recognizing unverifiable claims in early data slices-an aspect traditional static benchmarks overlook. LiveFact sets a sustainable standard for evaluating robust, temporally aware AI verification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LiveFact, a continuously updated, dynamic benchmark for evaluating LLMs on fake news detection that uses temporal evidence sets to simulate real-world uncertainty and avoid benchmark data contamination issues in static datasets. It proposes a dual-mode evaluation (Classification Mode for final verification and Inference Mode for evidence-based reasoning) with explicit BDC monitoring, and reports results from tests on 22 LLMs showing that open-source Mixture-of-Experts models (e.g., Qwen3-235B-A22B) match or outperform proprietary systems, while identifying a 'reasoning gap' in which capable models exhibit epistemic humility by recognizing unverifiable claims in early data slices.
Significance. If the temporal evidence construction holds, LiveFact could establish a more sustainable and realistic standard for assessing LLM robustness in misinformation detection, directly addressing limitations of static benchmarks like data contamination and lack of temporal reasoning evaluation. The explicit BDC monitoring component and the identification of the reasoning gap (epistemic humility on early slices) represent valuable contributions that traditional evaluations overlook. The finding that open-source MoE models can compete with proprietary ones is noteworthy if supported by rigorous metrics.
major comments (2)
- [Evaluation and Results] The central claims rest on results from 22 LLMs and the reasoning gap observation, but the abstract and available text provide no quantitative metrics, tables, statistical details, or full methodology for dataset construction and temporal slicing (e.g., how evidence sets evolve across time periods or how unverifiable claims are labeled). This is load-bearing for validating performance comparisons and the epistemic humility finding.
- [Benchmark Design] The dynamic temporal evidence sets are presented as accurately simulating the 'fog of war' without artificial biases, but no details are given on construction, validation against real events, or controls for inconsistencies (as highlighted in the weakest assumption). This directly affects the benchmark's claimed superiority over static methods.
minor comments (2)
- [Abstract] The abstract could include at least one key quantitative result or metric (e.g., accuracy delta or BDC rate) to strengthen the summary of findings.
- [Dual-mode evaluation] Clarify the exact operational definitions and differences between Classification Mode and Inference Mode, including any scoring rubrics or examples, to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. We have addressed each major comment below and revised the paper to incorporate additional details on results and benchmark design.
read point-by-point responses
-
Referee: [Evaluation and Results] The central claims rest on results from 22 LLMs and the reasoning gap observation, but the abstract and available text provide no quantitative metrics, tables, statistical details, or full methodology for dataset construction and temporal slicing (e.g., how evidence sets evolve across time periods or how unverifiable claims are labeled). This is load-bearing for validating performance comparisons and the epistemic humility finding.
Authors: We agree that the abstract and the version of the text provided for review lack the quantitative metrics, tables, and granular methodological details needed to fully substantiate the central claims. In the revised manuscript we have added a results table reporting accuracy, F1, and other metrics across all 22 models, included statistical significance tests and confidence intervals, and expanded Section 3 to describe the temporal slicing procedure, evidence evolution rules, and the exact criteria used to label unverifiable claims. These additions make the performance comparisons and the epistemic-humility observation directly verifiable. revision: yes
-
Referee: [Benchmark Design] The dynamic temporal evidence sets are presented as accurately simulating the 'fog of war' without artificial biases, but no details are given on construction, validation against real events, or controls for inconsistencies (as highlighted in the weakest assumption). This directly affects the benchmark's claimed superiority over static methods.
Authors: We accept that the original submission did not supply sufficient documentation of the evidence-set construction pipeline. The revised manuscript now contains an expanded subsection that details the data-collection timeline, the protocol for validating evidence slices against contemporaneous real-world records, and the specific consistency checks and bias-mitigation steps applied at each temporal boundary. These additions directly support the claim that LiveFact provides a more realistic evaluation setting than static benchmarks. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces a new dynamic benchmark (LiveFact) for evaluating LLMs on fake news detection under temporal uncertainty. Its core contributions are the benchmark construction itself, a dual-mode evaluation protocol, and empirical results from testing 22 independent LLMs. No derivation chain, mathematical prediction, or first-principles claim is present that reduces to fitted inputs or self-citations by construction. The reported performance patterns and 'reasoning gap' observations are direct outputs of applying the new benchmark to external models, with no self-definitional loops, renamed known results, or load-bearing self-citations. The work is self-contained as a proposal plus independent evaluation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Static benchmarks are vulnerable to benchmark data contamination (BDC)
- domain assumption Dynamic temporal evidence sets can effectively evaluate reasoning under uncertainty
invented entities (2)
-
LiveFact
no independent evidence
-
Dual-mode evaluation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2502.17521 , year=
Enhancing multi-hop fact verification with structured knowledge-augmented large language models.Proceedings of the AAAI Conference on Artificial Intelligence, 39(22):23514–23522. Jianhong Chen, Wenyi Zhang, Hongcai Ma, and Shan Yang. 2023. Rumor detection in social media based on multi-hop graphs and differential time series. Mathematics, 11(16). Sanxing ...
-
[2]
Unveiling the spectrum of data contamination in language model: A survey from detection to reme- diation. InFindings of the Association for Compu- tational Linguistics ACL 2024, pages 16078–16092, Bangkok, Thailand and virtual meeting. Association for Computational Linguistics. Shuzhi Gong, Richard O. Sinnott, Jianzhong Qi, and Cecile Paris. 2023. Fake ne...
-
[3]
gpt-oss-120b & gpt-oss-20b Model Card
Nela-gt-2018: A large multi-labelled news 11 dataset for the study of misinformation in news arti- cles.Proceedings of the International AAAI Confer- ence on Web and Social Media, 13(01):630–638. OpenAI, :, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Be...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
NLP evaluation in trouble: On the need to mea- sure LLM data contamination for each benchmark. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10776–10787, Sin- gapore. Association for Computational Linguistics. Mohammadamin Shafiei, Hamidreza Saffari, and Nafise Sadat Moosavi. 2025. MultiHoax: A dataset of multi-hop false-p...
-
[5]
Gemini: A family of highly capable multi- modal models.Preprint, arXiv:2312.11805. Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, and 150 others. 2025. Kimi k2: Open agentic...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
arXiv preprint arXiv:2406.04244 , year=
Piecing it all together: Verifying multi-hop multimodal claims. InProceedings of the 31st Inter- national Conference on Computational Linguistics, pages 7453–7469, Abu Dhabi, UAE. Association for Computational Linguistics. William Yang Wang. 2017. “liar, liar pants on fire”: A new benchmark dataset for fake news detection. InProceedings of the 55th Annual...
-
[7]
Don’t make your llm an evaluation benchmark cheater
Mrr-fv: Unlocking complex fact verification with multi-hop retrieval and reasoning.Proceedings of the AAAI Conference on Artificial Intelligence, 39(24):26066–26074. Kun Zhou, Yutao Zhu, Zhipeng Chen, Wentong Chen, Wayne Xin Zhao, Xu Chen, Yankai Lin, Ji-Rong Wen, and Jiawei Han. 2023. Don’t make your llm an evaluation benchmark cheater.Preprint, arXiv:23...
-
[8]
Focus ONL Y on identifying who/what the main entities are
-
[9]
Provide brief, factual descriptions (roles, posi- tions, basic facts)
-
[10]
Keep it concise - 2-3 sentences maximum
-
[11]
Do NOT explain the event itself, only the enti- ties involved
-
[12]
Trump to meet with Xi as he travels to Asia to contain trade war
Do NOT add unnecessary details or back- ground **Example**: Event: "Trump to meet with Xi as he travels to Asia to contain trade war" Context: "Trump is a businessman and politician, currently serving as the President of the United States. Xi is the President of China." **Output Format** (JSON): {{ "context": "your context text here" }} **Y our JSON outpu...
2025
-
[13]
Directly supported by the evidence above
-
[14]
Verifiable and accurate
-
[16]
Uses specific details from the evidence
-
[17]
claim_text
Does NOT add any unverified information **Output Format** (JSON): {{ "claim_text": "your factual claim here" }} **Y our JSON output**: Figure 6: Prompt for Real Claim Generation • Llama Family:Includes both the standard Dense architecture (Llama 3.1 70B/8B) and recent lightweight variants (Llama 3.2 3B/1B), serving as the baseline for open-weights per- fo...
2024
-
[18]
Related to the event but NOT supported by evidence
-
[19]
Contains fabricated details (false numbers, fake quotes, wrong people, etc.)
-
[20]
Sounds plausible but is factually incorrect
-
[21]
Written as a standalone news statement (1-2 sentences)
-
[22]
claim_text
Could mislead someone unfamiliar with the real story **Important**: Make it realistic fake news, not obviously absurd. **Output Format** (JSON): {{ "claim_text": "your fabricated claim here" }} **Y our JSON output**: Figure 7: Prompt for Fake Claim Generation general-purpose models to the absolute peak of computational power. B.2 Evaluation Settings To en...
2023
-
[23]
He signed the bill *specifically to appease his donors*
**Imputed Intent**: State a public figure’s private, internal motivation for a verifiable action as an objective fact (e.g., "He signed the bill *specifically to appease his donors*")
-
[24]
The stock drop *was a calculated response to* the leaked memo
**False Causality**: Connect two unrelated real facts as direct cause-and-effect without proof (e.g., "The stock drop *was a calculated response to* the leaked memo")
-
[25]
The negotiations ended in *an atmosphere of mutual distrust*
**Subjective Framing**: Use unverifiable, qualitative descriptors to characterize a verifiable event (e.g., "The negotiations ended in *an atmosphere of mutual distrust*")
-
[26]
The diplomat *refused to shake hands* before the meeting started
**Micro-Events**: Insert a plausible but unrecorded specific physical action into a real event (e.g., "The diplomat *refused to shake hands* before the meeting started")
-
[27]
The CEO *arrived 15 minutes late* to the conference
**Unfolding Details**: Add unverifiable specifics about the timing, location, or participants of a verifiable event (e.g., "The CEO *arrived 15 minutes late* to the conference", "Trump extended a dinner invitation to the Chinese delegation after the meeting", but this detail was not included in the evidence). **Goal**: The claim should sound like a confid...
-
[28]
Replace ALL named entities (people, organizations, cities, locations, nationalities, races) with fictional alternatives, ensure these names are not widely recognized
-
[29]
Trump" →
Use simple, uncommon but plausible names (e.g., "Trump" → "Korwin", "United States" → "Northland", "BBC"→"GBN")
-
[30]
Keep entity types consistent (person→person, country→country, organization→organization)
-
[31]
Preserve ALL other information (dates, numbers, events, relationships, facts)
-
[32]
Ensure the SAME entity always maps to the SAME fictional name across ALL fields
-
[33]
"" ENTITY_SHIFT_PROMPT=
Output valid JSON only, no markdown code blocks, no explanations""" ENTITY_SHIFT_PROMPT= """Perform entity shifting on the following news data. Replace all named entities with fictional alternatives while preserving semantic meaning. **Original Event Title**: {event_title} **Original Context**: {context} **Original Claim**: {claim} **Original Evidence Tit...
-
[34]
Identify ALL named entities: PERSON names, ORGANIZATION names, LOCATION names, NATIONALITY terms
-
[35]
Replace each with a LESS RECOGNIZABLE fictional alternative
-
[36]
Prince Andrew
Use simple, uncommon but plausible names (e.g., "Prince Andrew" → "Lord Harwick", "Buckingham Palace"→"Thornfield Manor", "United Kingdom"→"Alberia")
-
[37]
Keep entity types consistent (person→person, palace→palace, country→country)
-
[38]
PRESERVE all roles, positions, relationships, dates, numbers, and facts - ONL Y change entity names
-
[39]
Ensure CONSISTENT mapping: the SAME original entity ALWAYS maps to the SAME fictional name in ALL fields
-
[40]
Do NOT change news source names (BBC, Reuters, etc.) - these are metadata, not content entities
-
[41]
entity_mapping
Evidence titles should use the SAME entity mapping as claim, context, and event_title **Output Format** (JSON only, NO markdown, NO code blocks, NO explanations): {{ "entity_mapping": {{ "Original Entity 1": "Fictional Name 1", "Original Entity 2": "Fictional Name 2" }}, "event_title_shifted": "shifted event title here", "context_shifted": "shifted contex...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.