Recognition: 2 theorem links
· Lean TheoremANX: Protocol-First Design for AI Agent Interaction with a Supporting 3EX Decoupled Architecture
Pith reviewed 2026-05-10 18:38 UTC · model grok-4.3
The pith
ANX protocol unifies AI agent interactions via markup and decoupled architecture to cut token use and add native security.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
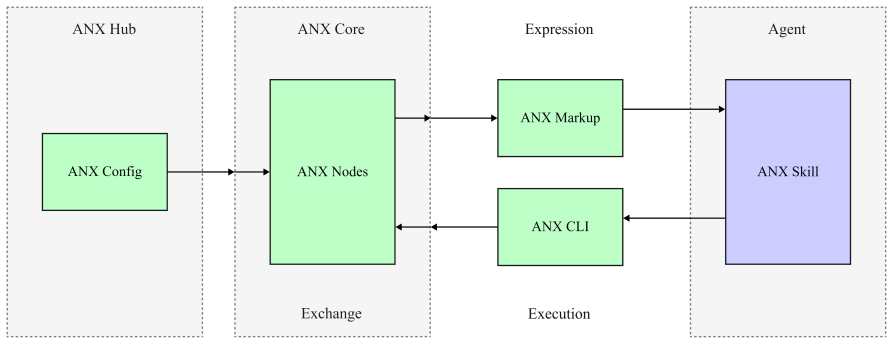
ANX is an open extensible verifiable agent-native protocol integrating CLI, Skill, and MCP through a 3EX decoupled architecture with ANXHub. Its agent-native design uses ANX Config, Markup, and CLI for high information density and adaptability. Skills provide flexible dual rendering as executable instructions and human UI. MCP enables lightweight apps without pre-registration. ANX Markup produces unambiguous machine-executable SOPs for long-horizon tasks and multi-agent collaboration. Security is achieved via LLM-bypassed UI-to-Core paths and human-only confirmations. Form-filling tests confirm lower token counts and shorter runtimes than MCP or GUI approaches.
What carries the argument
ANX Markup for high-density executable instructions and the 3EX decoupled architecture that integrates CLI, Skill, and MCP while separating execution concerns.
If this is right
- Long-horizon and multi-agent tasks gain reliability from unambiguous machine-executable SOPs.
- Overall token consumption drops, reducing costs for LLM-based agent operations.
- Security improves because sensitive data stays out of the agent context and actions require human approval.
- Human-agent handoff becomes smoother through skills that render as both instructions and UI.
Where Pith is reading between the lines
- Widespread use could standardize how agents connect to tools and interfaces across platforms.
- Application developers might design outputs natively in ANX Markup to gain automatic agent compatibility.
- The approach invites testing on non-form tasks to check if efficiency holds when task complexity increases.
Load-bearing premise
The token and time savings from limited form-filling tests with two models will generalize to diverse real-world agent tasks and that the security features hold without introducing new vulnerabilities.
What would settle it
Running the token and execution time comparison on a wider range of tasks such as multi-step web navigation or collaborative planning, or testing whether an agent can access protected data despite the UI-to-Core bypass.
Figures






read the original abstract
AI agents, autonomous digital actors, need agent-native protocols; existing methods include GUI automation and MCP-based skills, with defects of high token consumption, fragmented interaction, inadequate security, due to lacking a unified top-level framework and key components, each independent module flawed. To address these issues, we present ANX, an open, extensible, verifiable agent-native protocol and top-level framework integrating CLI, Skill, MCP, resolving pain points via protocol innovation, architectural optimization and tool supplementation. Its four core innovations: 1) Agent-native design (ANX Config, Markup, CLI) with high information density, flexibility and strong adaptability to reduce tokens and eliminate inconsistencies; 2) Human-agent interaction combining Skill's flexibility for dual rendering as agent-executable instructions and human-readable UI; 3) MCP-supported on-demand lightweight apps without pre-registration; 4) ANX Markup-enabled machine-executable SOPs eliminating ambiguity for reliable long-horizon tasks and multi-agent collaboration. As the first in a series, we focus on ANX's design, present its 3EX decoupled architecture with ANXHub and preliminary feasibility analysis and experimental validation. ANX ensures native security: LLM-bypassed UI-to-Core communication keeps sensitive data out of agent context; human-only confirmation prevents automated misuse. Form-filling experiments with Qwen3.5-plus/GPT-4o show ANX reduces tokens by 47.3% (Qwen3.5-plus) and 55.6% (GPT-4o) vs MCP-based skills, 57.1% (Qwen3.5-plus) and 66.3% (GPT-4o) vs GUI automation, and shortens execution time by 58.1% and 57.7% vs MCP-based skills.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ANX, an open agent-native protocol and top-level framework that integrates CLI, Skill, and MCP components via a 3EX decoupled architecture (with ANXHub) to address high token consumption, fragmented interactions, and security shortcomings in GUI automation and MCP-based skills. Core innovations include ANX Config/Markup/CLI for high-density agent-native design, dual-rendered human-agent skills, on-demand MCP apps, and Markup-enabled machine-executable SOPs for long-horizon and multi-agent reliability. The manuscript presents the architecture, security features (LLM-bypassed UI-to-Core paths and human confirmation), and preliminary experimental validation limited to form-filling tasks with Qwen3.5-plus and GPT-4o, reporting token reductions of 47.3–66.3% and time reductions of ~58% versus baselines.
Significance. If the protocol design and security properties generalize, ANX could offer a unified, extensible foundation for more efficient and verifiable AI agent interactions, with explicit strengths in its protocol-first approach, open extensibility, and LLM-bypassed security mechanisms that keep sensitive data out of agent context. The preliminary experiments provide concrete quantitative evidence of token and time savings in at least one task class, which is a positive step toward falsifiable claims.
major comments (3)
- [Abstract] Abstract: The headline performance claims (47.3% token reduction for Qwen3.5-plus vs MCP-based skills, 55.6% vs GPT-4o, up to 66.3% vs GUI automation, and ~58% time reduction) rest exclusively on form-filling experiments; no quantitative results are reported for the long-horizon tasks or multi-agent collaboration that the design section asserts are enabled by ANX Markup's elimination of ambiguity. This gap means the central assertion that ANX resolves the general defects of existing methods does not follow from the presented evidence.
- [Abstract] Abstract (experimental validation paragraph): The reported token and time savings lack any description of test setup, number of trials, statistical measures (e.g., variance or significance tests), full baseline implementations, or task complexity metrics. Without these, the quantitative claims cannot be assessed for robustness or reproducibility, directly undermining the feasibility analysis that is positioned as supporting the protocol's broader applicability.
- [Design section] Design section (four core innovations): The claim that ANX Markup enables 'reliable long-horizon tasks and multi-agent collaboration' by eliminating ambiguity is presented as a key innovation, yet the manuscript provides only descriptive architecture details and no formal verification, simulation results, or even qualitative case studies on such tasks. This leaves the load-bearing assertion about general defect resolution unsupported beyond the narrow form-filling scope.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from explicit cross-references to the specific sections describing the 3EX architecture and ANXHub implementation to improve readability for readers unfamiliar with the decoupled design.
- [Introduction] Notation for the four core innovations is listed numerically but not tied to later sections or figures; adding section pointers would clarify how each innovation maps to the 3EX components.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the current manuscript is a preliminary design paper with experimental validation limited to form-filling tasks, and we will revise to better scope the claims, add methodological details to the abstract, and distinguish design assertions from empirical results. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance claims (47.3% token reduction for Qwen3.5-plus vs MCP-based skills, 55.6% vs GPT-4o, up to 66.3% vs GUI automation, and ~58% time reduction) rest exclusively on form-filling experiments; no quantitative results are reported for the long-horizon tasks or multi-agent collaboration that the design section asserts are enabled by ANX Markup's elimination of ambiguity. This gap means the central assertion that ANX resolves the general defects of existing methods does not follow from the presented evidence.
Authors: We agree that the quantitative results are confined to form-filling tasks. The manuscript is explicitly the first in a series and centers on protocol design and 3EX architecture, using form-filling as an initial feasibility check. Assertions about long-horizon tasks and multi-agent collaboration stem from ANX Markup's production of machine-executable SOPs that remove ambiguity, but these are design properties rather than empirically demonstrated outcomes in this paper. We will revise the abstract to state that the reported savings are preliminary and specific to form-filling, while qualifying the broader benefits as enabled by the architecture and slated for future validation. revision: partial
-
Referee: [Abstract] Abstract (experimental validation paragraph): The reported token and time savings lack any description of test setup, number of trials, statistical measures (e.g., variance or significance tests), full baseline implementations, or task complexity metrics. Without these, the quantitative claims cannot be assessed for robustness or reproducibility, directly undermining the feasibility analysis that is positioned as supporting the protocol's broader applicability.
Authors: The referee correctly notes that the abstract's summary of results is insufficiently detailed. Although the full manuscript contains an experimental section, the abstract paragraph is too brief. We will revise it to include summaries of the test setup, number of trials, any statistical measures (means and variance where available), baseline implementation details, and task complexity metrics drawn from the experimental section. This will improve transparency and allow readers to evaluate reproducibility. revision: yes
-
Referee: [Design section] Design section (four core innovations): The claim that ANX Markup enables 'reliable long-horizon tasks and multi-agent collaboration' by eliminating ambiguity is presented as a key innovation, yet the manuscript provides only descriptive architecture details and no formal verification, simulation results, or even qualitative case studies on such tasks. This leaves the load-bearing assertion about general defect resolution unsupported beyond the narrow form-filling scope.
Authors: We concur that support for long-horizon and multi-agent reliability is currently descriptive only. ANX Markup is intended to generate machine-executable SOPs that eliminate natural-language ambiguity, which logically supports reliable execution, but no simulations, case studies, or verification are provided. We will revise the design section to present this as an architectural property with explicit caveats that empirical validation lies outside the scope of this preliminary paper, and we will add a limitations/future-work subsection to delineate what has been shown versus what is planned. revision: yes
- We cannot supply new quantitative or qualitative results for long-horizon tasks or multi-agent collaboration in this revision, as those experiments have not been performed and are reserved for follow-up papers in the series.
Circularity Check
No circularity; empirical comparisons are independent of design claims
full rationale
The paper describes a protocol design (ANX Config, Markup, CLI, 3EX architecture) and reports direct experimental measurements of token/time reductions versus MCP and GUI baselines in form-filling tasks. No equations, fitted parameters, or derivations are present that reduce to the inputs by construction. No self-citations are invoked to justify uniqueness or load-bearing premises. The performance numbers are measured outputs from external model runs, not renamed fits or self-referential definitions. Lack of long-horizon results is an evidence gap, not a circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing GUI automation and MCP-based skills suffer from high token use, fragmentation, and security gaps due to lack of unified framework.
invented entities (3)
-
ANX protocol
no independent evidence
-
3EX decoupled architecture
no independent evidence
-
ANX Markup
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ANX Markup... high information density... 3EX decoupled architecture... UI-to-Core communication... SOP ANX Config with sources/targets
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Form-filling experiments... token reduction 47.3–66.3 %
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anthropic. (2024). Model Context Protocol (MCP). https://github.com/modelcontextprotocol. Accessed: 2026-04-05
2024
-
[2]
Ben Hassouna, A., Chaari, H., & Belhaj, I. (2026). LLM-Agent-UMF: LLM-based Agent Unified Modeling Framework. Information Fusion, 127, 103865
2026
- [3]
-
[4]
Chen, J., Li, Z., Jiang, Y., et al. (2026). The Era of Skill Growing Agents: Shift from Task Execution to Skill Growth. TechRxiv. Preprint. doi:10.36227/techrxiv.177041975.54183859
-
[5]
Dhuliawala, S., Komeili, M., Xu, J., Raileanu, R., Li, X., Celikyilmaz, A., & Weston, J. (2024). Chain-of-Verification Reduces Hallucination in Large Language Models. In Findings of the Association for Computational Linguistics: ACL 2024 (pp. 3563–3578). Bangkok, Thailand: ACL
2024
- [6]
- [7]
- [8]
-
[9]
Grab Engineering. (2025). Introducing the SOP-driven LLM agent frameworks. Grab Engineering Blog. https://engineering.grab.com/introducing-the-sop-drive-llm-agent-framework. Accessed: 2026-04-06
2025
-
[10]
R., et al
Kasibatla, S. R., et al. (2025). The Command Line GUIde: Graphical Interfaces from Man Pages via AI. In Proceedings of the IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC) (pp. 1–5). IEEE
2025
- [11]
- [12]
- [13]
-
[14]
G., Zhang, T., Wang, X., & Gonzalez, J
Patil, S. G., Zhang, T., Wang, X., & Gonzalez, J. E. (2024). Gorilla: Large Language Model Connected with Massive APIs. In Advances in Neural Information Processing Systems, Vol. 37 (pp. 126544–126565). NeurIPS
2024
-
[15]
What Did It Actually Do?: Understanding risk awareness and traceability for computer-use agents,
Peng, Z. (2026). “What Did It Actually Do?”: Understanding Risk Awareness and Traceability for Computer-Use Agents. arXiv preprint arXiv:2603.28551
-
[16]
Rosenberg, J., White, P., & Jennings, C. F. (2025). CHEQ: A Protocol for Confirmation AI Agent Decisions with Human in the Loop (HITL). IETF Internet-Draft draft-rosenberg-aiproto-cheq-00. https://datatracker.ietf.org/doc/draft-rosenberg-aiproto-cheq/00/
2025
- [17]
-
[18]
Wang, Z., Wang, Y., Liu, X., et al. (2025). AgentDropout: Dynamic Agent Elimination for Token-Efficient and High-Performance LLM-Based Multi-Agent Collaboration. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025) (pp. 24013–24035). ACL
2025
-
[19]
Z., Shao, Y., Shaikh, O., et al
Wang, Z. Z., Shao, Y., Shaikh, O., et al. (2025). How Do AI Agents Do Human Work? Comparing AI and Human Workflows Across Diverse Occupations. Carnegie Mellon University & Stanford University. Technical report
2025
-
[20]
H., Le, Q
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, F., Chi, E. H., Le, Q. V., & Zhou, D. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In Advances in Neural Information Processing Systems, Vol. 35. NeurIPS
2022
-
[21]
Xie, T., Ran, D.-Z., Cao, Y., et al. (2026). From User Operations to Agentic Automation: Toward Intent-Oriented Software in the LLM Era. Journal of Computer Science and Technology, 41(2), 1–18
2026
-
[22]
Yuan, D., et al. (2026). Beyond Message Passing: Toward Semantically Aligned Agent Communication. arXiv preprint arXiv:2604.02369
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [23]
-
[24]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Zheng, B., Fatemi, M. Y., Jin, X., Wang, Z. Z., Gandhi, A., Song, Y., Gu, Y., Srinivasa, J., Liu, G., Neubig, G., et al. (2025). SkillWeaver: Web Agents Can Self-Improve by Discovering and Honing Skills. arXiv preprint arXiv:2504.07079
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.