Recognition: 3 theorem links
· Lean TheoremFree-Range Gaussians: Non-Grid-Aligned Generative 3D Gaussian Reconstruction
Pith reviewed 2026-05-10 19:45 UTC · model grok-4.3
The pith
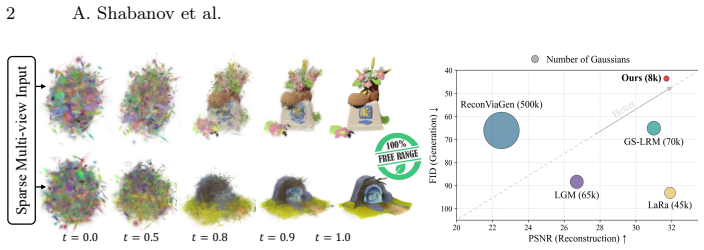
Free-Range Gaussians generates non-grid-aligned 3D Gaussians from four images via flow matching to synthesize missing regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Free-Range Gaussians predicts non-pixel, non-voxel-aligned 3D Gaussians from as few as four images through flow matching over Gaussian parameters. The generative formulation allows supervision with non-grid-aligned 3D data and synthesis of plausible content in unobserved regions, improving on methods that produce redundant grid-aligned Gaussians with holes or blurry conditional means in missing areas. A hierarchical patching scheme groups spatially related Gaussians to halve sequence length, while a timestep-weighted rendering loss, photometric gradient guidance, and classifier-free guidance further improve fidelity.
What carries the argument
Flow matching over Gaussian parameters with a hierarchical patching scheme that groups spatially related Gaussians into joint transformer tokens.
Load-bearing premise
Flow matching over Gaussian parameters combined with hierarchical patching can accurately capture the distribution of non-aligned 3D Gaussians without introducing artifacts or requiring post-hoc alignment.
What would settle it
Direct comparison on held-out objects with partially occluded regions would show whether the method produces fewer holes or lower error in unobserved areas than grid-aligned baselines when evaluated against ground-truth geometry.
Figures








read the original abstract
We present Free-Range Gaussians, a multi-view reconstruction method that predicts non-pixel, non-voxel-aligned 3D Gaussians from as few as four images. This is done through flow matching over Gaussian parameters. Our generative formulation of reconstruction allows the model to be supervised with non-grid-aligned 3D data, and enables it to synthesize plausible content in unobserved regions. Thus, it improves on prior methods that produce highly redundant grid-aligned Gaussians, and suffer from holes or blurry conditional means in unobserved regions. To handle the number of Gaussians needed for high-quality results, we introduce a hierarchical patching scheme to group spatially related Gaussians into joint transformer tokens, halving the sequence length while preserving structure. We further propose a timestep-weighted rendering loss during training, and photometric gradient guidance and classifier-free guidance at inference to improve fidelity. Experiments on Objaverse and Google Scanned Objects show consistent improvements over pixel and voxel-aligned methods while using significantly fewer Gaussians, with large gains when input views leave parts of the object unobserved.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Free-Range Gaussians, a multi-view 3D reconstruction technique that generates non-grid-aligned 3D Gaussians from as few as four input images via flow matching over Gaussian parameters. It incorporates a hierarchical patching scheme to efficiently handle large numbers of Gaussians by grouping them into transformer tokens, a timestep-weighted rendering loss for training, and photometric gradient guidance along with classifier-free guidance during inference. The approach is evaluated on the Objaverse and Google Scanned Objects datasets, demonstrating improvements over pixel- and voxel-aligned methods with fewer Gaussians, particularly in synthesizing content for unobserved regions.
Significance. If the empirical results hold under detailed scrutiny, this work could be significant for the field of 3D reconstruction and novel view synthesis. By adopting a generative formulation with free-range Gaussians, it addresses limitations of prior grid-aligned methods such as redundancy and poor performance in unobserved areas. The introduction of hierarchical patching and specific guidance techniques represents a practical advance in scaling generative models for 3D Gaussians. Credit is due for the benchmark comparisons on Objaverse and Google Scanned Objects and the emphasis on efficiency with fewer primitives.
major comments (2)
- [Abstract] Abstract: the claim of 'consistent improvements' and 'large gains' when input views leave parts unobserved is load-bearing for the central contribution, yet the provided text supplies no specific quantitative metrics (e.g., PSNR, SSIM, or Gaussian count reductions) or ablation tables to substantiate the magnitude of these gains relative to baselines.
- [Method] Method (hierarchical patching description): the assertion that spatial grouping 'halves the sequence length while preserving structure' is central to handling variable-cardinality Gaussians, but the exact tokenization rule, rotation/scale parameterization within flow matching, and any post-grouping alignment step are not specified with sufficient equations or pseudocode to verify absence of artifacts.
minor comments (2)
- [Abstract] Abstract: the phrase 'non-pixel, non-voxel-aligned' would benefit from a one-sentence clarification of how the Gaussian parameters are initialized and optimized without any implicit grid constraint.
- [Experiments] Experiments: ensure all flow-matching hyperparameters, guidance scales, and the exact number of Gaussians per scene are reported in a table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent improvements' and 'large gains' when input views leave parts unobserved is load-bearing for the central contribution, yet the provided text supplies no specific quantitative metrics (e.g., PSNR, SSIM, or Gaussian count reductions) or ablation tables to substantiate the magnitude of these gains relative to baselines.
Authors: We agree that the abstract would benefit from including specific quantitative metrics to support the claims of consistent improvements and large gains. The full paper provides detailed comparisons in the experiments section, including PSNR, SSIM, and the number of Gaussians used. To make this more prominent, we will revise the abstract to incorporate key results, such as the reported improvements over baselines and the reduction in Gaussian count, particularly highlighting the gains in unobserved regions. revision: yes
-
Referee: [Method] Method (hierarchical patching description): the assertion that spatial grouping 'halves the sequence length while preserving structure' is central to handling variable-cardinality Gaussians, but the exact tokenization rule, rotation/scale parameterization within flow matching, and any post-grouping alignment step are not specified with sufficient equations or pseudocode to verify absence of artifacts.
Authors: We thank the referee for this detailed comment on the hierarchical patching scheme. Upon review, we acknowledge that additional specificity could aid in understanding and reproducibility. In the revised version, we will include more detailed equations describing the tokenization rule for grouping Gaussians, the parameterization of rotation and scale within the flow matching framework, and clarify any post-grouping alignment procedures to ensure there are no artifacts introduced. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper's core derivation introduces flow matching over free Gaussian parameters, hierarchical patching to manage sequence length, a timestep-weighted rendering loss, and inference-time guidance mechanisms. These are presented as new architectural and training choices that enable supervision on non-grid-aligned data and plausible synthesis in unobserved regions. No equation or claim reduces a prediction to a fitted input by construction, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled via prior work. The generative formulation is self-contained against external benchmarks such as Objaverse and Google Scanned Objects experiments, with the central improvements (fewer Gaussians, better unobserved-region handling) arising from the stated components rather than tautological redefinition.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We frame sparse-view reconstruction as a generative task... flow matching [29] to model the conditional distribution of 3D Gaussians... hierarchical tree structure... patchification strategy that cuts the number of tokens in half
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use the standard parameterization of 3D Gaussians by mean position, log-scale, quaternion rotation...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The combined training loss is L = L_FM + w(t)·(R_Held + R_Seen)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Lyra 2.0: Explorable Generative 3D Worlds
Lyra 2.0 produces persistent 3D-consistent video sequences for large explorable worlds by using per-frame geometry for information routing and self-augmented training to correct temporal drift.
Reference graph
Works this paper leans on
-
[1]
In: ICLR (2026) Free-Range Gaussians 15
Bahmani, S., Shen, T., Ren, J., Huang, J., Jiang, Y., Turki, H., Tagliasacchi, A., Lindell, D.B., Gojcic, Z., Fidler, S., Ling, H., Gao, J., Ren, X.: Lyra: Generative 3D scene reconstruction via video diffusion model self-distillation. In: ICLR (2026) Free-Range Gaussians 15
2026
-
[2]
In: ICLR (2026)
Chang, J., Ye, C., Wu, Y., Chen, Y., Zhang, Y., Luo, Z., Li, C., Zhi, Y., Han, X.: ReconViaGen: Towards accurate multi-view 3D object reconstruction via generation. In: ICLR (2026)
2026
-
[3]
In: CVPR (2024)
Charatan, D., Li, S., Tagliasacchi, A., Sitzmann, V.: pixelSplat: 3D Gaussian splats from image pairs for scalable generalizable 3D reconstruction. In: CVPR (2024)
2024
-
[4]
In: ECCV (2024)
Chen, A., Xu, H., Esposito, S., Tang, S., Geiger, A.: LaRa: Efficient large-baseline radiance fields. In: ECCV (2024)
2024
-
[5]
In: ICCV (2021)
Chen, A., Xu, Z., Zhao, F., Zhang, X., Xiang, F., Yu, J., Su, H.: MVSNeRF: Fast generalizable radiance field reconstruction from multi-view stereo. In: ICCV (2021)
2021
- [6]
-
[7]
In: ECCV (2024)
Chen, Y., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T.J., Cai, J.: MVSplat: Efficient 3D Gaussian splatting from sparse multi-view images. In: ECCV (2024)
2024
-
[8]
Child, R., Gray, S., Radford, A., Sutskever, I.: Generating long sequences with sparse transformers (2019), arXiv:1904.10509
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[9]
In: ICLR (2024)
Darcet, T., Oquab, M., Mairal, J., Bojanowski, P.: Vision transformers need registers. In: ICLR (2024)
2024
-
[10]
In: CVPR (2023)
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3D objects. In: CVPR (2023)
2023
-
[11]
Downs, L., Francis, A., Koenig, N., Kinman, B., Hickman, R., Reymann, K., McHugh, T.B., Vanhoucke, V.: Google Scanned Objects: A high-quality dataset of 3D scanned household items. In: ICRA (2022).https://doi.org/10.1109/ ICRA46639.2022.9811809
-
[12]
In: NeurIPS (2023)
Fu, S., Tamir, N., Sundaram, S., Chai, L., Zhang, R., Dekel, T., Isola, P.: DreamSim: Learning new dimensions of human visual similarity using synthetic data. In: NeurIPS (2023)
2023
-
[13]
Henry, A., Dachapally, P.R., Pawar, S.S., Chen, Y.: Query-key normalization for transformers.In:FindingsoftheAssociationforComputationalLinguistics:EMNLP
-
[14]
4246–4253 (2020)
pp. 4246–4253 (2020)
2020
-
[15]
In: NIPS (2017)
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: GANs trained by a two time-scale update rule converge to a local nash equilibrium. In: NIPS (2017)
2017
-
[16]
In: NeurIPS Workshops (2021)
Ho, J., Salimans, T.: Classifier-free diffusion guidance. In: NeurIPS Workshops (2021)
2021
-
[17]
In: ICLR (2024)
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: LRM: Large reconstruction model for single image to 3D. In: ICLR (2024)
2024
-
[18]
ACM Trans
Jiang, L., Mao, Y., Xu, L., Lu, T., Ren, K., Jin, Y., Xu, X., Yu, M., Pang, J., Zhao, F., Lin, D., Dai, B.: AnySplat: Feed-forward 3D Gaussian splatting from unconstrained views. ACM Trans. Graph. (2025)
2025
-
[19]
In: International conference on machine learning
Katharopoulos, A., Vyas, A., Pappas, N., Fleuret, F.: Transformers are RNNs: Fast autoregressive transformers with linear attention. In: International conference on machine learning. pp. 5156–5165. PMLR (2020)
2020
-
[20]
In: 3DV (2026) 16 A
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., Luiten, J., Lopez-Antequera, M., Bulò, S.R., Richardt, C., Ramanan, D., Scherer, S., Kontschieder, P.: MapAnything: Universal feed-forward metric 3D reconstruction. In: 3DV (2026) 16 A. Shabanov et al
2026
-
[21]
https://doi.org/10.1145/3592433 Xiaonan Kong and Riley G
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3D Gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139:1–14 (2023). https://doi.org/10.1145/3592433
-
[22]
Kerbl, B., Meuleman, A., Kopanas, G., Wimmer, M., Lanvin, A., Drettakis, G.: A hierarchical3DGaussianrepresentationforreal-timerenderingofverylargedatasets. ACM Trans. Graph.43(4), 62:1–15 (2024).https://doi.org/10.1145/3658160
-
[23]
In: NeurIPS (2024)
Kheradmand, S., Rebain, D., Sharma, G., Sun, W., Tseng, J., Isack, H., Kar, A., Tagliasacchi, A., Yi, K.M.: 3D Gaussian splatting as Markov chain Monte Carlo. In: NeurIPS (2024)
2024
- [24]
-
[25]
In: ECCV (2024)
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3D with MASt3R. In: ECCV (2024)
2024
-
[26]
Li, T., He, K.: Back to basics: Let denoising generative models denoise (2025), arXiv:2511.13720
work page internal anchor Pith review arXiv 2025
-
[27]
Li, Y., Zou, Z.X., Liu, Z., Wang, D., Liang, Y., Yu, Z., Liu, X., Guo, Y.C., Liang, D., Ouyang, W., Cao, Y.P.: TripoSG: High-fidelity 3D shape synthesis using large-scale rectified flow models. IEEE Trans. Pattern Anal. Mach. Intell. (2026).https://doi.org/10.1109/TPAMI.2025.3633512
-
[28]
In: CVPR (2025)
Liang, H., Cao, J., Goel, V., Qian, G., Korolev, S., Terzopoulos, D., Plataniotis, K.N., Tulyakov, S., Ren, J.: Wonderland: Navigating 3D scenes from a single image. In: CVPR (2025)
2025
-
[29]
In: ICLR (2025)
Lin, C., Pan, P., Yang, B., Li, Z., Mu, Y.: DiffSplat: Repurposing image diffusion models for scalable Gaussian splat generation. In: ICLR (2025)
2025
-
[30]
In: ICLR (2023)
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: ICLR (2023)
2023
-
[31]
In: CVPR (2024)
Liu, M., Shi, R., Chen, L., Zhang, Z., Xu, C., Wei, X., Chen, H., Zeng, C., Gu, J., Su, H.: One-2-3-45++: Fast single image to 3D objects with consistent multi-view generation and 3D diffusion. In: CVPR (2024)
2024
-
[32]
In: ICCV (2023)
Liu, R., Wu, R., Hoorick, B.V., Tokmakov, P., Zakharov, S., Vondrick, C.: Zero-1- to-3: Zero-shot one image to 3D object. In: ICCV (2023)
2023
-
[33]
In: ICLR (2023)
Liu, X., Gong, C., qiang liu: Flow straight and fast: Learning to generate and transfer data with rectified flow. In: ICLR (2023)
2023
-
[34]
In: ICLR (2024)
Liu, X., Zhang, X., Ma, J., Peng, J., et al.: InstaFlow: One step is enough for high-quality diffusion-based text-to-image generation. In: ICLR (2024)
2024
-
[35]
In: ICLR (2024)
Liu, Y., Lin, C., Zeng, Z., Long, X., Liu, L., Komura, T., Wang, W.: SyncDreamer: Generating multiview-consistent images from a single-view image. In: ICLR (2024)
2024
-
[36]
In: 3DV (2025)
Ma, Q., Li, Y., Ren, B., Sebe, N., Konukoglu, E., Gevers, T., Gool, L.V., Paudel, D.P.: ShapeSplat: A large-scale dataset of Gaussian splats and their self-supervised pretraining. In: 3DV (2025)
2025
-
[37]
In: ECCV (2020).https://doi.org/10.1007/978-3-030-58452-8_24
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: NeRF: Representing scenes as neural radiance fields for view synthesis. In: ECCV (2020).https://doi.org/10.1007/978-3-030-58452-8_24
-
[38]
In: ECCV (2024)
Mu, Y., Zuo, X., Guo, C., Wang, Y., Lu, J., Wu, X., Xu, S., Dai, P., Yan, Y., Cheng, L.: GSD: View-guided Gaussian splatting diffusion for 3D reconstruction. In: ECCV (2024)
2024
-
[39]
Nichol, A., Jun, H., Dhariwal, P., Mishkin, P., Chen, M.: Point-E: A system for generating 3D point clouds from complex prompts (2022), arXiv:2212.08751
work page internal anchor Pith review arXiv 2022
-
[40]
In: International conference on machine learning
Nichol, A.Q., Dhariwal, P.: Improved denoising diffusion probabilistic models. In: International conference on machine learning. pp. 8162–8171. PMLR (2021) Free-Range Gaussians 17
2021
-
[41]
In: NeurIPS (2017)
van den Oord, A., Vinyals, O., Kavukcuoglu, K.: Neural discrete representation learning. In: NeurIPS (2017)
2017
-
[42]
Transactions on Machine Learning Research (2024)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual feat...
2024
-
[43]
In: ICCV (2023)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: ICCV (2023)
2023
-
[44]
In: ICLR (2023)
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: DreamFusion: Text-to-3D using 2D diffusion. In: ICLR (2023)
2023
-
[45]
In: NeurIPS (2024)
Ren, X., Lu, Y., Liang, H., Wu, Z., Ling, H., Chen, M., Fidler, S., Williams, F., Huang, J.: SCube: Instant large-scale scene reconstruction using VoxSplats. In: NeurIPS (2024)
2024
-
[46]
In: SIGGRAPH Asia (2024)
Roessle, B., Müller, N., Porzi, L., Bulò, S.R., Kontschieder, P., Dai, A., Nießner, M.: L3DG: Latent 3D Gaussian diffusion. In: SIGGRAPH Asia (2024)
2024
-
[47]
In: ICLR (2022)
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. In: ICLR (2022)
2022
- [48]
-
[49]
In: CVPR (2024)
Szymanowicz, S., Rupprecht, C., Vedaldi, A.: Splatter image: Ultra-fast single-view 3D reconstruction. In: CVPR (2024)
2024
-
[50]
In: ICCV (2025)
Szymanowicz, S., Zhang, J.Y., Srinivasan, P., Gao, R., Brussee, A., Holynski, A., Martin-Brualla, R., Barron, J.T., Henzler, P.: Bolt3D: Generating 3D scenes in seconds. In: ICCV (2025)
2025
-
[51]
In: ECCV (2024)
Tang, J., Chen, Z., Chen, X., Wang, T., Zeng, G., Liu, Z.: LGM: Large multi-view Gaussian model for high-resolution 3D content creation. In: ECCV (2024)
2024
-
[52]
In: CVPR (2025)
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: VGGT: Visual geometry grounded transformer. In: CVPR (2025)
2025
-
[53]
In: ICLR (2024)
Wang, P., Tan, H., Bi, S., Xu, Y., Luan, F., Sunkavalli, K., Wang, W., Xu, Z., Zhang, K.: PF-LRM: Pose-free large reconstruction model for joint pose and shape prediction. In: ICLR (2024)
2024
-
[54]
In: CVPR (2021)
Wang, Q., Wang, Z., Genova, K., Srinivasan, P., Zhou, H., Barron, J.T., Martin- Brualla, R., Snavely, N., Funkhouser, T.: IBRNet: Learning multi-view image-based rendering. In: CVPR (2021)
2021
-
[55]
In: CVPR (2024)
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: DUSt3R: Geometric 3D vision made easy. In: CVPR (2024)
2024
- [56]
- [57]
-
[58]
In: 3DV (2025)
Wu, C.H., Chen, Y.C., Solarte, B., Yuan, L., Sun, M.: iFusion: Inverting diffusion for pose-free reconstruction from sparse views. In: 3DV (2025)
2025
-
[59]
In: CVPR (2024)
Wu, R., Mildenhall, B., Henzler, P., Park, K., Gao, R., Watson, D., Srinivasan, P.P., Verbin, D., Barron, J.T., Poole, B., Holynski, A.: ReconFusion: 3D reconstruction with diffusion priors. In: CVPR (2024)
2024
-
[60]
In: NeurIPS (2024) 18 A
Wu, S., Lin, Y., Zhang, F., Zeng, Y., Xu, J., Torr, P., Cao, X., Yao, Y.: Direct3D: Scalable image-to-3D generation via 3D latent diffusion transformer. In: NeurIPS (2024) 18 A. Shabanov et al
2024
-
[61]
In: CVPR (2025)
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3D latents for scalable and versatile 3D generation. In: CVPR (2025)
2025
-
[62]
In: CVPR (2025)
Xu, H., Peng, S., Wang, F., Blum, H., Barath, D., Geiger, A., Pollefeys, M.: DepthSplat: Connecting Gaussian splatting and depth. In: CVPR (2025)
2025
-
[63]
Xu, J., Cheng, W., Gao, Y., Wang, X., Gao, S., Shan, Y.: InstantMesh: Efficient 3D mesh generation from a single image with sparse-view large reconstruction models (2024), arXiv:2404.07191
work page internal anchor Pith review arXiv 2024
-
[64]
In: ECCV (2024)
Xu, Y., Shi, Z., Yifan, W., Chen, H., Yang, C., Peng, S., Shen, Y., Wetzstein, G.: GRM: Large Gaussian reconstruction model for efficient 3D reconstruction and generation. In: ECCV (2024)
2024
-
[65]
ACM Trans
Yang, C., Li, S., Fang, J., Liang, R., Xie, L., Zhang, X., Shen, W., Tian, Q.: GaussianObject: Just taking four images to get a high-quality 3D object with Gaussian splatting. ACM Trans. Graph. (2024)
2024
-
[66]
In: CVPR (2021)
Yu, A., Ye, V., Tancik, M., Kanazawa, A.: pixelNeRF: Neural radiance fields from one or few images. In: CVPR (2021)
2021
-
[67]
In: NeurIPS (2019)
Zhang, B., Sennrich, R.: Root mean square layer normalization. In: NeurIPS (2019)
2019
-
[68]
Zhang, B., Tang, J., Nießner, M., Wonka, P.: 3DShape2VecSet: A 3D shape rep- resentation for neural fields and generative diffusion models. ACM Trans. Graph. 42(4), 92:1–16 (2023).https://doi.org/10.1145/3592442
-
[69]
In: NeurIPS (2024)
Zhang, B., Cheng, Y., Yang, J., Wang, C., Zhao, F., Tang, Y., Chen, D., Guo, B.: GaussianCube: A structured and explicit radiance representation for 3D generative modeling. In: NeurIPS (2024)
2024
-
[70]
In: ECCV (2024)
Zhang, K., Bi, S., Tan, H., Xiangli, Y., Zhao, N., Sunkavalli, K., Xu, Z.: GS-LRM: Large reconstruction model for 3D Gaussian splatting. In: ECCV (2024)
2024
-
[71]
In: ICCV (2025)
Ziwen, C., Tan, H., Zhang, K., Bi, S., Luan, F., Hong, Y., Fuxin, L., Xu, Z.: Long- LRM: Long-sequence large reconstruction model for wide-coverage Gaussian splats. In: ICCV (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.