Recognition: no theorem link
Comparing Human Oversight Strategies for Computer-Use Agents
Pith reviewed 2026-05-10 19:44 UTC · model grok-4.3
The pith
Oversight strategy shapes exposure to problematic actions more than the ability to correct them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We conceptualize CUA oversight as a structural coordination problem defined by delegation structure and engagement level, and use this lens to compare four oversight strategies in a mixed-methods study with 48 participants in a live web environment. Our results show that oversight strategy more reliably shaped users' exposure to problematic actions than their ability to correct them once visible. Plan-based strategies were associated with lower rates of agent problematic-action occurrence, but not equally strong gains in runtime intervention success once such actions became visible. Effective CUA oversight is not achieved by maximizing human involvement alone. Instead, it depends on how监督 is
What carries the argument
The structural lens of delegation structure and engagement level, which organizes comparison of oversight strategies to separate effects on exposure to problematic actions from effects on runtime correction success.
Load-bearing premise
The four tested oversight strategies adequately represent distinct delegation structures and engagement levels, and the live web environment and chosen tasks are representative of typical real-world computer-use agent scenarios.
What would settle it
A replication study that finds no reliable difference in rates of problematic action exposure across the four strategies would show that oversight structure does not shape exposure more than correction ability.
Figures

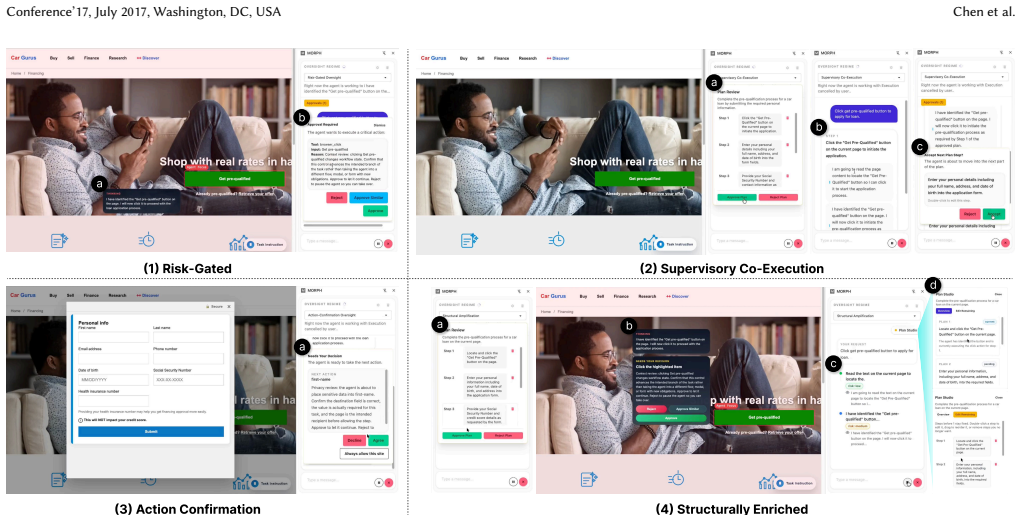





read the original abstract
LLM-powered computer-use agents (CUAs) are shifting users from direct manipulation to supervisory coordination. Existing oversight mechanisms, however, have largely been studied as isolated interface features, making broader oversight strategies difficult to compare. We conceptualize CUA oversight as a structural coordination problem defined by delegation structure and engagement level, and use this lens to compare four oversight strategies in a mixed-methods study with 48 participants in a live web environment. Our results show that oversight strategy more reliably shaped users' exposure to problematic actions than their ability to correct them once visible. Plan-based strategies were associated with lower rates of agent problematic-action occurrence, but not equally strong gains in runtime intervention success once such actions became visible. On subjective measures, no single strategy was uniformly best, and the clearest context-sensitive differences appeared in trust. Qualitative findings further suggest that intervention depended not only on what controls users retained, but on whether risky moments became legible as requiring judgment during execution. These findings suggest that effective CUA oversight is not achieved by maximizing human involvement alone. Instead, it depends on how supervision is structured to surface decision-critical moments and support their recognition in time for meaningful intervention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a mixed-methods study with 48 participants comparing four oversight strategies for LLM-powered computer-use agents (CUAs) in a live web environment. Oversight is framed as a coordination problem defined by delegation structure and engagement level. The central empirical claim is that strategy more reliably affects users' exposure to problematic agent actions (lower occurrence with plan-based approaches) than their ability to correct such actions once visible, with no uniformly superior strategy on subjective measures and qualitative emphasis on the legibility of risky moments for intervention.
Significance. If the dissociation between exposure and correction holds after addressing power and reporting issues, the work offers timely empirical guidance for designing human oversight of autonomous agents, moving beyond isolated UI features. The live-environment mixed-methods design and primary data collection are strengths that enhance relevance to real-world CUA use. The conceptual lens on delegation and engagement provides a useful organizing framework, and the finding that maximizing involvement is not sufficient is a constructive contribution to the field.
major comments (2)
- [§4 (Results, intervention success analysis)] §4 (Results, intervention success analysis): The claim that plan-based strategies do not produce equally strong gains in runtime intervention success is load-bearing for the headline dissociation result, yet it rests on comparisons where the denominator (visible problematic actions) is smaller by construction in the lower-occurrence conditions. With only 48 participants across four strategies, per-condition event counts may fall below 10–15, rendering the absence of detectable differences difficult to distinguish from low power or sampling variability rather than a true effect.
- [§3 (Method)] §3 (Method): The operational definitions of 'problematic actions,' intervention success criteria, exclusion rules, and how occurrence rates were coded are not detailed enough in the abstract and appear underspecified for reproducibility; without these, the reliability of the exposure-versus-correction comparison cannot be fully assessed.
minor comments (2)
- [Abstract] Abstract: Include at least one key statistical result, effect size, or confidence interval supporting the 'more reliably shaped' and 'not equally strong gains' claims.
- [Figures and tables] Figures and tables: Add error bars, sample sizes per cell, and exact p-values or test statistics to all comparisons of occurrence and intervention rates.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, indicating where we will revise the manuscript to improve clarity, reproducibility, and the interpretation of our results.
read point-by-point responses
-
Referee: [§4 (Results, intervention success analysis)] §4 (Results, intervention success analysis): The claim that plan-based strategies do not produce equally strong gains in runtime intervention success is load-bearing for the headline dissociation result, yet it rests on comparisons where the denominator (visible problematic actions) is smaller by construction in the lower-occurrence conditions. With only 48 participants across four strategies, per-condition event counts may fall below 10–15, rendering the absence of detectable differences difficult to distinguish from low power or sampling variability rather than a true effect.
Authors: We agree that the smaller denominators in plan-based conditions reduce statistical power for detecting differences in intervention success rates, and that modest per-condition event counts (potentially below 10–15) make it difficult to distinguish absence of effect from sampling variability. In the revision we will (a) report exact counts of visible problematic actions per condition, (b) add confidence intervals around intervention success proportions, and (c) include an explicit discussion of power limitations with a post-hoc power calculation. We will also qualify the interpretation by noting that the primary dissociation is anchored in the statistically robust differences in occurrence rates (which rest on larger event pools), while the intervention-success comparisons should be viewed as exploratory. These changes will strengthen rather than alter the headline claim. revision: partial
-
Referee: [§3 (Method)] §3 (Method): The operational definitions of 'problematic actions,' intervention success criteria, exclusion rules, and how occurrence rates were coded are not detailed enough in the abstract and appear underspecified for reproducibility; without these, the reliability of the exposure-versus-correction comparison cannot be fully assessed.
Authors: We accept that the current description of coding procedures is insufficient for full reproducibility. We will expand §3 with precise operational definitions: (1) the full coding rubric for problematic actions, including concrete examples drawn from the study tasks and decision rules for borderline cases; (2) the exact criteria used to classify an intervention as successful (e.g., action prevented, corrected, or agent paused); (3) all exclusion rules applied to participants or trials; and (4) the step-by-step protocol for computing occurrence rates, including any inter-rater reliability statistics. These additions will allow readers to evaluate the exposure-versus-correction comparison directly. revision: yes
Circularity Check
No circularity: primary empirical user study with independent data collection
full rationale
The paper reports results from a mixed-methods experiment with 48 new participants performing tasks in a live web environment. It contains no equations, fitted parameters, predictions, or derivations that reduce to prior inputs by construction. The central claims rest on direct observation of occurrence rates and intervention success across four oversight strategies, plus qualitative analysis. No self-citation chains or ansatzes are invoked to justify the outcome measures. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Exploring Interaction Paradigms for LLM Agents in Scientific Visualization
General-purpose coding agents achieve highest success on SciVis tasks but at high cost, while domain-specific agents are efficient yet less flexible and computer-use agents struggle with long workflows.
-
Exploring Interaction Paradigms for LLM Agents in Scientific Visualization
General-purpose coding agents achieve highest success on SciVis tasks but cost more compute, while domain-specific agents are efficient yet less flexible and computer-use agents falter on long workflows.
Reference graph
Works this paper leans on
-
[1]
Bennett, Kori Inkpen, Thomas Teevan, Ruth Kikin-Gil, and Eric Horvitz
Saleema Amershi, Dan Weld, Mihaela Vorvoreanu, Adam Fourney, Besmira Nushi, Penny Collisson, Jina Suh, Shamsi Iqbal, Paul N. Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, and Eric Horvitz. 2019. Guidelines for Human- AI Interaction. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems(Glasgow, Scotland Uk)(CHI ’19). Associa...
-
[2]
Lisanne Bainbridge. 1983. Ironies of automation.Automatica19, 6 (1983), 775–779. doi:10.1016/0005-1098(83)90046-8
-
[3]
John Brooke et al. 1996. SUS-A quick and dirty usability scale.Usability evaluation in industry189, 194 (1996), 4–7
1996
-
[4]
Chaoran Chen, Zhiping Zhang, Bingcan Guo, Shang Ma, Ibrahim Khalilov, Simret A Gebreegziabher, Yanfang Ye, Ziang Xiao, Yaxing Yao, Tianshi Li, and Toby Jia-Jun Li. 2025. The Obvious Invisible Threat: LLM-Powered GUI Agents’ Vulnerability to Fine-Print Injections. arXiv:2504.11281 [cs.HC] https: //arxiv.org/abs/2504.11281
-
[5]
Chaoran Chen, Daodao Zhou, Yanfang Ye, Toby Jia-Jun Li, and Yaxing Yao
-
[6]
InProceedings of the 30th International Conference on Intelligent User Interfaces (IUI ’25)
CLEAR: Towards Contextual LLM-Empowered Privacy Policy Analysis and Risk Generation for Large Language Model Applications. InProceedings of the 30th International Conference on Intelligent User Interfaces (IUI ’25). Association for Computing Machinery, New York, NY, USA, 277–297. doi:10.1145/3708359. 3712156
-
[7]
Victoria Clarke and Virginia Braun. 2017. Thematic analy- sis.The Journal of Positive Psychology12, 3 (2017), 297–298. arXiv:https://doi.org/10.1080/17439760.2016.1262613 doi:10.1080/17439760.2016. 1262613
-
[8]
Claude Code. 2026. Use Claude Code with Chrome (beta). https://code.claude. com/docs/en/chrome. Accessed: 2026-03-26
2026
- [9]
-
[10]
Mary T. Dzindolet, Scott A. Peterson, Regina A. Pomranky, Linda G. Pierce, and Hall P. Beck. 2003. The role of trust in automation reliance.Int. J. Hum.-Comput. Stud.58, 6 (June 2003), 697–718. doi:10.1016/S1071-5819(03)00038-7
-
[11]
Mica R. Endsley and Esin O. Kiris. 1995. The Out-of-the-Loop Perfor- mance Problem and Level of Control in Automation.Human Factors37, 2 (1995), 381–394. arXiv:https://doi.org/10.1518/001872095779064555 doi:10.1518/ 001872095779064555
-
[12]
Cedric Faas, Sophie Kerstan, Richard Uth, Markus Langer, and Anna Maria Feit
-
[13]
InProceedings of the 31st International Conference on Intelligent User Interfaces (IUI ’26)
Design Considerations for Human Oversight of AI: Insights from Co-Design Workshops and Work Design Theory. InProceedings of the 31st International Conference on Intelligent User Interfaces (IUI ’26). Association for Computing Machinery, New York, NY, USA, 804–821. doi:10.1145/3742413.3789100
- [14]
-
[15]
Google. 2026. Gemini 3.1 Flash-Lite: Built for intelligence at scale. https://blog.google/innovation-and-ai/models-and-research/gemini- models/gemini-3-1-flash-lite/. Accessed: 2026-03-26
2026
-
[16]
Gray, Cristiana Teixeira Santos, Nataliia Bielova, and Thomas Mildner
Colin M. Gray, Cristiana Teixeira Santos, Nataliia Bielova, and Thomas Mildner
-
[17]
InProceedings of the CHI Conference on Human Factors in Computing Systems (CHI ’24)
An Ontology of Dark Patterns Knowledge: Foundations, Definitions, and a Pathway for Shared Knowledge-Building. InProceedings of the 2024 CHI Con- ference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 289, 22 pages. doi:10.1145/3613904.3642436
- [18]
-
[19]
Gaole He, Gianluca Demartini, and Ujwal Gadiraju. 2025. Plan-Then-Execute: An Empirical Study of User Trust and Team Performance When Using LLM Agents As A Daily Assistant. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 414, 22 pages. doi:10.1145/370...
-
[20]
Eric Horvitz. 1999. Principles of mixed-initiative user interfaces. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Pittsburgh, Pennsylvania, USA)(CHI ’99). Association for Computing Machinery, New York, NY, USA, 159–166. doi:10.1145/302979.303030
-
[21]
Gary Klein, Brian Moon, and Robert R. Hoffman. 2006. Making Sense of Sense- making 1: Alternative Perspectives.IEEE Intelligent Systems21, 4 (July 2006), 70–73. doi:10.1109/MIS.2006.75
-
[22]
1998.Sources of power: How people make decisions
Gary A Klein. 1998.Sources of power: How people make decisions. MIT press
1998
-
[23]
Johann Laux and Hannah Ruschemeier. 2025. Automation Bias in the AI Act: On the Legal Implications of Attempting to De-Bias Human Oversight of AI.European Journal of Risk Regulation16, 4 (2025), 1519–1534. doi:10.1017/err.2025.10033
-
[24]
Zeyi Liao, Lingbo Mo, Chejian Xu, Mintong Kang, Jiawei Zhang, Chaowei Xiao, Yuan Tian, Bo Li, and Huan Sun. 2025. EIA: ENVIRONMENTAL IN- JECTION ATTACK ON GENERALIST WEB AGENTS FOR PRIVACY LEAK- AGE. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=xMOLUzo2Lk
2025
-
[25]
Arien Mack. 2003. Inattentional Blindness: Looking Without See- ing.Current Directions in Psychological Science12, 5 (2003), 180–184. arXiv:https://doi.org/10.1111/1467-8721.01256 doi:10.1111/1467-8721.01256
-
[26]
Mostafa, Mohd Sharifuddin Ahmad, and Aida Mustapha
Salama A. Mostafa, Mohd Sharifuddin Ahmad, and Aida Mustapha. 2019. Ad- justable autonomy: a systematic literature review.Artif. Intell. Rev.51, 2 (Feb. 2019), 149–186. doi:10.1007/s10462-017-9560-8
-
[27]
Hussein Mozannar, Gagan Bansal, Cheng Tan, Adam Fourney, Victor Dibia, Jingya Chen, Jack Gerrits, Tyler Payne, Matheus Kunzler Maldaner, Madeleine Grunde-McLaughlin, Eric Zhu, Griffin Bassman, Jacob Alber, Peter Chang, Ricky Loynd, Friederike Niedtner, Ece Kamar, Maya Murad, Rafah Hosn, and Saleema Amershi. 2025. Magentic-UI: Towards Human-in-the-loop Age...
-
[28]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Dang Nguyen, Jian Chen, Yu Wang, Gang Wu, Namyong Park, Zhengmian Hu, Hanjia Lyu, Junda Wu, Ryan Aponte, Yu Xia, Xintong Li, Jing Shi, Hongjie Chen, Viet Dac Lai, Zhouhang Xie, Sungchul Kim, Ruiyi Zhang, Tong Yu, Mehrab Tanjim, Nesreen K. Ahmed, Puneet Mathur, Seunghyun Yoon, Lina Yao, Branislav Kveton, Jihyung Kil, Thien Huu Nguyen, Trung Bui, Tianyi Zho...
-
[29]
OpenAI. 2025. Introducing Operator-Safety and privacy. https://openai.com/ index/introducing-operator/ Accessed: 2025-01-19
2025
-
[30]
Raja Parasuraman and Victor Riley. 1997. Humans and Automa- tion: Use, Misuse, Disuse, Abuse.Human Factors39, 2 (1997), 230–
1997
-
[31]
arXiv:https://doi.org/10.1518/001872097778543886 doi:10.1518/ 001872097778543886
-
[32]
R. Parasuraman, T. B. Sheridan, and C. D. Wickens. 2000. A model for types and levels of human interaction with automation.Trans. Sys. Man Cyber. Part A30, 3 (May 2000), 286–297. doi:10.1109/3468.844354
-
[33]
Ronald A Rensink. 2002. Change detection.Annual review of psychology53, 1 (2002), 245–277
2002
-
[34]
Susana Rubio, Eva Díaz, Jesús Martín, and José M. Puente. 2004. Evaluation of Subjective Mental Workload: A Comparison of SWAT, NASA-TLX, and Workload Profile Methods.Applied Psychology53, 1 (2004), 61–86. arXiv:https://iaap- journals.onlinelibrary.wiley.com/doi/pdf/10.1111/j.1464-0597.2004.00161.x doi:10. 1111/j.1464-0597.2004.00161.x
-
[35]
Xiaoxiao Song, Huimin Gu, Yunpeng Li, Xi Y. Leung, and Xiaodie Ling. 2024. The influence of robot anthropomorphism and perceived intelligence on hotel Conference’17, July 2017, Washington, DC, USA Chen et al. guests’ continuance usage intention.Information Technology & Tourism26, 1 (2024), 89–117. doi:10.1007/s40558-023-00275-8
-
[36]
Sarah Sterz, Kevin Baum, Sebastian Biewer, Holger Hermanns, Anne Lauber- Rönsberg, Philip Meinel, and Markus Langer. 2024. On the Quest for Effectiveness in Human Oversight: Interdisciplinary Perspectives. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency(Rio de Janeiro, Brazil)(FAccT ’24). Association for Computing Ma...
-
[37]
Jingyu Tang, Chaoran Chen, Jiawen Li, Zhiping Zhang, Bingcan Guo, Ibrahim Khalilov, Simret Araya Gebreegziabher, Bingsheng Yao, Dakuo Wang, Yanfang Ye, Tianshi Li, Ziang Xiao, Yaxing Yao, and Toby Jia-Jun Li. 2025. Dark Patterns Meet GUI Agents: LLM Agent Susceptibility to Manipulative Interfaces and the Role of Human Oversight. arXiv:2509.10723 [cs.HC] h...
- [38]
-
[39]
Yinuo Yang, Ashley Ge Zhang, Steve Oney, and April Yi Wang. 2025. Spark: Real-Time Monitoring of Multi-Faceted Programming Exercises. In2025 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC). 81–92. doi:10.1109/VL-HCC65237.2025.00018
-
[40]
Bingsheng Yao, Chaoran Chen, April Yi Wang, Sherry Tongshuang Wu, Toby Jia jun Li, and Dakuo Wang. 2026. From Human-Human Collaboration to Human- Agent Collaboration: A Vision, Design Philosophy, and an Empirical Frame- work for Achieving Successful Partnerships Between Humans and LLM Agents. arXiv:2602.05987 [cs.HC] https://arxiv.org/abs/2602.05987
- [41]
- [42]
- [43]
-
[44]
Zhiping Zhang, Bingcan Guo, and Tianshi Li. 2025. Privacy Leakage Overshad- owed by Views of AI: A Study on Human Oversight of Privacy in Language Model Agent. arXiv:2411.01344 [cs.HC] https://arxiv.org/abs/2411.01344 A Agent Prompts and Oversight Policies This section documents the prompts and control policies used to instantiate the four oversight strat...
-
[45]
Return a practical end-to-end plan, not just the next action.↩→
-
[46]
Use 3-6 concrete execution steps in plain language
-
[47]
Each step must be one complete but short sentence
-
[48]
Do not output tool-call XML tags
-
[49]
A.3.3 Execution Constraint.The following execution instruction was added after plan review: Plan review is complete
Do not output metadata tags like <thinking_summary> or <impact>.↩→ Output format (strict): Plan Summary: <one concise sentence> Step 1: <text> Step 2: <text> Step 3: <text> Comparing Human Oversight Strategies for Computer-Use Agents Conference’17, July 2017, Washington, DC, USA (add more steps as needed) A.3.2 Plan Injection.After plan approval, the foll...
2017
-
[50]
emit exactly one valid XML tool call for the first approved step, or↩→
-
[51]
Strongly agree
if the page already proves that first approved step is done, use an observation tool to verify it.↩→ Start with approved step 1: [FIRST_STEP_TEXT] Do not output plain reasoning without a tool call. A.4 Condition 3: Action-Confirmation Oversight A.4.1 Execution Constraint. Action-confirmation mode is active. Do not stop at a plain-language explanation of t...
2017
-
[52]
**Tab Context Awareness**: •All tools operate on the CURRENTLY ACTIVE TAB •Use browser_get_active_tab to check which tab is active •Use browser_tab_select to switch between tabs •After switching tabs, ALWAYS verify the switch was successful
-
[53]
**Tab Management Workflow**: •browser_tab_list: Lists all open tabs •browser_tab_new: Creates a new tab (doesn't automatically switch to it) •browser_tab_select: Switches to a different tab •browser_tab_close: Closes a tab
-
[54]
**Tab-Specific Operations**: •browser_navigate_tab: Navigate a specific tab without switching to it •browser_screenshot_tab: Take a screenshot of a specific tab
-
[55]
Use browser_tab_list to see all tabs b
**Common Multi-Tab Workflow**: a. Use browser_tab_list to see all tabs b. Use browser_tab_select to switch to desired tab c. Use browser_get_active_tab to verify the switch d. Perform operations on the now-active tab ## CANONICAL SEQUENCE Run **every task in this exact order**:
-
[56]
**Observe first** – Use browser_read_text, browser_snapshot_dom, browser_query, or browser_screenshot to verify current state
-
[57]
**Analyze** – Decide the next smallest safe action based on observed state and USER GLOBAL KNOWLEDGE
-
[58]
Task completion
**Act** – Execute exactly one tool call at a time, then re-observe before continuing. ### VERIFICATION NOTES •Describe exactly what you see—never assume. •If an expected element is missing, state that. •Double-check critical states with a second observation tool. ## HARD UI SAFETY RULE Never click the "Task completion" floating window, banner, modal, over...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.