Recognition: unknown
Exploring Interaction Paradigms for LLM Agents in Scientific Visualization
Pith reviewed 2026-05-14 21:08 UTC · model grok-4.3
The pith
LLM agents for scientific visualization display clear tradeoffs in success rates, efficiency, and flexibility across coding, domain-specific, and computer-use paradigms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
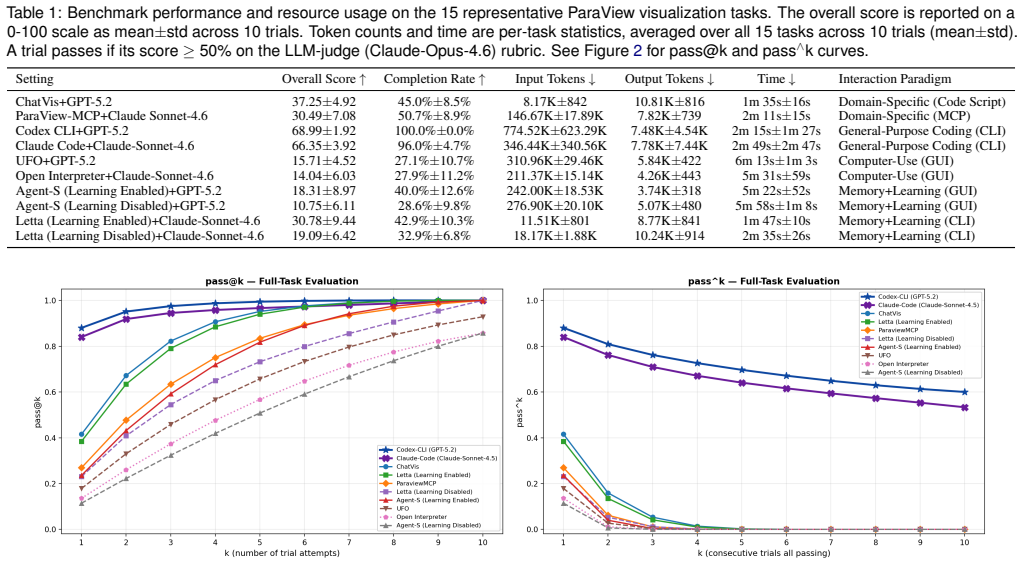
No single interaction paradigm suffices for LLM-driven scientific visualization: general-purpose coding agents reach the highest task success rates yet incur the greatest computational expense, domain-specific agents deliver greater efficiency and stability at the cost of reduced flexibility, and computer-use agents perform reliably on individual steps but fail to sustain longer multi-step workflows because long-horizon planning remains their chief limitation. Persistent memory improves results across repeated trials in both CLI and GUI settings, with the magnitude of improvement depending on the quality of feedback and the underlying interaction mode.
What carries the argument
Benchmark comparison of eight agents across three paradigms (domain-specific structured tool use, computer-use agents, general-purpose coding agents) on 15 SciVis tasks, measuring success, efficiency, robustness, and cost while varying modalities such as code scripts, MCP/API calls, CLI, GUI, and persistent memory.
If this is right
- Domain-specific agents will remain preferable when stability and low cost matter more than broad adaptability.
- Computer-use agents will require advances in long-horizon planning before they can handle complex end-to-end workflows reliably.
- Adding persistent memory consistently raises performance on repeated trials, with larger gains in modes that provide richer feedback.
- Future visualization systems will need hybrid designs that combine structured tool calling with interactive capabilities and adaptive memory.
Where Pith is reading between the lines
- The same paradigm tradeoffs are likely to appear in other scientific computing domains that convert natural language into executable pipelines.
- Developers could build meta-agents that dynamically switch between paradigms based on task length and required flexibility.
- User studies measuring actual time saved in daily visualization work would reveal whether the benchmark efficiency gains translate to practice.
Load-bearing premise
The 15 benchmark tasks and eight chosen agents capture enough of real scientific visualization practice that the observed performance tradeoffs will hold for other tasks and users.
What would settle it
Running the same eight agents on a fresh collection of twenty real-user visualization requests and finding that the ranking of success rates, efficiency, and robustness reverses from the original benchmark results.
Figures

read the original abstract
This paper examines how different types of large language model (LLM) agents perform on scientific visualization (SciVis) tasks, where users generate visualization workflows from natural-language instructions. We compare three primary interaction paradigms, including domain-specific agents with structured tool use, computer-use agents, and general-purpose coding agents, by evaluating eight representative agents across 15 benchmark tasks and measuring visualization quality, efficiency, robustness, and computational cost. We further analyze interaction modalities, including code scripts and model context protocol (MCP) or API calls for structured tool use, as well as command-line interfaces (CLI) and graphical user interfaces (GUI) for more general interaction, while additionally studying the effect of persistent memory in selected agents. The results reveal clear tradeoffs across paradigms and modalities. General-purpose coding agents achieve the highest task success rates but are computationally expensive, while domain-specific agents are more efficient and stable but less flexible. Computer-use agents perform well on individual steps but struggle with longer multi-step workflows, indicating that long-horizon planning is their primary limitation. Across both CLI- and GUI-based settings, persistent memory improves performance over repeated trials, although its benefits depend on the underlying interaction mode and the quality of feedback. These findings suggest that no single approach is sufficient, and future SciVis systems should combine structured tool use, interactive capabilities, and adaptive memory mechanisms to balance performance, robustness, and flexibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper evaluates eight LLM agents spanning three interaction paradigms—domain-specific agents using structured tool calls, computer-use agents, and general-purpose coding agents—on 15 benchmark scientific visualization tasks. It measures task success rates, visualization quality, efficiency, robustness, and computational cost, while also examining interaction modalities (CLI/GUI, code vs. MCP/API) and the impact of persistent memory. The central claim is that clear tradeoffs exist: general-purpose coding agents achieve the highest success rates but incur high computational cost; domain-specific agents are more efficient and stable but less flexible; computer-use agents handle individual steps well but fail on longer multi-step workflows; and persistent memory improves repeated-trial performance depending on the interaction mode.
Significance. If the measurement protocols and task representativeness hold, the work supplies the first systematic empirical comparison of LLM agent paradigms specifically for scientific visualization workflows. It identifies actionable design principles—namely that no single paradigm suffices and that hybrids combining structured tools, interactive capabilities, and adaptive memory are needed—which could directly inform the next generation of AI-assisted SciVis systems. The benchmark itself, once fully documented, could serve as a reusable testbed for future agent research in visualization and scientific computing.
major comments (2)
- [§3.2] §3.2 (Benchmark Tasks): The 15 tasks are repeatedly described as 'representative' of scientific visualization practice, yet the manuscript supplies no explicit selection criteria, coverage matrix across visualization techniques (volume vs. surface rendering, scalar vs. vector data), domain diversity, or validation against real user workflows. Because the headline claim of 'clear tradeoffs across paradigms' in §5 rests on these tasks being generalizable, the absence of justification is load-bearing.
- [§4.2] §4.2 (Evaluation Protocol): The abstract and results sections report quantitative success rates and visualization-quality scores across 15 tasks and eight agents, but provide no definition of success criteria, no description of how quality was scored (automated metric, human raters, or both), and no inter-rater reliability statistics. Without these controls the numerical comparisons that support all paradigm-level conclusions cannot be independently verified.
minor comments (2)
- A summary table listing the eight agents, their paradigm category, interaction modality, and memory configuration would improve readability of the experimental design.
- [§5.3] The discussion of persistent memory benefits would be strengthened by reporting the exact number of repeated trials and the statistical test used to claim improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the manuscript requires greater transparency on task selection and evaluation protocols to support the generalizability of our findings. We address each major comment below and have revised the manuscript to incorporate the requested clarifications and supporting details.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Benchmark Tasks): The 15 tasks are repeatedly described as 'representative' of scientific visualization practice, yet the manuscript supplies no explicit selection criteria, coverage matrix across visualization techniques (volume vs. surface rendering, scalar vs. vector data), domain diversity, or validation against real user workflows. Because the headline claim of 'clear tradeoffs across paradigms' in §5 rests on these tasks being generalizable, the absence of justification is load-bearing.
Authors: We acknowledge that the original manuscript would be strengthened by explicit documentation of task selection. In the revised version, we will expand §3.2 with a new subsection that states the selection criteria: tasks were chosen to span core SciVis operations (data loading, filtering, rendering, interaction) while covering major technique categories (volume rendering, surface rendering, glyph-based visualization) and data types (scalar, vector, tensor fields). We will include a coverage matrix table showing distribution across domains (biomedical imaging, fluid dynamics, astrophysics, materials science) and reference prior user studies and surveys from the visualization literature to demonstrate alignment with real workflows. These additions will directly support the generalizability of the paradigm tradeoffs reported in §5. revision: yes
-
Referee: [§4.2] §4.2 (Evaluation Protocol): The abstract and results sections report quantitative success rates and visualization-quality scores across 15 tasks and eight agents, but provide no definition of success criteria, no description of how quality was scored (automated metric, human raters, or both), and no inter-rater reliability statistics. Without these controls the numerical comparisons that support all paradigm-level conclusions cannot be independently verified.
Authors: We agree that precise definitions and controls are essential for reproducibility and independent verification. In the revised §4.2, we will add: (1) explicit success criteria per task (correct pipeline execution plus output matching ground-truth expectations within defined tolerances); (2) a description of the hybrid quality scoring process, combining automated metrics (e.g., structural similarity and peak signal-to-noise ratio on rendered images) with human ratings on a 5-point Likert scale by two domain-expert raters; and (3) inter-rater reliability statistics (Cohen’s kappa). These details will be presented alongside the quantitative results so that all paradigm-level comparisons can be verified. revision: yes
Circularity Check
Empirical benchmark study with no derivation circularity
full rationale
The paper conducts an empirical comparison of LLM agent paradigms on 15 predefined benchmark tasks, reporting measured outcomes such as task success rates, efficiency, robustness, and cost. These results are obtained directly from experimental runs against external task definitions and agent implementations rather than derived via equations, fitted parameters renamed as predictions, or self-citation chains. No load-bearing steps reduce to self-definition or ansatz smuggling; the central claims about tradeoffs follow from the observed data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 15 benchmark tasks adequately represent typical scientific visualization workflows
Reference graph
Works this paper leans on
-
[1]
S. Agashe, J. Han, S. Gan, J. Yang, A. Li, and X. E. Wang. Agent S: An open agentic framework that uses computers like a human.arXiv preprint arXiv:2410.08164, 2024. doi:10.48550/arXiv.2410.081641, 2
-
[2]
J. P. Ahrens, B. Geveci, and C. C. Law. ParaView: An end-user tool for large-data visualization. In C. D. Hansen and C. R. Johnson, eds., The Visualization Handbook, chap. 36, pp. 717–731. Academic Press,
-
[3]
doi:10.1016/B978-012387582-2/50038-11
- [4]
- [5]
-
[6]
K. Ai, K. Tang, and C. Wang. NLI4V olVis: Natural language interac- tion for volume visualization via multi-LLM agents and editable 3D Gaussian splatting.IEEE Transactions on Visualization and Computer Graphics, 32(1):46–56, 2026. doi:10.1109/TVCG.2025.36338882
-
[7]
Introducing computer use, a new Claude 3.5 Son- net, and Claude 3.5 Haiku
Anthropic. Introducing computer use, a new Claude 3.5 Son- net, and Claude 3.5 Haiku. https://www.anthropic.com/news/ 3-5-models-and-computer-use. 2
-
[8]
Claude Code: An agentic coding tool
Anthropic. Claude Code: An agentic coding tool. https://github. com/anthropics/claude-code, 2025. 1, 2
2025
-
[9]
Equipping agents for the real world with agent skills
Anthropic. Equipping agents for the real world with agent skills. https://claude.com/blog/ equipping-agents-for-the-real-world-with-agent-skills ,
-
[10]
A. Biswas, T. L. Turton, N. R. Ranasinghe, S. Jones, B. Love, W. Jones et al. VizGenie: Toward self-refining, domain-aware workflows for next-generation scientific visualization.IEEE Transactions on Visu- alization and Computer Graphics, 32(1):1021–1031, 2026. doi: 10. 1109/TVCG.2025.36346552
-
[11]
R. Bonatti, D. Zhao, F. Bonacci, D. Dupont, S. Abdali, Y . Li et al. Windows Agent Arena: Evaluating multi-modal OS agents at scale. arXiv preprint arXiv:2409.08264, 2024. doi: 10.48550/arXiv.2409.08264 2
-
[12]
C. Chen, Z. Zhang, Z. Chen, E. Xu, Y . Yang, I. Khalilov et al. Compar- ing human oversight strategies for computer-use agents.arXiv preprint arXiv:2604.04918, 2026. doi:10.48550/arXiv.2604.049182
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.049182 2026
-
[13]
N. Chen, Y . Zhang, J. Xu, K. Ren, and Y . Yang. VisEval: A benchmark for data visualization in the era of large language models.IEEE Trans- actions on Visualization and Computer Graphics, 31(1):1301–1311,
-
[14]
doi:10.1109/TVCG.2024.3456322
-
[15]
Z. Chen, J. Chen, S. Ö. Arik, M. Sra, T. Pfister, and J. Yoon. CoDA: Agentic systems for collaborative data visualization.arXiv preprint arXiv:2510.03194, 2025. doi:10.48550/arXiv.2510.031942
-
[16]
V . Dhanoa, A. Wolter, G. M. León, H.-J. Schulz, and N. Elmqvist. Agentic visualization: Extracting agent-based design patterns from visualization systems.IEEE Computer Graphics and Applications, 45(6):89–90, 2025. doi:10.1109/MCG.2025.36077411
-
[17]
P. P. Do, K. Tang, K. Ai, and C. Wang. SVLAT: Scientific visualization literacy assessment test.arXiv preprint arXiv:2603.19000, 2026. doi: 10.48550/arXiv.2603.190002
-
[18]
J. Fang, Y . Peng, X. Zhang, Y . Wang, X. Yi, G. Zhang et al. A com- prehensive survey of self-evolving AI agents: A new paradigm bridg- ing foundation models and lifelong agentic systems.arXiv preprint arXiv:2508.07407, 2025. doi:10.48550/arXiv.2508.074072
-
[19]
J. Y . Koh, R. Lo, L. Jang, V . Duvvur, M. C. Lim, P.-Y . Huang et al. Evaluating multimodal agents on realistic visual web tasks. In Proceedings of Annual Meeting of the Association for Computational Linguistics, pp. 881–905, 2024. doi:10.18653/v1/2024.acl-long.502
-
[20]
Letta: The platform for building stateful ai agents.https://github.com/letta-ai/letta, 2026
Letta AI and contributors. Letta: The platform for building stateful ai agents.https://github.com/letta-ai/letta, 2026. 1, 2
2026
-
[21]
S. Liu, H. Miao, and P.-T. Bremer. ParaView-MCP: An autonomous visualization agent with direct tool use. InProceedings of IEEE VIS Conference (Short Papers), pp. 61–65, 2025. doi: 10.48550/arXiv.2505. 070641, 2
-
[22]
S. Liu, H. Miao, Z. Li, M. Olson, V . Pascucci, and P.-T. Bremer. A V A: towards autonomous visualization agents through visual perception- driven decision-making.Computer Graphics Forum, 43(3):e15093,
-
[23]
doi:10.1111/cgf.150931, 2
-
[24]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
D. Nguyen, J. Chen, Y . Wang, G. Wu, N. Park, Z. Hu et al. GUI agents: A survey. InProceedings of Findings of the Association for Computational Linguistics, pp. 22522–22538, 2025. doi: 10.18653/v1/ 2025.findings-acl.11581
-
[25]
Open Interpreter: A natural language inter- face for computers
Open Interpreter. Open Interpreter: A natural language inter- face for computers. https://github.com/openinterpreter/ open-interpreter, 2023. 1, 2
2023
-
[26]
OpenAI Codex: Lightweight coding agent that runs in your terminal.https://github.com/openai/codex, 2025
OpenAI. OpenAI Codex: Lightweight coding agent that runs in your terminal.https://github.com/openai/codex, 2025. 1, 2
2025
-
[27]
T. Peterka, T. Mallick, O. Yildiz, D. Lenz, C. Quammen, and B. Geveci. ChatVis: Large language model agent for generating scientific visual- izations. InProceedings of IEEE Workshop on Large Data Analysis and Visualization, pp. 22–32, 2025. doi: 10.1109/LDAV68558.2025.00007 1, 2
- [28]
- [29]
-
[30]
K. Tang, K. Ai, J. Han, and C. Wang. TexGS-V olVis: Expressive scene editing for volume visualization via textured Gaussian splatting.IEEE Transactions on Visualization and Computer Graphics, 32(1):933–943,
-
[31]
doi:10.1109/TVCG.2025.36346432
-
[32]
Z. Wu, C. Han, Z. Ding, Z. Weng, Z. Liu, S. Yao et al. OS-Copilot: Towards generalist computer agents with self-improvement.arXiv preprint arXiv:2402.07456, 2024. doi:10.48550/arXiv.2402.074562
-
[33]
Y . Yang and S. Oney. Vizcode: A practical real-time tool for in-class computer programming tutoring. InProceedings of the Eleventh ACM Conference on Learning@ Scale, pp. 544–546, 2024. doi: 10.1145/ 3657604.36647162
-
[34]
Y . Yang, A. G. Zhang, S. Oney, and A. Y . Wang. Spark: Real-time mon- itoring of multi-faceted programming exercises. In2025 IEEE Sympo- sium on Visual Languages and Human-Centric Computing (VL/HCC), pp. 81–92, 2025. doi:10.1109/VL-HCC65237.2025.000182
-
[35]
Z. Yang, Z. Zhou, S. Wang, X. Cong, X. Han, Y . Yan et al. MatPlotA- gent: Method and evaluation for LLM-based agentic scientific data visualization. InProceedings of Findings of the Association for Com- putational Linguistics, pp. 11789–11804, 2024. doi: 10.18653/v1/2024. findings-acl.7012
-
[36]
Large language model-brained gui agents: A survey,
C. Zhang, S. He, J. Qian, B. Li, L. Li, S. Qin et al. Large language model-brained GUI agents: A survey.arXiv preprint arXiv:2411.18279,
-
[37]
doi:10.48550/arXiv.2411.182791
- [38]
-
[39]
C. Zhang, L. Li, S. He, X. Zhang, B. Qiao, S. Qin et al. UFO: A UI- focused agent for windows OS interaction. InProceedings of Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pp. 597–622, 2025. doi: 10.18653/v1/2025. naacl-long.261, 2
-
[40]
C. Zhang, L. Li, H. Huang, C. Ni, B. Qiao, S. Qin et al. UFO3: Weaving the digital agent galaxy.arXiv preprint arXiv:2511.11332, 2025. doi: 10.48550/arXiv.2511.113321, 2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.