Recognition: 2 theorem links
· Lean TheoremThe Illusion of Latent Generalization: Bi-directionality and the Reversal Curse
Pith reviewed 2026-05-15 11:16 UTC · model grok-4.3
The pith
Language models overcome the reversal curse only with explicit reverse-direction training signals, not by forming unified fact representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
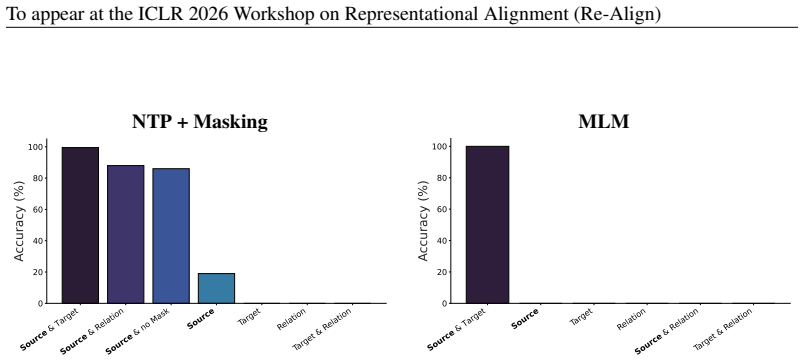
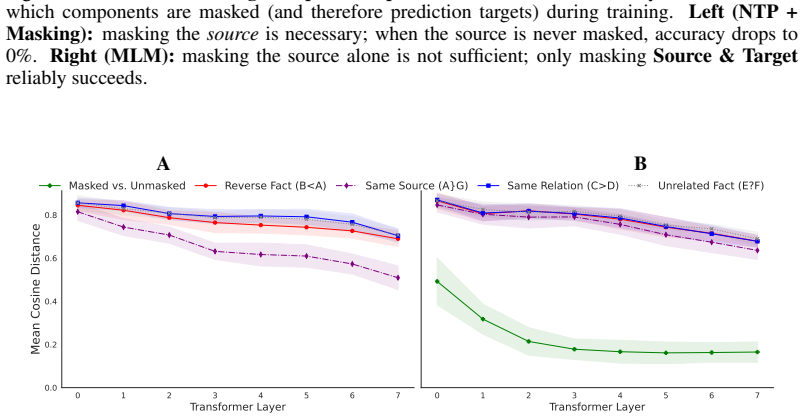
Reversal accuracy requires training signal that explicitly makes the source entity a prediction target. Representation distances and linear probes are consistent with storing forward and reverse directions as distinct entries, with different indexing geometry for MLM versus decoder-only masking-based training, rather than a single direction-agnostic representation of a fact.
What carries the argument
distinct directional entries for facts in hidden representations, identified via representation distances and linear probes
If this is right
- Bidirectional supervision improves reversal accuracy by creating separate forward and reverse entries.
- Different objectives produce different geometries for accessing those directional entries.
- Objective-level fixes can raise reversal performance without creating unified latent concepts.
- Vanilla MLM succeeds at reversal when it supplies explicit reverse prediction targets.
Where Pith is reading between the lines
- Models may need explicit bidirectional data for every fact to reach reliable relational reasoning.
- Scaling alone is unlikely to produce true direction-agnostic knowledge without changes to training signals.
- Similar separate storage patterns could appear in other relational or causal reasoning tasks.
Load-bearing premise
The chosen reversal benchmarks and linear probes on hidden states are sufficient to distinguish between unified latent concepts and distinct directional entries.
What would settle it
A model trained with bidirectional objectives that shows representation distances and probe results consistent with one shared vector for both directions would falsify the distinct-entries account.
Figures



read the original abstract
The reversal curse describes a failure of autoregressive language models to retrieve a fact in reverse order (e.g., training on ``$A > B$'' but failing on ``$B < A$''). Recent work shows that objectives with bidirectional supervision (e.g., bidirectional attention or masking-based reconstruction for decoder-only models) can mitigate the reversal curse. We extend this evaluation to include a vanilla masked language modeling (MLM) objective and compare it to decoder-only masking-based training across four reversal benchmarks and then provide a minimal mechanistic study of \emph{how} these objectives succeed. We show that reversal accuracy requires training signal that explicitly makes the source entity a prediction target, and we find little evidence that success corresponds to a single direction-agnostic representation of a fact. Instead, representation distances and linear probes are consistent with storing forward and reverse directions as distinct entries, with different indexing geometry for MLM versus decoder-only masking-based training. Our results caution that objective-level ``fixes'' can improve reversal behavior without necessarily inducing the kind of latent generalization one might expect from a unified concept.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the reversal curse in autoregressive language models can be mitigated by bidirectional supervision objectives such as vanilla masked language modeling (MLM) and decoder-only masking-based training. Across four reversal benchmarks, reversal accuracy requires explicit training signals that make the source entity a prediction target. Mechanistic analysis via representation distances and linear probes on hidden states finds little evidence for a single direction-agnostic latent representation; instead, results are consistent with forward and reverse directions being stored as distinct entries, with different indexing geometry for MLM versus decoder-only training.
Significance. If the central interpretation holds, the work is significant for cautioning that objective-level mitigations of the reversal curse do not necessarily produce unified conceptual representations. The empirical comparison of MLM and decoder-only masking, combined with internal representation analysis, provides concrete evidence on the role of explicit prediction targets and highlights the need for mechanistic scrutiny when interpreting generalization improvements in LLMs.
major comments (2)
- [Mechanistic study section] The mechanistic claim that representation distances and linear probes indicate distinct directional entries rather than a unified direction-agnostic representation rests on linear probes being sufficient to detect unified facts. Without non-linear probe baselines or controls for probe capacity, the separation could reflect readout limitations rather than storage format, especially given different objectives (MLM vs. decoder-only masking).
- [Abstract and Results] The abstract reports consistent patterns across four benchmarks and two probe types but provides no quantitative effect sizes, error bars, or details on data splits. This absence makes it difficult to assess the robustness of the reversal accuracy results and the probe-based evidence for distinct entries.
minor comments (2)
- [Mechanistic study] Clarify the precise definition and computation of 'representation distances' used to support the distinct-entries conclusion.
- [Abstract] Specify the four reversal benchmarks by name in the abstract for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and describe the planned revisions.
read point-by-point responses
-
Referee: [Mechanistic study section] The mechanistic claim that representation distances and linear probes indicate distinct directional entries rather than a unified direction-agnostic representation rests on linear probes being sufficient to detect unified facts. Without non-linear probe baselines or controls for probe capacity, the separation could reflect readout limitations rather than storage format, especially given different objectives (MLM vs. decoder-only masking).
Authors: We agree that linear probes alone do not fully exclude the possibility of a unified representation recoverable only via non-linear readouts, and that probe capacity should be controlled. In the revised manuscript we will add non-linear probe baselines (single-hidden-layer MLPs) to the mechanistic analysis section, reporting their accuracies alongside the linear results. We will also clarify that our interpretation relies on the combination of probe-independent representation distances and probe accuracies, which together favor distinct directional entries over a single latent fact. These additions will directly address the readout-limitation concern while preserving the original conclusions. revision: yes
-
Referee: [Abstract and Results] The abstract reports consistent patterns across four benchmarks and two probe types but provides no quantitative effect sizes, error bars, or details on data splits. This absence makes it difficult to assess the robustness of the reversal accuracy results and the probe-based evidence for distinct entries.
Authors: We acknowledge that the abstract would benefit from explicit quantitative information. In the revision we will update the abstract to report effect sizes (mean accuracy differences with standard errors across seeds), note the presence of error bars in the figures, and briefly describe the data splits (number of examples and train/test partitioning per benchmark). The main results section already contains these details with full tables; the abstract change will make the robustness information immediately accessible without altering any findings. revision: yes
Circularity Check
No circularity: purely empirical study with independent experimental results
full rationale
The paper conducts an empirical evaluation of reversal accuracy under different training objectives (MLM vs. decoder-only masking) across four benchmarks, followed by analysis of representation distances and linear probes on hidden states. No mathematical derivations, fitted parameters renamed as predictions, or self-citation chains are present in the claimed results. All conclusions follow directly from reported experimental measurements rather than reducing to inputs by construction. Self-citations to prior reversal-curse work are standard background and not load-bearing for the new findings.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
representation distances and linear probes are consistent with storing forward and reverse directions as distinct entries
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reversal accuracy requires training signal that explicitly makes the source entity a prediction target
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova
URLhttps://arxiv.org/abs/2309.12288. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,
-
[2]
URLhttps://aclanthology.org/N19-1423/. Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram´e, Morgane Rivi`ere, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Transformer Feed-Forward Layers Are Key-Value Memories
URLhttps://arxiv.org/abs/2012.14913. Olga Golovneva, Zeyuan Allen-Zhu, Jason Weston, and Sainbayar Sukhbaatar. Reverse training to nurse the reversal curse. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[4]
URLhttps://aclanthology.org/2024.emnlp-main. 754.pdf. Andrew K. Lampinen, A. Chaudhry, S. C. Chan, et al. On the generalization of language models from in-context learning and finetuning: a controlled study.arXiv preprint arXiv:2505.00661, 2025a. URLhttps://arxiv.org/abs/2505.00661. Andrew Kyle Lampinen, Martin Engelcke, Yuxuan Li, Arslan Chaudhry, and Ja...
-
[5]
doi: 10.18653/v1/2024.emnlp-main.754
Associa- tion for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.754. URLhttps: //aclanthology.org/2024.emnlp-main.754/. Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word represen- tations in vector space. InICLR,
-
[6]
Large Language Diffusion Models
URLhttps:// arxiv.org/abs/2502.09992. Xu Pan, Ely Hahami, Jingxuan Fan, Ziqian Xie, and Haim Sompolinsky. Closing the data-efficiency gap between autoregressive and masked diffusion llms,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
URLhttps://arxiv.org/ abs/2510.09885. H. Wang et al. Tracing representation progression: Analyzing and enhancing layer-wise similarity. arXiv preprint arXiv:2406.14479,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
fempare more dangerous thanglon
6 To appear at the ICLR 2026 Workshop on Representational Alignment (Re-Align) Held-out fact (train forward only):A > BTest query (reverse):B < ...→predictA NTP (causal mask) Train input:A > B. Loss:next-token prediction on the sequence. Examples: ✓A > B(standard forward sequence) ×B < ...(we donottrain on reverse prompts) MLM (bidirectional attention) Tr...
work page 2026
-
[9]
B.1 ILLUSTRATION OF TRAINING SAMPLES ONSimple Reversal Table 2 illustrates, for a single fact “A > B”, what training sequences look like under each objective (forSimple Reversal). This is only meant as an intuition pump; for multi-token entities, MLM uses token-level masking with probability 0.15 and NTP+Masking uses a sampled masking ratio. C AUXILIARY A...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.