Recognition: 2 theorem links
· Lean TheoremSynthetic Trust Attacks: Modeling How Generative AI Manipulates Human Decisions in Social Engineering Fraud
Pith reviewed 2026-05-13 20:38 UTC · model grok-4.3
The pith
Synthetic Trust Attacks succeed by targeting the victim's decision to comply, not by evading media detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that AI has not invented new crimes but has industrialized the manufacture of trust, making the victim's decision the true attack surface. The paper introduces the Synthetic Trust Attack Model (STAM) as an eight-stage operational framework from reconnaissance through post-compliance leverage, a five-category Trust-Cue Taxonomy, a 17-field Incident Coding Schema, and four falsifiable hypotheses that link attack structure to compliance outcomes. It operationalizes the Calm, Check, Confirm protocol as a research-grade decision-layer defense and concludes that synthetic credibility, not synthetic media, defines the AI fraud era.
What carries the argument
The Synthetic Trust Attack Model (STAM), an eight-stage operational framework that maps the complete attack chain from adversary reconnaissance to post-compliance leverage and shifts focus from media detection to decision-layer intervention.
If this is right
- Security policies must add decision-layer tools such as the Calm, Check, Confirm protocol alongside existing media-detection systems.
- The 17-field Incident Coding Schema enables reproducible analysis of future cases to test the four hypotheses on attack structure and compliance.
- Research should prioritize falsifiable tests of how specific trust cues in the taxonomy influence victim decisions.
- Practitioners can apply the five-category Trust-Cue Taxonomy to design training that targets decision vulnerabilities rather than perceptual ones.
- Organizations facing high-stakes transfers should treat synthetic credibility as the primary risk metric instead of media authenticity alone.
Where Pith is reading between the lines
- Employee training programs could simulate STAM-stage attacks in controlled environments to measure and improve decision resistance beyond current media-spotting drills.
- The framework may extend to non-financial domains such as political influence or personal relationships where generative AI creates false urgency or authority.
- Future incident databases built on the coding schema could reveal whether certain STAM stages correlate more strongly with success, guiding prioritized defenses.
- Integration of the protocol into communication platforms might provide real-time prompts during suspicious calls to interrupt compliance.
Load-bearing premise
The cited compliance rates of 46 percent for LLM agents versus 18 percent for humans and the 55.5 percent deepfake detection accuracy generalize beyond the referenced studies, and the eight-stage STAM framework accurately captures the causal structure of real attacks without missing key variables.
What would settle it
A controlled study or expanded incident database that directly measures compliance rates in operational settings using LLM agents versus human operators, along with deepfake detection accuracy in realistic video-call scenarios, to test whether the reported figures hold and whether STAM stages predict outcomes.
Figures


read the original abstract
Imagine receiving a video call from your CFO, surrounded by colleagues, asking you to urgently authorise a confidential transfer. You comply. Every person on that call was fake, and you just lost $25 million. This is not a hypothetical. It happened in Hong Kong in January 2024, and it is becoming the template for a new generation of fraud. AI has not invented a new crime. It has industrialised an ancient one: the manufacture of trust. This paper proposes Synthetic Trust Attacks (STAs) as a formal threat category and introduces STAM, the Synthetic Trust Attack Model, an eight-stage operational framework covering the full attack chain from adversary reconnaissance through post-compliance leverage. The core argument is this: existing defenses target synthetic media detection, but the real attack surface is the victim's decision. When human deepfake detection accuracy sits at approximately 55.5%, barely above chance, and LLM scam agents achieve 46% compliance versus 18% for human operators while evading safety filters entirely, the perception layer has already failed. Defense must move to the decision layer. We present a five-category Trust-Cue Taxonomy, a reproducible 17-field Incident Coding Schema with a pilot-coded example, and four falsifiable hypotheses linking attack structure to compliance outcomes. The paper further operationalizes the author's practitioner-developed Calm, Check, Confirm protocol as a research-grade decision-layer defense. Synthetic credibility, not synthetic media, is the true attack surface of the AI fraud era.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Synthetic Trust Attacks (STAs) as a formal threat category for generative AI-enabled social engineering and introduces the eight-stage Synthetic Trust Attack Model (STAM) spanning reconnaissance through post-compliance leverage. It argues that the perception layer has already failed because human deepfake detection accuracy is approximately 55.5% and LLM scam agents achieve 46% compliance versus 18% for human operators, necessitating a shift to decision-layer defenses. The paper presents a five-category Trust-Cue Taxonomy, a reproducible 17-field Incident Coding Schema with a pilot-coded example, four falsifiable hypotheses linking attack structure to compliance, and operationalizes the Calm, Check, Confirm protocol.
Significance. If the empirical foundations and framework hold, the work supplies an operational structure for modeling AI-manipulated trust in fraud and redirects defense research toward human decision processes rather than media detection alone. The reproducible 17-field coding schema and four falsifiable hypotheses are concrete strengths that could support standardized incident analysis and empirical testing across studies.
major comments (2)
- [Abstract] Abstract and empirical claims: The central claim that the perception layer has failed (and that defense must therefore shift to the decision layer) rests on the specific figures of 55.5% deepfake detection accuracy and 46% versus 18% compliance rates. These statistics are presented without accompanying sources, error bars, study methodologies, or discussion of contextual differences (e.g., low-stakes text setups versus high-urgency video-call scenarios with organizational protocols), which directly undermines the generalizability argument for real-world attacks such as the cited Hong Kong incident.
- [STAM description] STAM framework (eight-stage model): The model is offered as an operational causal mapping from reconnaissance to post-compliance leverage, yet the manuscript provides no derivation steps, validation data against real incidents, or controls for confounding variables such as prior user training or multi-cue verification. This gap is load-bearing because the framework is used to justify moving defenses to the decision layer.
minor comments (2)
- [Incident Coding Schema] The 17-field Incident Coding Schema is presented as reproducible with a pilot example; adding an explicit table or appendix listing all 17 fields with definitions would improve immediate usability for other researchers.
- [References] Ensure all cited statistics are accompanied by full references in the bibliography so readers can independently evaluate the studies' scope and limitations.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for identifying areas where additional rigor will strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract and empirical claims: The central claim that the perception layer has failed (and that defense must therefore shift to the decision layer) rests on the specific figures of 55.5% deepfake detection accuracy and 46% versus 18% compliance rates. These statistics are presented without accompanying sources, error bars, study methodologies, or discussion of contextual differences (e.g., low-stakes text setups versus high-urgency video-call scenarios with organizational protocols), which directly undermines the generalizability argument for real-world attacks such as the cited Hong Kong incident.
Authors: We agree that the abstract would be improved by explicit citations and brief contextual qualifiers for these statistics. The 55.5% figure derives from a cited meta-analysis of human deepfake detection performance, while the 46% versus 18% compliance rates come from controlled experiments comparing LLM scam agents to human operators. In the revised version we will insert parenthetical citations in the abstract, add a short methods paragraph in the main text discussing study designs, sample sizes, and limitations (including stakes and verification protocols), and expand the discussion of generalizability to high-urgency scenarios such as the Hong Kong incident. These changes will make the empirical grounding transparent without altering the core argument. revision: yes
-
Referee: [STAM description] STAM framework (eight-stage model): The model is offered as an operational causal mapping from reconnaissance to post-compliance leverage, yet the manuscript provides no derivation steps, validation data against real incidents, or controls for confounding variables such as prior user training or multi-cue verification. This gap is load-bearing because the framework is used to justify moving defenses to the decision layer.
Authors: The STAM stages were derived from systematic mapping of adversary actions observed in documented incidents, including the Hong Kong case and additional publicly reported AI-enabled frauds. We will add a new subsection (and supporting appendix) that explicitly describes the derivation process, provides a validation table aligning each stage with multiple real incidents, and discusses potential confounding factors such as user training and multi-cue verification together with proposed controls for future empirical studies. This addition will make the framework's construction and applicability more transparent while preserving its operational focus. revision: yes
Circularity Check
STAM is a definitional framework with no circular derivations or load-bearing self-citations
full rationale
The paper introduces STAM as an eight-stage operational model, Trust-Cue Taxonomy, Incident Coding Schema, and four falsifiable hypotheses drawn from analysis of the Hong Kong incident and external studies. Key statistics (55.5% detection accuracy, 46%/18% compliance) are presented as citations to referenced work rather than outputs derived or fitted within this manuscript. No equations, predictions, or reductions appear that loop back to inputs by construction. The Calm, Check, Confirm protocol is operationalized from the author's prior practitioner work but does not serve as a self-referential derivation for the central claims. The structure remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Human deepfake detection accuracy is approximately 55.5% and LLM scam agents achieve 46% compliance versus 18% for human operators
- domain assumption The eight-stage attack chain from reconnaissance to post-compliance leverage accurately represents real synthetic trust attacks
invented entities (3)
-
Synthetic Trust Attacks (STAs)
no independent evidence
-
STAM (Synthetic Trust Attack Model)
no independent evidence
-
Trust-Cue Taxonomy
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
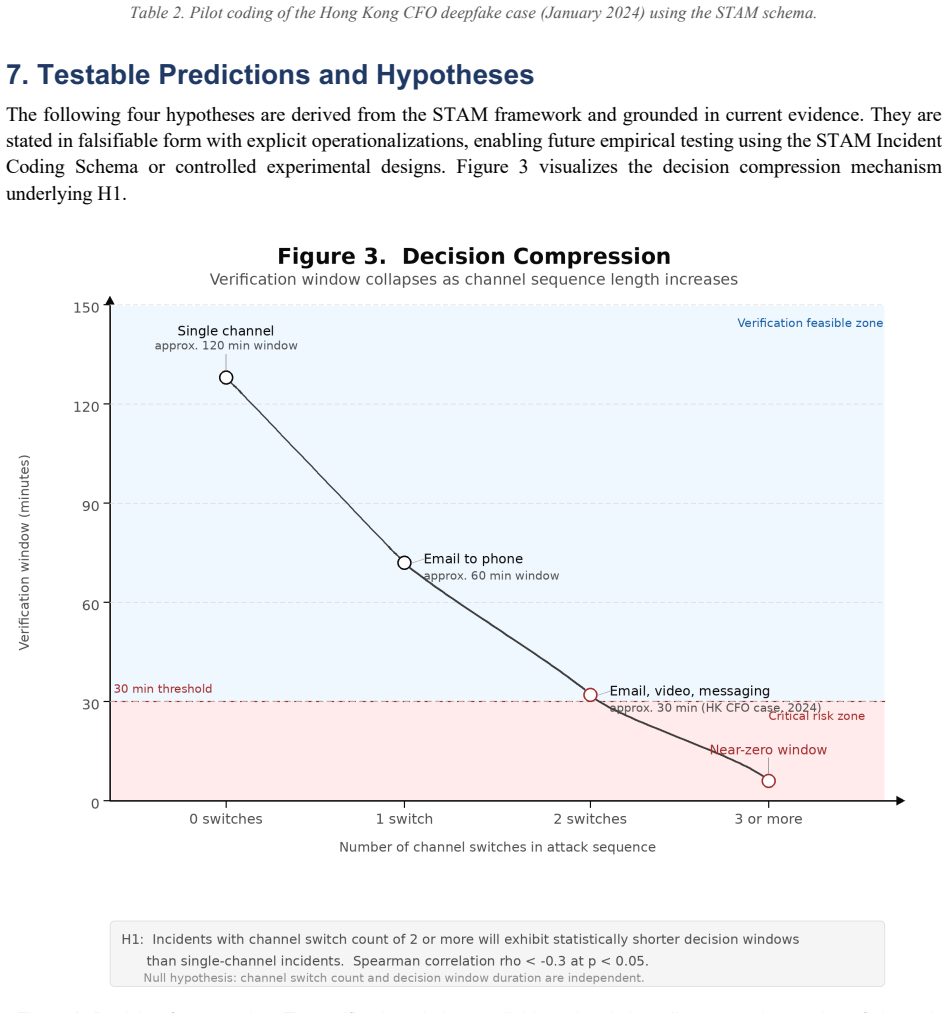
STAM formalizes the operational chain of a Synthetic Trust Attack through eight sequentially dependent but iteratively reinforcing stages... Stage 6 (Decision Compression) is the novel contribution
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
human deepfake detection accuracy of approximately 55.5%... LLM scam agents achieve 46% compliance versus 18% for human operators
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
What has changed is the industrial capacity to execute deception at scale
Introduction The sociology of deception has not changed. What has changed is the industrial capacity to execute deception at scale. Generative AI does not invent fraud; it perfects it, enabling attackers to construct highly personalized, multimodal social engineering attacks that compress verification windows, manufacture authority, and exploit cognitive ...
work page 2024
-
[2]
Related Work 2.1 Generative AI as a Social Engineering Amplifier The systematic literature has converged on a three-pillar amplification model [11]. Content realism refers to the capacity of generative models to produce text, audio, and video indistinguishable from authentic human output. Targeting and personalization encompasses LLM-driven bespoke pretex...
work page 2030
-
[3]
Threat Model and Definitions 3.1 Formal Definition A Synthetic Trust Attack (STA) is a social engineering campaign in which an adversary employs generative AI to manufacture, bundle, and deliver trust cues including identity simulation, contextual plausibility signals, authority indicators, and linguistic style mimicry, through orchestrated multi-channel ...
-
[4]
STAM: The Synthetic Trust Attack Model STAM formalizes the operational chain of a Synthetic Trust Attack through eight sequentially dependent but iteratively reinforcing stages. The model is designed to be codeable: each stage maps to specific observable variables extractable from incident reports, law enforcement advisories, and victim accounts. Figure 1...
-
[5]
Figure 2 presents the full taxonomy
Trust-Cue Taxonomy The Trust-Cue Taxonomy organizes the components of synthetic credibility into five measurable categories. Figure 2 presents the full taxonomy. Each cue category maps to specific STAM stages and specific coding variables in the Incident Schema. Figure 2. Trust-Cue Taxonomy. Five categories through which adversaries manufacture synthetic ...
work page 2024
-
[6]
Table 1 presents the full schema
Incident Coding Schema and Dataset Design The STAM Incident Coding Schema provides a reproducible framework for analyzing synthetic trust attacks across jurisdictions, victim segments, and time periods. Table 1 presents the full schema. Table 2 presents pilot coding of the Hong Kong CFO case (2024) across all schema fields. Field Values / Format Coding No...
work page 2024
-
[7]
Defensive Framework: Calm, Check, Confirm The Calm, Check, Confirm framework, developed from practitioner experience and previously described in work deposited on Zenodo (ORCID: 0009-0001-3400-5016), is here operationalized as a research-grade defensive protocol with falsifiable components. The framework addresses the STAM Stage 6 mechanism directly: by i...
work page 2025
-
[8]
Discussion 9.1 Implications for Enterprise Security The STAM framework reveals a fundamental misalignment in current enterprise security investment: the majority of resources are directed toward detection, while the attack has migrated to the decision layer. An organization with robust two-person authorization requirements and out-of-band verification pro...
-
[9]
Future Work Four research directions follow directly from this paper's contributions. First, the STAM Incident Coding Schema should be applied to a cross-jurisdictional corpus of at least 100 coded incidents with inter-rater reliability established, enabling the first statistically powered tests of H1 through H4. Priority sources include IC3 annual report...
-
[10]
Love, Lies, and Language Models: Investigating AI's Role in Romance-Baiting Scams
My Final Conclusion Generative AI has not invented a new category of crime. It has industrialized an ancient one. The capacity to manufacture trust has always been the core capability of skilled fraud operators. What generative AI provides is the ability to deploy that capacity at industrial scale, across thousands of targets simultaneously, with personal...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Fooled Twice: People Cannot Detect Deepfakes but Think They Can
Kobis, N., et al. Fooled Twice: People Cannot Detect Deepfakes but Think They Can. iScience, 24(11), 2021. [11] Bethany, M., et al. Generative AI in Social Engineering Attacks: A Systematic Review. ACM Computing Surveys, 57(3), 2024. [12] Chesney, R. and Citron, D.K. Deep Fakes: A Looming Challenge for Privacy, Democracy, and National Security. California...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.