Recognition: no theorem link
Prune-Quantize-Distill: An Ordered Pipeline for Efficient Neural Network Compression
Pith reviewed 2026-05-13 16:59 UTC · model grok-4.3
The pith
An ordered pipeline of pruning, INT8 quantization, and distillation produces better accuracy-size-latency tradeoffs than any technique used alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
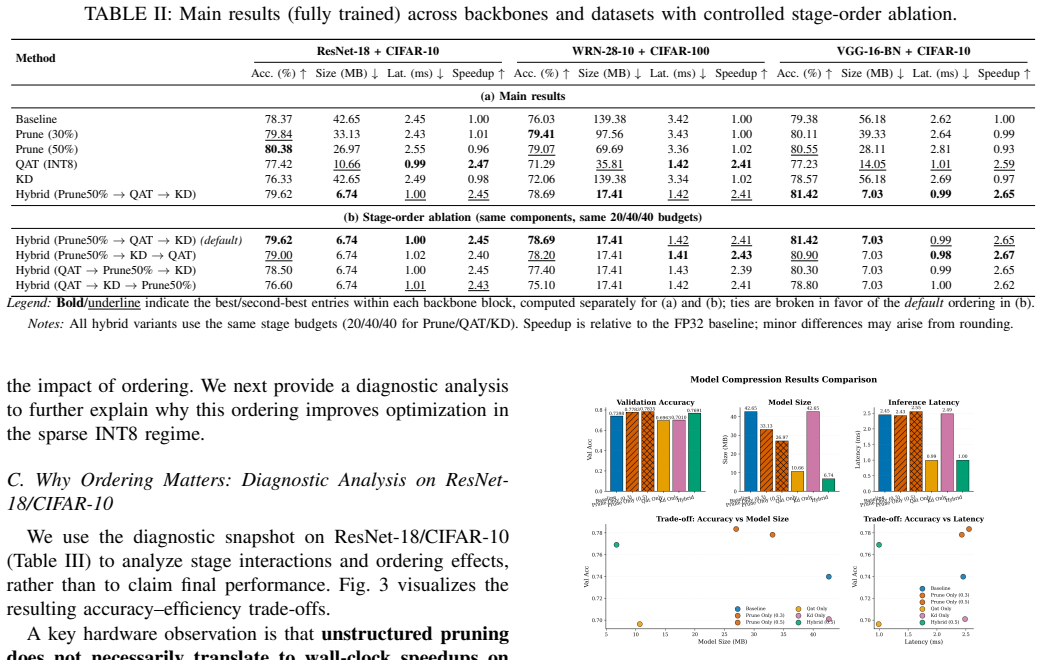
The paper claims that combining unstructured pruning, INT8 quantization-aware training, and knowledge distillation in that specific order creates models with superior accuracy at given sizes and measured CPU latencies compared to any single method or different ordering. Pruning serves mainly as a preconditioner that makes quantization more robust, quantization provides the dominant latency reduction to around 1 ms, and distillation recovers lost accuracy in the final sparse low-precision model. On CIFAR datasets with standard backbones, this reaches 0.99-1.42 ms latency with competitive accuracy.
What carries the argument
The ordered pipeline Prune-Quantize-Distill, in which pruning reduces capacity to aid quantization robustness, INT8 QAT supplies the primary runtime improvement through lower precision arithmetic, and KD restores accuracy without altering deployment characteristics.
If this is right
- Compressed models achieve 0.99 to 1.42 milliseconds CPU latency while maintaining competitive accuracy on image classification tasks.
- Evaluating compression in the joint accuracy-size-latency space using actual runtime measurements yields better results than relying on FLOPs or parameter counts alone.
- Applying the techniques in the prune-then-quantize-then-distill order generally outperforms other sequences when total training epochs are fixed.
- INT8 quantization-aware training is the main driver of latency reduction, while pruning improves the stability of the quantization step.
Where Pith is reading between the lines
- Similar ordered pipelines could be tested on larger-scale datasets like ImageNet to check if the same dominance of quantization holds.
- The emphasis on measured latency suggests that compression methods should be benchmarked directly on target hardware rather than theoretical proxies.
- This work implies that for CPU edge deployment, combining multiple compression stages in careful order can expand the feasible model space beyond what isolated methods allow.
- Future research might explore whether reversing the order or interleaving steps could yield further gains on different hardware.
Load-bearing premise
The observed superiority of the prune-quantize-distill order and the primary benefit from INT8 QAT will continue to hold when tested on different datasets, larger models, or non-CPU hardware.
What would settle it
An experiment applying the pipeline to a different dataset such as ImageNet and a different backbone such as ResNet-50, then checking whether the ordered approach still produces a better accuracy-latency curve than baselines on the same CPU hardware.
Figures


read the original abstract
Modern deployment often requires trading accuracy for efficiency under tight CPU and memory constraints, yet common compression proxies such as parameter count or FLOPs do not reliably predict wall-clock inference time. In particular, unstructured sparsity can reduce model storage while failing to accelerate (and sometimes slightly slowing down) standard CPU execution due to irregular memory access and sparse kernel overhead. Motivated by this gap between compression and acceleration, we study a practical, ordered pipeline that targets measured latency by combining three widely used techniques: unstructured pruning, INT8 quantization-aware training (QAT), and knowledge distillation (KD). Empirically, INT8 QAT provides the dominant runtime benefit, while pruning mainly acts as a capacity-reduction pre-conditioner that improves the robustness of subsequent low-precision optimization; KD, applied last, recovers accuracy within the already constrained sparse INT8 regime without changing the deployment form. We evaluate on CIFAR-10/100 using three backbones (ResNet-18, WRN-28-10, and VGG-16-BN). Across all settings, the ordered pipeline achieves a stronger accuracy-size-latency frontier than any single technique alone, reaching 0.99-1.42 ms CPU latency with competitive accuracy and compact checkpoints. Controlled ordering ablations with a fixed 20/40/40 epoch allocation further confirm that stage order is consequential, with the proposed ordering generally performing best among the tested permutations. Overall, our results provide a simple guideline for edge deployment: evaluate compression choices in the joint accuracy-size-latency space using measured runtime, rather than proxy metrics alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an ordered pipeline of unstructured pruning, followed by INT8 quantization-aware training (QAT), followed by knowledge distillation (KD) for neural network compression. It claims that this ordering yields a stronger accuracy-size-latency frontier than any single technique or alternative permutations on CIFAR-10/100 using ResNet-18, WRN-28-10, and VGG-16-BN, with INT8 QAT providing the dominant runtime gains, pruning acting as a preconditioner for QAT robustness, and KD recovering accuracy in the sparse low-precision regime, reaching 0.99-1.42 ms CPU latency.
Significance. If the empirical results hold under the tested conditions, the work is significant for practical edge deployment because it shifts focus from proxy metrics (parameter count, FLOPs) to measured wall-clock latency and shows that stage ordering is consequential even under fixed epoch budgets. The finding that QAT dominates and pruning preconditions it offers a concrete, actionable guideline supported by direct latency measurements and ordering ablations.
major comments (3)
- [Experimental Results] Experimental Results section: reported accuracy and latency numbers lack error bars, standard deviations, or results from multiple random seeds, which is necessary to establish that the proposed ordering's improvements over baselines and other permutations are statistically reliable rather than run-specific.
- [Ablation Studies] Ablation Studies: the ordering comparisons use a fixed 20/40/40 epoch allocation but provide no exact hyperparameter values, optimizer settings, data splits, or pruning ratios, limiting independent verification of the claim that the prune-quantize-distill order is generally best.
- [Discussion] Discussion: the guideline recommending the proposed ordering for practitioners rests on CIFAR-10/100, three CNN backbones, and CPU measurements only; the central claim of a strictly superior frontier would require either explicit scope limitation or additional experiments on ImageNet-scale data and other hardware, where unstructured sparsity and quantization overheads differ.
minor comments (2)
- [Abstract] Abstract: the phrase 'compact checkpoints' is used without accompanying numerical model sizes or compression ratios in the reported results.
- [Experimental Setup] Notation: latency is reported in ms but the measurement protocol (batch size, number of warm-up iterations, hardware model) is not stated in the main text or captions.
Simulated Author's Rebuttal
Thank you for the referee's insightful comments. We appreciate the emphasis on statistical rigor, reproducibility, and clear scoping of our findings. Below we provide point-by-point responses and indicate planned revisions.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: reported accuracy and latency numbers lack error bars, standard deviations, or results from multiple random seeds, which is necessary to establish that the proposed ordering's improvements over baselines and other permutations are statistically reliable rather than run-specific.
Authors: We agree with this observation. To strengthen the reliability of our results, we will rerun the key experiments with multiple random seeds (at least 3) and include error bars and standard deviations in the Experimental Results section and tables for both accuracy and latency metrics. revision: yes
-
Referee: [Ablation Studies] Ablation Studies: the ordering comparisons use a fixed 20/40/40 epoch allocation but provide no exact hyperparameter values, optimizer settings, data splits, or pruning ratios, limiting independent verification of the claim that the prune-quantize-distill order is generally best.
Authors: We acknowledge the need for more detailed information to enable independent verification. In the revised version, we will provide exact hyperparameter values, including optimizer settings (SGD with specific learning rates and momentum), data augmentation and splits, and the precise pruning ratios applied at each stage in the Ablation Studies section. revision: yes
-
Referee: [Discussion] Discussion: the guideline recommending the proposed ordering for practitioners rests on CIFAR-10/100, three CNN backbones, and CPU measurements only; the central claim of a strictly superior frontier would require either explicit scope limitation or additional experiments on ImageNet-scale data and other hardware, where unstructured sparsity and quantization overheads differ.
Authors: We concur that our claims are scoped to the evaluated datasets and hardware. We will revise the Discussion to explicitly limit the scope of the guideline to CIFAR-10/100, the three CNN architectures tested, and CPU latency measurements. We will also discuss potential differences on larger datasets and other hardware without claiming universality. revision: partial
- Performing additional experiments on ImageNet-scale datasets and diverse hardware platforms due to computational resource constraints.
Circularity Check
No circularity: purely empirical evaluation with direct measurements
full rationale
The paper reports an empirical comparison of compression orderings on CIFAR-10/100 using ResNet-18, WRN-28-10 and VGG-16-BN. All results consist of measured accuracy, model size and CPU latency after applying pruning, INT8 QAT and KD in different sequences; no equations, fitted parameters presented as predictions, or self-citation chains are used to derive the central claim. The ordering benefit is demonstrated by controlled ablations with fixed epoch budgets and direct runtime measurements, making the work self-contained against external benchmarks without any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Knowledge distillation can recover accuracy within a constrained sparse INT8 regime without altering deployment form.
- domain assumption Unstructured pruning acts primarily as a capacity-reduction preconditioner that improves robustness of subsequent low-precision optimization.
Reference graph
Works this paper leans on
-
[1]
Y . Cheng, D. Wang, P. Zhou, and T. Zhang, “Model compression and acceleration for deep neural networks: The principles, progress, and challenges,”IEEE Signal Process. Mag., vol. 35, no. 1, pp. 126–136, 2018
work page 2018
-
[2]
A comprehensive review of model compression techniques in machine learning,
P. V . Dantas, W. Sabino da Silva, L. C. Cordeiro, and C. B. Carvalho, “A comprehensive review of model compression techniques in machine learning,”Appl. Intell., vol. 54, no. 22, p. 11804–11844, Sep. 2024. [Online]. Available: https://doi.org/10.1007/s10489-024-05747-w
-
[3]
Deep neural networks compression: A comparative survey and choice recommenda- tions,
G. C. Marin ´o, A. Petrini, D. Malchiodi, and M. Frasca, “Deep neural networks compression: A comparative survey and choice recommenda- tions,”Neurocomputing, vol. 520, pp. 152–170, 2023
work page 2023
-
[4]
Deep neural network compression by in- parallel pruning-quantization,
T. Frederick and M. Greg, “Deep neural network compression by in- parallel pruning-quantization,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 6, 2018
work page 2018
-
[5]
A survey on deep neural network pruning: Taxonomy, comparison, analysis, and recommendations,
H. Cheng, M. Zhang, and J. Q. Shi, “A survey on deep neural network pruning: Taxonomy, comparison, analysis, and recommendations,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 12, pp. 10 558–10 578, 2024
work page 2024
-
[6]
Incremental network quantization: Towards lossless cnns with low-precision weights,
A. Zhou, A. Yao, Y . Guo, L. Xu, and Y . Chen, “Incremental network quantization: Towards lossless cnns with low-precision weights,”arXiv preprint arXiv:1702.03044, 2017
-
[7]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
Boosting pruned networks with linear over-parameterization,
Y . Qian, X. Li, J. Cao, J. Zhang, H. Li, and J. Chen, “Boosting pruned networks with linear over-parameterization,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP). IEEE, 2024, pp. 5070– 5074
work page 2024
-
[9]
arXiv preprint arXiv:2106.14681 (2021)
J. Kim, S. Chang, and N. Kwak, “Pqk: model compression via pruning, quantization, and knowledge distillation,”arXiv preprint arXiv:2106.14681, 2021
-
[10]
Comp-diff: A unified pruning and distillation framework for compressing diffusion models,
L. Yu, W. Xiang, K. Han, G. Liu, and R. Kompella, “Comp-diff: A unified pruning and distillation framework for compressing diffusion models,”IEEE Trans. Multimedia, vol. 27, pp. 8486–8497, 2025
work page 2025
-
[11]
Pruning and quantization for deep neural network acceleration: A survey,
T. Liang, J. Glossner, L. Wang, S. Shi, and X. Zhang, “Pruning and quantization for deep neural network acceleration: A survey,”Neuro- computing, vol. 461, pp. 370–403, 2021
work page 2021
-
[12]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
J. Frankle and M. Carbin, “The lottery ticket hypothesis: Finding sparse, trainable neural networks,”arXiv preprint arXiv:1803.03635, 2018
work page Pith review arXiv 2018
-
[13]
SNIP: Single-shot Network Pruning based on Connection Sensitivity
N. Lee, T. Ajanthan, and P. H. Torr, “Snip: Single-shot network pruning based on connection sensitivity,”arXiv preprint arXiv:1810.02340, 2018
work page Pith review arXiv 2018
-
[14]
Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients,
S. Zhou, Y . Wu, Z. Ni, X. Zhou, H. Wen, and Y . Zou, “Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients,”arXiv preprint arXiv:1606.06160, 2016
-
[15]
Learned step size quantization,
S. K. Esser, J. L. McKinstry, D. Bablani, R. Appuswamy, and D. S. Modha, “Learned step size quantization,”arXiv preprint arXiv:1902.08153, 2019
-
[16]
Contrastive representation distilla- tion,
Y . Tian, D. Krishnan, and P. Isola, “Contrastive representation distilla- tion,”arXiv preprint arXiv:1910.10699, 2019
-
[17]
Once-for-all: Train one network and specialize it for efficient deployment,
H. Cai, C. Gan, T. Wang, Z. Zhang, and S. Han, “Once-for-all: Train one network and specialize it for efficient deployment,”arXiv preprint arXiv:1908.09791, 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.