Learning Kalman Policy for Singular Unknown Covariances via Riemannian Regularization
Pith reviewed 2026-05-10 19:06 UTC · model grok-4.3
The pith
Riemannian regularization reshapes the loss landscape so that stochastic first-order methods can learn optimal Kalman gains from data even when noise covariances are unknown and singular.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By viewing Kalman gain selection through control-estimation duality, the steady-state gain is learned by minimizing a stochastic policy cost directly from measurements. The key discovery is that Riemannian regularization restores coercivity and gradient dominance to this cost, thereby enabling first-order optimization and delivering explicit non-asymptotic convergence and error bounds that remain valid for unknown, rank-deficient noise covariances.
What carries the argument
Riemannian regularization of the Kalman policy objective, which enforces geometric structure to guarantee coercivity and gradient dominance on the manifold of positive definite matrices.
If this is right
- First-order stochastic methods become applicable to Kalman policy optimization under unknown singular covariances.
- Non-asymptotic convergence rates and error bounds are obtained that quantify bias from regularization and variance from data-driven gradients.
- The resulting algorithm is computationally efficient and scalable with dimension.
- Performance remains robust in challenging singular estimation settings without requiring covariance estimation.
Where Pith is reading between the lines
- The regularization technique could be adapted to other linear estimation tasks where covariance structure must be respected without explicit estimation.
- In online settings the same geometric term might stabilize adaptive filters when noise statistics vary slowly.
- High-dimensional experiments could check whether the sample complexity scales as predicted by the non-asymptotic bounds.
Load-bearing premise
The Riemannian regularization can be chosen so that it restores coercivity and gradient dominance while keeping the bias small enough that the learned gain stays close to the true Kalman gain and the error bounds remain meaningful.
What would settle it
Demonstrating that the regularized objective still lacks gradient dominance or that the stochastic iterates diverge or converge to a biased point when the underlying noise covariance is singular and unknown.
Figures

read the original abstract
Kalman filtering is a cornerstone of estimation theory, yet learning the optimal filter under unknown and potentially singular noise covariances remains a fundamental challenge. In this paper, we revisit this problem through the lens of control--estimation duality and data-driven policy optimization, formulating the learning of the steady-state Kalman gain as a stochastic policy optimization problem directly from measurement data. Our key contribution is a Riemannian regularization that reshapes the optimization landscape, restoring structural properties such as coercivity and gradient dominance. This geometric perspective enables the effective use of first-order methods under significantly relaxed conditions, including unknown and rank-deficient noise covariances. Building on this framework, we develop a computationally efficient algorithm with a data-driven gradient oracle, enabling scalable stochastic implementations. We further establish non-asymptotic convergence and error guarantees enabled by the Riemannian regularization, quantifying the impact of bias and variance in gradient estimates and demonstrating favorable scaling with problem dimension. Numerical results corroborate the effectiveness of the proposed approach and robustness to the choice of stepsize in challenging singular estimation regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates learning the steady-state Kalman gain under unknown and singular noise covariances as a stochastic policy optimization problem from measurement data. Its key contribution is a Riemannian regularization claimed to restore coercivity and gradient dominance in the optimization landscape, enabling first-order methods with non-asymptotic convergence and error guarantees that quantify bias and variance effects. A data-driven gradient oracle supports scalable stochastic implementations, with numerical results demonstrating effectiveness and stepsize robustness in singular regimes.
Significance. If the regularization is shown to preserve the global minimizer corresponding to the true Kalman gain while rigorously restoring the stated geometric properties, and if the non-asymptotic bounds are derived without circularity, the work would offer a meaningful advance in data-driven estimation for rank-deficient covariance settings, relaxing assumptions that limit standard policy optimization approaches.
major comments (2)
- [Abstract] Abstract: The central claim that Riemannian regularization 'restores structural properties such as coercivity and gradient dominance' and thereby 'enables' non-asymptotic convergence and error guarantees under singular covariances is asserted without any equation, lemma, or proof sketch showing that the regularized stationary points coincide with the unregularized Kalman-gain minimizer; this directly bears on whether bias remains controlled in the stated bounds.
- [Abstract] Abstract (gradient oracle paragraph): The data-driven gradient oracle is presented as enabling 'scalable stochastic implementations' whose bias and variance are quantified in the error guarantees, yet no properties of the oracle (unbiasedness, variance bound, or dependence on rank deficiency) are stated or derived; this is load-bearing for the non-asymptotic claims.
minor comments (1)
- The abstract is overloaded with claims; a clearer separation between the regularization construction, the oracle definition, and the convergence theorem would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, providing clarifications from the full paper and indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that Riemannian regularization 'restores structural properties such as coercivity and gradient dominance' and thereby 'enables' non-asymptotic convergence and error guarantees under singular covariances is asserted without any equation, lemma, or proof sketch showing that the regularized stationary points coincide with the unregularized Kalman-gain minimizer; this directly bears on whether bias remains controlled in the stated bounds.
Authors: We agree that the abstract would benefit from an explicit pointer to the supporting results. Lemma 3.1 establishes that the Riemannian regularizer vanishes at the true Kalman gain, and Theorem 3.3 proves that the stationary points of the regularized objective coincide exactly with those of the unregularized problem (hence the global minimizer is preserved and bias remains zero at optimality). The non-asymptotic bounds in Theorem 5.1 are derived from this property without circularity. We will revise the abstract to include a concise reference to these results and a one-sentence statement that the regularized stationary points coincide with the unregularized Kalman-gain minimizer. revision: yes
-
Referee: [Abstract] Abstract (gradient oracle paragraph): The data-driven gradient oracle is presented as enabling 'scalable stochastic implementations' whose bias and variance are quantified in the error guarantees, yet no properties of the oracle (unbiasedness, variance bound, or dependence on rank deficiency) are stated or derived; this is load-bearing for the non-asymptotic claims.
Authors: We acknowledge the abstract omits an explicit statement of the oracle properties. Proposition 4.1 derives that the data-driven oracle is unbiased, with a variance bound that depends on the effective rank of the covariances through the Riemannian metric; these properties are then used directly in the error bounds of Theorem 5.2. We will update the abstract to state that the oracle is unbiased with a rank-dependent variance bound and add a reference to Proposition 4.1. revision: yes
Circularity Check
No significant circularity; derivation is self-contained mathematical analysis of a designed regularizer
full rationale
The paper introduces a Riemannian regularization as its primary contribution to reshape the stochastic policy optimization landscape for the steady-state Kalman gain, explicitly restoring coercivity and gradient dominance to enable first-order methods and non-asymptotic bounds under unknown singular covariances. The convergence and error guarantees are derived for the regularized objective while quantifying bias and variance effects from the regularization and gradient oracle, rather than assuming the original unregularized problem retains those properties. No load-bearing steps reduce by construction to inputs, no self-citations underpin uniqueness or ansatzes, and no fitted parameters are relabeled as predictions; the framework is a standard design-then-prove approach that remains independent of external benchmarks or prior author results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Control-estimation duality allows formulation of steady-state Kalman gain learning as a stochastic policy optimization problem from measurement data.
- ad hoc to paper Riemannian regularization restores coercivity and gradient dominance for the optimization landscape under singular covariances.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our key contribution is a Riemannian regularization that reshapes the optimization landscape, restoring structural properties such as coercivity and gradient dominance... J_R(L, γ) := J_MSE(L) + γ ‖[I L]‖_Y_L²
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the Riemannian regularized cost J_R(·, γ) has the PL-property... c(α, γ) := λ(Y*_L)/(2γ κ(α,γ)²)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A new approach to linear filtering and prediction problems,
R. E. Kalman, “A new approach to linear filtering and prediction problems,”ASME. Journal of Basic Engineering, vol. 82, pp. 35–45, 03 1960
work page 1960
-
[2]
On the identification of variances and adaptive Kalman filtering,
R. Mehra, “On the identification of variances and adaptive Kalman filtering,”IEEE Transactions on Automatic Control, vol. 15, no. 2, pp. 175–184, 1970
work page 1970
-
[3]
Approaches to adaptive filtering,
R. Mehra, “Approaches to adaptive filtering,”IEEE Transactions on Automatic Control, vol. 17, no. 5, pp. 693–698, 1972
work page 1972
-
[4]
Identification of optimum filter steady-state gain for systems with unknown noise covariances,
B. Carew and P. Belanger, “Identification of optimum filter steady-state gain for systems with unknown noise covariances,”IEEE Transactions on Automatic Control, vol. 18, no. 6, pp. 582–587, 1973
work page 1973
-
[5]
Estimation of noise covariance matrices for a linear time-varying stochastic process,
P. R. Belanger, “Estimation of noise covariance matrices for a linear time-varying stochastic process,”Automatica, vol. 10, no. 3, pp. 267– 275, 1974
work page 1974
-
[6]
Adaptive sequential estimation with unknown noise statistics,
K. Myers and B. Tapley, “Adaptive sequential estimation with unknown noise statistics,”IEEE Transactions on Automatic Control, vol. 21, no. 4, pp. 520–523, 1976
work page 1976
-
[7]
Estimation of steady-state Kalman filter gain,
K. Tajima, “Estimation of steady-state Kalman filter gain,”IEEE Trans- actions on Automatic Control, vol. 23, no. 5, pp. 944–945, 1978
work page 1978
-
[8]
L. Zhang, D. Sidoti, A. Bienkowski, K. R. Pattipati, Y . Bar-Shalom, and D. L. Kleinman, “On the identification of noise covariances and adaptive Kalman filtering: A new look at a 50 year-old problem,”IEEE Access, vol. 8, pp. 59362–59388, 2020
work page 2020
-
[9]
Optimal adaptive estimation of sampled stochastic pro- cesses,
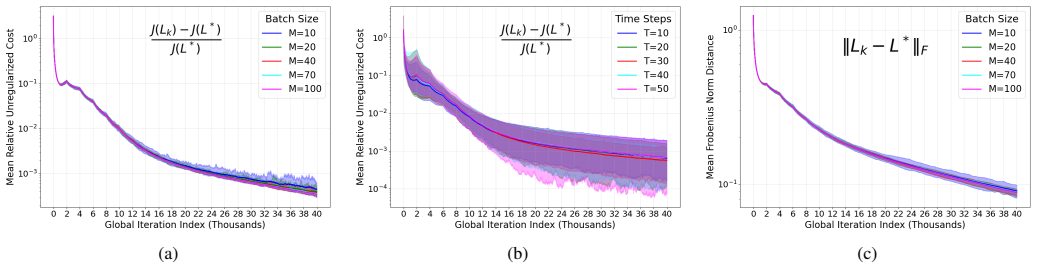
D. Magill, “Optimal adaptive estimation of sampled stochastic pro- cesses,”IEEE Transactions on Automatic Control, vol. 10, no. 4, pp. 434–439, 1965. (a) (b) (c) Fig. 1:Performance of our Riemanian-Regularized Kalman Policy Optimization (Algorithm 1) with the data-driven oracle and without knowledge of thesingularcovariances. Vertical lines represent a ne...
work page 1965
-
[10]
Optimal estimation in the presence of unknown parameters,
C. G. Hilborn and D. G. Lainiotis, “Optimal estimation in the presence of unknown parameters,”IEEE Transactions on Systems Science and Cybernetics, vol. 5, no. 1, pp. 38–43, 1969
work page 1969
-
[11]
Noise covariances estimation for Kalman filter tuning,
P. Matisko and V . Havlena, “Noise covariances estimation for Kalman filter tuning,”IFAC Proceedings Volumes, vol. 43, no. 10, pp. 31–36, 2010
work page 2010
-
[12]
Maximum likelihood identification of stochastic linear systems,
R. Kashyap, “Maximum likelihood identification of stochastic linear systems,”IEEE Transactions on Automatic Control, vol. 15, no. 1, pp. 25–34, 1970
work page 1970
-
[13]
An approach to time series smoothing and forecasting using the EM algorithm,
R. H. Shumway and D. S. Stoffer, “An approach to time series smoothing and forecasting using the EM algorithm,”Journal of Time Series Analysis, vol. 3, no. 4, pp. 253–264, 1982
work page 1982
-
[14]
A new autocovari- ance least-squares method for estimating noise covariances,
B. J. Odelson, M. R. Rajamani, and J. B. Rawlings, “A new autocovari- ance least-squares method for estimating noise covariances,”Automatica, vol. 42, no. 2, pp. 303–308, 2006
work page 2006
-
[15]
A generalized autocovariance least-squares method for Kalman filter tuning,
B. M. ˚Akesson, J. B. Jørgensen, N. K. Poulsen, and S. B. Jørgensen, “A generalized autocovariance least-squares method for Kalman filter tuning,”Journal of Process Control, vol. 18, no. 7-8, pp. 769–779, 2008
work page 2008
-
[16]
Methods for estimating state and measurement noise covariance matrices: Aspects and comparison,
J. Dun ´ık, M. ˆSimandl, and O. Straka, “Methods for estimating state and measurement noise covariance matrices: Aspects and comparison,”IFAC Proceedings Volumes, vol. 42, no. 10, pp. 372–377, 2009
work page 2009
-
[17]
On the general theory of control systems,
R. E. Kalman, “On the general theory of control systems,” inPro- ceedings First International Conference on Automatic Control, Moscow, USSR, pp. 481–492, 1960
work page 1960
-
[18]
On the duality between estimation and control,
J. Pearson, “On the duality between estimation and control,”SIAM Journal on Control, vol. 4, no. 4, pp. 594–600, 1966
work page 1966
-
[19]
LQR through the lens of first order methods: Discrete-time case,
J. Bu, A. Mesbahi, M. Fazel, and M. Mesbahi, “LQR through the lens of first order methods: Discrete-time case,”arXiv preprint arXiv:1907.08921, 2019
-
[20]
Policy Gradient-based Algorithms for Continuous-time Linear Quadratic Control,
J. Bu, A. Mesbahi, and M. Mesbahi, “Policy gradient-based algo- rithms for continuous-time linear quadratic control,”arXiv preprint arXiv:2006.09178, 2020
-
[21]
Global convergence of policy gradient methods for the linear quadratic regulator,
M. Fazel, R. Ge, S. Kakade, and M. Mesbahi, “Global convergence of policy gradient methods for the linear quadratic regulator,” inProceed- ings of the 35th International Conference on Machine Learning, vol. 80, pp. 1467–1476, PMLR, 2018
work page 2018
-
[22]
Optimizing static linear feedback: Gradient method,
I. Fatkhullin and B. Polyak, “Optimizing static linear feedback: Gradient method,”SIAM Journal on Control and Optimization, vol. 59, no. 5, pp. 3887–3911, 2021
work page 2021
-
[23]
Output-feedback synthesis orbit geometry: Quotient manifolds and lqg direct policy optimization,
S. Kraisler and M. Mesbahi, “Output-feedback synthesis orbit geometry: Quotient manifolds and lqg direct policy optimization,”IEEE Control Systems Letters, vol. 8, pp. 1577–1582, 2024
work page 2024
-
[24]
On the linear convergence of random search for discrete-time LQR,
H. Mohammadi, M. Soltanolkotabi, and M. R. Jovanovic, “On the linear convergence of random search for discrete-time LQR,”IEEE Control Systems Letters, vol. 5, no. 3, pp. 989–994, 2021
work page 2021
-
[25]
Global convergence of policy gra- dient primal-dual methods for risk-constrained LQRs,
F. Zhao, K. You, and T. Bas ¸ar, “Global convergence of policy gra- dient primal-dual methods for risk-constrained LQRs,”arXiv preprint arXiv:2104.04901, 2021
-
[26]
Ergodic-risk criterion for stochastically stabilizing policy optimization,
S. Talebi and N. Li, “Ergodic-risk criterion for stochastically stabilizing policy optimization,”arXiv preprint arXiv:2409.10767, 2024
-
[27]
Analysis of the optimization landscape of linear quadratic gaussian (LQG) control,
Y . Tang, Y . Zheng, and N. Li, “Analysis of the optimization landscape of linear quadratic gaussian (LQG) control,” inProceedings of the 3rd Conference on Learning for Dynamics and Control, vol. 144, pp. 599– 610, PMLR, June 2021
work page 2021
-
[28]
Policy optimization over submanifolds for constrained feedback synthesis,
S. Talebi and M. Mesbahi, “Policy optimization over submanifolds for constrained feedback synthesis,”IEEE Transactions on Automatic Control (to appear), arXiv preprint arXiv:2201.11157, 2022
-
[29]
Policy optimization in control: Geometry and algorithmic implications
S. Talebi, Y . Zheng, S. Kraisler, N. Li, and M. Mesbahi, “Policy optimization in control: Geometry and algorithmic implications,”arXiv preprint arXiv:2406.04243, 2024
-
[30]
Duality-based stochastic policy optimization for estimation with unknown noise covariances,
S. Talebi, A. Taghvaei, and M. Mesbahi, “Duality-based stochastic policy optimization for estimation with unknown noise covariances,”arXiv preprint arXiv:2210.14878, 2022
-
[31]
Data-driven optimal filtering for linear systems with unknown noise covariances,
S. Talebi, A. Taghvaei, and M. Mesbahi, “Data-driven optimal filtering for linear systems with unknown noise covariances,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 36, pp. 69546– 69585, Curran Associates, Inc., 2023
work page 2023
-
[32]
Interpretable gradient descent for kalman gain,
M. A. Belabbas and A. Olshevsky, “Interpretable gradient descent for kalman gain,”arXiv preprint arXiv:2507.14354, 2025
-
[33]
A comparison of guaranteeing and kalman filters,
M. V . Khlebnikov, “A comparison of guaranteeing and kalman filters,” Automation and Remote Control, vol. 84, pp. 389–411, 2023
work page 2023
-
[34]
Riemannian Constrained Policy Optimiza- tion via Geometric Stability Certificates,
S. Talebi and M. Mesbahi, “Riemannian Constrained Policy Optimiza- tion via Geometric Stability Certificates,” in2022 IEEE 61st Conference on Decision and Control (CDC), pp. 1472–1478, 2022
work page 2022
-
[35]
H. Kwakernaak and R. Sivan,Linear Optimal Control Systems, vol. 1072. Wiley-interscience, 1969
work page 1969
-
[36]
Optimal minimal-order observer-estimators for discrete linear time-varying systems,
E. Tse and M. Athans, “Optimal minimal-order observer-estimators for discrete linear time-varying systems,”IEEE Transactions on Automatic Control, vol. 15, no. 4, pp. 416–426, 1970
work page 1970
-
[37]
Lewis,Optimal Estimation with an Introduction to Stochastic Control Theory
F. Lewis,Optimal Estimation with an Introduction to Stochastic Control Theory. New York, Wiley-Interscience, 1986
work page 1986
-
[38]
Z. Gajic and M. T. J. Qureshi,Lyapunov Matrix Equation in System Stability and Control. Courier Corporation, 2008
work page 2008
-
[39]
Riemannian-regularized-policy-optimization,
S. Talebi and L. Bier, “Riemannian-regularized-policy-optimization,” Mar. 2026. Available on GitHub at https://github.com/shahriarta/ Riemannian-regularized-policy-optimization
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.