Recognition: 2 theorem links
· Lean TheoremEdit, But Verify: An Empirical Audit of Instructed Code-Editing Benchmarks
Pith reviewed 2026-05-10 19:10 UTC · model grok-4.3
The pith
The two benchmarks for LLM instructed code editing evaluate a narrower set of tasks than real-world use requires.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
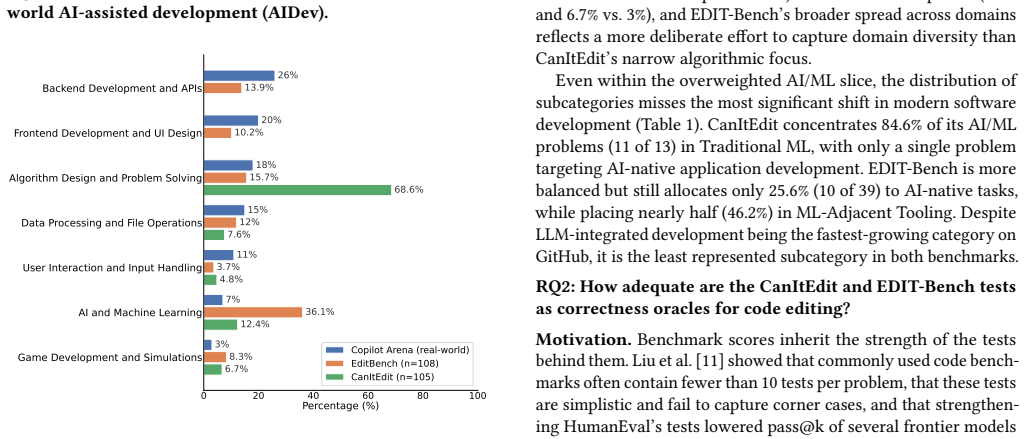
Both benchmarks measure a narrower construct than deployment decisions require, with over 90% Python focus, missing domains, zero representation of documentation/testing/maintenance edits, and test coverage problems that fail to detect many modifications.
What carries the argument
An empirical audit that maps benchmark languages, edit intents, application domains, test counts, statement coverage, and shared codebases against distributions observed in Copilot Arena, AIDev, and GitHub Octoverse data.
If this is right
- Current LLM rankings on CanItEdit and EDIT-Bench do not reflect performance across the full range of real editing tasks.
- New benchmarks must include non-Python languages and the 31 percent of edits that involve documentation, testing, or maintenance.
- Test suites need enough coverage to catch modifications outside the instructed edit region.
- Fifteen EDIT-Bench problems that no model solves trace to benchmark artifacts, so fixing those artifacts would change measured capabilities.
- Shared codebases across 29 percent of EDIT-Bench problems risk data leakage between evaluation items.
Where Pith is reading between the lines
- Teams selecting models for production code assistants may choose systems that perform well on the narrow benchmarks but underperform on common real tasks.
- The public release of the audit artifacts makes it possible to construct replacement benchmarks that match observed distributions without starting from scratch.
- Model training pipelines could be adjusted to emphasize underrepresented edit types once better evaluation targets exist.
Load-bearing premise
The real-world distributions drawn from Copilot Arena, AIDev, and GitHub Octoverse accurately represent the full population of instructed code-editing activity across languages, intents, and domains.
What would settle it
A new large-scale log of coding-assistant interactions that shows substantially higher shares of TypeScript, frontend, or maintenance edits than the three sources used here would indicate the audit's mismatch findings do not generalize.
Figures






read the original abstract
Instructed code editing, where an LLM modifies existing code based on a natural language instruction, accounts for roughly 19% of real-world coding assistant interactions. Yet very few benchmarks directly evaluate this capability. From a survey of over 150 code-related benchmarks, we find that only two, CanItEdit and EDIT-Bench, target instructed code editing with human-authored instructions and test-based evaluation. We audit both by comparing their programming languages, edit intents, and application domains against distributions observed in the wild (Copilot Arena, AIDev, GitHub Octoverse), and by measuring test counts, statement coverage, and test scope across all 213 problems. Both benchmarks concentrate over 90\% of evaluation on Python while TypeScript, GitHub's most-used language, is absent. Backend and frontend development, which together constitute 46% of real-world editing activity, are largely missing, and documentation, testing, and maintenance edits (31.4% of human PRs) have zero representation. Both benchmarks have modest test counts (CanItEdit median 13, EDIT-Bench median 4), though CanItEdit compensates with near-complete whole-file coverage and fail-before/pass-after validation. 59\% of EDIT-Bench's low-coverage suites would not detect modifications outside the edit region. EDIT-Bench has 15 problems that are not solved by any of 40 LLMs and 11 of these problems trace failures to poor benchmark artifacts rather than model limitations. Further, 29% of EDIT-Bench problems and 6% of CanItEdit problems share a codebase with at least one other problem within the benchmark. In summary, these benchmarks measure a narrower construct than deployment decisions require. We therefore propose six empirically grounded desiderata and release all audit artifacts so the community can build instructed code-editing benchmarks whose scores reliably reflect real-world editing capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys over 150 code-related benchmarks to identify only CanItEdit and EDIT-Bench as targeting instructed code editing with human-authored instructions and test-based evaluation. It audits both against real-world distributions from Copilot Arena, AIDev, and GitHub Octoverse for languages (over 90% Python, absent TypeScript), edit intents (zero documentation/testing/maintenance), and domains (missing backend/frontend), while measuring test counts (medians 13 and 4), coverage, and solvability across 213 problems, finding 59% low-coverage suites in EDIT-Bench, 15 unsolvable problems (11 due to artifacts), and some shared codebases, concluding the benchmarks measure a narrower construct than deployment requires and proposing six desiderata.
Significance. If the real-world distributions and survey classifications hold, the work supplies concrete, actionable evidence of gaps between existing benchmarks and observed usage patterns, directly supporting better benchmark construction in LLM-assisted code editing. The release of all audit artifacts is a clear strength that enables reproducibility and extension by others.
major comments (3)
- [Survey of benchmarks (abstract and methods)] The survey of over 150 benchmarks and the claim that only two target instructed code editing rest on unstated inclusion criteria, search strategy, and categorization rules for edit intents and domains; without these, it is impossible to assess whether the identification of CanItEdit and EDIT-Bench is exhaustive or reproducible.
- [Real-world data sources and comparisons] The central claim that both benchmarks measure a narrower construct depends on the reported mismatches (90%+ Python, absent TypeScript, 46% missing backend/frontend, zero doc/test/maintenance edits) being valid; however, the manuscript gives insufficient detail on sampling, filtering for instructed edits, and validation of the categorization schema when deriving distributions from Copilot Arena, AIDev, and GitHub Octoverse.
- [EDIT-Bench solvability analysis] The finding that 11 of the 15 unsolvable EDIT-Bench problems trace to poor benchmark artifacts rather than model limitations is load-bearing for the audit's critique, yet the diagnostic process, failure traces, and evidence for attributing failures to artifacts are not specified.
minor comments (2)
- [Abstract] The abstract reports concrete percentages (e.g., 59% low-coverage suites, 29% shared codebases) without cross-references to the supporting tables or figures, reducing traceability.
- [Evaluation metrics] Notation for percentages and medians is clear, but the exact definition of 'low-coverage suites' and 'fail-before/pass-after validation' would benefit from an explicit glossary or early definition.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each of the major comments below, and we will incorporate clarifications and additional details into the revised manuscript to improve reproducibility and transparency.
read point-by-point responses
-
Referee: [Survey of benchmarks (abstract and methods)] The survey of over 150 benchmarks and the claim that only two target instructed code editing rest on unstated inclusion criteria, search strategy, and categorization rules for edit intents and domains; without these, it is impossible to assess whether the identification of CanItEdit and EDIT-Bench is exhaustive or reproducible.
Authors: We agree that the current manuscript does not provide sufficient detail on the survey methodology. In the revised version, we will expand the Methods section to include a full description of the search strategy (e.g., keywords, databases, and time period), explicit inclusion and exclusion criteria for benchmarks, and the detailed categorization rules and examples for edit intents and application domains. This will enable independent verification of our identification of CanItEdit and EDIT-Bench as the only two benchmarks meeting the criteria. revision: yes
-
Referee: [Real-world data sources and comparisons] The central claim that both benchmarks measure a narrower construct depends on the reported mismatches (90%+ Python, absent TypeScript, 46% missing backend/frontend, zero doc/test/maintenance edits) being valid; however, the manuscript gives insufficient detail on sampling, filtering for instructed edits, and validation of the categorization schema when deriving distributions from Copilot Arena, AIDev, and GitHub Octoverse.
Authors: We acknowledge that additional details are needed to substantiate the real-world distributions. We will revise the manuscript to provide more information on the sampling and filtering procedures applied to the Copilot Arena, AIDev, and GitHub Octoverse datasets, including how we isolated instructed code edits. We will also describe the validation of our categorization schema, such as any inter-annotator agreement metrics or example annotations, to support the reported statistics on languages, domains, and edit intents. revision: yes
-
Referee: [EDIT-Bench solvability analysis] The finding that 11 of the 15 unsolvable EDIT-Bench problems trace to poor benchmark artifacts rather than model limitations is load-bearing for the audit's critique, yet the diagnostic process, failure traces, and evidence for attributing failures to artifacts are not specified.
Authors: We recognize the importance of detailing the diagnostic process for the solvability analysis. In the revision, we will add a new subsection (or appendix) that describes the step-by-step diagnostic procedure used to analyze the 15 unsolvable problems. This will include the specific failure traces reviewed, the criteria for determining that failures were due to benchmark artifacts (such as incorrect or incomplete test suites, missing context, or erroneous problem specifications), and concrete examples for each of the 11 problems attributed to artifacts. We will also clarify how this was distinguished from model limitations. revision: yes
Circularity Check
Empirical audit with no self-referential derivations or predictions
full rationale
The paper conducts a direct empirical comparison of two benchmarks (CanItEdit, EDIT-Bench) against external usage distributions drawn from Copilot Arena, AIDev, and GitHub Octoverse, plus manual inspection of test coverage and problem overlap. No equations, fitted parameters, or predictions appear; the central claim that the benchmarks measure a narrower construct follows from counting languages, intents, domains, and coverage metrics against the cited external logs. These sources are independent of the paper's own definitions or outputs, and no self-citation chain or ansatz is invoked to justify the audit methodology. The analysis is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Distributions observed in Copilot Arena, AIDev, and GitHub Octoverse reflect the true population of instructed code-editing activity.
- domain assumption The survey of over 150 code-related benchmarks correctly identified only two that target instructed editing with human instructions and test-based evaluation.
Reference graph
Works this paper leans on
-
[1]
Toufique Ahmed, Premkumar Devanbu, Christoph Treude, and Michael Pradel
-
[2]
In2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR)
Can LLMs replace manual annotation of software engineering artifacts?. In2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR). IEEE, 526–538
-
[3]
Binghan Cao, Simin Meng, Linhao Gao, Jingkai Li, Jiashun Qi, and Tao Xie
-
[4]
InProceedings of the IEEE/ACM International Conference on Software Engineering (ICSE)
HOW2BENCH: A Systematized Framework for Assessing Code-Related Benchmarks for LLMs. InProceedings of the IEEE/ACM International Conference on Software Engineering (ICSE). https://arxiv.org/abs/2501.10711
-
[5]
Federico Cassano, Luisa Li, Akul Sethi, Noah Shinn, Abby Brennan-Jones, Anton Lozhkov, Carolyn Jane Anderson, and Arjun Guha. 2024. Can It Edit? Evaluating the Ability of Large Language Models to Follow Code Editing Instructions. In Proceedings of the Conference on Language Modeling (COLM). https://arxiv.org/ abs/2312.12450
-
[6]
Wayne Chi, Valerie Chen, Anastasios Nikolas Angelopoulos, Wei-Lin Chiang, Aditya Mittal, Naman Jain, Tianjun Zhang, Ion Stoica, Chris Donahue, and Ameet Talwalkar. 2025. Copilot Arena: A Platform for Code LLM Evaluation in the Wild. InProceedings of the 42nd International Conference on Machine Learning (ICML). https://arxiv.org/abs/2502.09328
-
[7]
Wayne Chi, Valerie Chen, Ryan Shar, Aditya Mittal, Jenny Liang, Wei-Lin Chiang, Anastasios Nikolas Angelopoulos, Ion Stoica, Graham Neubig, Ameet Talwalkar, and Chris Donahue. 2025. EDIT-Bench: Evaluating LLM Abilities to Perform Real- World Instructed Code Edits. InProceedings of the 42nd International Conference on Machine Learning (ICML). https://arxiv...
-
[8]
GitHub Staff. 2025. Octoverse: A New Developer Joins GitHub Every Second as AI Leads TypeScript to #1. https://github.blog/news-insights/octoverse/octoverse-a- new-developer-joins-github-every-second-as-ai-leads-typescript-to-1/. GitHub Blog, updated February 28, 2026. Accessed April 3, 2026
2025
-
[9]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. 2022. UniXcoder: Unified Cross-Modal Pre-training for Code Representation. InPro- ceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL). 7212–7225. doi:10.18653/v1/2022.acl-long.499
-
[10]
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi Li, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, and Jie Fu. 2025. CodeEditorBench: Evaluating Code Editing Capability of LLMs. InThe 3rd DL4C Workshop: Emergent Possibilities and Challenges in Deep Learning for Code, at ICLR 2025. ...
2025
-
[11]
LangChain. 2025. State of AI Agents. https://www.langchain.com/stateofaiagents. Survey of 1,340 respondents; 57.3% report agents in production. Accessed: 2026- 03-30
2025
- [12]
-
[13]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Lan- guage Models for Code Generation. InAdvances in Neural Information Processing Systems 36 (NeurIPS). https://openreview.net/forum?id=1qvx610Cu7
2023
-
[14]
Xinwei Liu, Zhongxin Liu, Zhenlei Ye, Xin Xia, and David Lo. 2025. Evaluating the Test Adequacy of Benchmarks for LLMs on Code Generation.Journal of Software: Evolution and Process37, 4 (2025), e70034. doi:10.1002/smr.70034
-
[15]
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy- Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. 2024. Starcoder 2 and the stack v2: The next generation.arXiv preprint arXiv:2402.19173(2024)
work page internal anchor Pith review arXiv 2024
- [16]
-
[17]
Oliva, Gopi Krishnan Rajbahadur, Aaditya Bhatia, Haoxiang Zhang, Yihao Chen, Zhilong Chen, Arthur Leung, Dayi Lin, Boyuan Chen, and Ahmed E
Gustavo A. Oliva, Gopi Krishnan Rajbahadur, Aaditya Bhatia, Haoxiang Zhang, Yihao Chen, Zhilong Chen, Arthur Leung, Dayi Lin, Boyuan Chen, and Ahmed E. Hassan. 2026. SPICE: An Automated SWE-Bench Labeling Pipeline for Issue Clarity, Test Coverage, and Effort Estimation. IEEE, IEEE Press
2026
-
[18]
Agnia Sergeyuk, Yaroslav Golubev, Timofey Bryksin, and Iftekhar Ahmed. 2025. Using AI-Based Coding Assistants in Practice: State of Affairs, Perceptions, and Ways Forward.Information and Software Technology(2025). doi:10.1016/j.infsof. 2024.107610
-
[19]
Lukas Twist, Jie M Zhang, Mark Harman, Don Syme, Joost Noppen, and Detlef Nauck. 2025. LLMs Love Python: A Study of LLMs’ Bias for Programming Languages and Libraries.arXiv e-prints(2025), arXiv–2503
2025
-
[20]
Yuxiang Wei, Federico Cassano, Jiawei Liu, Yifeng Ding, Naman Jain, Zachary Mueller, Harm de Vries, Leandro Von Werra, Arjun Guha, and Lingming Zhang
-
[21]
Selfcodealign: Self-alignment for code generation.Advances in Neural Information Processing Systems37 (2024), 62787–62874
2024
-
[22]
Jian Yang, Xianglong Liu, Weifeng Lv, Ken Deng, Shawn Guo, Lin Jing, Yizhi Li, Shark Liu, Xianzhen Luo, Yuyu Luo, et al. 2025. From Code Foundation Models to Agents and Applications: A Comprehensive Survey and Practical Guide to Code Intelligence.arXiv preprint arXiv:2511.18538(2025). https://arxiv.org/abs/ 2511.18538
-
[23]
Zuoning Yin, Ding Yuan, Yuanyuan Zhou, Shankar Pasupathy, and Lakshmi Bairavasundaram. 2011. How Do Fixes Become Bugs?. InProceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering (ESEC/FSE). ACM, 26–36. doi:10.1145/2025113.2025121
-
[24]
feat” = adding new functionality that did not exist before. - “fix
Zekai Zhang, Mingwei Liu, Zhenxi Chen, Linxi Liang, Yuxuan Chen, Guangsheng Ou, Yanlin Wang, Dan Li, Xin Peng, and Zibin Zheng. 2025. Generating High- Quality Datasets for Code Editing via Open-Source Language Models.arXiv preprint arXiv:2509.25203(2025). 8 Edit, But Verify: An Empirical Audit of Instructed Code-Editing Benchmarks , , Prompt 1: Edit-Inten...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.