Recognition: 2 theorem links
· Lean TheoremWhat Makes a Good Response? An Empirical Analysis of Quality in Qualitative Interviews
Pith reviewed 2026-05-10 19:02 UTC · model grok-4.3
The pith
Direct relevance to a key research question is the strongest predictor of response quality in qualitative interviews.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By constructing the Qualitative Interview Corpus and having responses annotated for their contribution to study findings, the authors demonstrate that among ten candidate quality measures, only direct relevance to a key research question reliably predicts high contribution scores. Measures of clarity and surprisal-based informativeness, which are commonly applied to NLP-generated interviews, show no significant correlation with actual contribution.
What carries the argument
The Qualitative Interview Corpus of 343 transcripts containing 16,940 responses, together with human annotations of each response's contribution to the study's goals, used to correlate against ten proposed quality metrics.
Load-bearing premise
That trained annotators can consistently and objectively determine how much an individual response contributes to the overall study findings.
What would settle it
Re-annotating a subset of the responses using a different set of criteria for contribution or different annotators and finding that relevance no longer ranks as the top predictor would undermine the central result.
Figures













read the original abstract
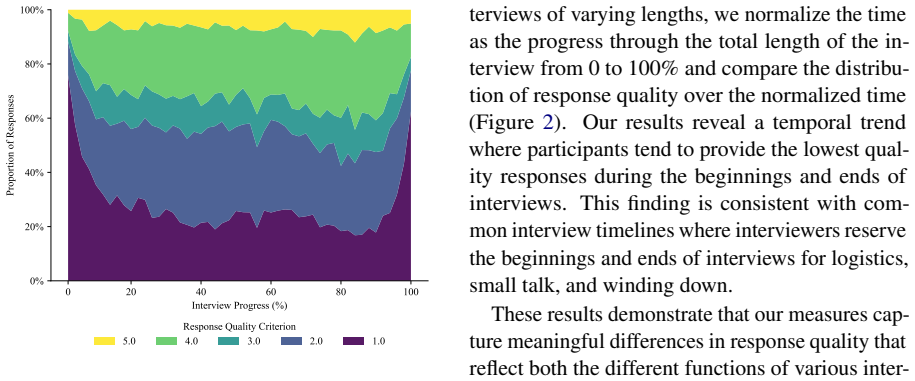
Qualitative interviews provide essential insights into human experiences when they elicit high-quality responses. While qualitative and NLP researchers have proposed various measures of interview quality, these measures lack validation that high-scoring responses actually contribute to the study's goals. In this work, we identify, implement, and evaluate 10 proposed measures of interview response quality to determine which are actually predictive of a response's contribution to the study findings. To conduct our analysis, we introduce the Qualitative Interview Corpus, a newly constructed dataset of 343 interview transcripts with 16,940 participant responses from 14 real research projects. We find that direct relevance to a key research question is the strongest predictor of response quality. We additionally find that two measures commonly used to evaluate NLP interview systems, clarity and surprisal-based informativeness, are not predictive of response quality. Our work provides analytic insights and grounded, scalable metrics to inform the design of qualitative studies and the evaluation of automated interview systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Qualitative Interview Corpus (343 transcripts, 16,940 responses from 14 real projects) and evaluates 10 proposed measures of response quality to identify which predict a response's contribution to study findings. It reports that direct relevance to a key research question is the strongest predictor, while clarity and surprisal-based informativeness are not predictive of quality.
Significance. If the central results hold after addressing the annotation and analysis details, the work supplies the first large-scale empirical validation of quality measures for qualitative interviews. This could shift evaluation practices in both qualitative research and NLP interview systems away from unvalidated proxies toward relevance-focused metrics, with direct implications for study design and automated system assessment.
major comments (3)
- [Corpus construction and annotation (likely §3)] The annotation protocol for the dependent variable ('contribution to the study findings') is not described: no coding rubric, number of annotators per response, disagreement resolution procedure, or inter-rater reliability statistics (Cohen’s κ or Krippendorff’s α) are reported. Because every correlation and ranking among the 10 measures rests on these human judgments as ground truth, the absence of this information renders the headline claims (relevance as strongest predictor; clarity and surprisal as non-predictive) impossible to evaluate for reliability or bias.
- [Results and statistical analysis (likely §5)] No information is supplied on the statistical tests, effect sizes, sample sizes per measure, or controls for confounds (question type, interviewer experience, project domain). Without these, it is unclear whether the reported superiority of relevance over the other nine measures survives multiple-comparison correction or is an artifact of unmodeled dependencies in the 16,940 responses.
- [Measure definitions and implementation (likely §4)] The operational definitions and implementation details for the ten measures themselves are insufficiently specified to permit replication or to diagnose why clarity and surprisal-based informativeness fail to correlate with contribution scores.
minor comments (2)
- [Abstract] The abstract would benefit from a single sentence stating the number of annotators and the reliability metric used for the contribution scores.
- [Tables and figures] Table or figure captions should explicitly note the exact statistical test and any covariates included when ranking the ten measures.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important gaps in reporting that affect the reproducibility and interpretability of our results. We address each point below and will revise the manuscript accordingly to strengthen the paper.
read point-by-point responses
-
Referee: [Corpus construction and annotation (likely §3)] The annotation protocol for the dependent variable ('contribution to the study findings') is not described: no coding rubric, number of annotators per response, disagreement resolution procedure, or inter-rater reliability statistics (Cohen’s κ or Krippendorff’s α) are reported. Because every correlation and ranking among the 10 measures rests on these human judgments as ground truth, the absence of this information renders the headline claims (relevance as strongest predictor; clarity and surprisal as non-predictive) impossible to evaluate for reliability or bias.
Authors: We agree that these annotation details are critical for assessing the validity of the ground-truth labels and were omitted from the submitted manuscript. In the revision, we will add a dedicated subsection describing the full annotation protocol: the coding rubric provided to annotators, the number of annotators per response, the disagreement resolution procedure, and the inter-rater reliability statistics. This will enable readers to evaluate potential biases or limitations in the dependent variable. revision: yes
-
Referee: [Results and statistical analysis (likely §5)] No information is supplied on the statistical tests, effect sizes, sample sizes per measure, or controls for confounds (question type, interviewer experience, project domain). Without these, it is unclear whether the reported superiority of relevance over the other nine measures survives multiple-comparison correction or is an artifact of unmodeled dependencies in the 16,940 responses.
Authors: We acknowledge that the statistical reporting was insufficient. The revised results section will specify the exact statistical tests performed, effect sizes, sample sizes used for each measure, and any controls or covariates included for confounds such as question type, interviewer experience, and project domain. We will also report whether the key findings hold after appropriate multiple-comparison corrections and discuss potential dependencies in the data. revision: yes
-
Referee: [Measure definitions and implementation (likely §4)] The operational definitions and implementation details for the ten measures themselves are insufficiently specified to permit replication or to diagnose why clarity and surprisal-based informativeness fail to correlate with contribution scores.
Authors: We agree that greater specificity is needed for replication. The revised manuscript will expand the measure definitions section with precise operational details, including formulas or pseudocode where applicable, preprocessing steps, and the exact tools or libraries used for implementation. This will also help clarify why certain measures (such as clarity and surprisal-based informativeness) did not predict contribution scores. revision: yes
Circularity Check
No significant circularity in empirical evaluation
full rationale
The paper performs an empirical analysis by constructing a new corpus of 16,940 responses from 14 projects and correlating 10 implemented measures against human-annotated contribution scores. No equations, parameter-fitting steps, or derivations are present that would reduce any reported predictor (such as direct relevance) to a quantity computed from the same contribution labels by construction. The measures are drawn from prior literature and applied independently to the text, while the annotations serve as an external ground truth; the comparison therefore remains self-contained and does not collapse into its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotators can consistently judge whether an individual response contributes to a study's overall findings
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe identify, implement, and evaluate 10 proposed measures of interview response quality... direct relevance to a key research question is the strongest predictor
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearlinear mixed-effects model... marginal R² of 0.506
Reference graph
Works this paper leans on
-
[1]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
SparkMe: Adaptive Semi-Structured Inter- viewing for Qualitative Insight Discovery. Alemitu Mequanint Bezabih and C. Estelle Smith. 2025. Expanding Models of Delivery for Online Spiritual Care. Kathy Charmaz. 2014.Constructing Grounded Theory. SAGE Publications Ltd, London ; Thousand Oaks, Calif. Deepro Choudhury, Sinead Williamson, Adam Goli´nski, Ning M...
work page internal anchor Pith review arXiv 2025
-
[2]
State Contexts during the COVID-19 Pandemic
Data for: What Extraordinary Times Tell Us about Ordinary Ones: A Multiple Case Study of Pre- cariously Employed Food Retail and Service Work- ers in Two U.S. State Contexts during the COVID-19 Pandemic. Ziang Xiao, Michelle X. Zhou, Wenxi Chen, Huahai Yang, and Changyan Chi. 2020a. If I Hear You Cor- rectly: Building and Evaluating Interview Chatbots 10 ...
2020
-
[3]
The participant statement does not provide information indicating how significant an action or experience is to the participant
-
[4]
The participant statement indicates some level of significance of an action or experience to a participant but does not provide information about what that significance is
-
[5]
The participant statement directly shows the significance of an action or experience to the participant and explains what that significance is. CONTEXT BLURB (context only): {context_blurb} PREVIOUS INTERVIEW EXCERPT (context_only): {previous} CURRENT INTERVIEW EXCERPT (rate this): {excerpt} CRITICAL: Output only a single digit (1, 2, or 3). Do not write ...
-
[6]
The participant statement is incoherent, or the meaning is completely unclear
-
[7]
The participant statement is ambiguous or requires guessing to understand
-
[8]
The participant statement is clear to read and understand. CONTEXT BLURB (context only): {context_blurb} PREVIOUS INTERVIEW EXCERPT (context_only): {previous} CURRENT INTERVIEW EXCERPT (rate this): {excerpt} CRITICAL: Output only a single digit (1, 2, or 3). Do not write any additional text. Figure 4: LLM Judge prompt used to evaluate the clarity of parti...
-
[9]
The participant statement is completely unrelated to the question asked, avoids the question entirely, or addresses a totally different topic
-
[10]
The participant statement is related to the general topic of the question but drifts or answers a different question than the one posed
-
[11]
The participant statement directly answers the specific question posed by the interviewer. CONTEXT BLURB (context only): {context_blurb} PREVIOUS INTERVIEW EXCERPT (context_only): {previous} CURRENT INTERVIEW EXCERPT (rate this): {excerpt} CRITICAL: Output only a single digit (1, 2, or 3). Do not write any additional text. Figure 5: LLM Judge prompt used ...
-
[12]
The participant statement is not interpretable without additional context
-
[13]
The core idea of the participant statement is understandable but may require additional context for full understanding
-
[14]
The participant statement is fully self-contained, not requiring any additional context to be interpretable. CONTEXT BLURB (context only): {context_blurb} PREVIOUS INTERVIEW EXCERPT (context_only): {previous} CURRENT INTERVIEW EXCERPT (rate this): {excerpt} CRITICAL: Output only a single digit (1, 2, or 3). Do not write any additional text. Figure 6: LLM ...
-
[15]
The participant statement is generic or abstract, providing only high-level summaries or vague descriptions
-
[16]
The participant statement describes a particular event, action, or opinion without concrete details or examples
-
[17]
The participant statement describes a particular event, action, or opinion with concrete details or examples. CONTEXT BLURB (context only): {context_blurb} PREVIOUS INTERVIEW EXCERPT (context_only): {previous} CURRENT INTERVIEW EXCERPT (rate this): {excerpt} CRITICAL: Output only a single digit (1, 2, or 3). Do not write any additional text. Figure 7: LLM...
-
[18]
The participant statement only confirms or reiterates information provided in the interviewer’s statement
-
[19]
The participant statement adds additional information beyond what was provided in the interviewer’s statement but remains within the topic posed
-
[20]
The participant statement introduces a new topic that may be related but was not introduced in the interviewer’s statement. CONTEXT BLURB (context only): {context_blurb} PREVIOUS INTERVIEW EXCERPT (context_only): {previous} CURRENT INTERVIEW EXCERPT (rate this): {excerpt} CRITICAL: Output only a single digit (1, 2, or 3). Do not write any additional text....
-
[21]
The participant statement is unrelated to the research question or discusses a completely different topic
-
[22]
The participant statement is tangentially related to the topic of the research question
-
[23]
The participant statement directly addresses the research question. RESEARCH QUESTION: {research_question} CONTEXT BLURB (context only): {context_blurb} PREVIOUS INTERVIEW EXCERPT (context_only): {previous} CURRENT INTERVIEW EXCERPT (rate this): {excerpt} CRITICAL: Output only a single digit (1, 2, or 3). Do not write any additional text. Figure 9: LLM Ju...
-
[24]
The statement is unrelated to the results section or contradicts it
-
[25]
Tangential relation; discusses the topic but offers no specific substance
-
[26]
Aligns with the results section but is general or vague
-
[27]
Provides an example or sentiment that matches the results section’s conclusion
-
[28]
Appears in the results section and likely served as a primary source for it. RESULTS SECTION: {result} CONTEXT BLURB (context only): {context_blurb} PREVIOUS INTERVIEW EXCERPT (context_only): {previous} CURRENT INTERVIEW EXCERPT (rate this): {excerpt} CRITICAL: Output only a single digit (1, 2, 3, 4, or 5). Do not write any additional text. Figure 10: LLM...
-
[29]
Introductory/Contextualization Questions: Open-ended questions that may be unrelated to the overall research questions but are designed to give an understanding of the participant or context
-
[30]
Support and Rapport Building: A statement designed to make a connection with the participant, provide support, or let the participant know that the purpose of the interview is being fulfilled
-
[31]
uh-huh” or “mmm,
Follow-up / Elaboration Probe: A statement designed to encourage a participant to continue talking. It may be a simple “uh-huh” or “mmm,” or it could also be a direct call such as, “Could you say some more about that?”
-
[32]
Specifying / Detail-Oriented Probe: Questions that follow up to ask who, where, what, when, or how to obtain a complete and detailed picture of an activity or experience
-
[33]
Direct Questioning: A question that directly introduces topics or dimensions and asks the respondent about them
-
[34]
Indirect / Projective Questioning: Indirect questions that may ask about the attitudes of others or encourage an indirect statement of the participant’s own motivations, attitudes, or emotions
-
[35]
Structuring: A statement that controls the structure of the interview by transitioning topics, redirecting respondents, or breaking off participant answers that may be irrelevant to the purpose of the interview
-
[36]
Interpreting: A statement that rephrases or interprets answers provided by the participant to get clarification or reach common ground with the participant. CONTEXT BLURB (context only): {context_blurb} PREVIOUS INTERVIEW EXCERPT (context_only): {previous} CURRENT INTERVIEW EXCERPT (rate this): {current_excerpt} CRITICAL: Output only digits (1, 2, 3, 4, 5...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.