Recognition: no theorem link
Not All Turns Are Equally Hard: Adaptive Thinking Budgets For Efficient Multi-Turn Reasoning
Pith reviewed 2026-05-10 19:33 UTC · model grok-4.3
The pith
Turn-adaptive token budgets let LLMs save up to 35% compute in multi-turn reasoning by spending less on easy steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
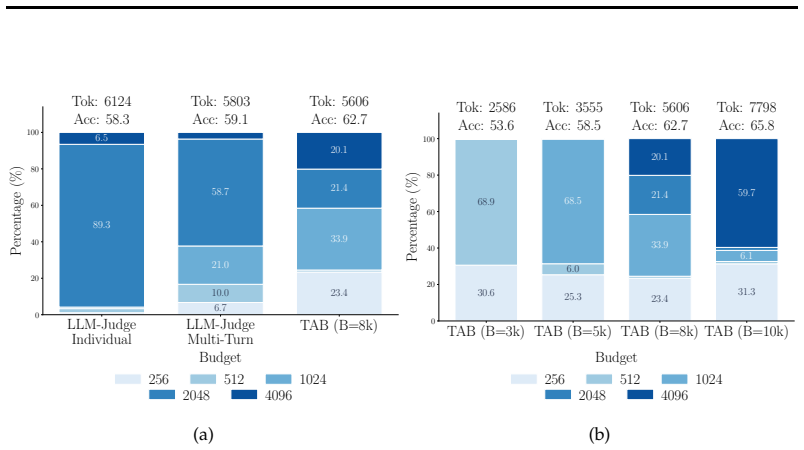
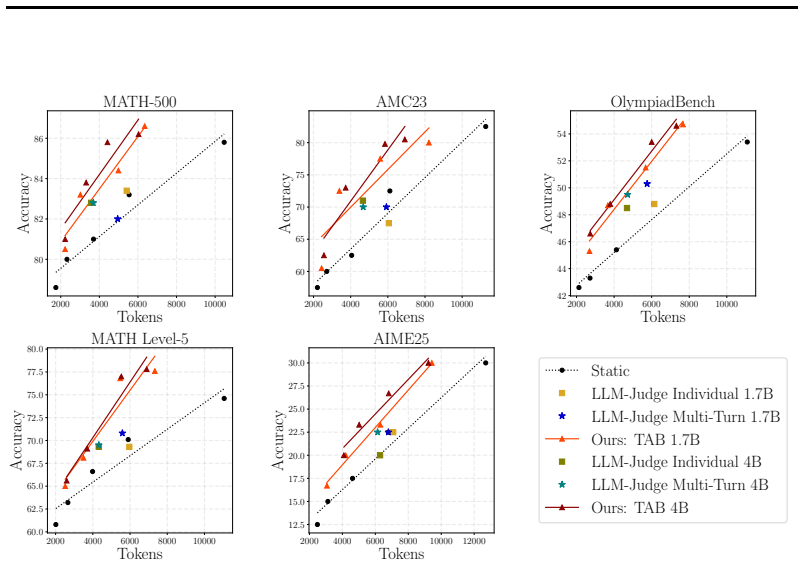
We model multi-turn reasoning as a sequential compute allocation problem using a multi-objective Markov Decision Process. TAB is a budget allocation policy trained with Group Relative Policy Optimization that inputs conversation history and adaptively assigns smaller token budgets to easier turns while preserving tokens for critical harder steps. On mathematical reasoning benchmarks, TAB achieves up to 35% token savings while maintaining accuracy, outperforming static and off-the-shelf LLM budget baselines. When all sub-questions are known in advance, the TAB All-SubQ variant reaches up to 40% savings.
What carries the argument
TAB (Turn-Adaptive Budgets), a GRPO-trained policy that decides per-turn token budgets from conversation history under global token constraints.
If this is right
- TAB improves the accuracy-tokens tradeoff by adapting to turn difficulty rather than using uniform budgets.
- The method respects global per-problem token limits while maximizing accuracy.
- TAB All-SubQ variant provides additional savings when future sub-questions are known ahead of time.
- It outperforms static allocation and standard LLM methods on math benchmarks.
Where Pith is reading between the lines
- The policy's reliance on history suggests it could identify difficulty patterns in other sequential tasks if trained similarly.
- Extending the multi-objective reward to include other costs like latency might further optimize real-world deployments.
- Since savings come from adaptive allocation, the gains may increase with longer, more varied multi-turn interactions.
Load-bearing premise
The GRPO-trained policy developed on math benchmarks generalizes to other multi-turn domains and the reward function balances objectives without needing adjustments that change the savings.
What would settle it
Applying TAB to a multi-turn reasoning benchmark outside of mathematics and observing whether token savings of around 35% are achieved at equivalent accuracy levels.
Figures



read the original abstract
As LLM reasoning performance plateau, improving inference-time compute efficiency is crucial to mitigate overthinking and long thinking traces even for simple queries. Prior approaches including length regularization, adaptive routing, and difficulty-based budget allocation primarily focus on single-turn settings and fail to address the sequential dependencies inherent in multi-turn reasoning. In this work, we formulate multi-turn reasoning as a sequential compute allocation problem and model it as a multi-objective Markov Decision Process. We propose TAB: Turn-Adaptive Budgets, a budget allocation policy trained via Group Relative Policy Optimization (GRPO) that learns to maximize task accuracy while respecting global per-problem token constraints. Consequently, TAB takes as input the conversation history and learns to adaptively allocate smaller budgets to easier turns and save appropriate number of tokens for the crucial harder reasoning steps. Our experiments on mathematical reasoning benchmarks demonstrate that TAB achieves a superior accuracy-tokens tradeoff saving up to 35% tokens while maintaining accuracy over static and off-the-shelf LLM budget baselines. Further, for systems where a plan of all sub-questions is available apriori, we propose TAB All-SubQ, a budget allocation policy that budgets tokens based on the conversation history and all past and future sub-questions saving up to 40% tokens over baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates multi-turn LLM reasoning as a sequential token allocation problem modeled as a multi-objective MDP. It introduces TAB, a policy trained via Group Relative Policy Optimization (GRPO) that takes conversation history as input and adaptively assigns smaller token budgets to easier turns while reserving capacity for harder steps. The central empirical claim is that TAB achieves a superior accuracy-token tradeoff on mathematical reasoning benchmarks, saving up to 35% tokens (40% for the TAB All-SubQ variant when all sub-questions are known a priori) while preserving accuracy relative to static and off-the-shelf LLM budget baselines.
Significance. If the reported tradeoff proves robust, the work would meaningfully advance inference-time efficiency for multi-turn reasoning by explicitly handling sequential dependencies and overthinking, which prior single-turn methods overlook. The MDP formulation and GRPO-based multi-objective training constitute a technically coherent contribution that could inform budget-aware agents in other sequential domains.
major comments (3)
- [Abstract and §3] Abstract and §3 (Method): The multi-objective reward used in GRPO combines accuracy and global token budget, yet the relative weighting between these terms is a free hyperparameter whose values are neither stated nor shown to have been fixed a priori. Without an ablation or sensitivity analysis on these weights, the headline 35% savings are compatible with post-hoc scalarization chosen after inspecting test curves, undermining the claim that the policy itself discovers a superior Pareto front.
- [§4] §4 (Experiments): No information is supplied on the training data distribution, exact baseline implementations, number of runs, or statistical tests for the accuracy-token curves. Because the policy is optimized directly on the evaluation benchmarks, the absence of these controls makes it impossible to distinguish genuine generalization from fitting to the reported test sets.
- [§4 and §5] §4 and §5: The manuscript presents no ablation on reward-weight sensitivity or on the effect of removing the future-sub-question information in TAB All-SubQ. These omissions are load-bearing for the central claim that the learned policy yields a robust accuracy-token improvement independent of experimental choices.
minor comments (2)
- [Abstract] Abstract: 'plateau' should read 'plateaus'; 'apriori' should be 'a priori'.
- [§3] Notation for the MDP components (state, action, reward) is introduced but not consistently referenced in the experimental section, making it hard to map the learned policy back to the formal model.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications where possible and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): The multi-objective reward used in GRPO combines accuracy and global token budget, yet the relative weighting between these terms is a free hyperparameter whose values are neither stated nor shown to have been fixed a priori. Without an ablation or sensitivity analysis on these weights, the headline 35% savings are compatible with post-hoc scalarization chosen after inspecting test curves, undermining the claim that the policy itself discovers a superior Pareto front.
Authors: We acknowledge that the specific weighting λ between the accuracy and token-budget terms was not explicitly stated in the original submission. It was set to λ=0.5 following preliminary validation on a small held-out subset of training problems to achieve a balanced objective, rather than post-hoc selection on test curves. To address the concern rigorously, we will add a sensitivity analysis in the revised manuscript (new subsection in §3 and appendix figure) varying λ across [0.2, 0.8] and showing that the reported accuracy-token improvements remain stable and superior to baselines over this range. This will clarify that the policy learns a robust tradeoff rather than relying on a single tuned scalar. revision: yes
-
Referee: [§4] §4 (Experiments): No information is supplied on the training data distribution, exact baseline implementations, number of runs, or statistical tests for the accuracy-token curves. Because the policy is optimized directly on the evaluation benchmarks, the absence of these controls makes it impossible to distinguish genuine generalization from fitting to the reported test sets.
Authors: We agree these experimental details were insufficiently documented. Training used the official training splits of GSM8K and MATH (disjoint from the reported test sets), with problems drawn from the same mathematical reasoning distribution. Baselines followed the exact prompting and decoding procedures from their original papers (with links to implementations). All curves were averaged over 3 random seeds; we will add standard deviations, error bars, and statistical significance tests (paired Wilcoxon tests) to the plots in revised §4. We will also expand the data-distribution description and baseline details in the appendix to demonstrate that evaluation occurs on held-out problems. revision: yes
-
Referee: [§4 and §5] §4 and §5: The manuscript presents no ablation on reward-weight sensitivity or on the effect of removing the future-sub-question information in TAB All-SubQ. These omissions are load-bearing for the central claim that the learned policy yields a robust accuracy-token improvement independent of experimental choices.
Authors: We concur that these ablations are necessary to support the robustness claims. In the revision we will add (i) a reward-weight sensitivity study in §4 reporting accuracy and token usage for multiple λ values, and (ii) an ablation of TAB All-SubQ in which future sub-question information is withheld (reducing it to the standard TAB setting) to quantify the incremental benefit of a priori knowledge. These results will be presented in §4 and §5 with accompanying discussion. revision: yes
Circularity Check
No significant circularity in method or empirical claims
full rationale
The paper models multi-turn reasoning as a multi-objective MDP and trains TAB via GRPO to allocate adaptive token budgets based on conversation history. The headline result is an empirical comparison showing up to 35% token savings while preserving accuracy versus static and off-the-shelf baselines on mathematical reasoning benchmarks. No derivation reduces by construction to its inputs: there are no equations equating a fitted quantity to a renamed prediction, no self-definitional loops, and no load-bearing self-citations or uniqueness theorems. The reported tradeoffs arise from policy optimization and evaluation against independent baselines rather than tautological renaming or post-training redefinition of the objective. The approach is self-contained as a standard RL-for-LLM method with external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Multi-objective reward weights
axioms (1)
- domain assumption Conversation history is a sufficient Markov state for predicting next-turn difficulty
Forward citations
Cited by 2 Pith papers
-
On Time, Within Budget: Constraint-Driven Online Resource Allocation for Agentic Workflows
MCPP is a Monte Carlo simulation-based online planner that improves the probability of agentic workflows completing successfully under explicit budget and deadline constraints compared to baselines on CodeFlow and Pro...
-
On Time, Within Budget: Constraint-Driven Online Resource Allocation for Agentic Workflows
MCPP uses Monte Carlo simulations of workflow executions to dynamically allocate resources and replan, raising constrained completion probability over baselines on CodeFlow and ProofFlow.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2510.08439. Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Mooncake: Trading more storage for less computation—a {KVCache-centric} architecture for serving {LLM} chatbot. In23rd USENIX conference on file and storage technologies (FAST 25), pp. 155–170, 2025. Ansh Ra...
-
[2]
The conversation history showing how a solver has worked through previous sub-questions (each turn contains the sub-question and the solver’s answer)
-
[3]
The next sub-question that needs a difficulty assessment Your role is to predict the difficulty level (0-4) of the next sub-question, informed by the problem context and the solver’s progress so far. Consider these factors: - How the solver handled previous sub-questions (errors, complexity of responses) - Whether the next sub-question builds on previous ...
-
[4]
Think carefully about what is being asked
-
[5]
Use any previous answers and context provided
-
[6]
Provide a clear, detailed solution within the token budget
-
[7]
Be precise with calculations and show your reasoning within the given token limit
State your answer clearly at the end When presenting the final answer to the original problem, you MUST format it as boxed{answer} . Be precise with calculations and show your reasoning within the given token limit. Initial User Prompt:I need help solving the following math problem. I will break it down into sub-questions and ask you one at a time. **Main...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.