Recognition: 2 theorem links
· Lean TheoremOn Time, Within Budget: Constraint-Driven Online Resource Allocation for Agentic Workflows
Pith reviewed 2026-05-11 02:11 UTC · model grok-4.3
The pith
Monte Carlo Portfolio Planning raises the probability that agentic workflows complete within given budget and deadline constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
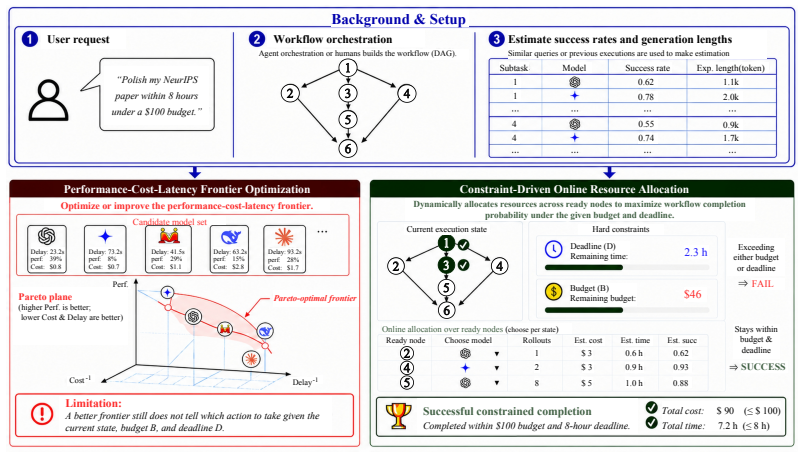
Given estimates of success rates and generation lengths for each subtask-model pair, Monte Carlo Portfolio Planning directly estimates the constrained completion probability through simulated workflow executions and replans allocations for simultaneously executable subtasks after observing outcomes, outperforming baselines in maximizing the probability that the full workflow finishes within budget and before the deadline.
What carries the argument
Monte Carlo Portfolio Planning (MCPP), a lightweight closed-loop planner that estimates constrained completion probability via simulated executions and replans model and sample allocations for subtasks based on observed results.
If this is right
- Resource allocation decisions can be made dynamically to prioritize paths that preserve budget and time for remaining subtasks.
- Parallel sampling can be concentrated on high-uncertainty subtasks that most affect overall completion probability.
- Replanning after each subtask outcome allows recovery from early failures by reallocating remaining resources.
- The approach applies to any dependency-structured workflow where model choices trade off cost, latency, and reliability.
Where Pith is reading between the lines
- Updating success and length estimates from actual run data could allow the planner to improve over time without manual recalibration.
- The simulation-based method might extend to workflows that include human-in-the-loop steps or external tool calls with uncertain durations.
- If model performance varies with input characteristics, adding context-aware estimates could further raise constrained success rates.
- The same planning loop could be tested on workflows from other domains such as data analysis pipelines or multi-step research tasks.
Load-bearing premise
Accurate estimates of success rates and generation lengths for each subtask-model pair are available in advance, and simulated executions sufficiently represent real outcomes under the chosen allocations.
What would settle it
If live executions on CodeFlow or ProofFlow show that the simulated completion probabilities under MCPP allocations do not match actual success rates, or if MCPP fails to improve over baselines when estimates contain realistic noise.
Figures






read the original abstract
Agentic systems increasingly solve complex user requests by executing orchestrated workflows, where subtasks are assigned to specialized models or tools and coordinated according to their dependencies. While recent work improves agent efficiency by optimizing the performance--cost--latency frontier, real deployments often impose concrete requirements: a workflow must be completed within a specified budget and before a specified deadline. This shifts the goal from average efficiency optimization to maximizing the probability that the entire workflow completes successfully under explicit budget and deadline constraints. We study \emph{constraint-driven online resource allocation for agentic workflows}. Given a dependency-structured workflow and estimates of success rates and generation lengths for each subtask--model pair, the executor dynamically allocates models and parallel samples across simultaneously executable subtasks while managing the remaining budget and time. We formulate this setting as a finite-horizon stochastic online allocation problem and propose \emph{Monte Carlo Portfolio Planning} (MCPP), a lightweight closed-loop planner that directly estimates constrained completion probability through simulated workflow executions and replans after observed outcomes. Experiments on CodeFlow and ProofFlow demonstrate that MCPP consistently improves constrained completion probability over strong baselines across a wide range of budget--deadline constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Monte Carlo Portfolio Planning (MCPP) for constraint-driven online resource allocation in agentic workflows. Given a workflow DAG and estimates of per-subtask success rates p and generation lengths l, MCPP formulates the problem as finite-horizon stochastic online allocation, uses Monte Carlo rollouts to estimate the probability of completing the workflow within budget and deadline, and replans dynamically after observed outcomes. Experiments on CodeFlow and ProofFlow are claimed to show that MCPP consistently improves constrained completion probability over strong baselines across a range of budget-deadline pairs.
Significance. If the empirical gains prove robust under noisy estimates and real execution variance, the work would be significant for practical deployment of agentic systems, as it shifts optimization from average efficiency to direct maximization of constrained success probability via lightweight closed-loop planning. The Monte Carlo simulation approach and online replanning are technically sound strengths that avoid parameter fitting.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the central claim of 'consistent improvements' over baselines is only weakly supported because no quantitative details (effect sizes, baseline values, number of trials, variance, or statistical significance) are supplied. This makes it impossible to judge whether the gains are practically meaningful or sensitive to the quality of the supplied p and l estimates.
- [Method / Evaluation] Method and Evaluation sections: the planner takes p and l as given and assumes Monte Carlo rollouts sufficiently represent real outcomes. No robustness analysis is provided for noisy/biased estimates, non-stationary success rates, or divergence between simulated and actual trajectories (e.g., context-dependent failures or latency variance). This assumption is load-bearing for the reported probability improvements.
minor comments (2)
- [Abstract] Abstract: specify the 'strong baselines' by name or citation so readers can immediately assess the comparison.
- Notation: ensure p and l are clearly defined with their estimation procedure or source when first introduced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the revisions we will incorporate to strengthen the empirical presentation and evaluation.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim of 'consistent improvements' over baselines is only weakly supported because no quantitative details (effect sizes, baseline values, number of trials, variance, or statistical significance) are supplied. This makes it impossible to judge whether the gains are practically meaningful or sensitive to the quality of the supplied p and l estimates.
Authors: We agree that the abstract and Experiments section would be strengthened by explicit quantitative details. The current manuscript reports the improvements in qualitative terms based on the CodeFlow and ProofFlow experiments. In the revised version we will update the abstract with representative effect sizes and add a summary table in the Experiments section that reports baseline values, MCPP results, number of trials per setting, standard deviations, and statistical significance tests. This will enable readers to evaluate the magnitude and reliability of the reported gains. revision: yes
-
Referee: [Method / Evaluation] Method and Evaluation sections: the planner takes p and l as given and assumes Monte Carlo rollouts sufficiently represent real outcomes. No robustness analysis is provided for noisy/biased estimates, non-stationary success rates, or divergence between simulated and actual trajectories (e.g., context-dependent failures or latency variance). This assumption is load-bearing for the reported probability improvements.
Authors: We acknowledge that the original submission does not contain a dedicated robustness analysis for noisy or biased p and l estimates, non-stationary success rates, or mismatches between simulated and real trajectories. This is a genuine limitation. In the revised manuscript we will add a new subsection under Evaluation that includes sensitivity experiments with perturbed estimates, tests under non-stationary conditions, and explicit discussion of potential simulation-reality gaps. The online replanning step in MCPP is intended to mitigate some of these issues by adapting after each observed outcome, but we will now quantify that robustness directly. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper takes success rates p and generation lengths l for each subtask-model pair as external given inputs, formulates the problem as finite-horizon stochastic online allocation, and introduces MCPP which performs Monte Carlo rollouts of the workflow DAG to estimate constrained completion probability and replan allocations. Experimental gains on CodeFlow and ProofFlow are measured by applying this planner (and baselines) inside the same simulation loop using those inputs. No step reduces the claimed improvement to a fitted parameter, self-referential definition, or self-citation chain; the planner optimizes within the supplied model rather than deriving its own inputs from outputs. This is self-contained against the simulation benchmark and meets the criteria for a non-circular finding.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate this setting as a finite-horizon stochastic online allocation problem and propose Monte Carlo Portfolio Planning (MCPP), a lightweight closed-loop planner that directly estimates constrained completion probability through simulated workflow executions and replans after observed outcomes.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on CodeFlow and ProofFlow demonstrate that MCPP consistently improves constrained completion probability over strong baselines across a wide range of budget–deadline constraints.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Proofflow: A dependency graph approach to faithful proof autoformalization.arXiv preprint arXiv:2510.15981. Lingjiao Chen, Matei Zaharia, and James Zou. Frugalgpt: How to use large language models while reducing cost and improving performance.Transactions on Machine Learning Research. Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee,...
-
[2]
Neharika Jali, Anupam Nayak, and Gauri Joshi
Latency and token-aware test-time compute.arXiv preprint arXiv:2509.09864. Neharika Jali, Anupam Nayak, and Gauri Joshi
-
[3]
Not All Turns Are Equally Hard: Adaptive Thinking Budgets For Efficient Multi-Turn Reasoning
Not all turns are equally hard: Adaptive thinking budgets for efficient multi-turn reasoning.arXiv preprint arXiv:2604.05164. Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Nalar: An agent serving framework.arXiv preprint arXiv:2601.05109. Yong Lin, Shange Tang, Bohan Lyu, Ziran Yang, Jui-Hui Chung, Haoyu Zhao, Lai Jiang, Yihan Geng, Jiawei Ge, Jingruo Sun, et al
-
[5]
Goedel-Prover-V2: Scaling Formal Theorem Proving with Scaffolded Data Synthesis and Self-Correction
Goedel-prover-v2: Scaling formal theorem proving with scaffolded data synthesis and self-correction.arXiv preprint arXiv:2508.03613. Hanbing Liu, Chunhao Tian, Nan An, Ziyuan Wang, Pinyan Lu, Changyuan Yu, and Qi Qi
-
[6]
arXiv preprint arXiv:2602.11541
Budget-constrained agentic large language models: Intention-based planning for costly tool use. arXiv preprint arXiv:2602.11541. Tengxiao Liu, Zifeng Wang, Jin Miao, I Hsu, Jun Yan, Jiefeng Chen, Rujun Han, Fangyuan Xu, Yanfei Chen, Ke Jiang, et al
-
[7]
Budget-aware tool-use enables effective agent scaling
Budget-aware tool-use enables effective agent scaling.arXiv preprint arXiv:2511.17006. Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al
-
[8]
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom
Timely machine: Awareness of time makes test-time scaling agentic.arXiv preprint arXiv:2601.16486. Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom
-
[9]
Zhihong Pan, Kai Zhang, Yuze Zhao, and Yupeng Han
100 instances is all you need: predicting the success of a new llm on unseen data by testing on a few instances.arXiv preprint arXiv:2409.03563. Zhihong Pan, Kai Zhang, Yuze Zhao, and Yupeng Han
-
[10]
Pranoy Panda, Raghav Magazine, Chaitanya Devaguptapu, Sho Takemori, and Vishal Sharma
Route to reason: Adaptive routing for llm and reasoning strategy selection.arXiv preprint arXiv:2505.19435. Pranoy Panda, Raghav Magazine, Chaitanya Devaguptapu, Sho Takemori, and Vishal Sharma
-
[11]
Pan, H., Tennenholtz, G., Mannor, S., Chi, C.-W., Brekel- mans, R., Shah, P., and Tewari, A
Adaptive llm routing under budget constraints.arXiv preprint arXiv:2508.21141. Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez
-
[12]
Sater: A self-aware and token-efficient approach to routing and cascading. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 10526–10540. Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al
work page 2025
-
[13]
Kimi K2.5: Visual Agentic Intelligence
Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276. Qwen Team
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
CodeFlowBench: A Multi-turn, Iterative Benchmark for Complex Code Generation
Qwen3 technical report. Fali Wang, Hui Liu, Jingying Zeng, Zhiwei Zhang, Zongyu Wu, Chen Luo, Zhen Li, Xianfeng Tang, Qi He, Suhang Wang, et al. 2025a. Agenttts: Large language model agent for test-time compute-optimal scaling strategy in complex tasks. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. Haiming Wang, Mert Unsal...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629. Caiqi Zhang, Menglin Xia, Xuchao Zhang, Daniel Madrigal, Ankur Mallick, Samuel Kessler, Victor Ruehle, and Saravan Rajmohan. 2026a. Budget-aware agentic routing via boundary-guided training. arXiv preprint arXiv:2602.21227. Guibin Zhang, Luyang Niu, Junfeng Fang, K...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Theorem 9 explains the role of the noise-injection experiments. When success rates or generation lengths are estimated imperfectly, the planner optimizes the simulated workflow model induced by these estimates. The degradation is controlled by the induced value discrepancy β(s). Empirically, we perturb predicted subtask success probabilities and generatio...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.