Recognition: 1 theorem link
· Lean TheoremFrom Use to Oversight: How Mental Models Influence User Behavior and Output in AI Writing Assistants
Pith reviewed 2026-05-10 18:51 UTC · model grok-4.3
The pith
Structural mental models of AI writing assistants improve understanding and usability ratings but lead to more grammatical errors in user outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
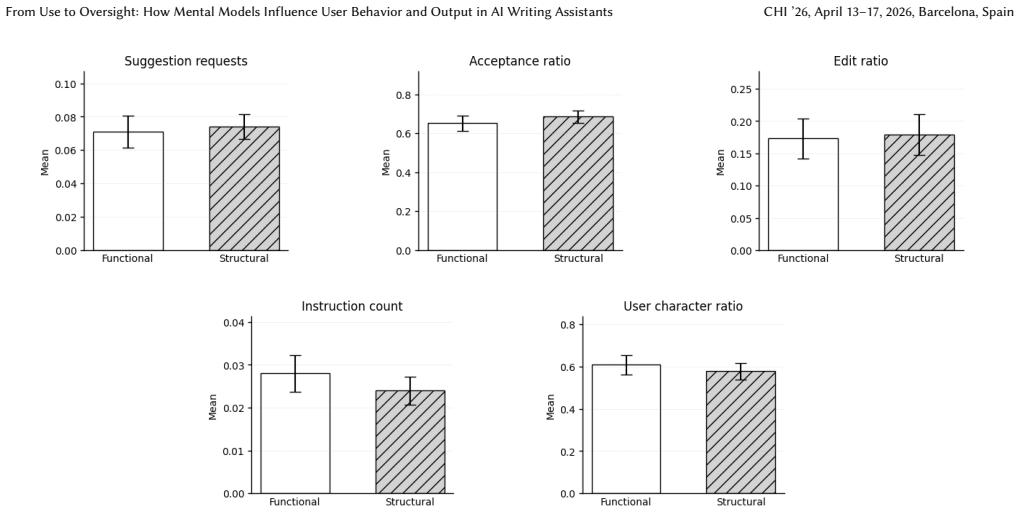
Participants primed with structural descriptions of the AI writing assistant demonstrated a better understanding of the system, judged the system as more usable, and produced cover letters containing more grammatical errors than participants primed with functional descriptions, even though the AI occasionally supplied ungrammatical suggestions.
What carries the argument
Priming via functional versus structural system descriptions to induce distinct mental models that then guide control behaviors such as requesting, accepting, or editing AI suggestions.
If this is right
- Structural understanding can raise usability perceptions while lowering actual error detection in AI-assisted writing.
- Functional descriptions may support more active editing of AI suggestions and fewer uncorrected mistakes.
- System explanations given to users can shape both trust and oversight behavior in error-prone AI tools.
- Design choices about how much internal detail to reveal affect output quality beyond simple comprehension gains.
Where Pith is reading between the lines
- Designers may need to add explicit error-checking prompts when supplying structural details about an AI system.
- The backfiring pattern could appear in other oversight-heavy domains such as AI code completion or report generation.
- Repeated use of structural explanations might gradually lower user vigilance if people come to feel they fully 'know' the tool.
Load-bearing premise
The system descriptions successfully created different mental models, and the rise in grammatical errors reflects reduced oversight rather than differences in participants' writing skill or attention.
What would settle it
A follow-up study that measures each participant's actual mental model after priming and separately assesses their baseline writing proficiency to check whether error differences remain when skill is held constant.
Figures





read the original abstract
AI-based writing assistants are ubiquitous, yet little is known about how users' mental models shape their use. We examine two types of mental models -- functional or related to what the system does, and structural or related to how the system works -- and how they affect control behavior -- how users request, accept, or edit AI suggestions as they write -- and writing outcomes. We primed participants ($N = 48$) with different system descriptions to induce these mental models before asking them to complete a cover letter writing task using a writing assistant that occasionally offered preconfigured ungrammatical suggestions to test whether the mental models affected participants' critical oversight. We find that while participants in the structural mental model condition demonstrate a better understanding of the system, this can have a backfiring effect: while these participants judged the system as more usable, they also produced letters with more grammatical errors, highlighting a complex relationship between system understanding, trust, and control in contexts that require user oversight of error-prone AI outputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical user study (N=48) in which participants were primed with functional or structural descriptions of an AI writing assistant before completing a cover-letter task that included occasional preconfigured ungrammatical suggestions. The central claim is that structural mental models produce better system understanding and higher usability ratings yet also yield letters containing more grammatical errors, interpreted as a backfiring effect on critical oversight of AI output.
Significance. If the causal link between mental-model induction, oversight behavior, and error rates can be isolated, the work would usefully extend HCI research on human-AI collaboration by showing that greater system transparency can sometimes reduce rather than increase user scrutiny. It offers a concrete, falsifiable prediction about the relationship between understanding, trust, and control that could inform the design of oversight-supporting interfaces.
major comments (3)
- The experimental design provides no pre-task measure of participants' baseline writing or editing skill. Because the key dependent variable is the number of grammatical errors in the final letter, any between-condition difference could be driven by uneven distribution of writing ability across the small N=48 sample rather than by changes in oversight behavior.
- No attention checks, manipulation checks for the mental-model induction, or correlational analyses linking error counts to observable control actions (e.g., acceptance rate of the deliberately ungrammatical suggestions) are described. Without such evidence, the interpretation that structural-model participants exercised less critical oversight remains unanchored.
- The manuscript reports no statistical details (effect sizes, confidence intervals, power analysis, or exact tests) for the claimed differences in error rates and usability judgments. With a modest sample and multiple dependent measures, these omissions make it impossible to assess whether the backfiring effect is robust or an artifact of the particular analysis choices.
minor comments (1)
- The abstract and methods would benefit from explicit operational definitions of 'functional' versus 'structural' mental models and of how grammatical errors were counted and verified.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, indicating where we agree and the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: The experimental design provides no pre-task measure of participants' baseline writing or editing skill. Because the key dependent variable is the number of grammatical errors in the final letter, any between-condition difference could be driven by uneven distribution of writing ability across the small N=48 sample rather than by changes in oversight behavior.
Authors: We agree this is a valid limitation given the sample size. Although participants were randomly assigned to conditions (which should balance baseline differences on average), we lack direct evidence of balance without pre-measures. In the revision we will add an explicit discussion of this limitation in the paper and note that future studies should include pre-task writing assessments. The reported differences in system understanding and usability ratings (which are less directly tied to writing skill) provide some convergent support for the mental-model effects. revision: partial
-
Referee: No attention checks, manipulation checks for the mental-model induction, or correlational analyses linking error counts to observable control actions (e.g., acceptance rate of the deliberately ungrammatical suggestions) are described. Without such evidence, the interpretation that structural-model participants exercised less critical oversight remains unanchored.
Authors: The manuscript already reports that structural-condition participants demonstrated better system understanding; we will revise the text to present this more explicitly as evidence of successful mental-model induction. We did not include formal attention checks in the original protocol and will note this as a limitation. To better anchor the oversight interpretation, we will add correlational analyses in the revision examining the relationship between acceptance rates of the preconfigured ungrammatical suggestions and final grammatical error counts. revision: yes
-
Referee: The manuscript reports no statistical details (effect sizes, confidence intervals, power analysis, or exact tests) for the claimed differences in error rates and usability judgments. With a modest sample and multiple dependent measures, these omissions make it impossible to assess whether the backfiring effect is robust or an artifact of the particular analysis choices.
Authors: We agree that fuller statistical reporting is necessary. In the revised manuscript we will add effect sizes, 95% confidence intervals, exact p-values, and a post-hoc power analysis for the key comparisons between conditions. We will also clarify the statistical tests used and address any multiple-comparison considerations. revision: yes
Circularity Check
No circularity: empirical user study with no derivations or self-referential reductions
full rationale
The paper is a controlled user study (N=48) that primes participants with system descriptions to induce functional vs. structural mental models, then measures control behaviors and writing outcomes on a cover-letter task. No equations, fitted parameters, predictions, or derivations appear anywhere in the text. All claims rest on direct experimental observations (e.g., error counts, usability ratings) rather than any definitional equivalence, self-citation chain, or renaming of inputs as outputs. The central finding—that structural priming yields better system understanding yet more grammatical errors—is presented as an empirical result, not a logical necessity derived from the study design itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Priming with different system descriptions induces distinct functional versus structural mental models
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe primed participants (N=48) with different system descriptions to induce these mental models before asking them to complete a cover letter writing task using a writing assistant that occasionally offered preconfigured ungrammatical suggestions
Reference graph
Works this paper leans on
-
[1]
Tazin Afrin, Omid Kashefi, Christopher Olshefski, Diane Litman, Rebecca Hwa, and Amanda Godley. 2021. Effective Interfaces for Student-Driven Revision Sessions for Argumentative Writing. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems(Yokohama, Japan)(CHI ’21, Article 58). Association for Computing Machinery, New York, NY, U...
-
[2]
Dhruv Agarwal, Mor Naaman, and Aditya Vashistha. 2025. AI suggestions homogenize writing toward western styles and diminish cultural nuances. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. ACM, New York, NY, USA, 1–21. doi:10.1145/3706598.3713564
-
[3]
T. A. Bach, A. Khan, H. Hallock, G. Beltrão, and S. Sousa. 2024. A Systematic Literature Review of User Trust in AI-Enabled Systems: An HCI Perspective. International Journal of Human–Computer Interaction40, 5 (2024), 1251–1266. doi:10.1080/10447318.2022.2138826
-
[4]
Gagan Bansal, Besmira Nushi, Ece Kamar, Walter S Lasecki, Daniel S Weld, and Eric Horvitz. 2019. Beyond accuracy: The role of mental models in human-AI team performance. InProceedings of the AAAI Conference on Human Computation and Crowdsourcing, Vol. 7. Association for the Advancement of Artificial Intelligence (AAAI), Honolulu, Hawaii, USA, 2–11. doi:10...
-
[5]
Gagan Bansal, Tongshuang Wu, Joyce Zhou, Raymond Fok, Besmira Nushi, Ece Kamar, Marco Tulio Ribeiro, and Daniel Weld. 2021. Does the Whole Exceed its Parts? The Effect of AI Explanations on Complementary Team Performance. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (Yokohama, Japan)(CHI ’21, Article 81). Association for...
-
[6]
Kevin Bauer, Moritz von Zahn, and Oliver Hinz. 2023. Expl(AI)ned: The Impact of Explainable Artificial Intelligence on Users’ Information Processing.Information Systems Research34, 4 (2023), 1582–1602. doi:10.1287/isre.2023.1199
-
[7]
Ralf Bender and Stefan Lange. 2001. Adjusting for multiple testing–when and how?J. Clin. Epidemiol.54, 4 (April 2001), 343–349. doi:10 .1016/s0895- 4356(00)00314-0
2001
-
[8]
Karim Benharrak, Tim Zindulka, and Daniel Buschek. 2024. Deceptive patterns of intelligent and interactive writing assistants. InProceedings of the Third Workshop on Intelligent and Interactive Writing Assistants. ACM, New York, NY, USA, 62–64. doi:10.1145/3690712.3690728
-
[9]
Peter Blokland and Genserik Reniers. 2020. Safety Science, a Systems Thinking Perspective: From Events to Mental Models and Sustainable Safety.Sustain. Sci. Pract. Policy12, 12 (June 2020), 5164. doi:10.3390/su12125164
-
[10]
Jessica Y Bo, Sophia Wan, and Ashton Anderson. 2025. To rely or not to rely? Evaluating interventions for appropriate reliance on large language models. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. ACM, New York, NY, USA, 1–23. doi:10.1145/3706598.3714097
-
[11]
Virginia Braun and Victoria Clarke. 2006. Using Thematic Analysis in Psychology. Qualitative Research in Psychology3, 2 (2006), 77–101
2006
-
[12]
Virginia Braun and Victoria Clarke. 2023. Toward good practice in thematic analysis: Avoiding common problems and be(com)ing a knowing researcher.Int. J. Transgend. Health24, 1 (2023), 1–6. doi:10.1080/26895269.2022.2129597
-
[13]
Michael J Burtscher and Tanja Manser. 2012. Team mental models and their potential to improve teamwork and safety: A review and implications for fu- ture research in healthcare.Saf. Sci.50, 5 (June 2012), 1344–1354. doi:10 .1016/ j.ssci.2011.12.033
2012
-
[14]
Daniel Buschek, Martin Zürn, and Malin Eiband. 2021. The Impact of Multiple Parallel Phrase Suggestions on Email Input and Composition Behaviour of Native and Non-Native English Writers. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems(Yokohama, Japan)(CHI ’21, Article 732). Association for Computing Machinery, New York, NY, ...
-
[15]
John M Carroll and Judith Reitman Olson. 1988. Mental Models in Human- Computer Interaction. InHandbook of Human-Computer Interaction, Martin Helander (Ed.). North-Holland, Amsterdam, 45–65. doi:10 .1016/B978-0-444- 70536-5.50007-5
1988
-
[16]
Karina Cortiñas-Lorenzo, Wanling Cai, and Gavin Doherty. 2025. Designing, implementing, and evaluating AI explanations: A scoping review of Explainable AI frameworks.ACM Trans. Comput. Hum. Interact.32, 6 (Dec. 2025), 1–79. doi:10.1145/3769678
-
[17]
Patrick Cox, Jörg Niewöhmer, Nick Pidgeon, Simon Gerrard, Baruch Fischhoff, and Donna Riley. 2003. The use of mental models in chemical risk protection: developing a generic workplace methodology.Risk Anal.23, 2 (April 2003), 311–324. doi:10.1111/1539-6924.00311
-
[18]
Hai Dang, Sven Goller, Florian Lehmann, and Daniel Buschek. 2023. Choice Over Control: How Users Write with Large Language Models using Diegetic and Non- Diegetic Prompting. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23, Article 408). Association for Computing Machinery, New York, NY, USA, 1–17. d...
-
[19]
Sidney Dekker. 2017.The Field Guide to Understanding “Human Error”(3rd ed.). CRC Press, Boca Raton, FL. doi:10.1201/9781317031833
-
[20]
Roel Dobbe. 2022. System Safety and Artificial Intelligence. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency(Seoul, Republic of Korea)(FAccT ’22). Association for Computing Machinery, New York, NY, USA, 1584. doi:10.1145/3531146.3533215
-
[21]
Fiona Draxler, Anna Werner, Florian Lehmann, Matthias Hoppe, Albrecht Schmidt, Daniel Buschek, and Robin Welsch. 2024. The AI Ghostwriter Ef- fect: When users do not perceive ownership of AI-generated text but self- declare as authors.ACM Trans. Comput. Hum. Interact.31, 2 (April 2024), 1–40. doi:10.1145/3637875
-
[22]
European Union. 2024. Regulation (EU) 2024/1689 of the European Parliament and of the Council laying down harmonised rules on artificial intelligence (AI Act). Official Journal of the European Union. https://eur-lex .europa.eu/eli/reg/ 2024/1689/oj Article 14 (Human Oversight)
2024
-
[23]
2020.The impact of driver’s mental models of advanced vehicle technologies on safety and performance
John Gaspar, Cher Carney, Emily Shull, and William Horrey. 2020.The impact of driver’s mental models of advanced vehicle technologies on safety and performance. Technical Report. AAA Foundation for Traffic Safety and SAFER-SIM
2020
-
[24]
John Maurice Gayed, May Kristine Jonson Carlon, Angelu Mari Oriola, and Jeffrey S Cross. 2022. Exploring an AI-based writing Assistant’s impact on English language learners.Computers and Education: Artificial Intelligence3 (Jan. 2022), 100055. doi:10.1016/j.caeai.2022.100055
-
[25]
Biniam Gebru, Lydia Zeleke, Daniel Blankson, Mahmoud Nabil, Shamila Nateghi, Abdollah Homaifar, and Edward Tunstel. 2022. A Review on Human–Machine Trust Evaluation: Human-Centric and Machine-Centric Perspectives.IEEE Transactions on Human-Machine Systems52, 5 (2022), 952–962. doi:10 .1109/ THMS.2022.3144956
-
[26]
Michael Gerlich. 2025. AI tools in society: Impacts on cognitive offloading and the future of critical thinking.Societies (Basel)15, 1 (Jan. 2025), 6. doi:10 .3390/ soc15010006
2025
-
[27]
Katy Ilonka Gero, Zahra Ashktorab, Casey Dugan, Qian Pan, James Johnson, Werner Geyer, Maria Ruiz, Sarah Miller, David R Millen, Murray Campbell, Sadhana Kumaravel, and Wei Zhang. 2020. Mental Models of AI Agents in a Cooperative Game Setting. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’20). Assoc...
-
[28]
Katy Ilonka Gero, Vivian Liu, and Lydia Chilton. 2022. Sparks: Inspiration for Science Writing using Language Models. InProceedings of the 2022 ACM Designing Interactive Systems Conference(Virtual Event, Australia)(DIS ’22). Asso- ciation for Computing Machinery, New York, NY, USA, 1002–1019. doi:10.1145/ 3532106.3533533 CHI ’26, April 13–17, 2026, Barcel...
-
[29]
Katy Ilonka Gero, Tao Long, and Lydia B Chilton. 2023. Social Dynamics of AI Support in Creative Writing. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23, Article 245). Association for Computing Machinery, New York, NY, USA, 1–15
2023
-
[30]
Steven M Goodman, Erin Buehler, Patrick Clary, Andy Coenen, Aaron Donsbach, Tiffanie N Horne, Michal Lahav, Robert MacDonald, Rain Breaw Michaels, Ajit Narayanan, Mahima Pushkarna, Joel Riley, Alex Santana, Lei Shi, Rachel Sweeney, Phil Weaver, Ann Yuan, and Meredith Ringel Morris. 2022. LaMPost: Design and Evaluation of an AI-assisted Email Writing Proto...
-
[31]
Grammarly. 2019. How Correctness Keeps Your Writing Sharp | Grammarly Spotlight. https://www .grammarly.com/blog/product/correctness-dimension/. Accessed: 2025-6-17
2019
-
[32]
Alicia Guo, Shreya Sathyanarayanan, Leijie Wang, Jeffrey Heer, and Amy X Zhang. 2025. From pen to prompt: How creative writers integrate AI into their writing practice. InProceedings of the 2025 Conference on Creativity and Cognition. ACM, New York, NY, USA, 527–545. doi:10.1145/3698061.3726910
-
[33]
Angel Hsing-Chi Hwang, Q Vera Liao, Su Lin Blodgett, Alexandra Olteanu, and Adam Trischler. 2025. ’It was 80% me, 20% AI’: Seeking Authenticity in Co- Writing with Large Language Models.Proc. ACM Hum. Comput. Interact.9, 2 (May 2025), 1–41. doi:10.1145/3711020
- [34]
-
[35]
Maurice Jakesch, Advait Bhat, Daniel Buschek, Lior Zalmanson, and Mor Naaman
-
[36]
Co-Writing with Opinionated Language Models Affects Users’ Views. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (Hamburg, Germany)(CHI ’23, Article 111). Association for Computing Machinery, New York, NY, USA, 1–15. doi:10.1145/3544548.3581196
-
[37]
1983.Mental Models
Philip N Johnson-Laird. 1983.Mental Models. Harvard University Press, London, England
1983
-
[38]
Kowe Kadoma, Marianne Aubin Le Quere, Xiyu Jenny Fu, Christin Munsch, Danaë Metaxa, and Mor Naaman. 2024. The role of inclusion, control, and ownership in workplace AI-mediated communication. InProceedings of the CHI Conference on Human Factors in Computing Systems. ACM, New York, NY, USA, 1–10. doi:10.1145/3613904.3642650
-
[39]
Jeongyeon Kim, Sangho Suh, Lydia B Chilton, and Haijun Xia. 2023. Metaphorian: Leveraging Large Language Models to Support Extended Metaphor Creation for Science Writing. InProceedings of the 2023 ACM Designing Interactive Systems Conference(Pittsburgh, PA, USA)(DIS ’23). Association for Computing Machinery, New York, NY, USA, 115–135. doi:10.1145/3563657.3595996
-
[40]
Sunnie S Y Kim, Jennifer Wortman Vaughan, Q Vera Liao, Tania Lombrozo, and Olga Russakovsky. 2025. Fostering appropriate reliance on large language models: The role of explanations, sources, and inconsistencies. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. ACM, New York, NY, USA, 1–19. doi:10.1145/3706598.3714020
-
[41]
Hannah Rose Kirk, Henry Davidson, Ed Saunders, Lennart Luettgau, Bertie Vidgen, Scott A Hale, and Christopher Summerfield. 2025. Neural steering vectors reveal dose and exposure-dependent impacts of human-AI relationships
2025
-
[42]
Aniket Kittur, Ed H. Chi, and Bongwon Suh. 2008. Crowdsourcing User Studies with Mechanical Turk. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems. ACM, New York, NY, USA, 453–456. doi:10.1145/1357054.1357127
-
[43]
Todd Kulesza, Simone Stumpf, Margaret Burnett, Sherry Yang, Irwin Kwan, and Weng-Keen Wong. 2013. Too Much, Too Little, or Just Right? Ways Explanations Impact End Users’ Mental Models. In2013 IEEE Symposium on Visual Languages and Human-Centric Computing. IEEE, San Jose, CA, USA, 3–10. doi:10 .1109/ vlhcc.2013.6645235
-
[44]
In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24)
Mina Lee, Katy Ilonka Gero, John Joon Young Chung, Simon Buckingham Shum, Vipul Raheja, Hua Shen, Subhashini Venugopalan, Thiemo Wambsganss, David Zhou, Emad A. Alghamdi, Tal August, Avinash Bhat, Madiha Zahrah Choksi, Senjuti Dutta, Jin L.C. Guo, Md Naimul Hoque, Yewon Kim, Simon Knight, Seyed Parsa Neshaei, Antonette Shibani, Disha Shrivastava, Lila Shr...
-
[45]
Mina Lee, Percy Liang, and Qian Yang. 2022. CoAuthor: Designing a Human-AI Collaborative Writing Dataset for Exploring Language Model Capabilities. InPro- ceedings of the 2022 CHI Conference on Human Factors in Computing Systems(New Orleans, LA, USA)(CHI ’22, Article 388). Association for Computing Machinery, New York, NY, USA, 1–19. doi:10.1145/3491102.3502030
-
[46]
Nancy Leveson. 2004. A new accident model for engineering safer systems.Saf. Sci.42, 4 (April 2004), 237–270. doi:10.1016/s0925-7535(03)00047-x
-
[47]
Nancy Leveson and John Thomas. 2018. STPA Handbook. https:// psas.scripts.mit.edu/home/get_file.php?name=STPA_handbook.pdf
2018
-
[48]
2012.Engineering a safer world: Systems thinking applied to safety
Nancy G Leveson. 2012.Engineering a safer world: Systems thinking applied to safety. MIT Press, London, England
2012
-
[49]
Zhuoyan Li, Chen Liang, Jing Peng, and Ming Yin. 2024. How Does the Disclosure of AI Assistance Affect the Perceptions of Writing?. InProceedings of the 2024 Con- ference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Lin- guistics, Miami, Florida, USA, 4849–4868...
2024
-
[50]
Zhuoyan Li, Chen Liang, Jing Peng, and Ming Yin. 2024. The Value, Benefits, and Concerns of Generative AI-Powered Assistance in Writing. InProceedings of the CHI Conference on Human Factors in Computing Systems. ACM, New York, NY, USA, 1048:1–1048:25. doi:10.1145/3613904.3642625
-
[51]
Shuai Ma, Qiaoyi Chen, Xinru Wang, Chengbo Zheng, Zhenhui Peng, Ming Yin, and Xiaojuan Ma. 2025. Towards human-AI deliberation: Design and evaluation of LLM-empowered deliberative AI for AI-assisted decision-making. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. ACM, New York, NY, USA, 1–23. doi:10.1145/3706598.3713423
-
[52]
Khalid Mehmood, Katrien Verleye, Arne De Keyser, and Bart Larivière. 2025. From promises to practice: Unravelling users’ mental models about Large Language Models at individual and societal levels. doi:10.2139/ssrn.5598465 Preprint paper
-
[53]
Piotr Mirowski, Kory W Mathewson, Jaylen Pittman, and Richard Evans. 2023. Co- Writing Screenplays and Theatre Scripts with Language Models: Evaluation by Industry Professionals. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23, Article 355). Association for Computing Machinery, New York, NY, USA, 1–...
-
[54]
Bonnie M. Muir. 1987. Trust Between Humans and Machines and the Design of Decision Aids.International Journal of Man-Machine Studies27, 5–6 (1987), 527–539. doi:10.1016/S0020-7373(87)80013-5
- [55]
-
[56]
D A Norman. 1987. Some observations on mental models. InHuman-computer interaction: a multidisciplinary approach. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 241–244
1987
-
[57]
Mahsan Nourani, Chiradeep Roy, Jeremy E Block, Donald R Honeycutt, Tahrima Rahman, Eric Ragan, and Vibhav Gogate. 2021. Anchoring Bias Affects Mental Model Formation and User Reliance in Explainable AI Systems. In26th Interna- tional Conference on Intelligent User Interfaces (IUI ’21). Association for Computing Machinery, New York, NY, USA, 340–350. doi:1...
-
[58]
Aswati Panicker, Novia Nurain, Zaidat Ibrahim, Chun-Han (ariel) Wang, Se- ung Wan Ha, Yuxing Wu, Kay Connelly, Katie A Siek, and Chia-Fang Chung. 2024. Understanding fraudulence in online qualitative studies: From the researcher’s perspective. InProceedings of the CHI Conference on Human Factors in Computing Systems. ACM, New York, NY, USA, 1–17. doi:10.1...
-
[59]
Gabriele Paolacci and Jesse Chandler. 2014. Inside the Turk: Understanding mechanical Turk as a participant pool.Curr. Dir. Psychol. Sci.23, 3 (June 2014), 184–188. doi:10.1177/0963721414531598
-
[60]
Samir Passi, Shipi Dhanorkar, and Mihaela Vorvoreanu. 2025. Addressing over- reliance on AI. InHandbook of Human-Centered Artificial Intelligence. Springer Nature Singapore, Singapore, 1–34. doi:10.1007/978-981-97-8440-0_98-1
-
[61]
Ritika Poddar, Rashmi Sinha, Mor Naaman, and Maurice Jakesch. 2023. AI Writing Assistants Influence Topic Choice in Self-Presentation. InExtended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI EA ’23, Article 29). Association for Computing Machinery, New York, NY, USA, 1–6. doi:10.1145/3544549.3585893
-
[62]
Jens Rasmussen. 1987. Mental models and the control of action in complex envi- ronments. InSelected papers of the 6th Interdisciplinary Workshop on Informatics and Psychology: Mental Models and Human-Computer Interaction 1. North-Holland Publishing Co., NLD, 41–69
1987
-
[63]
Mohi Reza, Jeb Thomas-Mitchell, Peter Dushniku, Nathan Laundry, Joseph Jay Williams, and Anastasia Kuzminykh. 2025. Co-writing with AI, on human terms: Aligning research with user demands across the writing process.Proc. ACM Hum. Comput. Interact.9, 7 (Oct. 2025), 1–37. doi:10.1145/3757566
-
[64]
Shalaleh Rismani, Renee Shelby, Leah Davis, Negar Rostamzadeh, and Ajung Moon. 2025. Measuring what matters: Connecting AI ethics evaluations to system attributes, hazards, and harms.Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society8, 3 (Oct. 2025), 2199–2213
2025
-
[65]
InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI 2021)
Ronald E Robertson, Alexandra Olteanu, Fernando Diaz, Milad Shokouhi, and Peter Bailey. 2021. “I Can’t Reply with That”: Characterizing Problematic Email Reply Suggestions. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems(Yokohama, Japan)(CHI ’21). Association for Computing Ma- chinery, New York, NY, USA, Article 724, 18 page...
-
[66]
Automation bias in human-AI collaboration: A review.AI & Society, 2025
G. Romeo and E. Conti. 2025. Exploring automation bias in human–AI collabo- ration: a review and implications for explainable AI.AI & Society40, 3 (2025), 789–812. doi:10.1007/s00146-025-02422-7 From Use to Oversight: How Mental Models Influence User Behavior and Output in AI Writing Assistants CHI ’26, April 13–17, 2026, Barcelona, Spain
-
[67]
Sarter, Christopher D
Nadine B. Sarter, Christopher D. Wickens, Randall J. Mumaw, Steve Kimball, Roger Marsh, Mark I. Nikolic, and W. Q. Xu. 2003. Modern flight deck au- tomation: pilots’ mental model and monitoring patterns and performance. https://api.semanticscholar.org/CorpusID:107831159. Presented at the 12th In- ternational Symposium on Aviation Psychology
2003
-
[68]
Ulrike Schäfer, Lars Sipos, and Claudia Müller-Birn. 2025. ‘The AI is uncertain, so am I. What now?’: Navigating Shortcomings of Uncertainty Representations in Human-AI Collaboration with Capability-focused Guidance.Proc. ACM Hum. Comput. Interact.9, 7 (Oct. 2025), 1–48. doi:10.1145/3757451
-
[69]
Sathya S Silva and R John Hansman. 2015. Divergence Between Flight Crew Mental Model and Aircraft System State in Auto-Throttle Mode Confusion Acci- dent and Incident Cases.Journal of Cognitive Engineering and Decision Making9, 4 (Dec. 2015), 312–328. doi:10.1177/1555343415597344
-
[70]
Nancy Staggers and A F Norcio. 1993. Mental models: concepts for human- computer interaction research.Int. J. Man. Mach. Stud.38, 4 (April 1993), 587–605. https://www.sciencedirect.com/science/article/pii/S002073738371028X
1993
-
[71]
Yujie Sun, Dongfang Sheng, Zihan Zhou, and Yifei Wu. 2024. AI hallucination: towards a comprehensive classification of distorted information in artificial intelligence-generated content.Humanit. Soc. Sci. Commun.11, 1 (Sept. 2024), 1–14. doi:10.1057/s41599-024-03811-x
-
[72]
Siddharth Swaroop, Zana Buçinca, Krzysztof Z Gajos, and Finale Doshi-Velez
-
[73]
InProceedings of the 30th International Conference on Intelligent User Interfaces
Personalising AI assistance based on overreliance rate in AI-assisted deci- sion making. InProceedings of the 30th International Conference on Intelligent User Interfaces. ACM, New York, NY, USA, 1107–1122. doi:10.1145/3708359.3712128
-
[74]
Christopher L Tarola, Sameer Hirji, Steven J Yule, Jennifer M Gabany, Alessandro Zenati, Roger D Dias, and Marco A Zenati. 2018. Cognitive Support to Promote Shared Mental Models during Safety-Critical Situations in Cardiac Surgery (Late Breaking Report). In2018 IEEE Conference on Cognitive and Computational As- pects of Situation Management (CogSIMA). In...
-
[75]
Mor Vered, Tali Livni, Piers Douglas Lionel Howe, Tim Miller, and Liz Sonenberg
-
[76]
The effects of explanations on automation bias.Artif. Intell.322, 103952 (Sept. 2023), 103952. doi:10.1016/j.artint.2023.103952
-
[77]
Kailas Vodrahalli, Roxana Daneshjou, Tobias Gerstenberg, and James Zou. 2022. Do Humans Trust Advice More if it Comes from AI? An Analysis of Human- AI Interactions. InProceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society(Oxford, United Kingdom)(AIES ’22). Association for Computing Machinery, New York, NY, USA, 763–777. doi:10.1145/351409...
-
[78]
Hanna Wallach, Meera Desai, A Feder Cooper, Angelina Wang, Chad Atalla, Solon Barocas, Su Lin Blodgett, Alexandra Chouldechova, Emily Corvi, P Alex Dow, Jean Garcia-Gathright, Alexandra Olteanu, Nicholas J Pangakis, Stefanie Reed, Emily Sheng, Dan Vann, Jennifer Wortman Vaughan, Matthew Vogel, Hannah Washington, and Abigail Z Jacobs. 2025. Position: Evalu...
2025
-
[79]
Xingyi Wang, Xiaozheng Wang, Sunyup Park, and Yaxing Yao. 2025. Users’ Mental Models of Generative AI Chatbot Ecosystems. InProceedings of the 30th International Conference on Intelligent User Interfaces (IUI ’25). ACM, Cagliari, Italy. doi:10.1145/3708359.3712125
-
[80]
Gesa Wiegand, Matthias Schmidmaier, Thomas Weber, Yuanting Liu, and Hein- rich Hussmann. 2019. I Drive - You Trust: Explaining Driving Behavior Of Autonomous Cars. InExtended Abstracts of the 2019 CHI Conference on Hu- man Factors in Computing Systems(Glasgow, Scotland Uk)(CHI EA ’19, Paper LBW0163). Association for Computing Machinery, New York, NY, USA,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.