Recognition: no theorem link
Right at My Level: A Unified Multilingual Framework for Proficiency-Aware Text Simplification
Pith reviewed 2026-05-10 19:59 UTC · model grok-4.3
The pith
A reinforcement learning system called Re-RIGHT simplifies text to exact target proficiency levels in English, Japanese, Korean, and Chinese without any parallel training examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
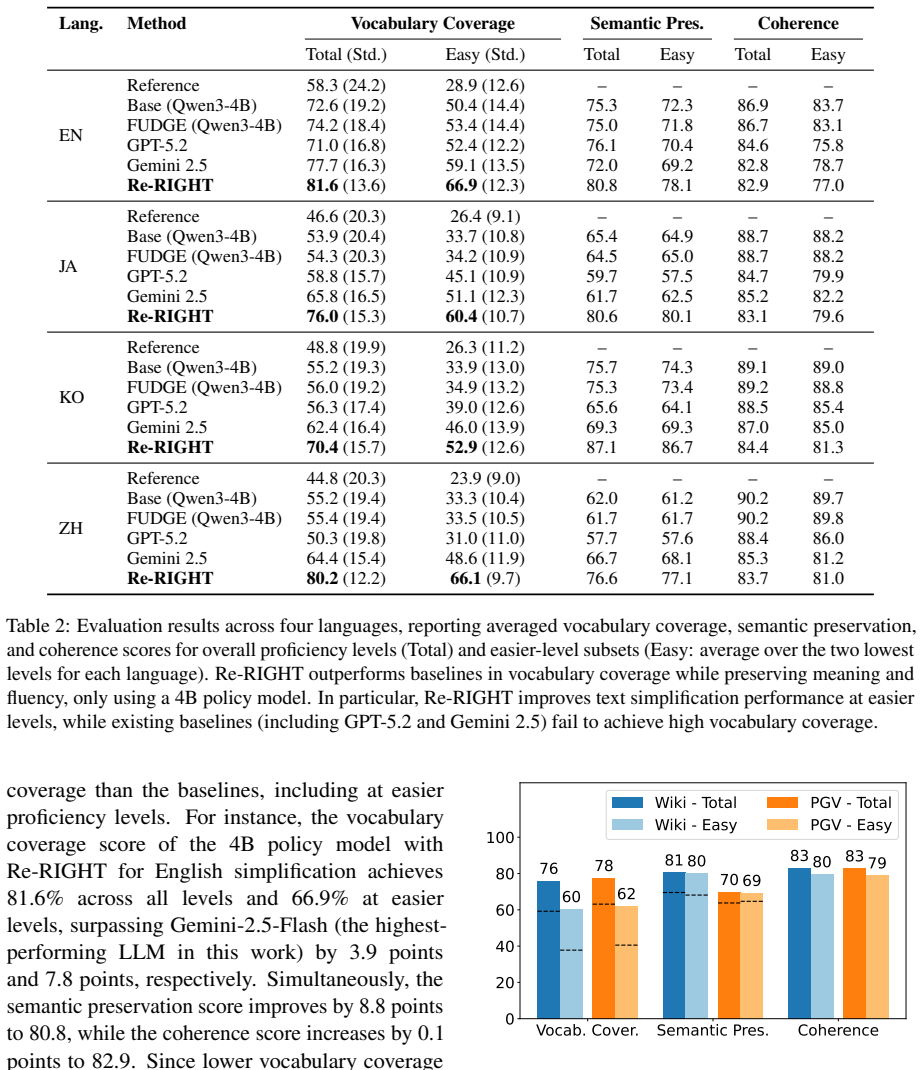
Re-RIGHT trains a 4B policy model on 43K vocabulary entries from English, Japanese, Korean, and Chinese. It combines three reward modules that score vocabulary coverage at a chosen proficiency level, semantic preservation of the source meaning, and overall coherence. The trained model produces simplifications with higher lexical coverage at the intended CEFR, JLPT, TOPIK, or HSK level than direct prompting of stronger models such as GPT-5.2 or Gemini 2.5, while preserving original meaning and fluency, and it does so without parallel corpus supervision.
What carries the argument
Re-RIGHT, a reinforcement learning framework that steers a policy model by combining rewards for vocabulary coverage at the target proficiency level, semantic preservation, and coherence.
If this is right
- Text simplification becomes feasible at precise levels on standard scales without building language-specific parallel datasets.
- A 4B model trained this way can exceed the lexical control of much larger prompted models at easier proficiency targets.
- The same reward structure produces consistent results across English, Japanese, Korean, and Chinese.
- Lexical coverage improves where pure prompting methods degrade most.
Where Pith is reading between the lines
- Similar vocabulary collections could be assembled for additional languages to broaden coverage beyond the four tested here.
- Embedding the trained policy inside reading platforms would allow on-the-fly difficulty adjustment for individual learners.
- The reward design might be tested on other control dimensions such as cultural familiarity or topic complexity.
Load-bearing premise
The three reward modules can reliably steer model output to exact target proficiency levels across languages without parallel supervision or post-hoc tuning.
What would settle it
A controlled test in which expert raters classify Re-RIGHT outputs back to their claimed proficiency levels and find no higher match rate than outputs from direct LLM prompting, or detect greater loss of meaning, would falsify the performance advantage.
Figures



read the original abstract
Text simplification supports second language (L2) learning by providing comprehensible input, consistent with the Input Hypothesis. However, constructing personalized parallel corpora is costly, while existing large language model (LLM)-based readability control methods rely on pre-labeled sentence corpora and primarily target English. We propose Re-RIGHT, a unified reinforcement learning framework for adaptive multilingual text simplification without parallel corpus supervision. We first show that prompting-based lexical simplification at target proficiency levels (CEFR, JLPT, TOPIK, and HSK) performs poorly at easier levels and for non-English languages, even with state-of-the-art LLMs such as GPT-5.2 and Gemini 2.5. To address this, we collect 43K vocabulary-level data across four languages (English, Japanese, Korean, and Chinese) and train a compact 4B policy model using Re-RIGHT, which integrates three reward modules: vocabulary coverage, semantic preservation, and coherence. Compared to the stronger LLM baselines, Re-RIGHT achieves higher lexical coverage at target proficiency levels while maintaining original meaning and fluency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Re-RIGHT, a unified reinforcement learning framework for adaptive multilingual text simplification without parallel corpus supervision. It collects 43K vocabulary-level data across English, Japanese, Korean, and Chinese, trains a compact 4B policy model using three reward modules (vocabulary coverage, semantic preservation, and coherence), and claims that Re-RIGHT outperforms stronger LLM baselines (GPT-5.2, Gemini 2.5) by achieving higher lexical coverage at target proficiency levels (CEFR, JLPT, TOPIK, HSK) while maintaining original meaning and fluency.
Significance. If the results hold under rigorous evaluation, the framework could enable scalable, personalized comprehensible input for L2 learners across languages by avoiding the cost of parallel corpora and the limitations of prompting-based control. The explicit collection of multilingual vocabulary data and the RL design with targeted rewards are practical strengths that address gaps in current LLM simplification methods.
major comments (2)
- [Abstract] Abstract: the central claim of superior performance at target proficiency levels is asserted without any quantitative metrics, baselines, error bars, or evaluation protocol details, preventing assessment of whether the reported gains are statistically meaningful or reproducible.
- [Method] Method (rewards section): the vocabulary coverage reward operates exclusively at the word-substitution level using the 43K per-word labels, while sentence complexity, syntax, and discourse remain uncontrolled; the semantic preservation and coherence rewards contain no proficiency signal, so it is unclear whether increased target-vocab percentage produces text whose overall readability matches the claimed exact proficiency levels (e.g., CEFR A2 or JLPT N3).
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of clarity in the abstract and the scope of our reward design. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of superior performance at target proficiency levels is asserted without any quantitative metrics, baselines, error bars, or evaluation protocol details, preventing assessment of whether the reported gains are statistically meaningful or reproducible.
Authors: We agree that the submitted abstract summarizes results at a high level without numerical details. The full manuscript reports quantitative comparisons in the Experiments section, including lexical coverage percentages across the four languages, direct comparisons against GPT-5.2 and Gemini 2.5, and evaluation protocols that combine automatic metrics with human judgments of meaning preservation and fluency. To improve accessibility, we will revise the abstract to incorporate key quantitative highlights (e.g., relative gains in target-vocabulary coverage) while retaining the word limit, and we will ensure error bars and protocol summaries are explicitly referenced. revision: yes
-
Referee: [Method] Method (rewards section): the vocabulary coverage reward operates exclusively at the word-substitution level using the 43K per-word labels, while sentence complexity, syntax, and discourse remain uncontrolled; the semantic preservation and coherence rewards contain no proficiency signal, so it is unclear whether increased target-vocab percentage produces text whose overall readability matches the claimed exact proficiency levels (e.g., CEFR A2 or JLPT N3).
Authors: Re-RIGHT is explicitly scoped to proficiency-aware lexical simplification. The vocabulary coverage reward uses the 43K per-word labels to directly increase the proportion of substitutions at the target CEFR/JLPT/TOPIK/HSK level. Semantic preservation (via cross-lingual embedding similarity) and coherence (via fluency and local discourse metrics) are intentionally proficiency-agnostic so that they do not bias the lexical signal; their role is to keep meaning and readability intact after substitution. Our evaluation shows that the resulting texts achieve measurably higher target-level lexical coverage than strong LLM baselines while human raters confirm preserved semantics and fluency. We acknowledge that sentence-level syntax and discourse are not explicitly controlled, as the framework avoids parallel corpora and focuses on lexical adaptation. We will add a dedicated limitations paragraph in the Method section clarifying this scope and its relation to overall readability. revision: partial
Circularity Check
No circularity detected in derivation or claims
full rationale
The paper collects an independent 43K vocabulary dataset across four languages, defines three explicit reward functions (vocabulary coverage based on that data, plus separate semantic preservation and coherence terms), trains a 4B RL policy, and reports empirical comparisons to LLM baselines. No equation, reward, or result is shown to be equivalent to its inputs by construction, no self-citation is load-bearing for the central claim, and no fitted parameter is relabeled as a prediction. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reinforcement learning with vocabulary coverage, semantic preservation, and coherence rewards can control output to specific proficiency levels
- domain assumption The 43K vocabulary-level data across four languages is sufficient to train a general policy
Reference graph
Works this paper leans on
-
[1]
Proximal Policy Optimization Algorithms
The percentage of words known in a text and reading comprehension.The modern language jour- nal, 95(1):26–43. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Prox- imal policy optimization algorithms.Preprint, arXiv:1707.06347. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchu...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Controllable text simplification with deep re- inforcement learning. InProceedings of the 2nd Conference of the Asia-Pacific Chapter of the Asso- ciation for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 398–404, Online only. Association for Computational Linguis- tics....
2003
-
[3]
BERTScore: Evaluating Text Generation with BERT
Lexically constrained decoding with edit oper- ation prediction for controllable text simplification. InProceedings of the Workshop on Text Simplifi- cation, Accessibility, and Readability (TSAR-2022), pages 147–153, Abu Dhabi, United Arab Emirates (Virtual). Association for Computational Linguistics. Dongbo Zhang. 2012. V ocabulary and grammar knowl- edg...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.