Recognition: 2 theorem links
· Lean TheoremJeffreys Flow: Robust Boltzmann Generators for Rare Event Sampling via Parallel Tempering Distillation
Pith reviewed 2026-05-10 20:14 UTC · model grok-4.3
The pith
Jeffreys Flow distills parallel tempering data using symmetric divergence to prevent mode collapse in Boltzmann generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
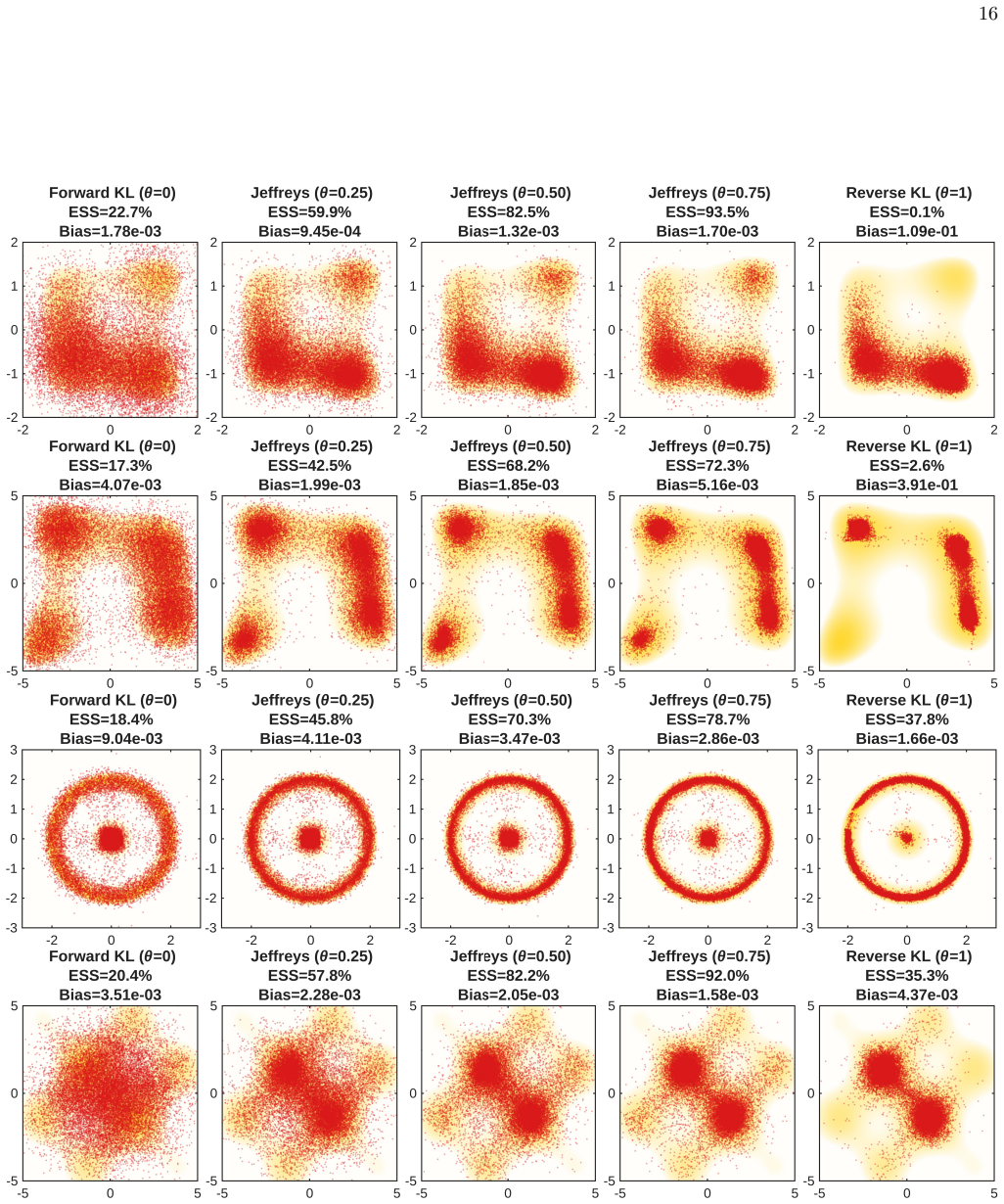
Minimizing the Jeffreys divergence between a Boltzmann generator and reference samples collected from parallel tempering trajectories suppresses mode collapse and corrects structural inaccuracies in the learned distribution. The symmetric form of the divergence balances the local target-seeking behavior of the forward term with the global mode-seeking behavior of the reverse term, so that the distilled generator inherits the completeness of the tempered trajectories while retaining the efficiency of a single-temperature generative model.
What carries the argument
Symmetric Jeffreys divergence minimization for distilling empirical parallel tempering trajectories into the Boltzmann generator, which supplies balanced gradients that enforce both local precision and global mode coverage.
If this is right
- The generator systematically corrects stochastic gradient biases that appear in replica exchange stochastic gradient Langevin dynamics.
- It yields massive acceleration of exact importance sampling inside path integral Monte Carlo calculations for quantum thermal states.
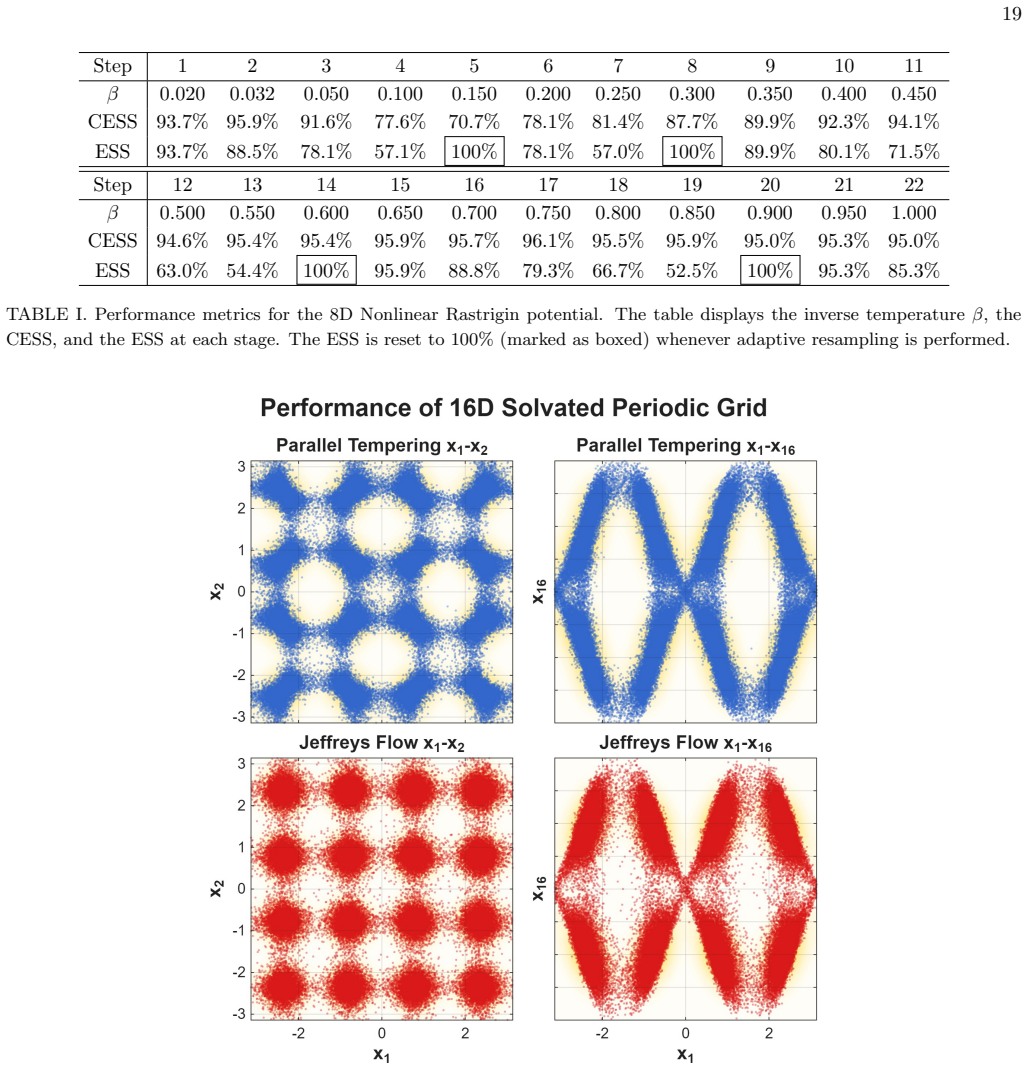
- It produces scalable and accurate sampling on highly non-convex multidimensional benchmark distributions.
- Mode collapse is suppressed because the symmetric divergence penalizes both under-coverage and over-concentration of probability mass.
Where Pith is reading between the lines
- The same distillation principle could be applied to other rare-event problems whose reference distributions are expensive to sample directly.
- Combining Jeffreys Flow with adaptive tempering schedules might further reduce the cost of generating the reference data.
- Verification on systems with analytically known partition functions would provide a direct numerical test of the bias-correction claim.
Load-bearing premise
The empirical trajectories produced by parallel tempering are sufficiently complete and free of tempering-specific biases to serve as an unbiased target distribution for distillation.
What would settle it
A concrete counter-example in which the Jeffreys Flow generator systematically misses a mode that is visited by the parallel tempering reference trajectories, or in which the claimed bias correction in replica-exchange stochastic gradient Langevin dynamics fails to reproduce known exact statistics on a benchmark system.
Figures










read the original abstract
Sampling physical systems with rough energy landscapes is hindered by rare events and metastable trapping. While Boltzmann generators already offer a solution, their reliance on the reverse Kullback--Leibler divergence frequently induces catastrophic mode collapse, missing specific modes in multi-modal distributions. Here, we introduce the Jeffreys Flow, a robust generative framework that mitigates this failure by distilling empirical sampling data from Parallel Tempering trajectories using the symmetric Jeffreys divergence. This formulation effectively balances local target-seeking precision with global modes coverage. We show that minimizing Jeffreys divergence suppresses mode collapse and structurally corrects inherent inaccuracies via distillation of the empirical reference data. We demonstrate the framework's scalability and accuracy on highly non-convex multidimensional benchmarks, including the systematic correction of stochastic gradient biases in Replica Exchange Stochastic Gradient Langevin Dynamics and the massive acceleration of exact importance sampling in Path Integral Monte Carlo for quantum thermal states.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Jeffreys Flow, a generative framework for Boltzmann generators that distills empirical reference distributions from Parallel Tempering (PT) trajectories by minimizing the symmetric Jeffreys divergence. This is proposed to mitigate catastrophic mode collapse induced by reverse KL divergence, while balancing local precision and global mode coverage for rare-event sampling in rough energy landscapes. The approach is demonstrated on highly non-convex multidimensional benchmarks, with applications to systematic correction of stochastic gradient biases in Replica Exchange Stochastic Gradient Langevin Dynamics and acceleration of exact importance sampling in Path Integral Monte Carlo for quantum thermal states.
Significance. If the central claims are substantiated, the work could meaningfully advance robust sampling for multi-modal physical systems by combining generative models with PT data in a symmetric-divergence setting. The emphasis on empirical distillation and explicit handling of mode collapse addresses a persistent limitation in Boltzmann generators. Credit is due for the reproducible experimental setup on standard benchmarks and the attempt to apply the method to both classical and quantum sampling tasks.
major comments (3)
- [§3 Method] §3 (Method) and abstract: the claim that minimizing Jeffreys divergence 'structurally corrects inherent inaccuracies via distillation of the empirical reference data' is load-bearing for the central contribution. This holds only if the PT trajectories are free of tempering-specific artifacts (incomplete mode visitation, temperature-swap correlations, or finite-run biases). The manuscript provides no quantitative check, such as comparison against independent ground-truth sampling or multiple PT runs with varying swap schedules, to separate reference quality from the claimed correction.
- [§4 Experiments] §4 (Experiments): the reported improvements in mode coverage on non-convex benchmarks do not include an ablation that isolates the effect of the Jeffreys divergence from the quality of the PT reference itself. Direct comparison of Jeffreys distillation versus, e.g., forward KL or Jensen-Shannon on identical PT trajectories would be required to establish that the symmetric formulation is responsible for suppressing mode collapse rather than simply inheriting a well-mixed reference.
- [§5 Applications] §5 (Applications): in the Replica Exchange SG-LD bias-correction experiment, it is unclear whether the generator corrects stochastic-gradient biases or merely reproduces PT-induced mixing artifacts. A diagnostic comparing the generator's stationary distribution against an independent, high-fidelity reference (e.g., long PT or exact enumeration on low-dimensional cases) is needed to support the 'systematic correction' claim.
minor comments (3)
- [Notation] Notation: the definition of the Jeffreys divergence (Eq. (3) or equivalent) should be stated explicitly once in the main text rather than only in the appendix, and the same symbol should be used consistently for the divergence and its components.
- [Figures] Figures: benchmark plots (e.g., mode-coverage histograms) should report variability across independent PT seeds or generator initializations; current captions lack error bars or standard deviations.
- [References] References: the manuscript cites foundational PT and Boltzmann-generator works but omits recent comparisons with other symmetric divergences (e.g., Jensen-Shannon or alpha-divergences) used in generative modeling for mode coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the potential impact of Jeffreys Flow. We address each major comment point by point below, offering clarifications and indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3 Method] §3 (Method) and abstract: the claim that minimizing Jeffreys divergence 'structurally corrects inherent inaccuracies via distillation of the empirical reference data' is load-bearing for the central contribution. This holds only if the PT trajectories are free of tempering-specific artifacts (incomplete mode visitation, temperature-swap correlations, or finite-run biases). The manuscript provides no quantitative check, such as comparison against independent ground-truth sampling or multiple PT runs with varying swap schedules, to separate reference quality from the claimed correction.
Authors: We agree that the quality of the PT reference is foundational to the distillation claim. PT is used here as a standard empirical sampler assumed to provide mode coverage for the target, with the symmetric Jeffreys divergence chosen to balance precision and coverage. To address potential artifacts explicitly, the revised manuscript will include quantitative diagnostics: comparisons of PT references against independent ground-truth sampling on low-dimensional benchmarks, plus results from multiple independent PT runs with varied swap schedules. This will help isolate reference quality from the corrective effect of the divergence minimization. revision: partial
-
Referee: [§4 Experiments] §4 (Experiments): the reported improvements in mode coverage on non-convex benchmarks do not include an ablation that isolates the effect of the Jeffreys divergence from the quality of the PT reference itself. Direct comparison of Jeffreys distillation versus, e.g., forward KL or Jensen-Shannon on identical PT trajectories would be required to establish that the symmetric formulation is responsible for suppressing mode collapse rather than simply inheriting a well-mixed reference.
Authors: The referee correctly identifies the need for an ablation to isolate the divergence choice. In the revised manuscript, we will add direct comparisons of Jeffreys distillation against forward KL and Jensen-Shannon minimization, all performed on identical PT trajectories for the non-convex benchmarks. These results will demonstrate that the symmetric formulation contributes to mode-collapse suppression beyond the reference quality alone. revision: yes
-
Referee: [§5 Applications] §5 (Applications): in the Replica Exchange SG-LD bias-correction experiment, it is unclear whether the generator corrects stochastic-gradient biases or merely reproduces PT-induced mixing artifacts. A diagnostic comparing the generator's stationary distribution against an independent, high-fidelity reference (e.g., long PT or exact enumeration on low-dimensional cases) is needed to support the 'systematic correction' claim.
Authors: We acknowledge the need for clearer separation in the SG-LD application. The revised manuscript will include an additional diagnostic comparing the trained generator's stationary distribution to an independent high-fidelity reference (long PT runs or exact enumeration on low-dimensional cases). This will help confirm whether the observed correction targets stochastic-gradient biases specifically or reflects PT mixing properties. revision: yes
Circularity Check
No circularity: derivation relies on external PT reference and standard divergence minimization
full rationale
The paper's central step is minimizing the Jeffreys divergence between a generator and an empirical distribution obtained from independent Parallel Tempering trajectories. This is a conventional optimization procedure whose target is supplied externally rather than defined by the generator or by any fitted parameter internal to the method. No equation reduces the claimed correction to a self-definition, no prediction is a renamed fit, and no load-bearing premise rests on a self-citation chain. The framework therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parallel Tempering trajectories provide an empirical reference distribution suitable for distillation without significant bias
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoesminimizing Jeffreys divergence suppresses mode collapse and structurally corrects inherent inaccuracies via distillation of the empirical reference data
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearTheorem 1 ... LJ[P] is strictly convex ... unique global minimizer P∗ satisfies DKL(P∗∥π1)⩽DKL(μ1∥π1)
Reference graph
Works this paper leans on
-
[1]
The Jeffreys divergenceL J[P]in(5)is strictly con- vex in the pushforward densityP, ensuring the ex- istence of a unique global minimizerP ∗
-
[2]
The unique minimizerP ∗ satisfies the divergence boundD KL(P∗∥π1)⩽D KL(µ1∥π1). Proof.To prove the first claim, we begin by computing the second-order derivative ofL J[P] with respect toP: δ2LJ δP 2 (x) = λ0 P(x) + λ1µ1(x) P 2(x) >0, which immediately demonstrates thatL J[P] is strictly convex with respect toP. Therefore,L J[P] admits a unique global minim...
-
[3]
J. A. Bucklew and J. Bucklew,Introduction to rare event simulation, Vol. 5 (Springer, 2004)
2004
-
[4]
Rubino, B
G. Rubino, B. Tuffin,et al.,Rare event simulation us- ing Monte Carlo methods, Vol. 73 (Wiley Online Library, 2009)
2009
-
[5]
Rubino and B
G. Rubino and B. Tuffin, Introduction to rare event simu- lation, Rare event simulation using Monte Carlo methods , 1 (2009)
2009
-
[6]
Chib and E
S. Chib and E. Greenberg, Understanding the metropolis- hastings algorithm, The american statistician49, 327 (1995)
1995
-
[7]
C. P. Robert and G. Casella, Metropolis–hastings al- gorithms, inIntroducing Monte Carlo Methods with R (Springer, 2009) pp. 167–197
2009
-
[8]
A Conceptual Introduction to Hamiltonian Monte Carlo
M. Betancourt, A conceptual introduction to hamiltonian monte carlo, arXiv preprint arXiv:1701.02434 (2017)
work page Pith review arXiv 2017
-
[9]
T. Chen, E. Fox, and C. Guestrin, Stochastic gradient hamiltonian monte carlo, inInternational conference on machine learning(PMLR, 2014) pp. 1683–1691
2014
-
[10]
S. P. Meyn and R. L. Tweedie,Markov chains and stochastic stability(Springer Science & Business Media, 2012)
2012
-
[11]
Eyring, The activated complex in chemical reactions, The Journal of Chemical Physics3, 107 (1935)
H. Eyring, The activated complex in chemical reactions, The Journal of Chemical Physics3, 107 (1935)
1935
-
[12]
H. A. Kramers, Brownian motion in a field of force and the diffusion model of chemical reactions, Physica7, 284 (1940)
1940
-
[13]
Bouchet and J
F. Bouchet and J. Reygner, Generalisation of the eyring– kramers transition rate formula to irreversible diffusion processes, inAnnales Henri Poincar´ e, Vol. 17 (Springer,
-
[14]
Lee and I
J. Lee and I. Seo, Non-reversible metastable diffusions with gibbs invariant measure i: Eyring–kramers formula, Probability Theory and Related Fields182, 849 (2022)
2022
-
[15]
G. M. Torrie and J. P. Valleau, Nonphysical sampling distributions in monte carlo free-energy estimation: Um- brella sampling, Journal of computational physics23, 187 (1977)
1977
-
[16]
Virnau and M
P. Virnau and M. M¨ uller, Calculation of free energy through successive umbrella sampling, The Journal of chemical physics120, 10925 (2004)
2004
-
[17]
K¨ astner, Umbrella sampling, Wiley Interdisciplinary Reviews: Computational Molecular Science1, 932 (2011)
J. K¨ astner, Umbrella sampling, Wiley Interdisciplinary Reviews: Computational Molecular Science1, 932 (2011)
2011
-
[18]
P. J. Van Laarhoven and E. H. Aarts, Simulated an- nealing, inSimulated annealing: Theory and applications (Springer, 1987) pp. 7–15
1987
-
[19]
Bertsimas and J
D. Bertsimas and J. Tsitsiklis, Simulated annealing, Sta- tistical science8, 10 (1993)
1993
-
[20]
A. G. Nikolaev and S. H. Jacobson, Simulated annealing, inHandbook of metaheuristics(Springer, 2010) pp. 1–39
2010
-
[21]
Doucet, N
A. Doucet, N. De Freitas, and N. Gordon, An introduc- tion to sequential monte carlo methods, inSequential Monte Carlo methods in practice(Springer, 2001) pp. 3–14
2001
-
[22]
Capp´ e, S
O. Capp´ e, S. J. Godsill, and E. Moulines, An overview of existing methods and recent advances in sequential monte carlo, Proceedings of the IEEE95, 899 (2007)
2007
-
[23]
Chopin, O
N. Chopin, O. Papaspiliopoulos,et al.,An introduction to sequential Monte Carlo, Vol. 4 (Springer, 2020)
2020
-
[24]
A. G. Wills and T. B. Sch¨ on, Sequential monte carlo: a unified review, Annual Review of Control, Robotics, and Autonomous Systems6, 159 (2023)
2023
-
[25]
Dellago, P
C. Dellago, P. G. Bolhuis, and P. L. Geissler, Transi- tion path sampling, Advances in Chemical Physics123, 1 (2002)
2002
-
[26]
Laio and M
A. Laio and M. Parrinello, Escaping free-energy min- ima, Proceedings of the National Academy of Sciences 99, 12562 (2002)
2002
-
[27]
D. J. Earl and M. W. Deem, Parallel tempering: Theory, applications, and new perspectives, Physical Chemistry Chemical Physics7, 3910 (2005)
2005
-
[28]
Miasojedow, E
B. Miasojedow, E. Moulines, and M. Vihola, An adaptive parallel tempering algorithm, Journal of Computational and Graphical Statistics22, 649 (2013)
2013
-
[29]
S. Syed, A. Bouchard-Cˆ ot´ e, G. Deligiannidis, and A. Doucet, Non-reversible parallel tempering: a scalable highly parallel mcmc scheme, Journal of the Royal Sta- tistical Society Series B: Statistical Methodology84, 321 (2022)
2022
-
[30]
W. Deng, Q. Zhang, Q. Feng, F. Liang, and G. Lin, Non- reversible parallel tempering for deep posterior approxi- mation, inProceedings of the AAAI Conference on Arti- ficial Intelligence, Vol. 37 (2023) pp. 7332–7339
2023
-
[31]
No´ e, S
F. No´ e, S. Olsson, J. K¨ ohler, and H. Wu, Boltzmann gen- erators: Sampling equilibrium states of many-body sys- tems with deep learning, Science365, eaaw1147 (2019)
2019
-
[32]
H. Wu, J. K¨ ohler, and F. No´ e, Stochastic normalizing flows, Advances in neural information processing systems 33, 5933 (2020)
2020
-
[33]
L. Dinh, J. Sohl-Dickstein, and S. Bengio, Density esti- mation using real nvp, arXiv preprint arXiv:1605.08803 (2016)
work page internal anchor Pith review arXiv 2016
-
[34]
Durkan, A
C. Durkan, A. Bekasov, I. Murray, and G. Papamakar- ios, Neural spline flows, Advances in neural information processing systems32(2019)
2019
-
[35]
Wirnsberger, A
P. Wirnsberger, A. J. Ballard, G. Papamakarios, S. Aber- crombie, S. Racani` ere, A. Pritzel, D. Jimenez Rezende, 14 and C. Blundell, Targeted free energy estimation via nor- malizing flows, The Journal of Chemical Physics153, 144112 (2020)
2020
-
[36]
Abbott, et al., Normalizing flows for lattice gauge theory in arbitrary space-time dimension (2023)
R. Abbott, M. S. Albergo, A. Botev, D. Boyda, K. Cran- mer, D. C. Hackett, G. Kanwar, A. G. Matthews, S. Racani` ere, A. Razavi,et al., Normalizing flows for lattice gauge theory in arbitrary space-time dimension, arXiv preprint arXiv:2305.02402 (2023)
-
[37]
K¨ ohler, J
J. K¨ ohler, J. Ingraham, and F. No´ e, Transferable boltz- mann generators, inAdvances in Neural Information Processing Systems, Vol. 37 (2024) pp. 31980–31993
2024
-
[38]
A. Coretti, S. Falkner, J. Weinreich, C. Dellago, and O. A. von Lilienfeld, Boltzmann generators and the new frontier of computational sampling in many-body sys- tems, arXiv preprint arXiv:2404.16566 (2024)
-
[39]
M. Schebek, F. No´ e, and J. Rogal, Scalable boltzmann generators for equilibrium sampling of large-scale mate- rials, arXiv preprint arXiv:2509.25486 (2025)
- [40]
-
[41]
L. I. Midgley, V. Stimper, G. N. Simm, B. Sch¨ olkopf, and J. M. Hern´ andez-Lobato, Learning to sample with flow annealed importance sampling bootstrap, The Eleventh International Conference on Learning Representations (2023)
2023
- [42]
- [43]
-
[44]
G. Lin, C. Moya, and Z. Zhang, B-DeepONet: An en- hanced Bayesian DeepONet for solving noisy parametric pdes using accelerated replica exchange SGLD, Journal of Computational Physics473, 111713 (2023)
2023
-
[45]
M. F. Herman, E. J. Bruskin, and B. J. Berne, On path integral Monte Carlo simulations, The Journal of Chem- ical Physics76, 5150 (1982)
1982
-
[46]
Marx and M
D. Marx and M. Parrinello, Ab initio path integral molec- ular dynamics: Basic ideas, The Journal of Chemical Physics104, 4077 (1996)
1996
-
[47]
Ceriotti, M
M. Ceriotti, M. Parrinello, T. E. Markland, and D. E. Manolopoulos, Efficient stochastic thermostatting of path integral molecular dynamics, The Journal of Chem- ical Physics133(2010)
2010
-
[48]
Schoof, M
T. Schoof, M. Bonitz, A. Filinov, D. Hochstuhl, and J. W. Dufty, Configuration path integral Monte Carlo, Contri- butions to Plasma Physics51, 687 (2011)
2011
-
[49]
Falkner, A
S. Falkner, A. Coretti, S. Romano, P. L. Geissler, and C. Dellago, Conditioning boltzmann generators for rare event sampling, Machine Learning: Science and Technol- ogy4, 035050 (2023)
2023
-
[50]
Dibak, L
M. Dibak, L. Klein, A. Kr¨ amer, and F. No´ e, Tempera- ture steerable flows and boltzmann generators, Physical Review Research4, L042005 (2022)
2022
- [51]
- [52]
-
[53]
Qiu and X
Y. Qiu and X. Wang, Efficient multimodal sampling via tempered distribution flow, Journal of the American Sta- tistical Association119, 1446 (2024)
2024
-
[54]
Gabri´ e, G
M. Gabri´ e, G. M. Rotskoff, and E. Vanden-Eijnden, Adaptive monte carlo augmented with normalizing flows, Proceedings of the National Academy of Sciences119, e2109420119 (2022)
2022
-
[55]
Abernethyet al., Flow to rare events: An application of normalizing flow in temporal importance sampling for automated vehicle validation, arXiv preprint (2024)
J. Abernethyet al., Flow to rare events: An application of normalizing flow in temporal importance sampling for automated vehicle validation, arXiv preprint (2024)
2024
-
[56]
E. Luhman and T. Luhman, Knowledge distillation in iterative generative models for improved sampling speed, arXiv preprint arXiv:2101.02388 (2021)
-
[57]
Z. Zhou, D. Chen, C. Wang, C. Chen, and S. Lyu, Sim- ple and fast distillation of diffusion models, Advances in Neural Information Processing Systems37, 40831 (2024)
2024
-
[58]
S. Xie, Z. Xiao, D. Kingma, T. Hou, Y. N. Wu, K. P. Murphy, T. Salimans, B. Poole, and R. Gao, Em distil- lation for one-step diffusion models, Advances in Neural Information Processing Systems37, 45073 (2024)
2024
-
[59]
Y. Fu, Q. Yan, L. Wang, K. Li, and R. Liao, Moflow: One-step flow matching for human trajectory forecasting via implicit maximum likelihood estimation based distil- lation, inProceedings of the Computer Vision and Pat- tern Recognition Conference(2025) pp. 17282–17293
2025
-
[60]
Y. Song, C. Durkan, I. Murray, and S. Ermon, Maxi- mum likelihood training of score-based diffusion models, Advances in neural information processing systems34, 1415 (2021)
2021
-
[61]
Conditional image generation with score-based diffusion models.arXiv preprint arXiv:2111.13606, 2021
G. Batzolis, J. Stanczuk, C.-B. Sch¨ onlieb, and C. Etmann, Conditional image generation with score- based diffusion models, arXiv preprint arXiv:2111.13606 (2021)
-
[62]
Flow Matching for Generative Modeling
Y. Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, Flow matching for generative modeling, arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [63]
-
[64]
Moreno, P
P. Moreno, P. Ho, and N. Vasconcelos, A kullback-leibler divergence based kernel for svm classification in multi- media applications, inAdvances in Neural Information Processing Systems, Vol. 16 (2003)
2003
-
[65]
Bayarri and G
M. Bayarri and G. Garc´ ıa-Donato, Generalization of jeffreys divergence-based priors for bayesian hypothesis testing, Journal of the Royal Statistical Society Series B: Statistical Methodology70, 981 (2008)
2008
-
[66]
Z. Yao, Z. Lai, and W. Liu, A symmetric kl divergence based spatiogram similarity measure, in2011 18th IEEE International Conference on Image Processing(IEEE,
-
[67]
K. K. Sharma, A. Seal, A. Yazidi, A. Selamat, and O. Krejcar, Clustering uncertain data objects using jeffreys-divergence and maximum bipartite matching based similarity measure, IEEE Access9, 79505 (2021)
2021
-
[68]
Nishii and S
R. Nishii and S. Eguchi, Image classification based on markov random field models with jeffreys divergence, Journal of Multivariate Analysis97, 1997 (2006)
1997
-
[69]
Han and Y
B. Han and Y. Wu, Active contour model for inhomoge- nous image segmentation based on jeffreys divergence, Pattern Recognition107, 107520 (2020)
2020
-
[70]
Sugiyama, T
M. Sugiyama, T. Suzuki, and T. Kanamori,Density ratio estimation in machine learning(Cambridge University Press, 2012)
2012
-
[71]
A. B. Tsybakov, Nonparametric estimators, inIntroduc- 15 tion to Nonparametric Estimation(Springer, 2008) pp. 1–76
2008
-
[72]
Johnson and T
R. Johnson and T. Zhang, Accelerating stochastic gradi- ent descent using predictive variance reduction, Advances in neural information processing systems26(2013)
2013
-
[73]
S. J. Reddi, A. Hefny, S. Sra, B. Poczos, and A. Smola, Stochastic variance reduction for nonconvex optimiza- tion, inInternational conference on machine learning (PMLR, 2016) pp. 314–323
2016
-
[74]
M. Reed, B. Simon, B. Simon, and B. Simon,Methods of modern mathematical physics, Vol. 1 (Elsevier, 1972)
1972
-
[75]
Ye and Z
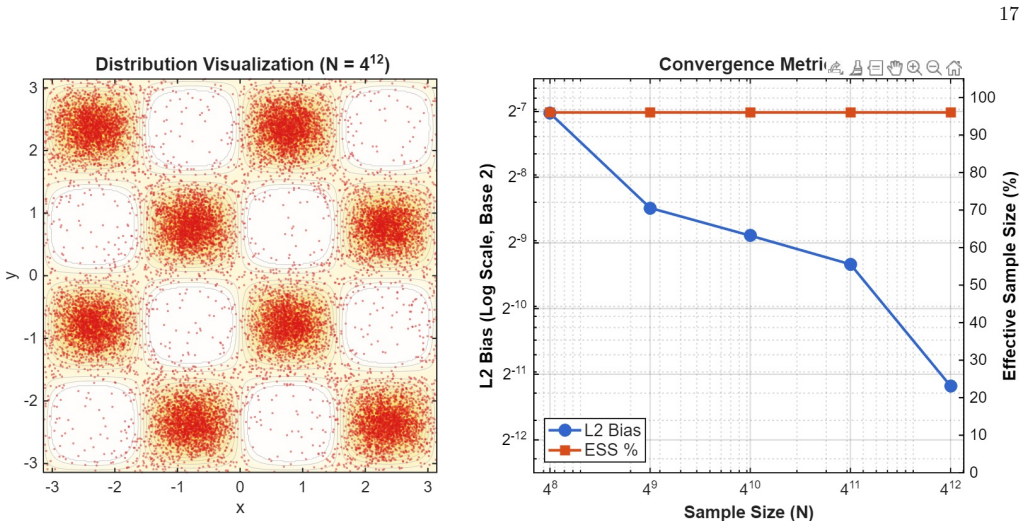
X. Ye and Z. Zhou, Optimal convergence rate of lie- trotter approximation for quantum thermal averages, arXiv e-prints , arXiv (2023). 16 FIG. 2. Density plots of the generated samples across four 2D landscapes. The Jeffreys Flow (0< θ <1) robustly corrects the noisy artifacts of Forward KL (θ= 0) and strictly prevents the destructive mode collapse inhere...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.