Recognition: 2 theorem links
· Lean TheoremVLA-InfoEntropy: A Training-Free Vision-Attention Information Entropy Approach for Vision-Language-Action Models Inference Acceleration and Success
Pith reviewed 2026-05-10 18:29 UTC · model grok-4.3
The pith
Image and attention entropy scores let VLA models prune redundant visual tokens during inference while keeping action success rates intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
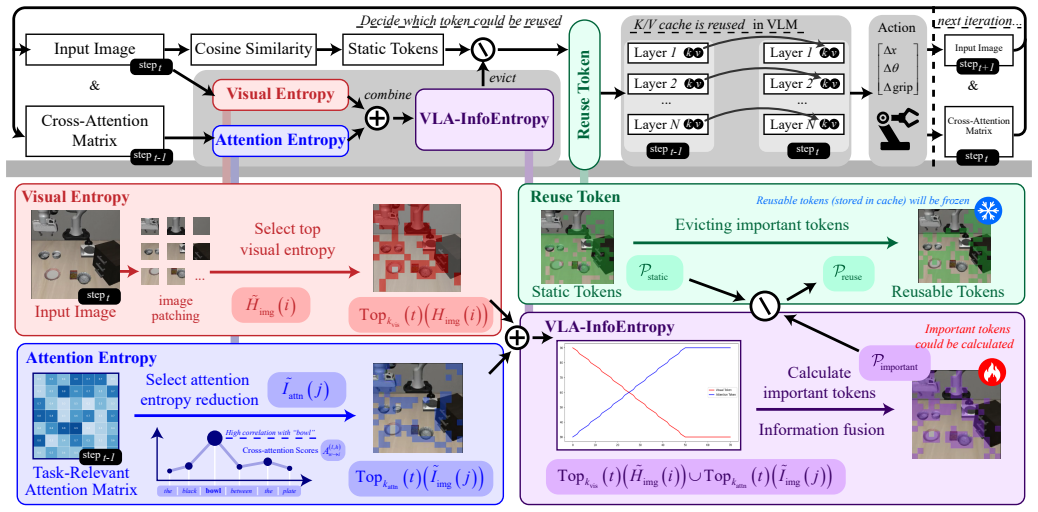
The VLA-InfoEntropy method integrates spatial cues from image entropy, semantic cues from attention entropy over task-related text, and temporal cues from timestep information to create a dynamic transition strategy that moves the model from global visual features to attention-guided local informative regions, reducing redundancy while preserving critical content for action decisions.
What carries the argument
The dynamic transition strategy that combines image entropy for texture-rich regions, attention entropy for semantically relevant tokens, and timestep information to select a reduced set of visual tokens at each step.
If this is right
- The number of active parameters during inference decreases.
- Inference speed increases while action success rates stay the same or rise.
- The method works on existing VLA models without any retraining.
- It outperforms prior acceleration techniques on standard benchmarks.
Where Pith is reading between the lines
- The same entropy signals could be adapted to trim computation in other vision-language or embodied models that face similar token overload.
- Hardware-constrained robots might run longer sequences or more frequent decisions once global features are replaced by entropy-selected local ones.
- Further tests on long-horizon tasks with changing environments would show whether the timestep cue remains sufficient when task-critical regions shift rapidly.
Load-bearing premise
That image entropy and attention entropy, when added to timestep information, will always flag the exact visual content needed for the current action without missing details that lower success rates.
What would settle it
Running the pruned model on a benchmark where success drops noticeably compared with the full model on tasks that require scattered or low-entropy but still essential visual details.
Figures



read the original abstract
Vision-Language-Action (VLA) models integrate visual perception, language understanding, and action decision-making for cross-modal semantic alignment, exhibiting broad application potential. However, the joint processing of high-dimensional visual features, complex linguistic inputs, and continuous action sequences incurs significant computational overhead and low inference efficiency, thereby hindering real-time deployment and reliability. To address this issue, we use image entropy to quantify the grayscale distribution characteristics of each visual token and introduce attention entropy to capture the distribution of attention scores over task-related text. Visual entropy identifies texture-rich or structurally informative regions, while attention entropy pinpoints semantically relevant tokens. Combined with timestep information, these metrics enable a dynamic transition strategy that shifts the model's focus from global visual features to attention-guided local informative regions. Thus, the resulting VLA-InfoEntropy method integrates spatial, semantic, and temporal cues to reduce redundancy while preserving critical content. Extensive experiments show that our method reduces inference parameters, accelerates inference speed, and outperforms existing approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents VLA-InfoEntropy, a training-free technique for accelerating inference in Vision-Language-Action models. It employs image entropy to measure the information content in visual tokens based on their grayscale distributions and attention entropy to assess the distribution of attention scores on task-related textual tokens. By integrating these with timestep data, it proposes a dynamic focus strategy that transitions from global visual features to local informative regions, thereby reducing computational redundancy while preserving critical semantic and action-relevant content. The abstract asserts that extensive experiments demonstrate reductions in inference parameters, faster inference, and superior performance compared to existing methods.
Significance. Should the method prove effective in maintaining task success rates while achieving the claimed efficiency gains, it would represent a valuable contribution to the field by enabling more practical deployment of VLA models in resource-constrained or real-time settings. The training-free aspect avoids the computational expense of retraining and could be broadly applicable.
major comments (1)
- [Abstract] Abstract: The assertion that 'Extensive experiments show that our method reduces inference parameters, accelerates inference speed, and outperforms existing approaches' supplies no quantitative results (e.g., success-rate deltas, inference-time reductions, parameter counts, baseline comparisons, or error bars). This is load-bearing for the central claim because the utility of the entropy-based token selection rests on demonstrating no drop in action success rate across tasks.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work's significance and for the constructive feedback on the abstract. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'Extensive experiments show that our method reduces inference parameters, accelerates inference speed, and outperforms existing approaches' supplies no quantitative results (e.g., success-rate deltas, inference-time reductions, parameter counts, baseline comparisons, or error bars). This is load-bearing for the central claim because the utility of the entropy-based token selection rests on demonstrating no drop in action success rate across tasks.
Authors: We agree that the abstract would be strengthened by including specific quantitative results to support the claims. The full manuscript (Section 4) reports detailed experiments across multiple VLA benchmarks, showing that VLA-InfoEntropy maintains task success rates (with no statistically significant drop relative to the unpruned baseline) while achieving measurable reductions in inference parameters and latency, outperforming prior token-pruning baselines. To address the concern directly, we will revise the abstract to incorporate key quantitative metrics from our results, including success-rate preservation, inference-time speedups, parameter reductions, and baseline comparisons. revision: yes
Circularity Check
No significant circularity; heuristic method uses standard entropy formulas without reduction to inputs by construction.
full rationale
The paper presents VLA-InfoEntropy as a training-free heuristic that applies standard image entropy (grayscale distribution per visual token) and attention entropy (over task-related text), combined with timestep, to enable dynamic token selection. No equations, derivations, or claims in the provided text reduce the method's predictions or success metrics to fitted parameters, self-definitions, or self-citation chains. The approach relies on externally defined entropy calculations rather than ansatzes or uniqueness theorems imported from the authors' prior work. Central claims of inference acceleration and preserved action success are framed as empirical outcomes, not tautological results. This is the common case of a self-contained heuristic with independent content.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Image entropy on grayscale tokens identifies texture-rich or structurally informative visual regions.
- domain assumption Attention entropy over task-related text tokens identifies semantically relevant linguistic cues.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearHimg(i)=−∑pi(g)log2pi(g) … eIattn(i)=1−Hattn(i)/log2|W| … Pimportant(t)=Topkvis(t)(eHimg(i))∪Topkattn(t)(eIattn(j)) with α=t/T
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and orbit embedding uncleartimestep-aware dynamic transition … from global visual context to task-driven local evidence
Reference graph
Works this paper leans on
-
[1]
A comprehensive survey on embodied intelligence: Advancements, challenges, and future perspectives,
Fuchun Sun, Runfa Chen, Tianying Ji, Yu Luo, Huaidong Zhou, and Huaping Liu, “A comprehensive survey on embodied intelligence: Advancements, challenges, and future perspectives,”CAAI Artificial Intelligence Research, vol. 3, pp. 9150042, 2024
2024
-
[2]
A survey of embodied ai: From simulators to research tasks,
Jiafei Duan, Samson Yu, Hui Li Tan, Hongyuan Zhu, and Cheston Tan, “A survey of embodied ai: From simulators to research tasks,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 6, no. 2, pp. 230–244, 2022
2022
-
[3]
Large language models for robotics: Opportunities, challenges, and perspectives,
Jiaqi Wang, Enze Shi, Huawen Hu, Chong Ma, Yiheng Liu, Xuhui Wang, Yincheng Yao, Xuan Liu, Bao Ge, and Shu Zhang, “Large language models for robotics: Opportunities, challenges, and perspectives,”Jour- nal of Automation and Intelligence, vol. 4, no. 1, pp. 52–64, 2025
2025
-
[4]
A survey of embodied learning for object-centric robotic manipulation,
Ying Zheng, Lei Yao, Yuejiao Su, Yi Zhang, Yi Wang, Sicheng Zhao, Yiyi Zhang, and Lap-Pui Chau, “A survey of embodied learning for object-centric robotic manipulation,”Machine Intelligence Research, pp. 1–39, 2025
2025
-
[5]
Advanc- ing embodied intelligence in robotic-assisted endovascular procedures: A systematic review of ai solutions,
Tianliang Yao, Bo Lu, Markus Kowarschik, Yixuan Yuan, Hubin Zhao, Sebastien Ourselin, Kaspar Althoefer, Junbo Ge, and Peng Qi, “Advanc- ing embodied intelligence in robotic-assisted endovascular procedures: A systematic review of ai solutions,”IEEE Reviews in Biomedical Engineering, 2025
2025
-
[6]
Foundation models in robotics: Applications, challenges, and the future,
Roya Firoozi, Johnathan Tucker, Stephen Tian, Anirudha Majumdar, Jiankai Sun, Weiyu Liu, Yuke Zhu, Shuran Song, Ashish Kapoor, Karol Hausman, et al., “Foundation models in robotics: Applications, challenges, and the future,”The International Journal of Robotics Research, vol. 44, no. 5, pp. 701–739, 2025
2025
-
[7]
Em- bodied intelligence toward future smart manufacturing in the era of ai foundation model,
Lei Ren, Jiabao Dong, Shuai Liu, Lin Zhang, and Lihui Wang, “Em- bodied intelligence toward future smart manufacturing in the era of ai foundation model,”IEEE/ASME Transactions on Mechatronics, 2024
2024
-
[8]
VLA-cache: Efficient vision-language-action manipulation via adaptive token caching,
Siyu Xu, Yunke Wang, Chenghao Xia, Dihao Zhu, Tao Huang, and Chang Xu, “VLA-cache: Efficient vision-language-action manipulation via adaptive token caching,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[9]
Titong Jiang, Xuefeng Jiang, Yuan Ma, Xin Wen, Bailin Li, Kun Zhan, Peng Jia, Yahui Liu, Sheng Sun, and Xianpeng Lang, “The better you learn, the smarter you prune: Towards efficient vision- language-action models via differentiable token pruning,”arXiv preprint arXiv:2509.12594, 2025
-
[10]
Xudong Tan, Yaoxin Yang, Peng Ye, Jialin Zheng, Bizhe Bai, Xinyi Wang, Jia Hao, and Tao Chen, “Think twice, act once: Token-aware compression and action reuse for efficient inference in vision-language- action models,”arXiv preprint arXiv:2505.21200, 2025
-
[11]
SP-VLA: A joint model scheduling and token pruning approach for VLA model acceleration,
Ye Li, Yuan Meng, Zewen Sun, Kangye Ji, Chen Tang, Jiajun Fan, Xinzhu Ma, Shu-Tao Xia, Zhi Wang, and Wenwu Zhu, “SP-VLA: A joint model scheduling and token pruning approach for VLA model acceleration,” inInternational Conference on Learning Representations, 2026
2026
-
[12]
On the consistency of video large language models in temporal comprehen- sion,
Minjoon Jung, Junbin Xiao, Byoung-Tak Zhang, and Angela Yao, “On the consistency of video large language models in temporal comprehen- sion,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 13713–13722
2025
-
[13]
Rt-1: Robotics transformer for real-world control at scale,
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alexander Herzog, Jasmine Hsu, et al., “Rt-1: Robotics transformer for real-world control at scale,” inRobotics: Science and Systems, 2023
2023
-
[14]
Rt- 2: Vision-language-action models transfer web knowledge to robotic control,
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al., “Rt- 2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165– 2183
2023
-
[15]
Diffusion policy: Visuomotor policy learning via action diffusion,
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[16]
Diffusionvla: Scaling robot foundation models via unified diffusion and autoregression,
Junjie Wen, Yichen Zhu, Minjie Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Xiaoyu Liu, Chaomin Shen, Yaxin Peng, and Feifei Feng, “Diffusionvla: Scaling robot foundation models via unified diffusion and autoregression,” inInternational Conference on Machine Learning, 2025
2025
-
[17]
π 0: A vision-language-action flow model for general robot control,
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al., “π 0: A vision-language-action flow model for general robot control,” inRobotics: Science and Systems, 2025
2025
-
[18]
π 0.5: A vision-language-action model with open- world generalization,
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, et al., “π 0.5: A vision-language-action model with open- world generalization,” inConference on Robot Learning, 2025, vol. 305, pp. 17–40
2025
-
[19]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Casta ˜neda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al., “Gr00t n1: An open foundation model for generalist humanoid robots,”arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review arXiv 2025
-
[20]
Understanding world or predicting future? a comprehensive survey of world models,
Jingtao Ding, Yunke Zhang, Yu Shang, Yuheng Zhang, Zefang Zong, Jie Feng, Yuan Yuan, Hongyuan Su, Nian Li, Nicholas Sukiennik, et al., “Understanding world or predicting future? a comprehensive survey of world models,”ACM Computing Surveys, vol. 58, no. 3, pp. 1–38, 2025
2025
-
[21]
Dreamvla: A vision-language-action model dreamed with comprehensive world knowledge,
Wenyao Zhang, Hongsi Liu, Zekun Qi, Yunnan Wang, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, He Wang, Zhizheng Zhang, Li Yi, Wenjun Zeng, and Xin Jin, “Dreamvla: A vision-language-action model dreamed with comprehensive world knowledge,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[22]
Fine-tuning vision- language-action models: Optimizing speed and success,
Moo Jin Kim, Chelsea Finn, and Percy Liang, “Fine-tuning vision- language-action models: Optimizing speed and success,” inRobotics: Science and Systems, 2025
2025
-
[23]
PD-VLA: Accelerating vision-language-action model integrated with action chunking via parallel decoding,
Wenxuan Song, Jiayi Chen, Pengxiang Ding, Han Zhao, Wei Zhao, Zhide Zhong, Zongyuan Ge, Zhijun Li, Donglin Wang, Lujia Wang, et al., “PD-VLA: Accelerating vision-language-action model integrated with action chunking via parallel decoding,” in2025 IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 13162–13169
2025
-
[24]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine, “Fast: Efficient action tokenization for vision-language-action models,”arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review arXiv 2025
-
[25]
Wenxuan Song, Jiayi Chen, Pengxiang Ding, Yuxin Huang, Han Zhao, Donglin Wang, and Haoang Li, “CEED-VLA: Consistency vision- language-action model with early-exit decoding,”arXiv preprint arXiv:2506.13725, 2025
-
[26]
SparseVLM: Visual token sparsification for efficient vision-language model inference,
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis A Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al., “SparseVLM: Visual token sparsification for efficient vision-language model inference,” inInternational Conference on Machine Learning, 2025
2025
-
[27]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models,
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang, “An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 19–35
2024
-
[28]
EfficientVLA: Training-free acceleration and compression for vision-language-action models,
Yantai Yang, Yuhao Wang, Zichen Wen, Luo Zhongwei, Chang Zou, Zhipeng Zhang, Chuan Wen, and Linfeng Zhang, “EfficientVLA: Training-free acceleration and compression for vision-language-action models,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[29]
DeeR-VLA: Dynamic inference of multimodal large language models for efficient robot execution,
Yang Yue, Yulin Wang, Bingyi Kang, Yizeng Han, Shenzhi Wang, Shiji Song, Jiashi Feng, and Gao Huang, “DeeR-VLA: Dynamic inference of multimodal large language models for efficient robot execution,” Advances in Neural Information Processing Systems, vol. 37, pp. 56619– 56643, 2024
2024
-
[30]
A mathematical theory of communication,
Claude Elwood Shannon, “A mathematical theory of communication,” The Bell System Technical Journal, vol. 27, no. 3, pp. 379–423, 1948
1948
-
[31]
A new method for gray-level picture thresholding using the entropy of the histogram,
Jagat Narain Kapur, Prasanna K Sahoo, and Andrew KC Wong, “A new method for gray-level picture thresholding using the entropy of the histogram,”Computer Vision, Graphics, and Image Processing, vol. 29, no. 3, pp. 273–285, 1985
1985
-
[32]
Open- VLA: An open-source vision-language-action model,
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R San- keti, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn, “Open- VLA: An open-source vision-language-action model,” inConference on Robot Learning, 20...
2025
-
[33]
Spec-VLA: speculative decoding for vision-language-action models with relaxed acceptance,
Songsheng Wang, Rucheng Yu, Zhihang Yuan, Chao Yu, Feng Gao, Yu Wang, and Derek F Wong, “Spec-VLA: speculative decoding for vision-language-action models with relaxed acceptance,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 26916–26928
2025
-
[34]
LIBERO: Benchmarking knowledge transfer for lifelong robot learning,
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone, “LIBERO: Benchmarking knowledge transfer for lifelong robot learning,”Advances in Neural Information Processing Systems, vol. 36, pp. 44776–44791, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.