Recognition: no theorem link
Data-Driven Function Calling Improvements in Large Language Model for Online Financial QA
Pith reviewed 2026-05-10 19:21 UTC · model grok-4.3
The pith
A periodically updated dataset with parameter augmentation and two-step training lets large language models call financial APIs more reliably.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
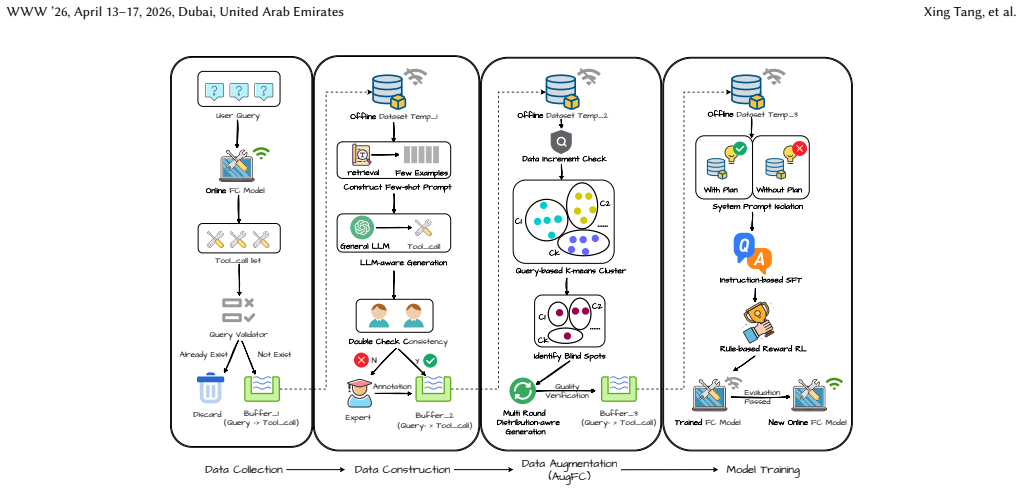
The authors claim that a data-driven pipeline of periodic dataset construction, incorporation of user queries, augmentation that explores possible parameter values, and two-step training enables an LLM to exploit a set of financial functions, with the resulting gains visible both in offline dataset tests and in actual online deployment.
What carries the argument
The pipeline of periodic dataset updates that incorporate the AugFC augmentation method, followed by two-step training on function-calling examples.
If this is right
- The updated dataset lets the model draw on the financial toolset through data rather than manual rules.
- AugFC increases the range of parameter values the model sees, reducing errors on unusual inputs.
- The two-step training process produces a model that can decide both which function to call and how to format its inputs.
- The same pipeline has been placed into live operation for an online financial question-answering service.
Where Pith is reading between the lines
- The same maintenance loop of periodic updates plus augmentation could be tried in other domains that rely on many private APIs and variable user phrasing.
- Because the method depends on ongoing collection of real queries, it implies that production systems will need continuous data pipelines rather than one-time training.
- The two-step training may serve as a lighter alternative to full retraining when new functions are added to the toolset.
Load-bearing premise
The assumption that regularly adding real user queries and generating extra parameter examples will prepare the model to handle every kind of financial question that appears online.
What would settle it
A clear rise in wrong function selections or outright failures when the deployed system meets user questions whose parameter values fall outside the examples seen during training.
Figures





read the original abstract
Large language models (LLMs) have been incorporated into numerous industrial applications. Meanwhile, a vast array of API assets is scattered across various functions in the financial domain. An online financial question-answering system can leverage both LLMs and private APIs to provide timely financial analysis and information. The key is equipping the LLM model with function calling capability tailored to a financial scenario. However, a generic LLM requires customized financial APIs to call and struggles to adapt to the financial domain. Additionally, online user queries are diverse and contain out-of-distribution parameters compared with the required function input parameters, which makes it more difficult for a generic LLM to serve online users. In this paper, we propose a data-driven pipeline to enhance function calling in LLM for our online, deployed financial QA, comprising dataset construction, data augmentation, and model training. Specifically, we construct a dataset based on a previous study and update it periodically, incorporating queries and an augmentation method named AugFC. The addition of user query-related samples will \textit{exploit} our financial toolset in a data-driven manner, and AugFC explores the possible parameter values to enhance the diversity of our updated dataset. Then, we train an LLM with a two-step method, which enables the use of our financial functions. Extensive experiments on existing offline datasets, as well as the deployment of an online scenario, illustrate the superiority of our pipeline. The related pipeline has been adopted in the financial QA of YuanBao\footnote{https://yuanbao.tencent.com/chat/}, one of the largest chat platforms in China.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a data-driven pipeline to enhance function calling in LLMs for an online financial QA system. The pipeline consists of periodic dataset construction based on a prior study, augmentation with the AugFC method to explore parameter values and increase diversity (including OOD cases), and two-step model training to enable use of financial functions. The authors claim this yields superior performance on existing offline datasets and in a live online deployment, with the pipeline now adopted in the YuanBao financial QA platform.
Significance. If the empirical claims are substantiated, the work offers a practical, deployable approach for adapting LLMs to private financial APIs while handling diverse and out-of-distribution user queries through data augmentation and periodic updates. The reported production adoption in YuanBao constitutes a concrete strength, demonstrating feasibility in a high-stakes industrial setting.
major comments (2)
- [Abstract] Abstract: the superiority claim is asserted on the basis of 'extensive experiments on existing offline datasets, as well as the deployment of an online scenario,' yet no metrics, baselines, ablation results, or quantitative handling of out-of-distribution parameters are supplied. This prevents evaluation of the data-to-claim link.
- [Pipeline description] Dataset construction and augmentation section (presumably §3): the central premise that the periodically updated dataset plus AugFC augmentation sufficiently covers the diversity and out-of-distribution parameters of real online user queries is stated at a high level but is not supported by distribution statistics, coverage metrics, or failure-mode analysis comparing the augmented data against logged production queries. This coverage assumption is load-bearing for both the two-step training and the offline/online superiority claims.
minor comments (2)
- [Abstract / Dataset construction] The reference to 'a previous study' for the base dataset is not accompanied by a citation; add the appropriate reference.
- [Augmentation method] Clarify the exact definition and implementation of AugFC (e.g., via pseudocode or parameter sampling procedure) to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the two major comments point by point below. Where the comments correctly identify gaps in quantitative support, we agree to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the superiority claim is asserted on the basis of 'extensive experiments on existing offline datasets, as well as the deployment of an online scenario,' yet no metrics, baselines, ablation results, or quantitative handling of out-of-distribution parameters are supplied. This prevents evaluation of the data-to-claim link.
Authors: We agree that the abstract would benefit from explicit quantitative anchors. In the revised manuscript we will insert the key offline metrics (e.g., function-calling accuracy and parameter-match F1 versus the strongest baselines), a one-sentence ablation summary, and a brief statement on how AugFC increases coverage of OOD parameter values. These numbers are already present in §4 and §5; moving a concise subset into the abstract will directly address the data-to-claim concern without altering the claims themselves. revision: yes
-
Referee: [Pipeline description] Dataset construction and augmentation section (presumably §3): the central premise that the periodically updated dataset plus AugFC augmentation sufficiently covers the diversity and out-of-distribution parameters of real online user queries is stated at a high level but is not supported by distribution statistics, coverage metrics, or failure-mode analysis comparing the augmented data against logged production queries. This coverage assumption is load-bearing for both the two-step training and the offline/online superiority claims.
Authors: The referee correctly notes that §3 currently describes the construction and AugFC procedure at a high level without supporting statistics. We will add a new paragraph (or short subsection) that reports (i) parameter-value coverage before and after augmentation, (ii) diversity metrics such as unique parameter combinations and entropy, and (iii) a high-level comparison against a sample of anonymized production query logs. Because raw production logs are subject to privacy constraints, the comparison will use aggregated statistics rather than raw failure cases; we believe this still substantiates the coverage claim while remaining compliant. revision: yes
Circularity Check
No circularity in empirical pipeline construction
full rationale
The paper describes a practical data-driven pipeline for enhancing LLM function calling in financial QA: periodic dataset updates from a prior study, AugFC augmentation for parameter diversity, and two-step training. No mathematical derivations, equations, or fitted parameters are presented that reduce to the inputs by construction. Claims of superiority rest on external experiments using offline datasets and online deployment results, which are independent of the construction process. Any reference to a previous study for initial dataset construction does not create circularity, as the method adds updates and augmentation explicitly and evaluates outcomes against separate benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Lada A Adamic and Bernardo A Huberman. 2000. Power-law distribution of the world wide web.science287, 5461 (2000), 2115–2115
2000
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[5]
Jian Chen, Peilin Zhou, Yining Hua, Loh Xin, Kehui Chen, Ziyuan Li, Bing Zhu, and Junwei Liang. 2024. FinTextQA: A Dataset for Long-form Financial Question Answering. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 6025–6047
2024
- [6]
-
[7]
Sorouralsadat Fatemi and Yuheng Hu. 2024. Enhancing Financial Question Answering with a Multi-Agent Reflection Framework. InProceedings of the 5th ACM International Conference on AI in Finance(Brooklyn, NY, USA)(ICAIF ’24). Association for Computing Machinery, 530–537
2024
-
[8]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al . 2025. DeepSeek-R1 in- centivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (2025), 633–638
2025
- [9]
-
[10]
Bingguang Hao, Maolin Wang, Zengzhuang Xu, Cunyin Peng, Yicheng Chen, Xiangyu Zhao, Jinjie Gu, and Chenyi Zhuang. 2025. FunReason: Enhancing Large Language Models’ Function Calling via Self-Refinement Multiscale Loss and Automated Data Refinement.arXiv preprint arXiv:2505.20192(2025)
-
[11]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[12]
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. 2023. API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 3102–3116
2023
-
[13]
Qiqiang Lin, Muning Wen, Qiuying Peng, Guanyu Nie, Junwei Liao, Jun Wang, Xiaoyun Mo, Jiamu Zhou, Cheng Cheng, Yin Zhao, Jun Wang, and Weinan Zhang
-
[14]
InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025
Robust Function-Calling for On-Device Language Model via Function Masking. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net
2025
-
[15]
Weiwen Liu, Xu Huang, Xingshan Zeng, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Zhengying Liu, Yuanqing Yu, Zezhong WANG, et al . [n. d.]. ToolACE: Winning the Points of LLM Function Calling. InThe Thirteenth International Conference on Learning Representations
-
[16]
Zuxin Liu, Thai Hoang, Jianguo Zhang, Ming Zhu, Tian Lan, Shirley Kokane, Juntao Tan, Weiran Yao, Zhiwei Liu, Yihao Feng, Rithesh Murthy, Liangwei Yang, Silvio Savarese, Juan Carlos Niebles, Huan Wang, Shelby Heinecke, and Caiming Xiong. 2024. APIGen: Automated PIpeline for Generating Verifiable and Diverse Function-Calling Datasets. InAdvances in Neural ...
2024
-
[17]
Zhuang Liu, Degen Huang, Kaiyu Huang, Zhuang Li, and Jun Zhao. 2020. Fin- BERT: A Pre-trained Financial Language Representation Model for Financial Text Mining. InProceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020. ijcai.org, 4513–4519
2020
- [18]
-
[19]
Karmvir Singh Phogat, Chetan Harsha, Sridhar Dasaratha, Shashishekar Ra- makrishna, and Sai Akhil Puranam. 2023. Zero-Shot Question Answering over Financial Documents using Large Language Models.CoRRabs/2311.14722 (2023). https://doi.org/10.48550/arXiv.2311.14722
-
[20]
Karmvir Singh Phogat, Sai Akhil Puranam, Sridhar Dasaratha, Chetan Harsha, and Shashishekar Ramakrishna. 2024. Fine-tuning Smaller Language Models for Question Answering over Financial Documents. InFindings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA, November 12-16,
2024
-
[21]
Association for Computational Linguistics, 10528–10548
-
[22]
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani- Tür, Gokhan Tur, and Heng Ji. 2025. Toolrl: Reward is all tool learning needs. arXiv preprint arXiv:2504.13958(2025)
work page internal anchor Pith review arXiv 2025
-
[23]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al . [n. d.]. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. InICLR 2024
2024
-
[24]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems36 (2023), 68539–68551
2023
-
[25]
Zhengliang Shi, Shen Gao, Lingyong Yan, Yue Feng, Xiuyi Chen, Zhumin Chen, Dawei Yin, Suzan Verberne, and Zhaochun Ren. 2025. Tool learning in the wild: Empowering language models as automatic tool agents. InProceedings of the ACM on Web Conference 2025. 2222–2237
2025
-
[26]
Venkat Krishna Srinivasan, Zhen Dong, Banghua Zhu, Brian Yu, Damon Mosk- Aoyama, Kurt Keutzer, Jiantao Jiao, and Jian Zhang. 2023. Nexusraven: a commercially-permissive language model for function calling. InNeurIPS 2023 Foundation Models for Decision Making Workshop
2023
-
[27]
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Na Zou, et al . 2025. Stop overthinking: A survey on efficient reasoning for large language models.arXiv preprint arXiv:2503.16419(2025)
work page internal anchor Pith review arXiv 2025
- [28]
-
[29]
Zichen Tang, Haihong E, Ziyan Ma, Haoyang He, Jiacheng Liu, Zhongjun Yang, Zihua Rong, Rongjin Li, Kun Ji, Qing Huang, Xinyang Hu, Yang Liu, and Qianhe Zheng. 2025. FinanceReasoning: Benchmarking Financial Numerical Reasoning More Credible, Comprehensive and Challenging. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguis...
2025
-
[30]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al . 2025. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Maolin Wang, Yingyi Zhang, Cunyin Peng, Yicheng Chen, Wei Zhou, Jinjie Gu, Chenyi Zhuang, Ruocheng Guo, Bowen Yu, Wanyu Wang, et al. 2025. Function Calling in Large Language Models: Industrial Practices, Challenges, and Future Directions. (2025)
2025
-
[32]
Mengsong Wu, Tong Zhu, Han Han, Chuanyuan Tan, Xiang Zhang, and Wenliang Chen. 2024. Seal-Tools: Self-instruct Tool Learning Dataset for Agent Tuning and Detailed Benchmark. Springer-Verlag, Berlin, Heidelberg, 372–384
2024
-
[33]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. 2025. The rise and potential of large language model based agents: A survey.Science China Information Sciences 68, 2 (2025), 121101
2025
-
[34]
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, et al . 2024. Finben: A holistic financial benchmark for large language models.Advances in Neural Information Processing Systems37 (2024), 95716–95743
2024
- [35]
-
[36]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR)
2023
-
[37]
Junjie Ye, Zhengyin Du, Xuesong Yao, Weijian Lin, Yufei Xu, Zehui Chen, Zaiyuan Wang, Sining Zhu, Zhiheng Xi, Siyu Yuan, Tao Gui, Qi Zhang, Xuanjing Huang, and Jiecao Chen. 2025. ToolHop: A Query-Driven Benchmark for Evaluating Large Language Models in Multi-Hop Tool Use. InProceedings of the 63rd Annual Meeting of the Association for Computational Lingui...
2025
-
[38]
Guancheng Zeng, Wentao Ding, Beining Xu, Chi Zhang, Wenqiang Han, Gang Li, Jingjing Mo, Pengxu Qiu, Xinran Tao, Wang Tao, and Haowen Hu. 2024. Adaptable and Precise: Enterprise-Scenario LLM Function-Calling Capability Training Pipeline.CoRRabs/2412.15660 (2024). https://doi.org/10.48550/arXiv. 2412.15660
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[39]
N., Zeyuan Chen, Ran Xu, Juan Carlos Niebles, Shelby Heinecke, Huan Wang, Silvio Savarese, and Caiming Xiong
Jianguo Zhang, Tian Lan, Ming Zhu, Zuxin Liu, Thai Hoang, Shirley Kokane, Weiran Yao, Juntao Tan, Akshara Prabhakar, Haolin Chen, Zhiwei Liu, Yihao Feng, Tulika Manoj Awalgaonkar, Rithesh R. N., Zeyuan Chen, Ran Xu, Juan Carlos Niebles, Shelby Heinecke, Huan Wang, Silvio Savarese, and Caiming Xiong. 2025. xLAM: A Family of Large Action Models to Empower A...
2025
-
[40]
Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua. 2021. TAT-QA: A Question Answer- ing Benchmark on a Hybrid of Tabular and Textual Content in Finance. InACL. Association for Computational Linguistics. WWW ’26, April 13–17, 2026, Dubai, United Arab Emirates Xing Tang, et al. A Prompt list used in...
2021
-
[41]
Carefully read the generated user query and understand theintended action
-
[42]
Review the tool definition to understand each parameter’smeaning and constraints
-
[43]
Check the parameter values in tool_call: - Do they match the intent and details in the user query? - Are they internally consistent (no contradictions between parameters)? - Do they comply with the tool definition (value types, required fields, allowed ranges)?
-
[44]
Consistent
Decide if the tool_call is logically correct: - If all parameters reflect the query correctly and satisfy the tool’s definition, return"Consistent". - If there is any mismatch or logical conflict, return"Inconsistent". ## Output format requirements: - Return a (JSON list) containing exactly one object: [{ "analysis": "...your reasoning here...", "result":...
2026
-
[45]
A set of FIVE few-shot examples, each containing: - A user query - A toolset with tool names, descriptions, and parameters - The correct tool calls for that query in strict JSON list format
-
[46]
The CURRENT user query we need to process
-
[47]
name": "func_name1
The CURRENT toolset specification ## Your task: - Carefully study the five examples to understand how queries are mapped to tool calls. - For the CURRENT query, use ONLY the tools provided in the CURRENT toolset, along with their descriptions, to determine the exact functions to call and the correct values of their parameters. - Parameter values MUST be d...
2026
-
[48]
**Learn from previous rounds**: Analyze what values were generated and their impact
-
[49]
**Focus on current gaps**: Target parameter values that are still underrepresented in local distribution
-
[50]
**Avoid redundancy**: Don’t generate values that were already created in previous rounds
-
[51]
**Strategic selection**: Choose values that will maximally increase the entropy ratio
-
[52]
**Maintain coherence**: Ensure semantic consistency within the cluster context
-
[53]
**Diversify query expressions**: Generate queries with varied linguistic forms but similar semantics, avoiding mere entity substitution
-
[54]
new_query
**Preserve tool_call logical coherence**: All parameter values in the generated tool_call must maintain logical consistency. # JSON Output Format: [{ "new_query": "...", "new_value_for_{tool_param.split('.')[-1]}": "...", "new_tool_call": "...", "step_rationale": "Strategic explanation for Round {step}" }]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.