Recognition: 2 theorem links
· Lean TheoremVideoStir: Understanding Long Videos via Spatio-Temporally Structured and Intent-Aware RAG
Pith reviewed 2026-05-10 19:10 UTC · model grok-4.3
The pith
VideoStir builds clip-level spatio-temporal graphs and uses an intent-relevance scorer to retrieve evidence for long-video RAG in MLLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
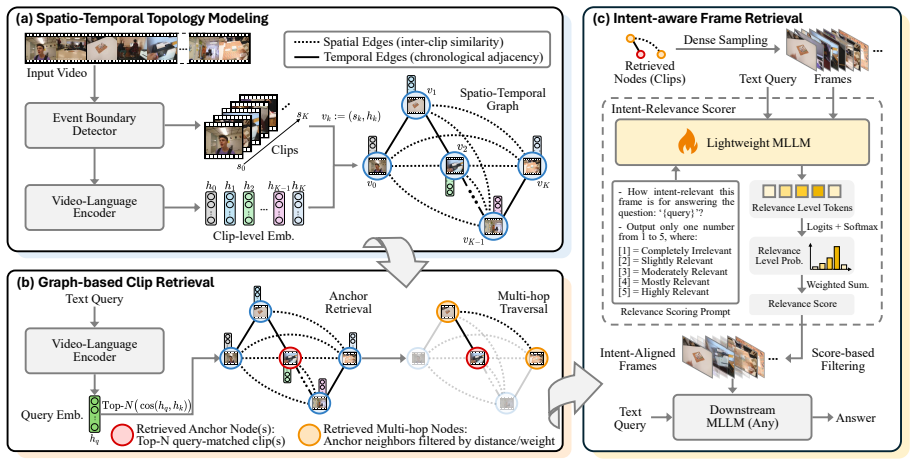
VideoStir first constructs a spatio-temporal graph at the clip level to preserve inherent video structure, then applies multi-hop retrieval to gather evidence from distant but contextually linked events, and finally employs an MLLM-backed intent-relevance scorer that selects frames according to their fit with the query's reasoning goal rather than surface semantic similarity alone; the scorer is trained on the newly curated IR-600K dataset of frame-query intent alignments.
What carries the argument
A clip-level spatio-temporal graph enabling multi-hop retrieval, paired with an MLLM-backed intent-relevance scorer that judges frame alignment to query reasoning intent.
If this is right
- Multi-hop retrieval over the graph allows aggregation of evidence from non-adjacent but related events in a single compact context.
- Intent-aware scoring captures relevance that explicit semantic matching misses, reducing the need for hand-crafted auxiliary signals.
- The IR-600K dataset provides a scalable way to train models on frame-query intent alignment for video tasks.
- Performance competitive with state-of-the-art baselines is achievable while keeping the retrieved context compact enough for existing MLLM windows.
Where Pith is reading between the lines
- Similar graph-based structuring could be tested on other long-form multimodal inputs such as audio streams or document collections where temporal or spatial order matters.
- If the intent scorer generalizes, it may reduce reliance on ever-larger context windows by making retrieval more precise rather than simply longer.
- The framework suggests that future video benchmarks should include more queries requiring implicit cross-clip reasoning to expose differences between flat and structured retrieval.
Load-bearing premise
That constructing a clip-level spatio-temporal graph and applying the intent-relevance scorer will consistently surface the right evidence for a query without adding noise or overlooking implicit connections.
What would settle it
A controlled test set of long-video queries whose correct answers depend on implicit spatio-temporal links across distant clips, where VideoStir retrieves fewer relevant frames than pure semantic baselines or shows no accuracy gain.
Figures


read the original abstract
Scaling multimodal large language models (MLLMs) to long videos is constrained by limited context windows. While retrieval-augmented generation (RAG) is a promising remedy by organizing query-relevant visual evidence into a compact context, most existing methods (i) flatten videos into independent segments, breaking their inherent spatio-temporal structure, and (ii) depend on explicit semantic matching, which can miss cues that are implicitly relevant to the query's intent. To overcome these limitations, we propose VideoStir, a structured and intent-aware long-video RAG framework. It firstly structures a video as a spatio-temporal graph at clip level, and then performs multi-hop retrieval to aggregate evidence across distant yet contextually related events. Furthermore, it introduces an MLLM-backed intent-relevance scorer that retrieves frames based on their alignment with the query's reasoning intent. To support this capability, we curate IR-600K, a large-scale dataset tailored for learning frame-query intent alignment. Experiments show that VideoStir is competitive with state-of-the-art baselines without relying on auxiliary information, highlighting the promise of shifting long-video RAG from flattened semantic matching to structured, intent-aware reasoning. Codes and checkpoints are available at https://github.com/RomGai/VideoStir.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VideoStir, a long-video RAG framework that first constructs a clip-level spatio-temporal graph from the input video, then applies multi-hop retrieval to aggregate evidence across related events, and finally uses an MLLM-backed intent-relevance scorer (trained on the newly curated IR-600K dataset) to select frames aligned with the query's reasoning intent rather than pure semantic similarity. It reports that the resulting system achieves competitive performance with state-of-the-art baselines on long-video understanding tasks while requiring no auxiliary information, and releases code and checkpoints.
Significance. If the empirical claims hold after addressing the points below, the work offers a concrete step toward replacing flattened semantic retrieval with structured, intent-aware reasoning for long videos. The public release of the IR-600K dataset, code, and checkpoints is a clear strength that enables reproducibility and follow-up research.
major comments (2)
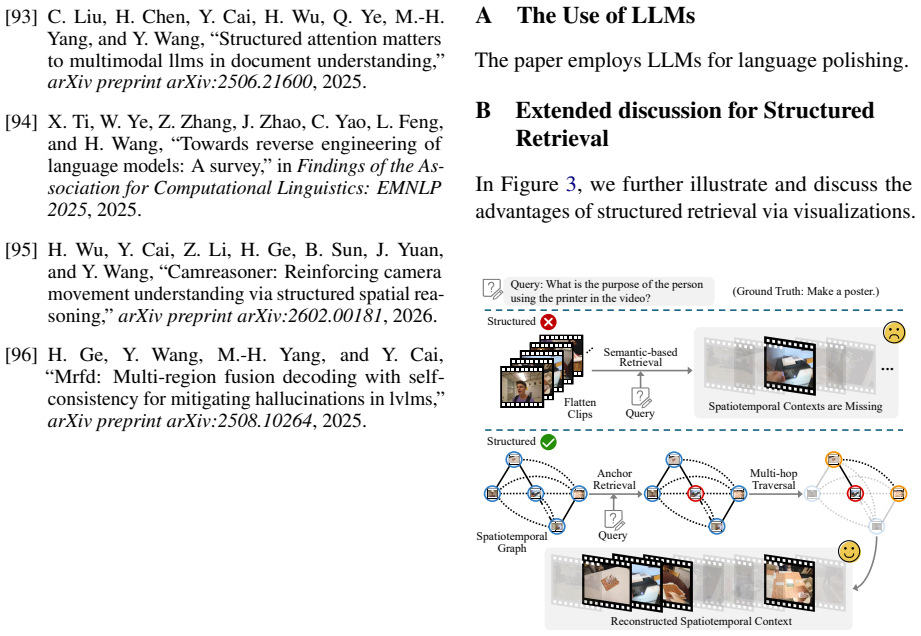
- [Experiments] Experiments section: the central claim that the spatio-temporal graph plus multi-hop retrieval and intent-relevance scorer together surface implicit evidence more reliably than flattened semantic matching is not isolated by any ablation that disables the graph structure (or replaces the intent scorer with pure semantic similarity) while holding the MLLM backbone and retrieval budget fixed. Without this comparison, the reported competitiveness could be driven by MLLM capacity or dataset curation rather than the proposed structured components.
- [§3.2 and §4] §3.2 and §4: the description of the intent-relevance scorer and the multi-hop retrieval procedure does not quantify how often the graph introduces noise or misses implicit connections, nor does it provide a failure-case analysis on queries where distant events are relevant only through unstated intent. This directly affects the weakest assumption underlying the competitiveness claim.
minor comments (2)
- [Abstract] Abstract: while the competitiveness claim is stated, no key quantitative metrics (e.g., accuracy deltas or task-specific scores) are supplied; adding one or two headline numbers would strengthen the abstract without altering its length.
- [Abstract / Code availability] The paper mentions that codes and checkpoints are available at the GitHub link, which is appreciated; ensure the repository includes the exact training scripts and dataset preprocessing code used for the IR-600K experiments.
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which highlight important aspects for strengthening our empirical validation. We address each major comment below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that the spatio-temporal graph plus multi-hop retrieval and intent-relevance scorer together surface implicit evidence more reliably than flattened semantic matching is not isolated by any ablation that disables the graph structure (or replaces the intent scorer with pure semantic similarity) while holding the MLLM backbone and retrieval budget fixed. Without this comparison, the reported competitiveness could be driven by MLLM capacity or dataset curation rather than the proposed structured components.
Authors: We agree that a more isolated ablation study would better substantiate the contribution of the proposed components. While our experiments compare VideoStir against baselines employing flattened semantic matching under similar MLLM backbones, we did not explicitly ablate the graph structure or the intent scorer in isolation with fixed retrieval budget. In the revised manuscript, we will include additional ablation experiments that disable the spatio-temporal graph (replacing it with independent clip-level retrieval) and replace the intent-relevance scorer with pure semantic similarity, while keeping the MLLM and retrieval budget constant. This will help isolate the effects of the structured components. revision: yes
-
Referee: [§3.2 and §4] §3.2 and §4: the description of the intent-relevance scorer and the multi-hop retrieval procedure does not quantify how often the graph introduces noise or misses implicit connections, nor does it provide a failure-case analysis on queries where distant events are relevant only through unstated intent. This directly affects the weakest assumption underlying the competitiveness claim.
Authors: We acknowledge the value of quantifying potential noise or missed connections in the graph and providing failure-case analysis. The current manuscript focuses on overall performance metrics and does not include such detailed error analysis. In the revision, we will add a subsection in §4 discussing the frequency of graph-induced noise based on manual inspection of a sample of retrieval results, and include representative failure cases where distant events are linked only via intent. We note that exhaustive quantification may require additional human annotation, but we will provide quantitative estimates where feasible and qualitative insights. revision: partial
Circularity Check
No circularity in claimed derivation; empirical framework with external validation
full rationale
The paper presents VideoStir as an empirical RAG framework that structures videos into clip-level spatio-temporal graphs, performs multi-hop retrieval, and employs an MLLM-backed intent-relevance scorer trained on the newly curated IR-600K dataset. No equations, derivations, or first-principles results appear that reduce performance claims to self-defined parameters or inputs by construction. Competitiveness is asserted via experiments on standard long-video benchmarks without auxiliary information, relying on external MLLM capabilities and dataset curation rather than tautological fits or self-citation chains. The absence of mathematical reductions or load-bearing self-references keeps the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A video possesses an inherent spatio-temporal structure that can be faithfully represented as a graph at the clip level.
- domain assumption An MLLM can accurately score the alignment between individual frames and the reasoning intent of a query.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearflattening videos into independent segments, breaking their inherent spatio-temporal structure... explicit semantic matching
Reference graph
Works this paper leans on
-
[1]
Videochat: Chat- centric video understanding,
K. Li, Y . He, Y . Wang, Y . Li, W. Wang, P. Luo, Y . Wang, L. Wang, and Y . Qiao, “Videochat: Chat- centric video understanding,”Science China In- formation Sciences, vol. 68, no. 10, p. 200102, 2025
2025
-
[2]
Video-rag: Visually-aligned retrieval-augmented long video comprehension,
Y . Luo, X. Zheng, G. Li, S. Yin, H. Lin, C. Fu, J. Huang, J. Ji, F. Chao, J. Luoet al., “Video-rag: Visually-aligned retrieval-augmented long video comprehension,”NeurIPS 2025, 2025
2025
-
[3]
Vgent: Graph-based retrieval-reasoning- augmented generation for long video understand- ing,
X. Shen, W. Zhang, J. Chen, and M. Elho- seiny, “Vgent: Graph-based retrieval-reasoning- augmented generation for long video understand- ing,”arXiv preprint arXiv:2510.14032, 2025
-
[4]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasu- pat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosenet al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodal- ity, long context, and next generation agentic capa- bilities,”arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Videorag: Retrieval-augmented generation with extreme long-context videos, 2025
X. Ren, L. Xu, L. Xia, S. Wang, D. Yin, and C. Huang, “Videorag: Retrieval-augmented gen- eration with extreme long-context videos,”arXiv preprint arXiv:2502.01549, 2025
-
[6]
Adaptive keyframe sampling for long video under- standing,
X. Tang, J. Qiu, L. Xie, Y . Tian, J. Jiao, and Q. Ye, “Adaptive keyframe sampling for long video under- standing,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 29 118–29 128
2025
- [7]
-
[8]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[9]
Tv-rag: A temporal-aware and semantic entropy- weighted framework for long video retrieval and understanding,
Z. Cao, Y . He, A. Liu, J. Xie, F. Chen, and Z. Wang, “Tv-rag: A temporal-aware and semantic entropy- weighted framework for long video retrieval and understanding,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 9071–9079
2025
-
[10]
Videoinsta: Zero-shot long video understanding via informative spatial- temporal reasoning with llms,
R. Liao, M. Erler, H. Wang, G. Zhai, G. Zhang, Y . Ma, and V . Tresp, “Videoinsta: Zero-shot long video understanding via informative spatial- temporal reasoning with llms,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 6577–6602
2024
-
[11]
I3: I ntent- i ntrospective retrieval conditioned on i nstruc- tions,
K. Pan, J. Li, W. Wang, H. Fei, H. Song, W. Ji, J. Lin, X. Liu, T.-S. Chua, and S. Tang, “I3: I ntent- i ntrospective retrieval conditioned on i nstruc- tions,” inProceedings of the 47th International ACM SIGIR Conference on Research and Devel- opment in Information Retrieval, 2024, pp. 1839– 1849
2024
-
[12]
Hacsurv: A hierarchical copula-based approach for survival analysis with dependent competing risks,
X. Liu, W. Zhang, and M.-L. Zhang, “Hacsurv: A hierarchical copula-based approach for survival analysis with dependent competing risks,” inInter- national Conference on Artificial Intelligence and Statistics. PMLR, 2025, pp. 3079–3087
2025
-
[13]
Defending multimodal backdoored models by re- pulsive visual prompt tuning,
Z. Zhang, S. He, H. Wang, B. Shen, and L. Feng, “Defending multimodal backdoored models by re- pulsive visual prompt tuning,”NeurIPS, 2025
2025
-
[14]
Tuning vision-language models with candidate labels by prompt alignment,
Z. Zhang, Y . Niu, X. Liu, and B. Li, “Tuning vision-language models with candidate labels by prompt alignment,” inDASFAA, 2025
2025
-
[15]
Z. Zhang, J. Zhang, S. Zhou, Q. Wei, S. He, F. Liu, and L. Feng, “Improving generalizability and un- detectability for targeted adversarial attacks on multimodal pre-trained models,”arXiv preprint arXiv:2509.19994, 2025
-
[16]
L. Mei, S. Liu, Y . Wang, Y . Ge, B. Bi, J. Yao, J. Wan, Z. Yin, J. Guo, and X. Cheng, “Gated differentiable working memory for long- context language modeling,”arXiv preprint arXiv:2601.12906, 2026
-
[17]
Gemini: A Family of Highly Capable Multimodal Models
R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millicanet al., “Gemini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Y . Shen, C. Fu, S. Dong, X. Wang, Y .-F. Zhang, P. Chen, M. Zhang, H. Cao, K. Li, S. Linet al., “Long-vita: Scaling large multi-modal models to 1 million tokens with leading short-context accu- racy,”arXiv preprint arXiv:2502.05177, 2025
-
[19]
Video-xl: Extra-long vi- sion language model for hour-scale video under- standing,
Y . Shu, Z. Liu, P. Zhang, M. Qin, J. Zhou, Z. Liang, T. Huang, and B. Zhao, “Video-xl: Extra-long vi- sion language model for hour-scale video under- standing,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 26 160–26 169
2025
-
[20]
Longvlm: Efficient long video under- standing via large language models,
Y . Weng, M. Han, H. He, X. Chang, and B. Zhuang, “Longvlm: Efficient long video under- standing via large language models,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 453–470
2024
-
[21]
Clip4clip: An empirical study of CLIP for end to end video clip retrieval.CoRR, abs/2104.08860, 2021
H. Luo, L. Ji, M. Zhong, Y . Chen, W. Lei, N. Duan, and T. Li, “Clip4clip: An empirical study of clip for end to end video clip retrieval,”arXiv preprint arXiv:2104.08860, 2021
-
[22]
Videoclip: Contrastive pre- training for zero-shot video-text understanding,
H. Xu, G. Ghosh, P.-Y . Huang, D. Okhonko, A. Aghajanyan, F. Metze, L. Zettlemoyer, and C. Feichtenhofer, “Videoclip: Contrastive pre- training for zero-shot video-text understanding,” inProceedings of the 2021 Conference on Em- pirical Methods in Natural Language Processing, 2021, pp. 6787–6800
2021
-
[23]
X-clip: End-to-end multi-grained con- trastive learning for video-text retrieval,
Y . Ma, G. Xu, X. Sun, M. Yan, J. Zhang, and R. Ji, “X-clip: End-to-end multi-grained con- trastive learning for video-text retrieval,” inPro- ceedings of the 30th ACM international conference on multimedia, 2022, pp. 638–647
2022
-
[24]
Perception Encoder: The best visual embeddings are not at the output of the network
D. Bolya, P.-Y . Huang, P. Sun, J. H. Cho, A. Madotto, C. Wei, T. Ma, J. Zhi, J. Rajasegaran, H. Rasheedet al., “Perception encoder: The best visual embeddings are not at the output of the net- work,”arXiv preprint arXiv:2504.13181, 2025
work page internal anchor Pith review arXiv 2025
-
[25]
Optical remote sensing image salient object de- tection via bidirectional cross-attention and atten- tion restoration,
Y . Gu, S. Chen, X. Sun, J. Ji, Y . Zhou, and R. Ji, “Optical remote sensing image salient object de- tection via bidirectional cross-attention and atten- tion restoration,”Pattern Recognition, vol. 164, p. 111478, 2025
2025
-
[26]
Z. Xiong, Y . Cai, Z. Li, and Y . Wang, “Un- veiling the potential of diffusion large language model in controllable generation,”arXiv preprint arXiv:2507.04504, 2025
-
[27]
Refineshot: Rethinking cinematography understanding with foundational skill evaluation,
H. Wu, Y . Cai, H. Ge, H. Chen, M.-H. Yang, and Y . Wang, “Refineshot: Rethinking cinematography understanding with foundational skill evaluation,” arXiv preprint arXiv:2510.02423, 2025
-
[28]
Acl: Activating capability of linear attention for image restoration,
Y . Gu, Y . Meng, J. Ji, and X. Sun, “Acl: Activating capability of linear attention for image restoration,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 17 913–17 923
2025
-
[29]
Z. Li, Y . Wang, B. Hooi, Y . Cai, N. Cheung, N. Peng, and K.-W. Chang, “Think carefully and check again! meta-generation unlocking llms for low-resource cross-lingual summarization,”arXiv preprint arXiv:2410.20021, 2024
-
[30]
Focusing by contrastive attention: Enhancing vlms’ visual reasoning,
Y . Ge, S. Liu, Y . Wang, L. Mei, B. Bi, X. Zhou, J. Yao, J. Guo, and X. Cheng, “Focusing by con- trastive attention: Enhancing vlms’ visual reason- ing,”arXiv preprint arXiv:2509.06461, 2025
-
[31]
Dp-iqa: Utilizing diffusion prior for blind image quality assessment in the wild,
H. Fu, Y . Wang, W. Yang, A. C. Kot, and B. Wen, “Dp-iqa: Utilizing diffusion prior for blind image quality assessment in the wild,”arXiv preprint arXiv:2405.19996, 2024
-
[32]
Hdtcnet: A hybrid- dimensional convolutional network for multivari- ate time series classification,
Y . Gu, X. Yan, H. Qin, N. Akhtar, S. Yuan, H. Fu, S. Yang, and A. Mian, “Hdtcnet: A hybrid- dimensional convolutional network for multivari- ate time series classification,”Pattern Recognition, vol. 168, p. 111837, 2025
2025
-
[33]
Tokenswap: Backdoor attack on the com- positional understanding of large vision-language models,
Z. Zhang, Q. Tao, J. Lv, N. Zhao, L. Feng, and J. T. Zhou, “Tokenswap: Backdoor attack on the com- positional understanding of large vision-language models,”arXiv preprint arXiv:2509.24566, 2025
-
[34]
Mm-vid: Advancing video understanding with gpt-4v (ision),
K. Lin, F. Ahmed, L. Li, C.-C. Lin, E. Azarnasab, Z. Yang, J. Wang, L. Liang, Z. Liu, Y . Luet al., “Mm-vid: Advancing video understanding with gpt-4v (ision),”arXiv preprint arXiv:2310.19773, 2023
-
[35]
Omagent: A multi-modal agent framework for complex video understanding with task divide-and- conquer,
L. Zhang, T. Zhao, H. Ying, Y . Ma, and K. Lee, “Omagent: A multi-modal agent framework for complex video understanding with task divide-and- conquer,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Pro- cessing, 2024, pp. 10 031–10 045
2024
-
[36]
arXiv preprint arXiv:2512.04540 , year=
H. Jin, Q. Wang, W. Zhang, Y . Liu, and S. Cheng, “Videomem: Enhancing ultra-long video un- derstanding via adaptive memory management,” arXiv preprint arXiv:2512.04540, 2025
-
[37]
Vamos: Versatile action models for video understanding,
S. Wang, Q. Zhao, M. Q. Do, N. Agarwal, K. Lee, and C. Sun, “Vamos: Versatile action models for video understanding,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 142–160
2024
-
[38]
Morevqa: Exploring modular rea- soning models for video question answering,
J. Min, S. Buch, A. Nagrani, M. Cho, and C. Schmid, “Morevqa: Exploring modular rea- soning models for video question answering,” in Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2024, pp. 13 235–13 245
2024
-
[39]
Drvideo: Document retrieval based long video understanding,
Z. Ma, C. Gou, H. Shi, B. Sun, S. Li, H. Rezatofighi, and J. Cai, “Drvideo: Document retrieval based long video understanding,” inPro- ceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 18 936–18 946
2025
-
[40]
Z. Xue, J. Zhang, X. Xie, Y . Cai, Y . Liu, X. Li, and D. Tao, “Omni-adavideorag: Omni- contextual adaptive retrieval-augmented for effi- cient long video understanding,”arXiv preprint arXiv:2506.13589, 2025
-
[41]
N. Zeng, H. Hou, F. R. Yu, S. Shi, and Y . T. He, “Scenerag: Scene-level retrieval-augmented gen- eration for video understanding,”arXiv preprint arXiv:2506.07600, 2025
-
[42]
Vide- orag: Retrieval-augmented generation over video corpus,
S. Jeong, K. Kim, J. Baek, and S. J. Hwang, “Vide- orag: Retrieval-augmented generation over video corpus,”arXiv preprint arXiv:2501.05874, 2025
-
[43]
Z. Xu, J. Zhang, Q. Wang, and Y . Liu, “E-vrag: En- hancing long video understanding with resource- efficient retrieval augmented generation,”arXiv preprint arXiv:2508.01546, 2025
-
[44]
Contextnav: Towards agentic multimodal in-context learning.arXiv preprint arXiv:2510.04560, 2025
H. Fu, Y . Ouyang, K.-W. Chang, Y . Wang, Z. Huang, and Y . Cai, “Contextnav: Towards agen- tic multimodal in-context learning,”arXiv preprint arXiv:2510.04560, 2025
-
[45]
X. Liu, W. Zhang, W. Tang, T. D. Le, J. Li, L. Liu, and M.-L. Zhang, “From correlation to causation: Max-pooling-based multi-instance learning leads to more robust whole slide image classification,” arXiv preprint arXiv:2408.09449, 2024
-
[46]
H. Ge, Y . Wang, K.-W. Chang, H. Wu, and Y . Cai, “Framemind: Frame-interleaved video rea- soning via reinforcement learning,”arXiv preprint arXiv:2509.24008, 2025
-
[47]
Sfir: Optimizing spatial and frequency domains for image restoration,
Y . Gu, Y . Meng, S. Chen, J. Ji, X. Sun, W. Ruan, and R. Ji, “Sfir: Optimizing spatial and frequency domains for image restoration,”Pattern Recogni- tion, p. 112188, 2025
2025
-
[48]
An efficient and mixed het- erogeneous model for image restoration,
Y . Gu, Y . Meng, K. Zheng, X. Sun, J. Ji, W. Ruan, L. Cao, and R. Ji, “An efficient and mixed het- erogeneous model for image restoration,”arXiv preprint arXiv:2504.10967, 2025
-
[49]
Sgcn: a multi-order neighborhood feature fusion land- form classification method based on superpixel and graph convolutional network,
H. Fu, Y . Shen, Y . Liu, J. Li, and X. Zhang, “Sgcn: a multi-order neighborhood feature fusion land- form classification method based on superpixel and graph convolutional network,”International Journal of Applied Earth Observation and Geoin- formation, vol. 122, p. 103441, 2023
2023
-
[50]
a1: Steep test-time scaling law via environment augmented generation,
L. Mei, S. Liu, Y . Wang, B. Bi, Y . Ge, J. Wan, Y . Wu, and X. Cheng, “a1: Steep test-time scaling law via environment augmented generation,”arXiv preprint arXiv:2504.14597, 2025
-
[51]
Drs: Deep question reformulation with structured output,
Z. Li, Y . Wang, B. Hooi, Y . Cai, N. Peng, and K.-W. Chang, “Drs: Deep question reformulation with structured output,” inAssociation for Compu- tational Linguistics ACL, 2025., 2024
2025
-
[52]
Texture or semantics? vision-language models get lost in font recognition,
Z. Li, G. Song, Y . Cai, Z. Xiong, J. Yuan, and Y . Wang, “Texture or semantics? vision-language models get lost in font recognition,” inConference on Language Modeling COLM, 2025., 2025
2025
-
[53]
Haif-gs: Hierarchical and induced flow-guided gaussian splatting for dynamic scene,
J. Chen, Z. Li, Y . Cai, H. Jiang, C. Qian, J. Kang, S. Gao, H. Zhao, T. Mao, and Y . Zhang, “Haif-gs: Hierarchical and induced flow-guided gaussian splatting for dynamic scene,” inNeurIPS 2025, 2025
2025
-
[54]
Opti- mal detection of changepoints with a linear compu- tational cost,
R. Killick, P. Fearnhead, and I. A. Eckley, “Opti- mal detection of changepoints with a linear compu- tational cost,”Journal of the American Statistical Association, vol. 107, no. 500, pp. 1590–1598, 2012
2012
-
[55]
Lora: Low- rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low- rank adaptation of large language models.”ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[56]
Orsi salient object detection via bidimensional attention and full-stage semantic guidance,
Y . Gu, H. Xu, Y . Quan, W. Chen, and J. Zheng, “Orsi salient object detection via bidimensional attention and full-stage semantic guidance,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–13, 2023
2023
-
[57]
Y . Ge, S. Liu, Y . Wang, L. Mei, L. Chen, B. Bi, and X. Cheng, “Innate reasoning is not enough: In-context learning enhances reasoning large lan- guage models with less overthinking,”arXiv preprint arXiv:2503.19602, 2025
-
[58]
Mixed degrada- tion image restoration via local dynamic optimization and conditional embedding,
Y . Gu, Y . Meng, X. Sun, J. Ji, W. Ruan, and R. Ji, “Mixed degradation image restoration via local dy- namic optimization and conditional embedding,” arXiv preprint arXiv:2411.16217, 2024
-
[59]
A Survey of Context Engineering for Large Language Models
L. Mei, J. Yao, Y . Ge, Y . Wang, B. Bi, Y . Cai, J. Liu, M. Li, Z.-Z. Li, D. Zhanget al., “A survey of context engineering for large language models,” arXiv preprint arXiv:2507.13334, 2025
work page internal anchor Pith review arXiv 2025
-
[60]
Dimo-gui: Advancing test- time scaling in gui grounding via modality-aware visual reasoning,
H. Wu, H. Chen, Y . Cai, C. Liu, Q. Ye, M.-H. Yang, and Y . Wang, “Dimo-gui: Advancing test- time scaling in gui grounding via modality-aware visual reasoning,” inEMNLP 2025, 2025
2025
-
[61]
Hiddenguard: Fine-grained safe gener- ation with specialized representation router,
L. Mei, S. Liu, Y . Wang, B. Bi, R. Yuan, and X. Cheng, “Hiddenguard: Fine-grained safe gener- ation with specialized representation router,”arXiv preprint arXiv:2410.02684, 2024
-
[62]
Vulnerability of llms to verti- cally aligned text manipulations,
Z. Li, Y . Wang, B. Hooi, Y . Cai, Z. Xiong, N. Peng, and K.-W. Chang, “Vulnerability of llms to verti- cally aligned text manipulations,” inAssociation for Computational Linguistics ACL, 2025., 2024
2025
-
[63]
From tokens to nodes: Semantic-guided motion control for dynamic 3d gaussian splatting,
J. Chen, Z. Li, Y . Cai, H. Jiang, S. Gao, H. Zhao, T. Mao, and Y . Zhang, “From tokens to nodes: Semantic-guided motion control for dynamic 3d gaussian splatting,”arXiv preprint arXiv:2510.02732, 2025
-
[64]
"not aligned
L. Mei, S. Liu, Y . Wang, B. Bi, J. Mao, and X. Cheng, “"not aligned" is not" malicious": Be- ing careful about hallucinations of large language models’ jailbreak,”COLING 2025, 2024
2025
-
[65]
A simple llm frame- work for long-range video question-answering,
C. Zhang, T. Lu, M. M. Islam, Z. Wang, S. Yu, M. Bansal, and G. Bertasius, “A simple llm frame- work for long-range video question-answering,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 21 715–21 737
2024
-
[66]
Videoagent: Long-form video understanding with large language model as agent,
X. Wang, Y . Zhang, O. Zohar, and S. Yeung-Levy, “Videoagent: Long-form video understanding with large language model as agent,” inEuropean Con- ference on Computer Vision. Springer, 2024, pp. 58–76
2024
-
[67]
Videoagent: A memory-augmented mul- timodal agent for video understanding,
Y . Fan, X. Ma, R. Wu, Y . Du, J. Li, Z. Gao, and Q. Li, “Videoagent: A memory-augmented mul- timodal agent for video understanding,” inEuro- pean Conference on Computer Vision. Springer, 2024, pp. 75–92
2024
-
[68]
Videotree: Adaptive tree-based video representation for llm reasoning on long videos,
Z. Wang, S. Yu, E. Stengel-Eskin, J. Yoon, F. Cheng, G. Bertasius, and M. Bansal, “Videotree: Adaptive tree-based video representation for llm reasoning on long videos,” inProceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 3272–3283
2025
-
[69]
An im- age grid can be worth a video: Zero-shot video question answering using a vlm,
W. Kim, C. Choi, W. Lee, and W. Rhee, “An im- age grid can be worth a video: Zero-shot video question answering using a vlm,”IEEE Access, 2024
2024
-
[70]
Tvsum: Summarizing web videos using titles,
Y . Song, J. Vallmitjana, A. Stent, and A. Jaimes, “Tvsum: Summarizing web videos using titles,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 5179– 5187
2015
-
[71]
Detecting mo- ments and highlights in videos via natural lan- guage queries,
J. Lei, T. L. Berg, and M. Bansal, “Detecting mo- ments and highlights in videos via natural lan- guage queries,”Advances in Neural Information Processing Systems, vol. 34, pp. 11 846–11 858, 2021
2021
-
[72]
Activitynet-qa: A dataset for under- standing complex web videos via question answer- ing,
Z. Yu, D. Xu, J. Yu, T. Yu, Z. Zhao, Y . Zhuang, and D. Tao, “Activitynet-qa: A dataset for under- standing complex web videos via question answer- ing,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 9127–9134
2019
-
[73]
Next- qa: Next phase of question-answering to ex- plaining temporal actions,
J. Xiao, X. Shang, A. Yao, and T.-S. Chua, “Next- qa: Next phase of question-answering to ex- plaining temporal actions,” inProceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, 2021, pp. 9777–9786
2021
-
[74]
STAR: A Benchmark for Situ- ated Reasoning in Real-World Videos.arXiv e-prints, art
B. Wu, S. Yu, Z. Chen, J. B. Tenenbaum, and C. Gan, “Star: A benchmark for situated rea- soning in real-world videos,”arXiv preprint arXiv:2405.09711, 2024
-
[75]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tanget al., “Qwen2. 5-vl technical report,”arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Longvideobench: A benchmark for long-context interleaved video-language understanding,
H. Wu, D. Li, B. Chen, and J. Li, “Longvideobench: A benchmark for long-context interleaved video-language understanding,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 28 828–28 857, 2024
2024
-
[77]
Mlvu: Benchmarking multi-task long video understand- ing,
J. Zhou, Y . Shu, B. Zhao, B. Wu, Z. Liang, S. Xiao, M. Qin, X. Yang, Y . Xiong, B. Zhanget al., “Mlvu: Benchmarking multi-task long video understand- ing,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 13 691– 13 701
2025
-
[78]
Video-mme: The first-ever comprehensive eval- uation benchmark of multi-modal llms in video analysis,
C. Fu, Y . Dai, Y . Luo, L. Li, S. Ren, R. Zhang, Z. Wang, C. Zhou, Y . Shen, M. Zhanget al., “Video-mme: The first-ever comprehensive eval- uation benchmark of multi-modal llms in video analysis,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 24 108–24 118
2025
-
[79]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radfordet al., “Gpt-4o system card,” arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[80]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Y . Zhang, J. Wu, W. Li, B. Li, Z. Ma, Z. Liu, and C. Li, “Video instruction tuning with synthetic data,”arXiv preprint arXiv:2410.02713, 2024
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.