Recognition: 2 theorem links
· Lean TheoremContent Fuzzing for Escaping Information Cocoons on Digital Social Media
Pith reviewed 2026-05-10 19:16 UTC · model grok-4.3
The pith
A fuzzing method rewrites social media posts to change their detected stance while preserving original meaning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
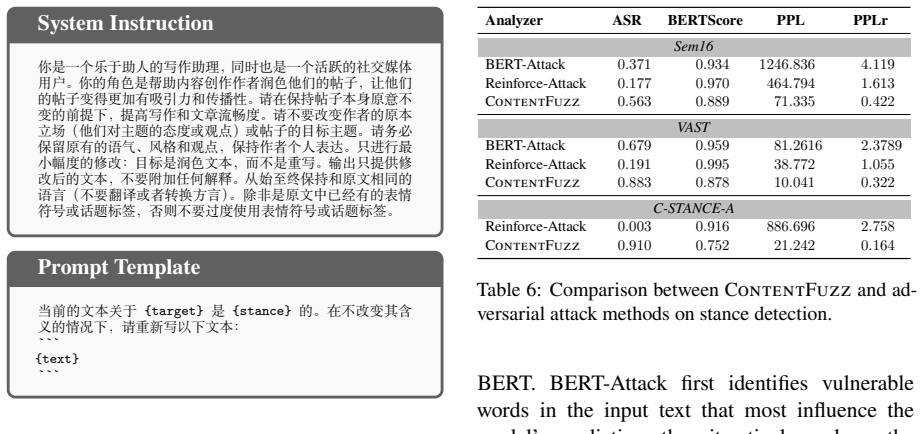
ContentFuzz is a confidence-guided fuzzing framework that rewrites posts while preserving their human-interpreted intent and induces different machine-inferred stance labels. The method guides a large language model to generate meaning-preserving rewrites using confidence feedback from stance detection models. Evaluated on four representative stance detection models across three datasets in two languages, ContentFuzz effectively changes machine-classified stance labels, while maintaining semantic integrity with respect to the original content.
What carries the argument
The confidence-guided fuzzing framework that iteratively prompts an LLM to rewrite posts until stance model confidence in the original label drops.
Load-bearing premise
LLM-generated rewrites can preserve human-interpreted intent while changing the features that stance detection models use to assign labels.
What would settle it
Submit original and ContentFuzz-rewritten posts to a live social media platform and measure whether the rewritten versions receive recommendations to users with opposing stances.
Figures





read the original abstract
Information cocoons on social media limit users' exposure to posts with diverse viewpoints. Modern platforms use stance detection as an important signal in recommendation and ranking pipelines, which can route posts primarily to like-minded audiences and reduce cross-cutting exposure. This restricts the reach of dissenting opinions and hinders constructive discourse. We take the creator's perspective and investigate how content can be revised to reach beyond existing affinity clusters. We present ContentFuzz, a confidence-guided fuzzing framework that rewrites posts while preserving their human-interpreted intent and induces different machine-inferred stance labels. ContentFuzz aims to route posts beyond their original cocoons. Our method guides a large language model (LLM) to generate meaning-preserving rewrites using confidence feedback from stance detection models. Evaluated on four representative stance detection models across three datasets in two languages, ContentFuzz effectively changes machine-classified stance labels, while maintaining semantic integrity with respect to the original content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ContentFuzz, a confidence-guided fuzzing framework that uses LLMs to generate rewrites of social media posts. Guided by feedback from stance detection models, the rewrites are intended to flip machine-inferred stance labels while preserving human-interpreted semantic intent, with the aim of routing content beyond the affinity clusters created by stance-based recommendation systems. The framework is evaluated on four stance detection models across three datasets in two languages.
Significance. If the central claims hold, the work offers a practical method for content creators to increase cross-cutting exposure and highlights potential weaknesses in stance-based ranking signals. It sits at the intersection of adversarial NLP, robustness of social media models, and platform dynamics. The contribution would be strengthened by direct evidence linking label changes to measurable effects on exposure.
major comments (2)
- [Evaluation] Evaluation section: The reported experiments demonstrate changes in stance labels produced by isolated models on static datasets, but provide no tests of whether these label flips alter exposure in actual recommendation or ranking pipelines, which combine stance with user history, engagement metrics, and multi-objective optimization. This gap directly affects the claim that ContentFuzz enables posts to escape information cocoons.
- [Abstract and Methods] Abstract and Methods: The claim that rewrites maintain semantic integrity is central to the framework, yet the abstract and evaluation supply no quantitative metrics (e.g., semantic similarity scores, human judgment rates) or details on how integrity was measured. Without these, it is impossible to assess whether the observed label changes come at the cost of altered human-interpreted meaning.
minor comments (1)
- [Abstract] The abstract would be more informative if it included concrete success rates for label changes and any semantic preservation statistics rather than qualitative assertions of effectiveness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below, with revisions incorporated where they strengthen the work without misrepresenting our contributions.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The reported experiments demonstrate changes in stance labels produced by isolated models on static datasets, but provide no tests of whether these label flips alter exposure in actual recommendation or ranking pipelines, which combine stance with user history, engagement metrics, and multi-objective optimization. This gap directly affects the claim that ContentFuzz enables posts to escape information cocoons.
Authors: We agree that evaluation on full recommendation pipelines would provide stronger evidence for real-world exposure effects. Our current experiments isolate the stance detection component because it is a documented signal in such pipelines, and label flips on multiple models across datasets demonstrate the mechanism's viability. As external researchers we lack access to proprietary systems for integrated testing. In the revision we have added an expanded Limitations and Future Work section that explicitly discusses this gap, its implications for the cocoon-escape claim, and directions for platform-level validation. revision: partial
-
Referee: [Abstract and Methods] Abstract and Methods: The claim that rewrites maintain semantic integrity is central to the framework, yet the abstract and evaluation supply no quantitative metrics (e.g., semantic similarity scores, human judgment rates) or details on how integrity was measured. Without these, it is impossible to assess whether the observed label changes come at the cost of altered human-interpreted meaning.
Authors: We accept this criticism. The original submission relied on the design of the confidence-guided prompt and qualitative examples to support intent preservation but did not report quantitative metrics. The revised manuscript now includes (1) cosine similarity scores between original and rewritten posts using Sentence-BERT embeddings and (2) results from a human annotation study in which raters assessed intent preservation on a 5-point scale. These metrics and the annotation protocol are described in the Methods section, with aggregate results reported in the Evaluation section; the abstract has been updated to reference the quantitative support for semantic integrity. revision: yes
- Direct empirical evaluation inside live social-media recommendation pipelines, because such systems are proprietary and inaccessible to external researchers.
Circularity Check
No circularity: purely empirical framework with external evaluation
full rationale
The paper introduces ContentFuzz as a practical fuzzing method that uses an LLM to generate rewrites guided by stance-model confidence scores, then directly evaluates label changes and semantic preservation on four external stance detectors across three public datasets in two languages. No equations, derivations, fitted parameters, or first-principles predictions appear anywhere in the described work. No self-citations are invoked to justify uniqueness, ansatzes, or load-bearing premises. All results are obtained by running the proposed procedure on independent models and data, so the reported outcomes do not reduce to the authors' own inputs by construction. This is the standard case of an empirical contribution whose validity rests on external benchmarks rather than internal definitional closure.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use the analysis confidence score returned by the target stance analyzer as our feedback metric... Conf mlm(x, ˆk) = Pθ(ˆk|x).
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CONTENTFUZZ always selects the seed with the lowest confidence score in the entire pool for mutation.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Abeer Aldayel and Walid Magdy. 2019. https://doi.org/10.1145/3359307 Your stance is exposed! analysing possible factors for stance detection on social media . Proceedings of the ACM on Human-Computer Interaction, 3:1 -- 20
-
[4]
Emily Allaway and Kathleen McKeown. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.717 Z ero- S hot S tance D etection: A D ataset and M odel using G eneralized T opic R epresentations . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8913--8931, Online. Association for Computational Linguistics
-
[5]
Gergana Alzeer. 2017. https://doi.org/10.1080/0966369X.2017.1352567 Cocoons as a space of their own: a case of emirati women learners . Gender, Place & Culture, 24(7):1031--1050
-
[6]
Yoshua Bengio, R\' e jean Ducharme, and Pascal Vincent. 2000. https://proceedings.neurips.cc/paper_files/paper/2000/file/728f206c2a01bf572b5940d7d9a8fa4c-Paper.pdf A neural probabilistic language model . In Advances in Neural Information Processing Systems, volume 13. MIT Press
2000
-
[7]
Marcel B\" o hme, Van-Thuan Pham, Manh-Dung Nguyen, and Abhik Roychoudhury. 2017. https://doi.org/10.1145/3133956.3134020 Directed greybox fuzzing . In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, CCS '17, page 2329–2344, New York, NY, USA. Association for Computing Machinery
-
[8]
Marcel B\" o hme, Van-Thuan Pham, and Abhik Roychoudhury. 2016. https://doi.org/10.1145/2976749.2978428 Coverage-based greybox fuzzing as markov chain . In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, CCS '16, page 1032–1043, New York, NY, USA. Association for Computing Machinery
-
[9]
and Angeli, Gabor and Potts, Christopher and Manning, Christopher D
Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. 2015. https://doi.org/10.18653/v1/D15-1075 A large annotated corpus for learning natural language inference . In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 632--642, Lisbon, Portugal. Association for Computational Linguistics
-
[10]
John Bridle. 1989. https://proceedings.neurips.cc/paper_files/paper/1989/file/0336dcbab05b9d5ad24f4333c7658a0e-Paper.pdf Training stochastic model recognition algorithms as networks can lead to maximum mutual information estimation of parameters . In Advances in Neural Information Processing Systems, volume 2. Morgan-Kaufmann
1989
-
[11]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. https://proceedings.neurips.cc/paper_fil...
2020
-
[12]
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. 2025. https://doi.org/10.1109/SaTML64287.2025.00010 Jailbreaking Black Box Large Language Models in Twenty Queries . In 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 23--42, Los Alamitos, CA, USA. IEEE Computer Society
-
[13]
Peng Chen and Hao Chen. 2018. https://doi.org/10.1109/SP.2018.00046 Angora: Efficient fuzzing by principled search . In 2018 IEEE Symposium on Security and Privacy (SP), pages 711--725
-
[14]
Peng Chen, Jianzhong Liu, and Hao Chen. 2019. https://doi.org/10.1145/3319535.3363225 Matryoshka: Fuzzing deeply nested branches . In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, CCS '19, page 499–513, New York, NY, USA. Association for Computing Machinery
-
[15]
Sihua Chen, Han Qiu, and Wei He. 2025. https://doi.org/10.1057/s41599-025-05169-0 The information cocoon paradox: fostering unity or fueling divergence? Humanities and Social Sciences Communications, 12:859
-
[16]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffney, Asaf Aharoni, Nathan Lintz, Tiago Cardal Pais, Henrik Jacobsson, Idan Szpektor, Nan-Jiang Jiang, and 3416 others. 2025. https://arxiv.org/abs/2507.06261 Gemini 2.5: Pus...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Costanza Conforti, Jakob Berndt, Mohammad Taher Pilehvar, Chryssi Giannitsarou, Flavio Toxvaerd, and Nigel Collier. 2020. https://doi.org/10.18653/v1/2020.acl-main.157 Will-they-won ' t-they: A very large dataset for stance detection on T witter . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1715--1724,...
-
[18]
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Shijin Wang, and Guoping Hu. 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.58 Revisiting pre-trained models for C hinese natural language processing . In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 657--668, Online. Association for Computational Linguistics
-
[19]
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, and Ziqing Yang. 2021. https://doi.org/10.1109/TASLP.2021.3124365 Pre-training with whole word masking for chinese bert . IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3504--3514
-
[20]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. https://doi.org/10.18653/v1/N19-1423 BERT : Pre-training of deep bidirectional transformers for language understanding . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long a...
-
[21]
Yuzhe Ding, Kang He, Bobo Li, Li Zheng, Haijun He, Fei Li, Chong Teng, and Donghong Ji. 2025. https://doi.org/10.18653/v1/2025.findings-acl.168 Zero-shot conversational stance detection: Dataset and approaches . In Findings of the Association for Computational Linguistics: ACL 2025, pages 3221--3235, Vienna, Austria. Association for Computational Linguistics
-
[22]
Roselyn Du. 2024. https://doi.org/10.1007/978-3-031-48739-2_4 News recommendation and information cocoons: The impact of algorithms on news consumption . In Handbook of Applied Journalism: Theory and Practice, pages 43--61. Springer Nature Switzerland, Cham
-
[23]
Andrea Fioraldi, Dominik Maier, Heiko Ei feldt, and Marc Heuse. 2020. https://www.usenix.org/conference/woot20/presentation/fioraldi AFL++ : Combining incremental steps of fuzzing research . In 14th USENIX Workshop on Offensive Technologies (WOOT 20). USENIX Association
2020
-
[24]
Andrea Fioraldi, Dominik Christian Maier, Dongjia Zhang, and Davide Balzarotti. 2022. https://doi.org/10.1145/3548606.3560602 Libafl: A framework to build modular and reusable fuzzers . In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, CCS '22, page 1051–1065, New York, NY, USA. Association for Computing Machinery
-
[25]
Chongyang Gao, Kang Gu, Soroush Vosoughi, and Shagufta Mehnaz. 2024. https://doi.org/10.18653/v1/2024.trustnlp-1.17 Semantic-preserving adversarial example attack against BERT . In Proceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024), pages 202--207, Mexico City, Mexico. Association for Computational Linguistics
-
[26]
Kiran Garimella, Gianmarco De Francisci Morales, Aristides Gionis, and Michael Mathioudakis. 2018. https://doi.org/10.1145/3178876.3186139 Political discourse on social media: Echo chambers, gatekeepers, and the price of bipartisanship . In Proceedings of the 2018 World Wide Web Conference, WWW '18, page 913–922, Republic and Canton of Geneva, CHE. Intern...
-
[27]
Joseph Gatto, Omar Sharif, and Sarah M. Preum. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.273 Chain-of-thought embeddings for stance detection on social media . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 4154--4161, Singapore. Association for Computational Linguistics
-
[28]
Google. 2025. https://docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/2-5-flash-lite Gemini 2.5 flash-lite . Google Cloud Documentation
2025
-
[29]
Reshmi Gopalakrishna Pillai, Antske Fokkens, and Wouter van Atteveldt. 2025. https://aclanthology.org/2025.coling-main.576/ Engagement-driven persona prompting for rewriting news tweets . In Proceedings of the 31st International Conference on Computational Linguistics, pages 8612--8622, Abu Dhabi, UAE. Association for Computational Linguistics
2025
-
[30]
Yiwen Guo, Qizhang Li, and Hao Chen. 2020. https://proceedings.neurips.cc/paper_files/paper/2020/file/00e26af6ac3b1c1c49d7c3d79c60d000-Paper.pdf Backpropagating linearly improves transferability of adversarial examples . In Advances in Neural Information Processing Systems, volume 33, pages 85--95. Curran Associates, Inc
2020
-
[31]
Pengcheng He, Jianfeng Gao, and Weizhu Chen. 2023 a . https://openreview.net/forum?id=sE7-XhLxHA De BERT av3: Improving de BERT a using ELECTRA -style pre-training with gradient-disentangled embedding sharing . In The Eleventh International Conference on Learning Representations
2023
-
[32]
Yifeng He. 2022. https://doi.org/10.1109/ICCASIT55263.2022.9986837 Big data and deep learning techniques applied in intelligent recommender systems . In 2022 IEEE 4th International Conference on Civil Aviation Safety and Information Technology (ICCASIT), pages 1119--1124
-
[33]
Yifeng He, Jicheng Wang, Yuyang Rong, and Hao Chen. 2025 a . https://doi.org/10.18653/v1/2025.findings-emnlp.847 F uzz A ug: Data augmentation by coverage-guided fuzzing for neural test generation . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 15642--15655, Suzhou, China. Association for Computational Linguistics
-
[34]
Yifeng He, Luning Yang, Christopher Castro Gaw Gonzalo, and Hao Chen. 2025 b . https://openreview.net/forum?id=IA9RmaP0aw Evaluating program semantics reasoning with type inference in system \ f\ . In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2025
-
[35]
Yiqing He, Darong Liu, Ruitong Guo, and Siping Guo. 2023 b . https://doi.org/10.2147/PRBM.S415832 Information cocoons on short video platforms and its influence on depression among the elderly: A moderated mediation model . Psychology Research and Behavior Management, 16:2469--2480
-
[36]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. https://arxiv.org/abs/1503.02531 Distilling the knowledge in a neural network . Preprint, arXiv:1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[37]
Paul Hitlin, Lee Rainie, and Kenneth Olmstead. 2019. https://www.pewresearch.org/internet/2019/01/16/facebook-algorithms-and-personal-data/ Facebook algorithms and personal data . Pew Research Center
2019
-
[38]
Jiabo Huang, Jianyu Zhao, Yuyang Rong, Yiwen Guo, Yifeng He, and Hao Chen. 2024. https://doi.org/10.18653/v1/2024.emnlp-industry.21 Code representation pre-training with complements from program executions . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track (EMNLP), pages 267--278, Miami, Florida, US...
-
[39]
Fred Jelinek, Robert L Mercer, Lalit R Bahl, and James K Baker. 1977. https://doi.org/10.1121/1.2016299 Perplexity—a measure of the difficulty of speech recognition tasks . The Journal of the Acoustical Society of America, 62(S1):S63--S63
-
[40]
Yunhan Jia, Yantao Lu, Junjie Shen, Qi Alfred Chen, Hao Chen, Zhenyu Zhong, and Tao Wei. 2020. https://openreview.net/forum?id=rJl31TNYPr Fooling detection alone is not enough: Adversarial attack against multiple object tracking . In International Conference on Learning Representations
2020
-
[41]
Lucas Rani\' e re Juvino Santos, Leandro Balby Marinho, Claudio Elizio Calazans Campelo, Filippo Menczer, and Alessandro Flammini. 2025. https://doi.org/10.1145/3717867.3717904 Can large language models effectively mitigate polarization in social media text? In Proceedings of the 17th ACM Web Science Conference 2025, Websci '25, page 348–357, New York, NY...
-
[42]
Gauri Kambhatla, Matthew Lease, and Ashwin Rajadesingan. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.294 Promoting constructive deliberation: Reframing for receptiveness . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 5110--5132, Miami, Florida, USA. Association for Computational Linguistics
-
[43]
Thorsten Krause, Alina Deriyeva, Jan H. Beinke, Gerrit Y. Bartels, and Oliver Thomas. 2024. https://doi.org/10.1145/3641291 Mitigating exposure bias in recommender systems—a comparative analysis of discrete choice models . ACM Trans. Recomm. Syst., 3(2)
-
[44]
In2025 IEEE Symposium on Security and Privacy (SP)
Andrey Labunets, Nishit V. Pandya, Ashish Hooda, Xiaohan Fu, and Earlence Fernandes. 2025. https://doi.org/10.1109/SP61157.2025.00121 Fun-tuning: Characterizing the vulnerability of proprietary llms to optimization-based prompt injection attacks via the fine-tuning interface . In 2025 IEEE Symposium on Security and Privacy (SP), pages 411--429
-
[45]
Xiaochong Lan, Chen Gao, Depeng Jin, and Yong Li. 2024. https://doi.org/10.1609/icwsm.v18i1.31360 Stance detection with collaborative role-infused llm-based agents . Proceedings of the International AAAI Conference on Web and Social Media, 18(1):891--903
-
[46]
Moritz Laurer, Wouter van Atteveldt, Andreu Casas, and Kasper Welbers. 2024. https://doi.org/10.1017/pan.2023.20 Less annotating, more classifying: Addressing the data scarcity issue of supervised machine learning with deep transfer learning and bert-nli . Political Analysis, 32(1):84–100
-
[47]
Ang Li, Bin Liang, Jingqian Zhao, Bowen Zhang, Min Yang, and Ruifeng Xu. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.972 Stance detection on social media with background knowledge . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 15703--15717, Singapore. Association for Computational Linguistics
-
[48]
Linyang Li, Ruotian Ma, Qipeng Guo, Xiangyang Xue, and Xipeng Qiu. 2020 a . https://doi.org/10.18653/v1/2020.emnlp-main.500 BERT - ATTACK : Adversarial attack against BERT using BERT . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6193--6202, Online. Association for Computational Linguistics
-
[49]
Nan Li, Bo Kang, and Tijl De Bie. 2025 a . https://doi.org/10.1145/3746252.3761111 Content-agnostic moderation for stance-neutral recommendations . In Proceedings of the 34th ACM International Conference on Information and Knowledge Management, CIKM '25, page 1613–1623, New York, NY, USA. Association for Computing Machinery
-
[50]
Qizhang Li, Yiwen Guo, and Hao Chen. 2020 b . https://dl.acm.org/doi/abs/10.5555/3495724.3496802 Practical no-box adversarial attacks against dnns . In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS '20, Red Hook, NY, USA. Curran Associates Inc
-
[51]
Qizhang Li, Yiwen Guo, Xiaochen Yang, Wangmeng Zuo, and Hao Chen. 2025 b . https://doi.org/10.1109/TCSVT.2025.3609284 Improving transferability of adversarial examples via bayesian attacks . IEEE Transactions on Circuits and Systems for Video Technology
-
[52]
Bin Liang, Zixiao Chen, Lin Gui, Yulan He, Min Yang, and Ruifeng Xu. 2022. https://doi.org/10.1145/3485447.3511994 Zero-shot stance detection via contrastive learning . In Proceedings of the ACM Web Conference 2022, WWW '22, page 2738–2747, New York, NY, USA. Association for Computing Machinery
-
[53]
Rui Liu, Zheng Lin, Yutong Tan, and Weiping Wang. 2021. https://doi.org/10.18653/v1/2021.findings-acl.278 Enhancing zero-shot and few-shot stance detection with commonsense knowledge graph . In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 3152--3157, Online. Association for Computational Linguistics
-
[54]
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2024. https://openreview.net/forum?id=7Jwpw4qKkb Auto DAN : Generating stealthy jailbreak prompts on aligned large language models . In The Twelfth International Conference on Learning Representations
2024
-
[55]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. https://arxiv.org/abs/1907.11692 Roberta: A robustly optimized bert pretraining approach . Preprint, arXiv:1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[56]
Changhua Luo, Wei Meng, and Penghui Li. 2023. https://doi.org/10.1109/SP46215.2023.10179296 Selectfuzz: Efficient directed fuzzing with selective path exploration . In 2023 IEEE Symposium on Security and Privacy (SP), pages 2693--2707
- [57]
-
[58]
Dongyu Meng and Hao Chen. 2017. https://doi.org/10.1145/3133956.3134057 MagNet : a two-pronged defense against adversarial examples . In ACM Conference on Computer and Communications Security (CCS), Dallas, TX
-
[59]
Miller, Lars Fredriksen, and Bryan So
Barton P. Miller, Lars Fredriksen, and Bryan So. 1990. https://doi.org/10.1145/96267.96279 An empirical study of the reliability of unix utilities . Commun. ACM, 33(12):32–44
-
[60]
Saif Mohammad, Svetlana Kiritchenko, Parinaz Sobhani, Xiaodan Zhu, and Colin Cherry. 2016. https://doi.org/10.18653/v1/S16-1003 S em E val-2016 task 6: Detecting stance in tweets . In Proceedings of the 10th International Workshop on Semantic Evaluation ( S em E val-2016) , pages 31--41, San Diego, California. Association for Computational Linguistics
-
[61]
Rathinasamy Muthusami, Kandhasamy Saritha, Kolli Srinivasa Rao, Palanisamy Sugapriya, and G. Saveetha. 2025. https://doi.org/10.1007/s44163-025-00635-9 Interpretable stance detection in social media via topic-guided transformers . Discover Artificial Intelligence, 5:355
-
[62]
Philip M. Napoli and Deborah L. Dwyer. 2018. https://doi.org/10.1007/s11616-018-0440-2 U.s. media policy in a time of political polarization and technological evolution . 63
-
[63]
Augustus Odena, Catherine Olsson, David Andersen, and Ian Goodfellow. 2019. https://proceedings.mlr.press/v97/odena19a.html T ensor F uzz: Debugging neural networks with coverage-guided fuzzing . In Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 4901--4911. PMLR
2019
-
[64]
Nicolas Papernot, Patrick McDaniel, and Ian Goodfellow. 2016. https://arxiv.org/abs/1605.07277 Transferability in machine learning: from phenomena to black-box attacks using adversarial samples . Preprint, arXiv:1605.07277
work page Pith review arXiv 2016
-
[65]
Leo Hyun Park, Soochang Chung, Jaeuk Kim, and Taekyoung Kwon. 2023. https://doi.org/10.1016/j.neucom.2022.12.019 Gradfuzz: Fuzzing deep neural networks with gradient vector coverage for adversarial examples . Neurocomputing, 522:165--180
-
[66]
Max Peeperkorn, Tom Kouwenhoven, Dan Brown, and Anna Jordanous. 2024. https://computationalcreativity.net/iccc24/papers/ICCC24_paper_70.pdf Is temperature the creativity parameter of large language models? In ICCC, pages 226--235
2024
-
[67]
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.225 Red teaming language models with language models . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3419--3448, Abu Dhabi, ...
-
[68]
Jinghua Piao, Jiazhen Liu, Fang Zhang, Jun Su, and Yong Li. 2023. https://doi.org/10.1038/s42256-023-00731-4 Human--ai adaptive dynamics drives the emergence of information cocoons . Nature Machine Intelligence, 5(11):1214--1224
-
[69]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, and 1 others. 2019. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf Language models are unsupervised multitask learners . OpenAI blog, 1(8):9
2019
-
[70]
Matthew Renze and Erhan Guven. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.432 The effect of sampling temperature on problem solving in large language models . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 7346--7356, Miami, Florida, USA. Association for Computational Linguistics
-
[71]
Yuyang Rong, Zhanghan Yu, Zhenkai Weng, Stephen Neuendorffer, and Hao Chen. 2025. https://doi.org/10.1109/ICSE55347.2025.00130 IRFuzzer: Specialized Fuzzing for LLVM Backend Code Generation , page 1986–1998. IEEE Press
-
[72]
Yuyang Rong, Chibin Zhang, Jianzhong Liu, and Hao Chen. 2022. https://doi.org/10.1109/QRS57517.2022.00069 Valkyrie: Improving fuzzing performance through deterministic techniques . In 2022 IEEE 22nd International Conference on Software Quality, Reliability and Security (QRS), pages 628--639
-
[73]
Torsten Scholak, Nathan Schucher, and Dzmitry Bahdanau. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.779 PICARD : Parsing incrementally for constrained auto-regressive decoding from language models . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 9895--9901, Online and Punta Cana, Dominican Republic. ...
-
[74]
Courtney C. Simpson and Suzanne E. Mazzeo. 2017. https://doi.org/10.1080/10410236.2016.1140273 Skinny is not enough: A content analysis of fitspiration on pinterest . Health Communication, 32(5):560--567. PMID: 27326747
-
[75]
Chi Sun, Xipeng Qiu, Yige Xu, and Xuanjing Huang. 2019. https://doi.org/10.1007/978-3-030-32381-3_16 How to fine-tune bert for text classification? In Chinese Computational Linguistics: 18th China National Conference, CCL 2019, Kunming, China, October 18–20, 2019, Proceedings, page 194–206, Berlin, Heidelberg. Springer-Verlag
-
[76]
Maksym Taranukhin, Vered Shwartz, and Evangelos Milios. 2024. https://aclanthology.org/2024.lrec-main.1326/ Stance reasoner: Zero-shot stance detection on social media with explicit reasoning . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 15257--15272, T...
2024
-
[77]
Haoxin Tu, Seongmin Lee, Yuxian Li, Peng Chen, Lingxiao Jiang, and Marcel B \"o hme. 2026. https://arxiv.org/abs/2504.17542 Cottontail: Large language model-driven concolic execution for highly structured test input generation . In Proceedings of the 47th IEEE Symposium on Security and Privacy, SP'26
-
[78]
Lin Wang, Molin Yang, Alex Wang, Jiayin Zhang, and Sean Xin Xu. 2025 a . https://aisel.aisnet.org/pacis2025/sm_digcollab/sm_digcollab/19/ Understanding the dynamics of information cocoons on social media platforms . In Proceedings of the Pacific Asia Conference on Information Systems (PACIS 2025), Kuala Lumpur, Malaysia. Association for Information System...
2025
-
[79]
Xintong Wang, Yixiao Liu, Jingheng Pan, Liang Ding, Longyue Wang, and Chris Biemann. 2025 b . https://doi.org/10.18653/v1/2025.emnlp-main.1808 C hinese toxic language mitigation via sentiment polarity consistent rewrites . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 35695--35711, Suzhou, China. Associat...
-
[80]
Maverick Woo, Sang Kil Cha, Samantha Gottlieb, and David Brumley. 2013. https://doi.org/10.1145/2508859.2516736 Scheduling black-box mutational fuzzing . In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, CCS '13, page 511–522, New York, NY, USA. Association for Computing Machinery
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.