Recognition: no theorem link
CUE-R: Beyond the Final Answer in Retrieval-Augmented Generation
Pith reviewed 2026-05-10 19:15 UTC · model grok-4.3
The pith
CUE-R shows that perturbing single evidence items in RAG uncovers utility effects missed by final-answer evaluation alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CUE-R perturbs individual evidence items via REMOVE, REPLACE, and DUPLICATE operators, then tracks changes along three utility axes plus a trace-divergence signal. REMOVE and REPLACE consistently reduce correctness and proxy grounding while producing large trace shifts; DUPLICATE is frequently answer-redundant yet not fully behaviorally neutral. A zero-retrieval control confirms the observed effects arise from loss of meaningful retrieval rather than generic perturbation artifacts, and a two-support ablation shows that multi-hop evidence items interact non-additively.
What carries the argument
CUE-R, the intervention framework that applies REMOVE, REPLACE, and DUPLICATE operators to single evidence items and measures resulting shifts across correctness, proxy-based grounding faithfulness, confidence error, and observable retrieval-use traces.
If this is right
- Answer-only evaluation misses important per-evidence effects on correctness and grounding.
- Multi-hop evidence items interact non-additively: removing both supports harms performance more than removing either one alone.
- DUPLICATE operations show that answer redundancy does not guarantee full behavioral neutrality.
- Intervention-based utility analysis serves as a practical complement to citation faithfulness or final-answer metrics in RAG evaluation.
Where Pith is reading between the lines
- Similar perturbation tests could be used to rank or prune evidence during retrieval to improve efficiency without sacrificing accuracy.
- Extending the operators to multi-turn or agentic settings might reveal how evidence utility changes across conversation turns.
- The observed non-additive interactions suggest that joint utility of evidence sets, rather than independent item scores, may be needed for optimal retrieval.
Load-bearing premise
That shallow observable traces together with the three chosen utility axes capture the operational utility of each evidence item without missing deeper internal model effects or introducing artifacts from the perturbation operators.
What would settle it
An experiment in which removing a relevant evidence item produces no measurable change in traces, correctness, or grounding would contradict the claim that CUE-R detects per-item utility shifts.
Figures



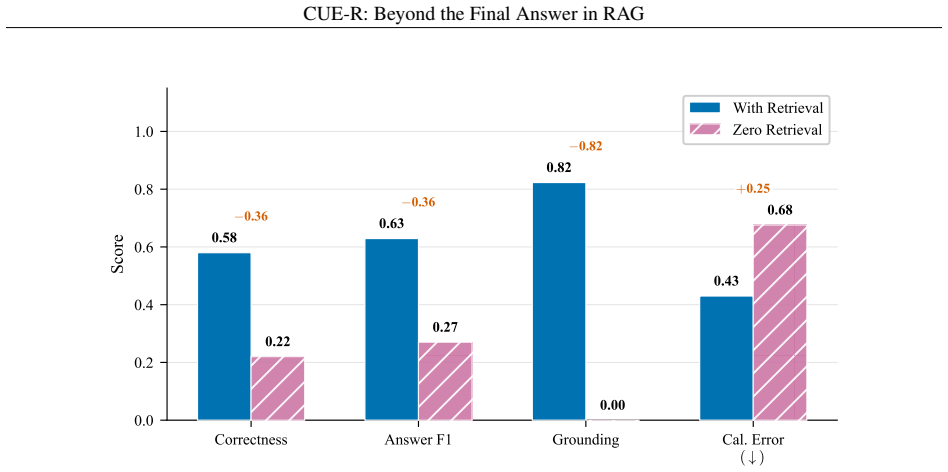
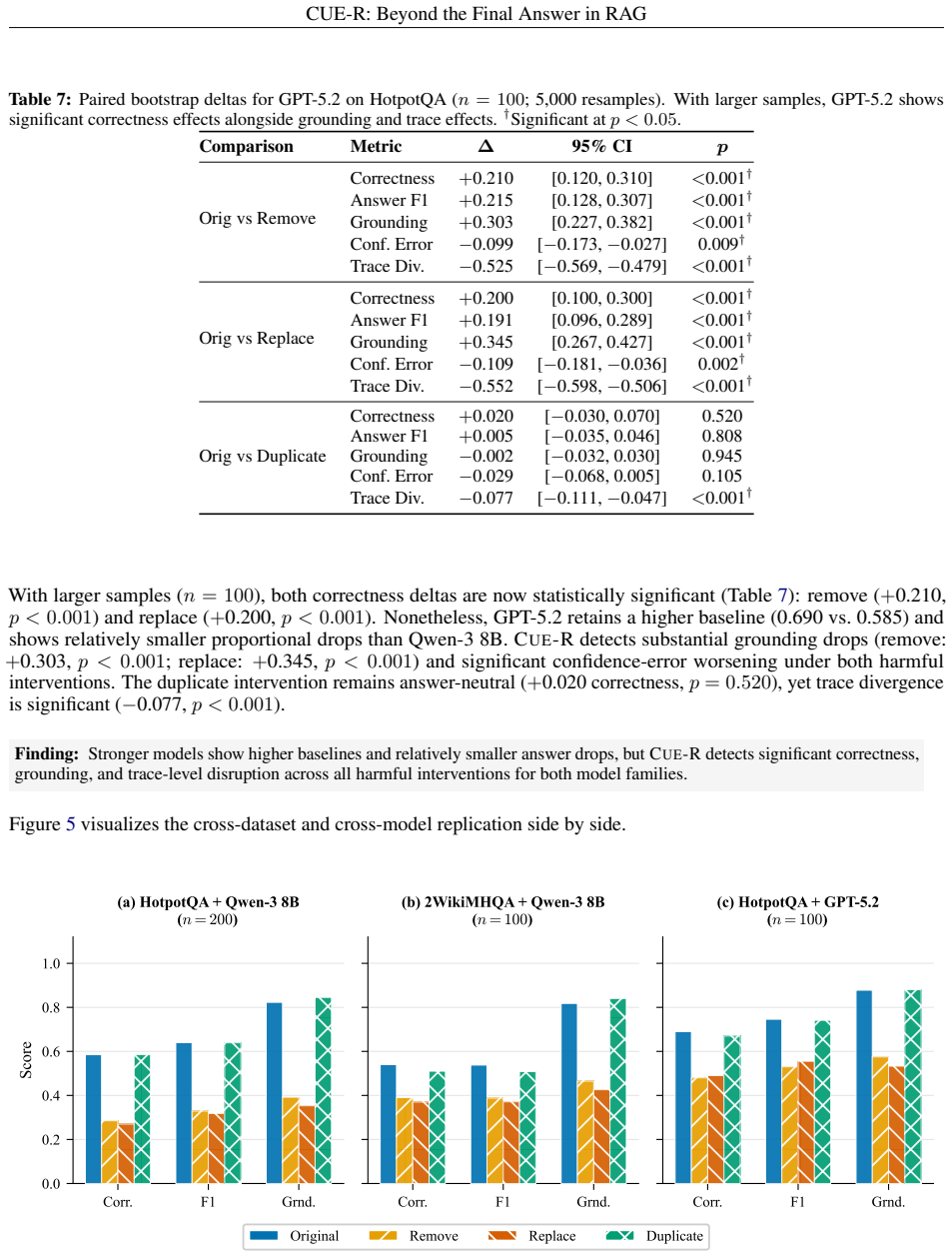
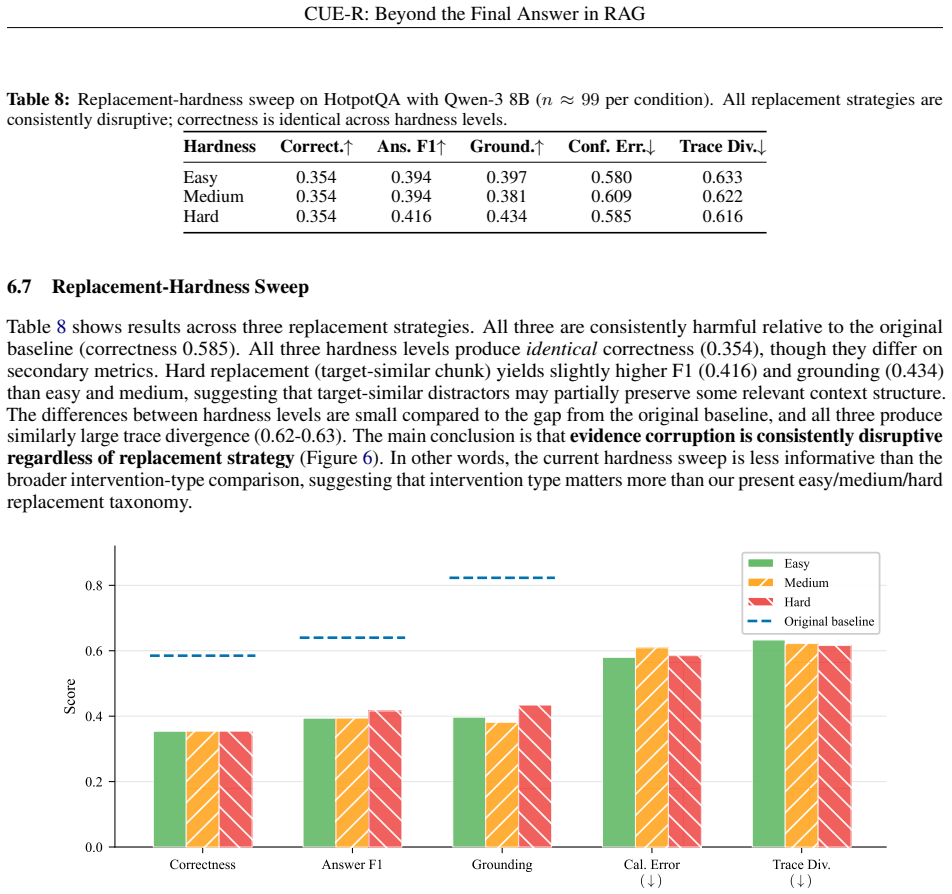
read the original abstract
As language models shift from single-shot answer generation toward multi-step reasoning that retrieves and consumes evidence mid-inference, evaluating the role of individual retrieved items becomes more important. Existing RAG evaluation typically targets final-answer quality, citation faithfulness, or answer-level attribution, but none of these directly targets the intervention-based, per-evidence-item utility view we study here. We introduce CUE-R, a lightweight intervention-based framework for measuring per-evidence-item operational utility in single-shot RAG using shallow observable retrieval-use traces. CUE-R perturbs individual evidence items via REMOVE, REPLACE, and DUPLICATE operators, then measures changes along three utility axes (correctness, proxy-based grounding faithfulness, and confidence error) plus a trace-divergence signal. We also outline an operational evidence-role taxonomy for interpreting intervention outcomes. Experiments on HotpotQA and 2WikiMultihopQA with Qwen-3 8B and GPT-5.2 reveal a consistent pattern: REMOVE and REPLACE substantially harm correctness and grounding while producing large trace shifts, whereas DUPLICATE is often answer-redundant yet not fully behaviorally neutral. A zero-retrieval control confirms that these effects arise from degradation of meaningful retrieval. A two-support ablation further shows that multi-hop evidence items can interact non-additively: removing both supports harms performance far more than either single removal. Our results suggest that answer-only evaluation misses important evidence effects and that intervention-based utility analysis is a practical complement for RAG evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CUE-R, a lightweight intervention-based framework for assessing per-evidence operational utility in single-shot RAG. It applies REMOVE, REPLACE, and DUPLICATE perturbations to individual retrieved items and tracks changes along correctness, proxy-based grounding faithfulness, confidence error, and trace-divergence axes, supplemented by an operational evidence-role taxonomy. Experiments on HotpotQA and 2WikiMultihopQA with Qwen-3 8B and GPT-5.2 demonstrate that REMOVE and REPLACE substantially degrade correctness and grounding with large trace shifts, while DUPLICATE is often answer-redundant yet behaviorally non-neutral; these are supported by a zero-retrieval control and a two-support ablation showing non-additive multi-hop interactions. The central claim is that answer-only evaluation misses important per-evidence effects.
Significance. If the empirical patterns hold after addressing controls, CUE-R offers a practical, intervention-driven complement to existing RAG metrics focused on final answers or citations. The multi-dataset, multi-model design with explicit ablations provides a reproducible template for finer-grained evidence utility analysis, which could inform better retrieval strategies and multi-hop reasoning diagnostics in the field.
major comments (2)
- [zero-retrieval control and experiments] The zero-retrieval control (described in the abstract and experiments) rules out total absence of retrieval but does not isolate operator-specific artifacts: REMOVE shortens the prompt, DUPLICATE lengthens it, and REPLACE alters content distribution. These structural changes can independently affect attention patterns, generation length, and confidence scores, risking attribution of format sensitivity to 'evidence utility' rather than the semantic role of the item. Length-matched neutral perturbations or format-preserving controls would be needed to support the per-evidence interpretation.
- [results] The results report consistent patterns across datasets and models but provide no error bars, run-to-run variance, or statistical significance tests for the observed changes in correctness, grounding, or trace divergence. Without these, the strength of the claim that DUPLICATE is 'not fully behaviorally neutral' and that REMOVE/REPLACE produce 'substantially' larger effects remains difficult to assess quantitatively.
minor comments (2)
- [abstract] The abstract introduces 'proxy-based grounding faithfulness' without a one-sentence definition or pointer to its exact computation; a brief clarification here would improve accessibility.
- [taxonomy section] The operational evidence-role taxonomy is outlined but its concrete mapping rules from intervention outcomes to roles (e.g., how trace-divergence thresholds are applied) could be expanded with an example table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where we will revise the manuscript to strengthen the work.
read point-by-point responses
-
Referee: [zero-retrieval control and experiments] The zero-retrieval control (described in the abstract and experiments) rules out total absence of retrieval but does not isolate operator-specific artifacts: REMOVE shortens the prompt, DUPLICATE lengthens it, and REPLACE alters content distribution. These structural changes can independently affect attention patterns, generation length, and confidence scores, risking attribution of format sensitivity to 'evidence utility' rather than the semantic role of the item. Length-matched neutral perturbations or format-preserving controls would be needed to support the per-evidence interpretation.
Authors: We agree that the structural changes introduced by the operators (length and content distribution) could act as confounds. The zero-retrieval control was intended to show that effects arise from removing or altering meaningful evidence rather than from having no retrieval at all. To isolate semantic utility more cleanly, we will add length-matched neutral perturbation controls in the revision, such as padding with dummy tokens or neutral strings that preserve format and length without semantic content. This will allow us to quantify any format-driven effects separately. revision: yes
-
Referee: [results] The results report consistent patterns across datasets and models but provide no error bars, run-to-run variance, or statistical significance tests for the observed changes in correctness, grounding, or trace divergence. Without these, the strength of the claim that DUPLICATE is 'not fully behaviorally neutral' and that REMOVE/REPLACE produce 'substantially' larger effects remains difficult to assess quantitatively.
Authors: We accept that variance reporting and significance testing would make the quantitative claims more robust. The original experiments showed consistent directional patterns across both datasets and models, but did not include multiple seeded runs or statistical tests. In the revised manuscript we will rerun key conditions with multiple random seeds (where model stochasticity permits), report standard deviations or error bars on the deltas for correctness, grounding, and trace divergence, and apply paired statistical tests (e.g., Wilcoxon signed-rank) to assess the significance of the observed effects, including the non-neutrality of DUPLICATE. revision: yes
Circularity Check
No circularity: empirical intervention measurements are direct observations
full rationale
The paper introduces CUE-R as an intervention-based framework that applies explicit REMOVE/REPLACE/DUPLICATE operators to individual evidence items and records measured deltas in correctness, proxy grounding faithfulness, confidence error, and trace divergence on HotpotQA and 2WikiMultihopQA. These quantities are obtained by running the model on the perturbed inputs and comparing outputs; they are not obtained by fitting parameters to a target variable and then relabeling the fit as a prediction, nor by self-referential definitions, nor by load-bearing self-citations that close the argument. The operational taxonomy is derived post-hoc from the observed intervention outcomes rather than presupposed. The zero-retrieval control and two-support ablation are likewise direct experimental contrasts. The derivation chain is therefore self-contained experimental reporting with no reduction of claimed results to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Intervention operators (REMOVE, REPLACE, DUPLICATE) isolate per-evidence utility without confounding the model's internal reasoning process.
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, volume 33, pages 9459–9474, 2020
2020
-
[2]
Improving language models by retrieving from trillions of tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. InInternational Conference on Machine Learning, pages 2206–2240. PMLR, 2022
2022
-
[3]
REALM: Retrieval-augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. REALM: Retrieval-augmented language model pre-training. InInternational Conference on Machine Learning, pages 3929–3938. PMLR, 2020
2020
-
[4]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023
2023
-
[5]
Self-RAG: Learning to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG: Learning to retrieve, generate, and critique through self-reflection. InInternational Conference on Learning Representations, 2024
2024
-
[6]
Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. InProceedings of the Conference on Empirical Methods in Natural Language Processing, pages 7969–7992, 2023
2023
-
[7]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024
2024
-
[8]
Benchmarking large language models in retrieval-augmented generation
Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun. Benchmarking large language models in retrieval-augmented generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17754–17762, 2024
2024
-
[9]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning. arXiv preprint arXiv:2307.13702, 2023
work page Pith review arXiv 2023
-
[10]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[11]
AgentBench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. AgentBench: Evaluating LLMs as agents. InInternational Conference on Learning Representations, 2024
2024
-
[12]
API-Bank: A comprehensive benchmark for tool-augmented LLMs
Minghao Li, Feifan Song, Bowen Yu, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API-Bank: A comprehensive benchmark for tool-augmented LLMs. InProceedings of the Conference on Empirical Methods in Natural Language Processing, pages 3102–3116, 2023
2023
-
[13]
Cohen, Ruslan Salakhutdinov, and Christo- pher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christo- pher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, 2018
2018
-
[14]
Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, 2020
2020
-
[15]
Selection-inference: Exploiting large language models for interpretable logical reasoning
Antonia Creswell, Murray Shanahan, and Irina Higgins. Selection-inference: Exploiting large language models for interpretable logical reasoning. InInternational Conference on Learning Representations, 2023
2023
-
[16]
Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, volume 35, pages 24824–24837, 2022
2022
-
[17]
Enabling large language models to generate text with citations
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. Enabling large language models to generate text with citations. InProceedings of the Conference on Empirical Methods in Natural Language Processing, pages 6465–6488, 2023. 18 CUE-R: Beyond the Final Answer in RAG
2023
-
[18]
arXiv preprint arXiv:2212.08037 , year=
Bernd Bohnet, Vinh Q. Tran, Pat Verga, Roee Aharoni, Daniel Andor, Jason Baldridge, Massimiliano Ciaramita, Jacob Eisenstein, Kuzman Ganchev, Jonathan Herzig, et al. Attributed question answering: Evaluation and modeling for attributed large language models.arXiv preprint arXiv:2212.08037, 2022
-
[19]
Adaptive chameleon or stubborn sloth: Reveal- ing the behavior of large language models in knowledge conflicts
Jian Xie, Kai Zhang, Jiangjie Chen, Renze Lou, and Yu Su. Adaptive chameleon or stubborn sloth: Reveal- ing the behavior of large language models in knowledge conflicts. InInternational Conference on Learning Representations, 2024
2024
-
[20]
Risk of misinformation in retrieval-augmented generation with large language models
Yue Pan, Yonghao He, et al. Risk of misinformation in retrieval-augmented generation with large language models. arXiv preprint arXiv:2305.14552, 2023
-
[21]
KILT: A benchmark for knowledge intensive language tasks
Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, et al. KILT: A benchmark for knowledge intensive language tasks. InProceedings of the Conference of the North American Chapter of the Association for Computational Linguistics, pages 2523–2544, 2021
2021
-
[22]
Evaluation of retrieval- augmented generation: A survey.CoRR, abs/2405.07437,
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, and Zhaofeng Liu. Evaluation of retrieval-augmented generation: A survey.arXiv preprint arXiv:2405.07437, 2024
-
[23]
RAGChecker: A fine-grained framework for diagnosing retrieval-augmented generation
Dongyu Ru, Lin Qiu, Xiangkun Hu, Tianhang Zhang, Peng Shi, Shuaichen Chang, Jiayang Cheng, Cunxiang Wang, Shichao Sun, Huanyu Li, Zizhao Zhang, Binjie Wang, Jiarong Jiang, Tong He, Zhiguo Wang, Pengfei Liu, Yue Zhang, and Zheng Zhang. RAGChecker: A fine-grained framework for diagnosing retrieval-augmented generation. InAdvances in Neural Information Proce...
2024
-
[24]
Correctness is not faithfulness in RAG attributions
Jonas Wallat, Maria Heuss, Maarten de Rijke, and Avishek Anand. Correctness is not faithfulness in RAG attributions. InProceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in Information Retrieval (ICTIR), 2025
2025
-
[25]
Groundedness in retrieval-augmented long-form generation: An empirical study
Alessandro Stolfo. Groundedness in retrieval-augmented long-form generation: An empirical study. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 1537–1552, 2024
2024
-
[26]
Evidence contextualization and counterfactual attribution for conversational QA over heterogeneous data with RAG systems
Rishiraj Saha Roy, Joel Schlotthauer, Chris Hinze, Andreas Foltyn, Luzian Hahn, and Fabian Kuech. Evidence contextualization and counterfactual attribution for conversational QA over heterogeneous data with RAG systems. InProceedings of the 18th ACM International Conference on Web Search and Data Mining (WSDM), 2025
2025
-
[27]
The probabilistic relevance framework: BM25 and beyond.Foundations and Trends in Information Retrieval, 3(4):333–389, 2009
Stephen Robertson and Hugo Zaragoza. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends in Information Retrieval, 3(4):333–389, 2009
2009
-
[28]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. In International Conference on Machine Learning, pages 1321–1330, 2017
2017
-
[30]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
answer": your short answer,
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the Conference on Empirical Methods in Natural Language Processing, pages 6769–6781, 2020. A Bootstrap Confidence Intervals Table 11:Intervention means with 95% boots...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.