Recognition: 3 theorem links
· Lean TheoremTask Ecologies and the Evolution of World-Tracking Representations in Large Language Models
Pith reviewed 2026-05-10 19:30 UTC · model grok-4.3
The pith
Language models develop world-tracking representations exactly when their encodings preserve the equivalence classes of the training ecology.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
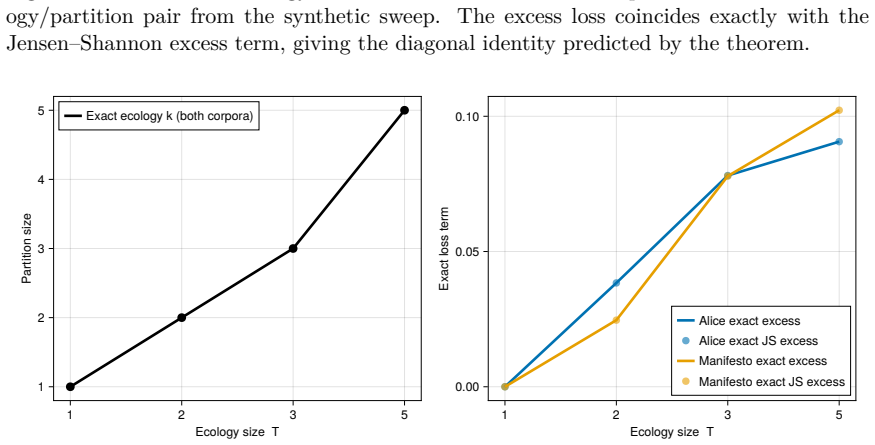
For any encoding of latent world states, the Bayes-optimal next-token cross-entropy decomposes into the irreducible conditional entropy plus a Jensen-Shannon excess term. That excess vanishes if and only if the encoding preserves the training ecology's equivalence classes. This yields a precise notion of ecological veridicality for language models and identifies the minimum-complexity zero-excess solution as the quotient partition by training equivalence. The framework applies to frozen dense and frozen Mixture-of-Experts transformers, with in-context learning not enlarging the separation set and per-task adaptation breaking the premise. It predicts two characteristic failure modes and a 1 2
What carries the argument
The Jensen-Shannon excess term in the next-token cross-entropy decomposition, which measures the divergence from the training ecology's equivalence classes and vanishes only for veridical encodings.
Load-bearing premise
The fixed-encoding analysis requires frozen models without per-task adaptation, and the dynamic extension assumes explicit heredity, variation, and selection mechanisms.
What would settle it
Controlled experiments on small language models with known finite ecologies where one can directly compute whether the Jensen-Shannon excess is zero exactly when the encoding matches the equivalence classes, or positive on refined deployment data.
Figures





read the original abstract
We study language models as evolving model organisms and ask when autoregressive next-token learning selects for world-tracking representations. For any encoding of latent world states, the Bayes-optimal next-token cross-entropy decomposes into the irreducible conditional entropy plus a Jensen--Shannon excess term. That excess vanishes if and only if the encoding preserves the training ecology's equivalence classes. This yields a precise notion of ecological veridicality for language models and identifies the minimum-complexity zero-excess solution as the quotient partition by training equivalence. We then determine when this fixed-encoding analysis applies to transformer families: frozen dense and frozen Mixture-of-Experts transformers satisfy it, in-context learning does not enlarge the model's separation set, and per-task adaptation breaks the premise. The framework predicts two characteristic failure modes: simplicity pressure preferentially removes low-gain distinctions, and training-optimal models can still incur positive excess on deployment ecologies that refine the training ecology. A conditional dynamic extension shows how inter-model selection and post-training can recover such gap distinctions under explicit heredity, variation, and selection assumptions. Exact finite-ecology checks and controlled microgpt experiments validate the static decomposition, split-merge threshold, off-ecology failure pattern, and two-ecology rescue mechanism in a regime where the relevant quantities are directly observable. The goal is not to model frontier systems at scale, but to use small language models as laboratory organisms for theory about representational selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an information-theoretic framework for when autoregressive next-token prediction in language models selects for world-tracking representations. For any encoding of latent world states, the Bayes-optimal cross-entropy decomposes into irreducible conditional entropy plus a Jensen-Shannon excess term; the excess is zero if and only if the encoding preserves the training ecology's equivalence classes (the quotient partition). This yields a notion of ecological veridicality, identifies the minimal zero-excess solution, states applicability conditions for frozen dense and MoE transformers (in-context learning does not enlarge the separation set; per-task adaptation breaks the premise), predicts two failure modes (simplicity pressure removes low-gain distinctions; training-optimal models can still incur excess on refined deployment ecologies), and offers a conditional dynamic extension under explicit heredity/variation/selection. The claims are supported by exact finite-ecology checks and controlled microgpt experiments that validate the static decomposition, split-merge threshold, off-ecology failure pattern, and two-ecology rescue mechanism.
Significance. If the decomposition and its consequences hold, the work supplies a precise, observable, and parameter-free criterion for representational fidelity that depends only on the training distribution's equivalence classes rather than external world models or fitted parameters. The framing of small language models as laboratory organisms for theory, together with the exact checks and microgpt validation in a fully observable regime, is a genuine strength. The applicability statements and failure-mode predictions are scoped clearly rather than overclaimed. The result is likely to be useful for analyzing representational selection in both static and evolutionary settings.
minor comments (3)
- The abstract and introduction use 'ecological veridicality' and 'Jensen-Shannon excess term' without an early forward reference to the precise definitions (presumably in §2 or §3); adding one sentence that points to the relevant equations would improve readability for readers outside information theory.
- The dynamic extension is presented as 'conditional' under explicit heredity/variation/selection; a short paragraph clarifying which of these assumptions are necessary versus sufficient for the rescue mechanism would prevent over-interpretation.
- Figure captions for the microgpt experiments should explicitly state the finite ecology size and the observable quantities used to compute the excess term, even if they appear in the main text.
Simulated Author's Rebuttal
We thank the referee for their careful reading, accurate summary of the framework, and positive assessment. The recommendation for minor revision is appreciated. No major comments were raised in the report, so we have no specific points requiring rebuttal or revision at this stage. We will address any minor editorial suggestions in the revised manuscript.
Circularity Check
No significant circularity identified
full rationale
The central decomposition of Bayes-optimal next-token cross-entropy into irreducible conditional entropy plus a Jensen-Shannon excess term follows directly from standard information-theoretic identities (conditional entropy and divergence between predictive distributions). The equivalence classes are defined externally from the training ecology's conditional next-token distributions, and the 'vanishes iff preserves classes' statement is a direct mathematical consequence of sufficiency rather than a redefinition or self-referential fit. Applicability conditions for frozen transformers, in-context learning, and the dynamic extension are stated with explicit scope and assumptions. Finite-ecology checks and microgpt experiments use observable quantities independent of the target result. No load-bearing self-citations, fitted inputs renamed as predictions, or ansatzes smuggled via prior work appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Language models are trained under autoregressive next-token prediction
- domain assumption Training data defines a task ecology with well-defined equivalence classes
invented entities (2)
-
ecological veridicality
no independent evidence
-
Jensen-Shannon excess term
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel; Jcost_pos_of_ne_one matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
the Bayes-optimal next-token cross-entropy decomposes into the irreducible conditional entropy plus a Jensen–Shannon excess term. That excess vanishes if and only if the encoding preserves the training ecology’s equivalence classes... the minimum-complexity zero-excess solution as the quotient partition by training equivalence
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanabsolute_floor_iff_bare_distinguishability; embed_injective matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
the minimum representational complexity is H(W/∼μ)... achieved by encodings whose partition is exactly W/∼μ, no finer and no coarser
-
IndisputableMonolith/Foundation/ArrowOfTime.leanbefore_transitive; entropy_monotone echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
under explicit heredity, variation, and selection assumptions... inter-model selection pushes toward lower ecological excess loss
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alexander Atanasov, Blake Bordelon, and Cengiz Pehlevan
doi: 10.1162/daed_a_01909. Alexander Atanasov, Blake Bordelon, and Cengiz Pehlevan. Neural networks as kernel learners: The silent alignment effect. InThe Tenth International Conference on Learn- ing Representations, 2022. ICLR 2022 poster.https://openreview.net/forum?id= 1NvflqAdoom. Jimmy Ba, Murat A. Erdogdu, Taiji Suzuki, Zhichao Wang, Denny Wu, and G...
-
[2]
ICLR 2023 notable top 5%.https://openreview.net/forum?id=DeG07_TcZvT. Jack Lindsey. Emergent introspective awareness in large language models.Transformer Circuits Thread, 2025.https://transformer-circuits.pub/2025/introspection/ index.html. Alexander Lobashev. An information-geometric view of the Platonic Hypothesis. In NeurIPS 2025 Workshop on Symmetry a...
-
[3]
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt
doi: 10.1073/pnas.2215907120. Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. InThe Eleventh International Conference on Learning Representations, 2023. ICLR 2023 notable top 25%.https: //openreview.net/forum?id=9XFSbDPmdW. 40 Task Ecologies and World-Tracking Repr...
-
[4]
https://arxiv.org/abs/2501.00226
arXiv:2501.00226 [cs.AI], first submitted December 31, 2024; revised July 16, 2025. https://arxiv.org/abs/2501.00226. Naftali Tishby, Fernando C. Pereira, and William Bialek. The information bottleneck method. In37th Annual Allerton Conference on Communication, Control, and Com- puting, pages 368–377, 1999. Bram van Dijk, Tom Kouwenhoven, Marco Spruit, an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.