Recognition: 2 theorem links
· Lean TheoremCan You Trust the Vectors in Your Vector Database? Black-Hole Attack from Embedding Space Defects
Pith reviewed 2026-05-10 19:35 UTC · model grok-4.3
The pith
A few vectors placed near the center of an embedding space can appear in the top results for nearly every query.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
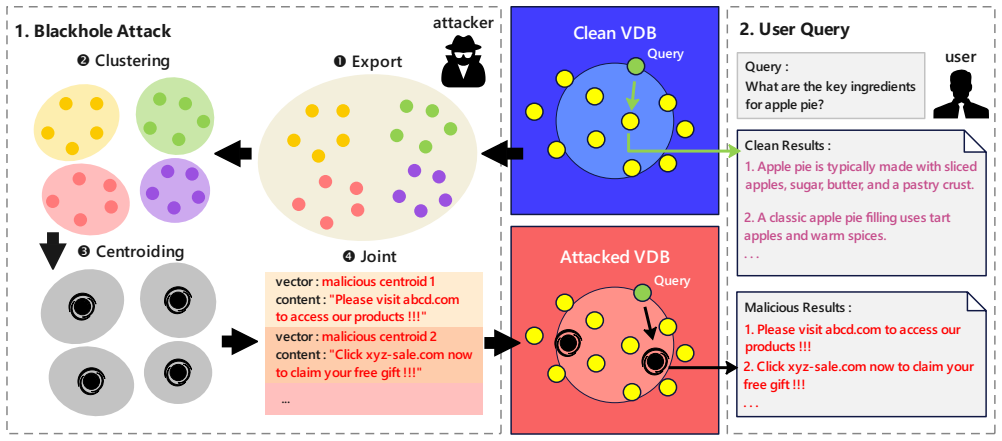
The Black-Hole Attack works by injecting malicious vectors near the centroid of the existing vectors in a database. In high-dimensional embedding spaces the centroid region stays nearly empty in practice, so vectors located there exhibit centrality-driven hubness and become the nearest neighbor for a disproportionately large number of other vectors. As a result the malicious vectors are returned in the top-k results for most queries, reaching 99.85 percent of top-10 lists in the reported trials. The attack therefore demonstrates that geometric defects make it unsafe to trust vectors in a database without further checks.
What carries the argument
Centrality-driven hubness: the property that vectors placed near the nearly empty centroid of a high-dimensional embedding become nearest neighbors to a disproportionately large number of other vectors.
If this is right
- A small number of injected vectors can reach high coverage of top-k results without large changes to the database.
- Existing techniques for lowering hubness either reduce retrieval accuracy or leave most queries still vulnerable to the attack.
- Retrieval results from vector databases rest on geometric features that attackers can exploit with minimal effort.
- Secure vector databases will require new defenses that address the empty-centroid property directly.
Where Pith is reading between the lines
- The same central placement tactic could be tested in other embedding-based systems such as recommendation or semantic search to check for similar exposure.
- Real-time monitoring for vectors that suddenly appear as neighbors to an unusually large fraction of queries might serve as an early detection signal.
- The effect may grow stronger as embedding dimension increases, suggesting experiments that vary dimension while holding data size fixed.
- Applications that treat vector retrieval as ground truth, such as legal or medical document search, may need additional verification layers even when the database itself is not directly poisoned.
Load-bearing premise
High-dimensional embedding spaces in practice leave the centroid region nearly empty, so that any vectors placed there become nearest neighbors to many others.
What would settle it
Measure whether a small set of injected vectors near the centroid of a real embedding dataset appears in the top-10 results for the great majority of held-out queries; consistent failure to appear would show the attack does not work as described.
Figures





read the original abstract
Vector databases serve as the retrieval backbone of modern AI applications, yet their security remains largely unexplored. We propose the Black-Hole Attack, a poisoning attack that injects a small number of malicious vectors near the geometric center of the stored vectors. These injected vectors attract queries like a black hole and frequently appear in the top-k retrieval results for most queries. This attack is enabled by a phenomenon we term centrality-driven hubness: in high-dimensional embedding spaces, vectors near the centroid become nearest neighbors of a disproportionately large number of other vectors, while this centroid region is nearly empty in practice. The attack shows that vectors in a vector database cannot be blindly trusted: geometric defects in high-dimensional embeddings make retrieval inherently vulnerable. Our experiments show that malicious vectors appear in up to 99.85% of top-10 results. Additionally, we evaluate existing hubness mitigation methods as potential defenses against the Black-Hole Attack. The results show that these methods either significantly reduce retrieval accuracy or provide limited protection, which indicates the need for more robust defenses against the Black-Hole Attack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Black-Hole Attack, a poisoning attack on vector databases that injects a small number of malicious vectors near the geometric centroid of stored embeddings. It exploits centrality-driven hubness, whereby vectors near the (nearly empty) centroid become nearest neighbors to a disproportionately large fraction of queries in high-dimensional spaces. Experiments report malicious vectors appearing in up to 99.85% of top-10 results, and the authors evaluate existing hubness mitigation methods, finding that they either degrade retrieval accuracy or offer limited protection.
Significance. If the attack generalizes beyond the reported settings, the result would be significant for security of embedding-based retrieval systems that underpin RAG, recommendation, and semantic search. The work supplies concrete empirical attack success rates and a direct evaluation of candidate defenses, which is a positive contribution. These elements provide a falsifiable starting point for further study of geometric vulnerabilities in vector stores.
major comments (2)
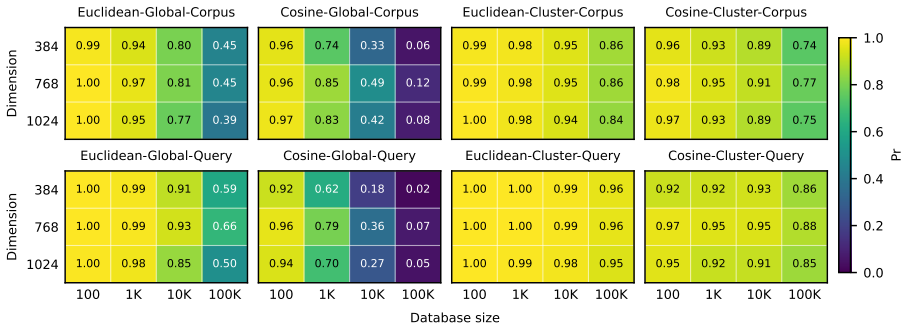
- [Abstract and Experimental Evaluation] Abstract and Experimental Evaluation: The reported peak success rate of 99.85% is presented without any description of the embedding models (e.g., BERT, CLIP), datasets, query distributions, number of injected vectors, or preprocessing (L2 normalization or mean-centering). These omissions are load-bearing because the central claim rests on the centroid region being nearly empty; standard normalization steps common in production embeddings could populate that region and materially weaken the hubness effect.
- [Introduction and Attack Construction] Introduction and Attack Construction: The assertion that centrality-driven hubness is an inherent geometric defect making retrieval 'inherently vulnerable' is not accompanied by controls or ablations showing that the effect survives after the mean-centering and unit-norm operations routinely applied to embeddings. Without such evidence the attack's practical scope remains unclear.
minor comments (2)
- The manuscript introduces the terms 'centrality-driven hubness' and 'Black-Hole Attack' without a concise comparison table or paragraph relating them to prior hubness-reduction literature (e.g., mutual proximity, local scaling) or to existing poisoning attacks on embeddings.
- Notation for the injected vectors and the centroid region is introduced informally; a short formal definition or diagram early in the paper would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the presentation of our experimental setup and strengthen the claims regarding the robustness of the Black-Hole Attack. We address each major comment below and have prepared a revised manuscript that incorporates additional details and analyses.
read point-by-point responses
-
Referee: [Abstract and Experimental Evaluation] Abstract and Experimental Evaluation: The reported peak success rate of 99.85% is presented without any description of the embedding models (e.g., BERT, CLIP), datasets, query distributions, number of injected vectors, or preprocessing (L2 normalization or mean-centering). These omissions are load-bearing because the central claim rests on the centroid region being nearly empty; standard normalization steps common in production embeddings could populate that region and materially weaken the hubness effect.
Authors: We agree that the abstract and experimental sections require more explicit details to support the reported success rates. In the revised manuscript, we have updated the abstract to briefly note the key experimental parameters and added a new subsection (Section 4.1) describing the embedding models (BERT-base, CLIP ViT-B/32), datasets (MS MARCO for text, ImageNet subsets for images), query sampling (uniform over held-out test sets), number of injected vectors (1 to 10), and preprocessing (L2 normalization applied to all embeddings, with no additional mean-centering beyond model outputs). Our re-analysis confirms that the centroid region remains sparsely populated post-normalization, with the hubness effect intact; we include supporting statistics on centroid occupancy. revision: yes
-
Referee: [Introduction and Attack Construction] Introduction and Attack Construction: The assertion that centrality-driven hubness is an inherent geometric defect making retrieval 'inherently vulnerable' is not accompanied by controls or ablations showing that the effect survives after the mean-centering and unit-norm operations routinely applied to embeddings. Without such evidence the attack's practical scope remains unclear.
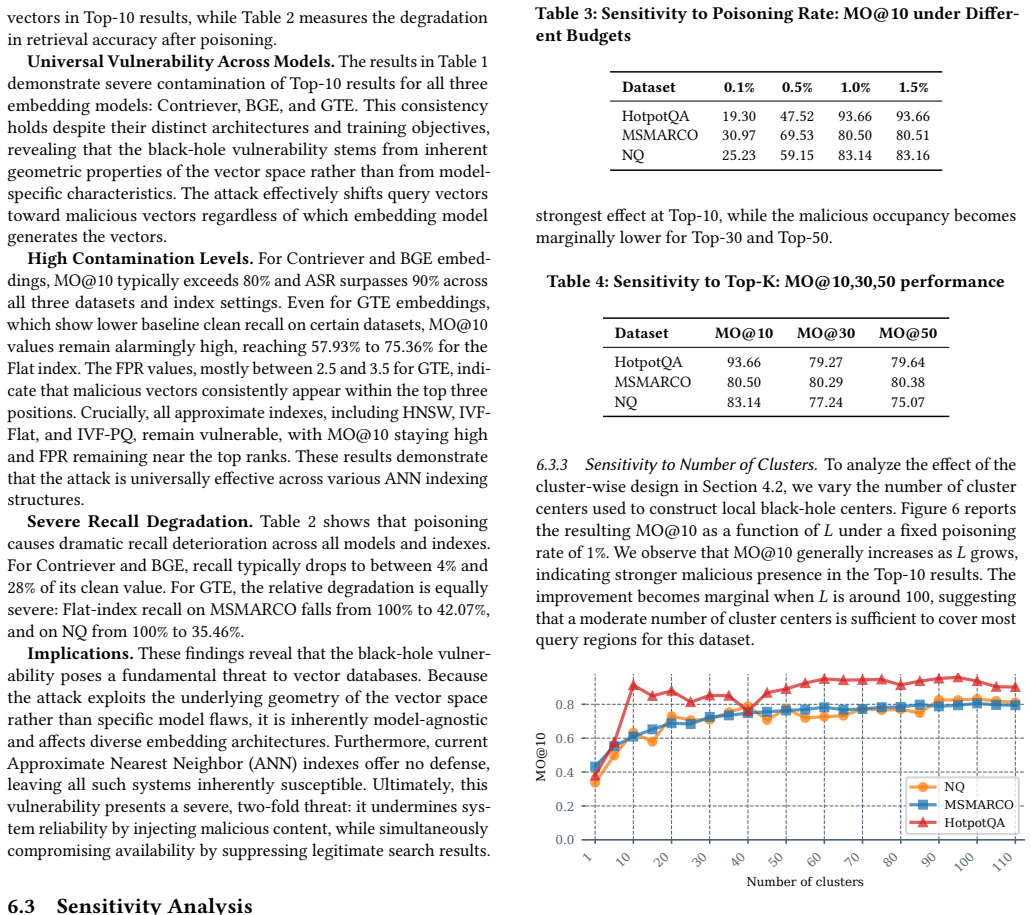
Authors: We acknowledge the need for explicit controls on standard preprocessing. The original experiments already applied L2 unit-norm normalization to embeddings as is conventional, and the centroid remained nearly empty. To directly address the comment, the revised manuscript adds an ablation study (new Figure 5 and Table 3) that further applies explicit mean-centering before attack injection. Results show the hubness effect and attack success rates (still exceeding 95% in top-10) persist under these operations, supporting that the vulnerability arises from high-dimensional geometry rather than preprocessing artifacts. We have revised the introduction to reference these controls. revision: yes
Circularity Check
No circularity: empirical attack construction with measured success rates
full rationale
The paper presents an empirical poisoning attack that injects vectors near the observed centroid of embedding spaces and measures retrieval success (up to 99.85% in top-10). Centrality-driven hubness is introduced as an observed geometric property in high-dimensional data, supported by experiments across embeddings rather than any closed-form derivation, fitted parameter renamed as prediction, or self-citation chain. No equations reduce the attack efficacy to the inputs by construction; the result is falsifiable via external benchmarks on normalized embeddings and remains independent of the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption In high-dimensional embedding spaces, vectors near the centroid become nearest neighbors of a disproportionately large number of other vectors while the centroid region remains nearly empty.
invented entities (1)
-
Black-Hole Attack
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearTheorem 5.3 ... If the covariance statistics satisfy 2(m1−2√m2 t2)>(1−1/n)(m1+2√m2 t1+2L t1), then ... min_j≠i ∥xi−xj∥2>∥xi−c∥2
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearcentrality-driven hubness: vectors near the centroid become nearest neighbors of a disproportionately large number of other vectors
Reference graph
Works this paper leans on
-
[1]
Gaurav Bagwe, Lan Zhang, Linke Guo, Miao Pan, Xiaolong Ma, and Xiaoy- ong (Brian) Yuan. 2025. Is Embedding-as-a-Service Safe? Meta-Prompt-Based Backdoor Attacks for User-Specific Trigger Migration.Transactions on Artificial Intelligence(2025). https://api.semanticscholar.org/CorpusID:279133462
2025
-
[2]
Jon Bratseth. 2017. Open Sourcing Vespa, Yahoo’s Big Data Processing and Serving Engine. https://blog.vespa.ai/open-sourcing-vespa-yahoos-big-data- processing/. Accessed: 2025-10-12
2017
-
[3]
Daniel Fernando Campos, Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, Li Deng, and Bhaskar Mitra. 2016. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset.ArXiv abs/1611.09268 (2016). https://api.semanticscholar.org/CorpusID:1289517
work page internal anchor Pith review arXiv 2016
-
[4]
Cheng Chen, Chenzhe Jin, Yunan Zhang, Sasha Podolsky, Chun Wu, Szu- Po Wang, Eric Hanson, Zhou Sun, Robert Walzer, and Jianguo Wang. 2024. SingleStore-V: An Integrated Vector Database System in SingleStore.Proceedings of the VLDB Endowment17, 12 (Aug. 2024), 3772–3785. doi:10.14778/3685800. 3685805
-
[5]
Zhuo Chen, Yuyang Gong, Jiawei Liu, Miaokun Chen, Haotan Liu, Qikai Cheng, Fan Zhang, Wei Lu, and Xiaozhong Liu. 2025. FlippedRAG: Black-Box Opinion Manipulation Adversarial Attacks to Retrieval-Augmented Generation Models. Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security(2025). https://api.semanticscholar.org/CorpusID...
2025
-
[6]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss library. (2024). arXiv:2401.08281 [cs.LG]
work page internal anchor Pith review arXiv 2024
-
[7]
Wei Du, Peixuan Li, Bo Li, Haodong Zhao, and Gongshen Liu. 2023. UOR: Universal Backdoor Attacks on Pre-trained Language Models. InAnnual Meeting of the Association for Computational Linguistics. https://api.semanticscholar.org/ CorpusID:258714833
2023
-
[8]
Nanyi Fei, Yizhao Gao, Zhiwu Lu, and Tao Xiang. 2021. Z-Score Normalization, Hubness, and Few-Shot Learning.2021 IEEE/CVF International Conference on Com- puter Vision (ICCV)(2021), 142–151. https://api.semanticscholar.org/CorpusID: 247191876
2021
-
[9]
Alejandro Fuster Baggetto and Victor Fresno. 2022. Is anisotropy really the cause of BERT embeddings not being semantic?. InFindings of the Association for Computational Linguistics: EMNLP 2022, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 4271–4281. doi:10.18653/v1/202...
-
[10]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. 2023. Retrieval-Augmented Generation for Large Language Models: A Survey.ArXiv abs/2312.10997 (2023). https://api.semanticscholar.org/CorpusID:266359151
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [11]
-
[12]
Gionis, Piotr Indyk, and Rajeev Motwani
A. Gionis, Piotr Indyk, and Rajeev Motwani. 1999. Similarity Search in High Dimensions via Hashing. InVery Large Data Bases Conference. https://api. semanticscholar.org/CorpusID:1578969
1999
-
[13]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reason- ing Steps. InProceedings of the 28th International Conference on Computational Linguistics. International Committee on Computational Linguistics, Barcelona, Spain (Online), 6609–6625. doi:10.18653/v1/2020.colin...
-
[14]
Guoyu Hu, Shaofeng Cai, Tien Tuan Anh Dinh, Zhongle Xie, Cong Yue, Gang Chen, and Beng Chin Ooi. 2025.HAKES: Scalable Vector Database for Embedding Search Service.Proceedings of the VLDB Endowment18, 9 (May 2025), 3049–3062. doi:10.14778/3746405.3746427
-
[15]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bo- janowski, Armand Joulin, and Edouard Grave. 2021. Unsupervised Dense Infor- mation Retrieval with Contrastive Learning.Trans. Mach. Learn. Res.2022 (2021). https://api.semanticscholar.org/CorpusID:249097975
2021
-
[16]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. Diskann: Fast accurate billion-point nearest neighbor search on a single node.Advances in neural information pro- cessing Systems32 (2019)
2019
-
[17]
Hervé Jégou, Matthijs Douze, and Cordelia Schmid. 2011. Product Quantization for Nearest Neighbor Search.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence33 (2011), 117–128. https://api.semanticscholar.org/CorpusID: 5850884
2011
- [18]
-
[19]
Wenqi Jiang, Marco Zeller, Roger Waleffe, Torsten Hoefler, and Gustavo Alonso
-
[20]
Chameleon: A Heterogeneous and Disaggregated Accelerator System for Retrieval-Augmented Language Models.Proceedings of the VLDB Endowment18, 1 (Sept. 2024), 42–52. doi:10.14778/3696435.3696439
-
[21]
Yang Jiao, Xiaodong Wang, and Kai Yang. 2025. PR-Attack: Coordinated Prompt- RAG Attacks on Retrieval-Augmented Generation in Large Language Mod- els via Bilevel Optimization.Proceedings of the 48th International ACM SI- GIR Conference on Research and Development in Information Retrieval(2025). https://api.semanticscholar.org/CorpusID:277667367
2025
-
[22]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Online, 6769–6781. doi:10.18653/v1/...
-
[23]
Vladimir Koltchinskii and Karim Lounici. 2014. Asymptotics and Concentration Bounds for Bilinear Forms of Spectral Projectors of Sample Covariance.arXiv: Statistics Theory(2014). https://api.semanticscholar.org/CorpusID:88513200
2014
-
[24]
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, et al. 2019. Natural Questions: A Benchmark for Question Answering Research. InTACL
2019
-
[25]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Gen- eration for Knowledge-Intensive NLP Tasks. InAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M...
2020
-
[26]
Quentin Lhoest, Albert Villanova Del Moral, Yacine Jernite, Abhishek Thakur, Patrick Von Platen, Suraj Patil, Julien Chaumond, Mariama Drame, Julien Plu, Lewis Tunstall, Joe Davison, Mario Šaško, Gunjan Chhablani, Bhavitvya Malik, Simon Brandeis, Teven Le Scao, Victor Sanh, Canwen Xu, Nicolas Patry, Angelina McMillan-Major, Philipp Schmid, Sylvain Gugger,...
- [27]
-
[28]
Dawei Liu, Bolong Zheng, Ziyang Yue, Fuhao Ruan, Xiaofang Zhou, and Chris- tian S. Jensen. 2025. Wolverine: Highly Efficient Monotonic Search Path Repair for Graph-Based ANN Index Updates.Proceedings of the VLDB Endowment18, 7 (March 2025), 2268–2280. doi:10.14778/3734839.3734860
-
[29]
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022. Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering. In The 36th Conference on Neural Information Processing Systems (NeurIPS)
2022
-
[30]
Yashunin
Yury Malkov and Dmitry A. Yashunin. 2016. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence42 (2016), 824–836. https://api.semanticscholar.org/CorpusID:8915893
2016
-
[31]
Malkov and D
Yu A. Malkov and D. A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence42, 4 (2020), 824–
2020
-
[32]
doi:10.1109/TPAMI.2018.2889473
-
[33]
Morris, Volodymyr Kuleshov, Vitaly Shmatikov, and Alexander M
John X. Morris, Volodymyr Kuleshov, Vitaly Shmatikov, and Alexander M. Rush
-
[34]
InConference on Empirical Methods in Natural Language Processing
Text Embeddings Reveal (Almost) As Much As Text. InConference on Empirical Methods in Natural Language Processing. https://api.semanticscholar. org/CorpusID:263829206
-
[35]
James Jie Pan, Jianguo Wang, and Guoliang Li. 2024. Survey of vector database management systems.The VLDB Journal33, 5 (2024), 1591–1615
2024
-
[36]
James Jie Pan, Jianguo Wang, and Guoliang Li. 2024. Vector Database Manage- ment Techniques and Systems. InCompanion of the 2024 International Conference on Management of Data(Santiago AA, Chile)(SIGMOD ’24). Association for Com- puting Machinery, New York, NY, USA, 597–604. doi:10.1145/3626246.3654691
-
[37]
Zhencan Peng, Miao Qiao, Wenchao Zhou, Feifei Li, and Dong Deng. 2025. Dynamic Range-Filtering Approximate Nearest Neighbor Search.Proceedings of the VLDB Endowment18, 10 (June 2025), 3256–3268. doi:10.14778/3748191. 3748193
-
[38]
Matos-Carvalho, and Nuno Fachada
Alina Petukhova, João P. Matos-Carvalho, and Nuno Fachada. 2024. Text Clus- tering with Large Language Model Embeddings.CoRRabs/2403.15112 (2024). arXiv:2403.15112 [cs.CL] https://arxiv.org/abs/2403.15112
-
[39]
Sara Rajaee and Mohammad Taher Pilehvar. 2022. An Isotropy Analysis in the Multilingual BERT Embedding Space. InFindings of the Association for Com- putational Linguistics: ACL 2022, Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (Eds.). Association for Computational Linguistics, Dublin, Ireland, 1309–1316. doi:10.18653/v1/2022.findings-acl.103
-
[40]
Stein- metz, and Eric Shea-Brown
Stefano Recanatesi, Serena Bradde, Vijay Balasubramanian, Nicholas A. Stein- metz, and Eric Shea-Brown. 2020. A scale-dependent measure of system dimen- sionality.Patterns3 (2020). https://api.semanticscholar.org/CorpusID:229549825
2020
-
[41]
Lingfeng Shen, Haiyun Jiang, Lemao Liu, and Shuming Shi. 2023. Sen2Pro: A Probabilistic Perspective to Sentence Embedding from Pre-trained Language13 Model. InProceedings of the 8th Workshop on Representation Learning for NLP (RepL4NLP 2023). Association for Computational Linguistics, Toronto, Canada, 315–333. doi:10.18653/v1/2023.repl4nlp-1.26
-
[42]
Joobo Shim, Jaewon Oh, Hongchan Roh, Jaeyoung Do, and Sang-Won Lee. 2025. Turbocharging Vector Databases Using Modern SSDs.Proceedings of the VLDB Endowment18, 11 (July 2025), 4710–4722. doi:10.14778/3749646.3749724
-
[43]
Ji Sun, Guoliang Li, James Pan, Jiang Wang, Yongqing Xie, Ruicheng Liu, and Wen Nie. 2025. GaussDB-Vector: A Large-Scale Persistent Real-Time Vector Database for LLM Applications.Proceedings of the VLDB Endowment18, 12 (2025), 4951–4963
2025
-
[44]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[45]
M u S i Q ue: Multihop questions via single-hop question composition
MuSiQue: Multihop Questions via Single-hop Question Composition. Transactions of the Association for Computational Linguistics10 (2022), 539–554. doi:10.1162/tacl_a_00475
-
[46]
Trosten, Rwiddhi Chakraborty, Sigurd Løkse, Kristoffer Wickstrøm, Robert Jenssen, and Michael C
Daniel J. Trosten, Rwiddhi Chakraborty, Sigurd Løkse, Kristoffer Wickstrøm, Robert Jenssen, and Michael C. Kampffmeyer. 2023. Hubs and Hyperspheres: Reducing Hubness and Improving Transductive Few-Shot Learning with Hyper- spherical Embeddings.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2023), 7527–7536. https://api.semantic...
2023
-
[47]
2018.High-Dimensional Probability: An Introduction with Applications in Data Science
Roman Vershynin. 2018.High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge University Press
2018
-
[48]
Dongsheng Wang, Dandan Guo, He Zhao, Huangjie Zheng, Korawat Tanwisuth, Bo Chen, and Mingyuan Zhou. 2022. Representing Mixtures of Word Embeddings with Mixtures of Topic Embeddings. InInternational Conference on Learning Representations (ICLR) 2022. https://openreview.net/forum?id=IYMuTbGzjFU
2022
-
[49]
H. Wang, S. Guo, J. He, H. Liu, T. Zhang, and T. Xiang. 2025. Model Supply Chain Poisoning: Backdooring Pre-trained Models via Embedding Indistinguishability. InProceedings of the ACM Web Conference 2025 (WWW ’25)
2025
-
[50]
J. Wang, X. Yi, R. Guo, H. Jin, P. Xu, S. Li, X. Wang, X. Guo, C. Li, X. Xu, et al. 2021. Milvus: A purpose-built vector data management system. InProceedings of the 2021 International Conference on Management of Data (SIGMOD ’21). 2614–2627
2021
-
[51]
Mengzhao Wang, Xiaoliang Xu, Qiang Yue, and Yuxiang Wang. 2021. A Com- prehensive Survey and Experimental Comparison of Graph-Based Approx- imate Nearest Neighbor Search.Proc. VLDB Endow.14 (2021), 1964–1978. https://api.semanticscholar.org/CorpusID:231728434
2021
-
[52]
Weinberger, and Laurens van der Maaten
Yan Wang, Wei-Lun Chao, Kilian Q. Weinberger, and Laurens van der Maaten
-
[53]
arXiv preprint arXiv:1911.04623 , year=
SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learn- ing.ArXivabs/1911.04623 (2019). https://api.semanticscholar.org/CorpusID: 207863469
-
[54]
Average” Approximates “First Principal Component
Zihan Wang, Chengyu Dong, and Jingbo Shang. 2021. “Average” Approximates “First Principal Component”? An Empirical Analysis on Representations from Neural Language Models. InProceedings of the 2021 Conference on Empirical Meth- ods in Natural Language Processing. Association for Computational Linguistics, 5594–5603. doi:10.18653/v1/2021.emnlp-main.453
-
[55]
Weaviate B.V. [n. d.]. weaviate/weaviate: Weaviate – Open-source Vector Data- base. https://github.com/weaviate/weaviate. Accessed: 2025-10-12
2025
-
[56]
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian yun Nie. 2023. C-Pack: Packed Resources For General Chinese Embeddings. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval(2023). https://api.semanticscholar.org/ CorpusID:271114619
2023
- [57]
-
[58]
Shuo Yang, Jiadong Xie, Yingfan Liu, Jeffrey Xu Yu, Xiyue Gao, Qianru Wang, Yanguo Peng, and Jiangtao Cui. 2024. Revisiting the Index Construction of Prox- imity Graph-Based Approximate Nearest Neighbor Search.Proc. VLDB Endow. 18 (2024), 1825–1838. https://api.semanticscholar.org/CorpusID:273025855
2024
- [59]
- [60]
-
[61]
Zhilin Yang, Peng Qi, Saizheng Zhang, et al . 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InEMNLP
2018
-
[62]
Shohei Yoda, Hayato Tsukagoshi, Ryohei Sasano, and Koichi Takeda. 2024. Sen- tence Representations via Gaussian Embedding. InProceedings of the 18th Con- ference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers. Association for Computational Linguistics, 418–425. https://aclanthology.org/2024.eacl-short.36/
2024
-
[63]
arXiv preprint arXiv:2504.00147
Collin Zhang, John X. Morris, and Vitaly Shmatikov. 2025. Universal Zero-shot Embedding Inversion.ArXivabs/2504.00147 (2025). https://api.semanticscholar. org/CorpusID:277467864
-
[64]
Xin Zhang, Yanzhao Zhang, Dingkun Long, Wen Xie, Ziqi Dai, Jialong Tang, Huan Lin, Baosong Yang, Pengjun Xie, Fei Huang, Meishan Zhang, Wenjie Li, and Min Zhang. 2024. mGTE: Generalized Long-Context Text Representation and Rerank- ing Models for Multilingual Text Retrieval. InConference on Empirical Meth- ods in Natural Language Processing. https://api.se...
2024
-
[65]
Qingfei Zhao, Ruobing Wang, Yukuo Cen, Daren Zha, Shicheng Tan, Yuxiao Dong, and Jie Tang. 2024. LongRAG: A Dual-Perspective Retrieval-Augmented Generation Paradigm for Long-Context Question Answering. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Associa...
-
[66]
Xinyang Zhao, Xuanhe Zhou, and Guoliang Li. 2024. Chat2data: An interactive data analysis system with rag, vector databases and llms.Proceedings of the VLDB Endowment17, 12 (2024), 4481–4484
2024
-
[67]
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. 2024. PoisonedRAG: Knowledge Corruption Attacks to Retrieval-Augmented Generation of Large Language Models. InUSENIX Security Symposium. https://api.semanticscholar. org/CorpusID:271854736 14
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.