Recognition: no theorem link
On the Role of Fault Localization Context for LLM-Based Program Repair
Pith reviewed 2026-05-10 19:51 UTC · model grok-4.3
The pith
File-level fault localization multiplies LLM program repair success by 15-17 times compared to no localization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that file-level localization provides a 15-17x improvement over a baseline with no file information. Successful repairs occur most often when using about 6-10 relevant files. Adding element-level context helps only if the file context is already accurate, but line-level context tends to hurt performance because it adds noise. Retrieval of context using the LLM itself works better than using fixed structural rules and uses less information overall.
What carries the argument
The evaluation of 61 different fault localization context configurations, varying the number of files, elements within files, and specific lines provided to the model for repair.
If this is right
- Repair tools should prioritize identifying the buggy file accurately as the primary step.
- Configurations with roughly 6 to 10 files tend to yield the highest number of successful fixes.
- Line-level details should be added selectively since they frequently reduce performance.
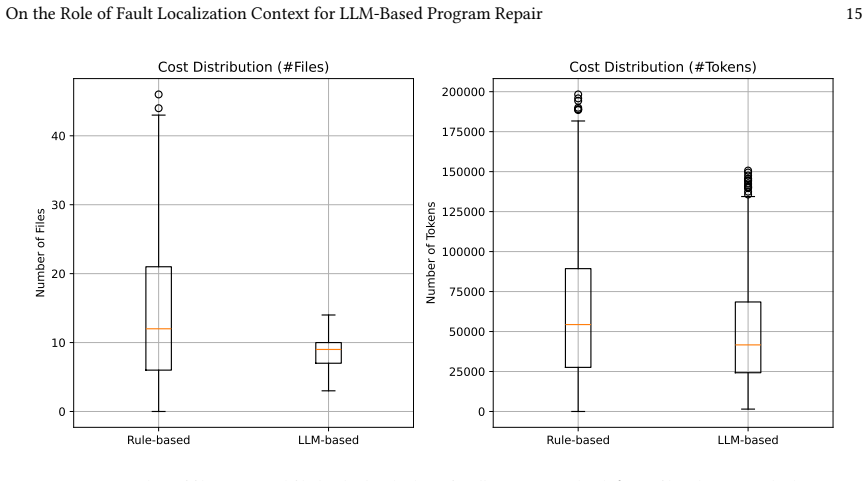
- Using LLM-based methods to select context outperforms traditional heuristic approaches.
Where Pith is reading between the lines
- These results imply that automated repair systems could be made more efficient by focusing localization efforts on files rather than investing in line-level precision.
- Similar studies on other models or bug datasets might reveal whether the preference for file-level context is a general property of current LLMs.
- Integrating this into repair pipelines could lead to hybrid approaches that start with semantic file selection and refine only when needed.
Load-bearing premise
The 500 SWE-bench Verified instances and the specific model used are sufficient to represent general behavior across different models, other benchmarks, and practical software repair tasks.
What would settle it
Conducting the same set of experiments using a different large language model or on a fresh collection of bugs from another source and checking whether the dominance of file-level context persists.
Figures







read the original abstract
Fault Localization (FL) is a key component of Large Language Model (LLM)-based Automated Program Repair (APR), yet its impact remains underexplored. In particular, it is unclear how much localization is needed, whether additional context beyond the predicted buggy location is beneficial, and how such context should be retrieved. We conduct a large-scale empirical study on 500 SWE-bench Verified instances using GPT-5-mini, evaluating 61 configurations that vary file-level, element-level, and line-level context. Our results show that more context does not consistently improve repair performance. File-level localization is the dominant factor, yielding a 15-17x improvement over a no-file baseline. Expanding file context is often associated with improved performance, with successful repairs most commonly observed in configurations with approximately 6-10 relevant files. Element-level context expansion provides conditional gains that depend strongly on the file context quality, while line-level context expansion frequently degrades performance due to noise amplification. LLM-based retrieval generally outperforms structural heuristics while using fewer files and tokens. Overall, the most effective FL context strategy typically combines a broad semantic understanding at higher abstraction levels with precise line-level localization. These findings challenge our assumption that increasing the localization context uniformly improves APR, and provide practical guidance for designing LLM-based FL strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical study on the impact of fault localization context granularity (file-level, element-level, line-level) for LLM-based automated program repair. Using GPT-5-mini on 500 SWE-bench Verified tasks across 61 configurations, it finds that file-level localization dominates with a 15-17x repair improvement over a no-file baseline, that expanding context beyond the file level does not consistently help (and line-level often hurts due to noise), that LLM-based retrieval outperforms structural heuristics, and that effective strategies combine broad file context with precise localization.
Significance. If the observed patterns hold, the work is significant for providing large-scale, quantitative evidence that challenges the assumption of 'more context is better' in LLM-APR and offers practical design guidance on context retrieval strategies. The scale (500 tasks, 61 configs) and focus on differential effects across abstraction levels are strengths; the finding that ~6-10 relevant files often suffices is actionable.
major comments (2)
- [Evaluation and Results sections] The central claim of 15-17x improvement from file-level localization and the ordering of context levels rests on a single model (GPT-5-mini) and single benchmark (SWE-bench Verified). Different LLMs vary substantially in long-context utilization, instruction adherence, and noise tolerance, so the dominance of file-level context and the conditional gains from element/line expansion could shift; the paper should either add cross-model validation or explicitly qualify all claims as specific to this setup.
- [Results section] The abstract and results report that 'more context does not consistently improve repair performance' and that line-level expansion 'frequently degrades performance,' but without reported per-configuration success rates, variance across the 500 instances, or statistical significance tests (e.g., McNemar or bootstrap), it is difficult to determine whether the observed patterns reflect robust effects or sampling variability.
minor comments (2)
- [Experimental Setup] The description of the 61 configurations would benefit from an explicit enumeration or table showing how file/element/line levels are combined rather than leaving the reader to infer coverage.
- [Evaluation section] The paper should clarify the precise definition of the 'no-file baseline' (e.g., whether it includes any repository context or is strictly empty) and the exact repair success criterion used to compute the 15-17x multiplier.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical study. The comments highlight important aspects of generalizability and statistical rigor, which we address point by point below. We will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation and Results sections] The central claim of 15-17x improvement from file-level localization and the ordering of context levels rests on a single model (GPT-5-mini) and single benchmark (SWE-bench Verified). Different LLMs vary substantially in long-context utilization, instruction adherence, and noise tolerance, so the dominance of file-level context and the conditional gains from element/line expansion could shift; the paper should either add cross-model validation or explicitly qualify all claims as specific to this setup.
Authors: We agree that our results are specific to GPT-5-mini and SWE-bench Verified, limiting broad generalization across models with differing context-handling capabilities. Adding cross-model experiments would require substantial new computational effort beyond the scope of this revision. We will revise the abstract, introduction, results, and conclusion sections to explicitly qualify all quantitative claims (including the 15-17x improvement and context-level ordering) as holding for this model-benchmark pair. We will also expand the limitations and future work sections to discuss potential variability across LLMs and recommend cross-model validation as an important direction for follow-up research. revision: yes
-
Referee: [Results section] The abstract and results report that 'more context does not consistently improve repair performance' and that line-level expansion 'frequently degrades performance,' but without reported per-configuration success rates, variance across the 500 instances, or statistical significance tests (e.g., McNemar or bootstrap), it is difficult to determine whether the observed patterns reflect robust effects or sampling variability.
Authors: We acknowledge that additional statistical detail would improve confidence in the patterns. In the revised manuscript, we will include a supplementary table or appendix with per-configuration repair success rates across the 500 tasks. We will also report variance measures (e.g., standard deviation of success rates) and add statistical significance testing, such as McNemar's test for paired comparisons between context configurations, to substantiate claims about degradation from line-level expansion and the benefits of file-level context. revision: yes
Circularity Check
No circularity: purely empirical measurements of repair success rates
full rationale
The paper reports results from running 61 experimental configurations on 500 SWE-bench Verified tasks with GPT-5-mini. All claims (file-level dominance yielding 15-17x improvement, effects of element/line context, LLM retrieval vs. heuristics) are direct counts of successful repairs observed in the data. No equations, no parameters fitted to subsets and then relabeled as predictions, no self-citations used as load-bearing uniqueness theorems, and no ansatzes or renamings of known results. The derivation chain consists solely of experimental measurement and comparison; nothing reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SWE-bench Verified is a representative sample of real-world repair tasks for evaluating LLM-based APR.
- domain assumption GPT-5-mini behavior is sufficiently indicative of LLM-based APR in general.
Forward citations
Cited by 1 Pith paper
-
SieveFL: Hierarchical Runtime-Aware Pruning for Scalable LLM-Based Fault Localization
SieveFL combines vector retrieval and JaCoCo runtime pruning to cut LLM token use by 49% while achieving 41.8% Top-1 accuracy on 395 Defects4J bugs, outperforming AgentFL.
Reference graph
Works this paper leans on
-
[1]
Rui Abreu, Peter Zoeteweij, and Arjan JC Van Gemund. 2007. On the accuracy of spectrum-based fault localization. InTesting: Academic and industrial conference practice and research techniques-MUTATION (TAICPART-MUTATION 2007). IEEE, 89–98
2007
- [2]
-
[3]
Fatmah Yousef Assiri and James M Bieman. 2017. Fault localization for automated program repair: effectiveness, performance, repair correctness. Software Quality Journal25, 1 (2017), 171–199
2017
-
[4]
Xin Chen, Tian Sun, Dongling Zhuang, Dongjin Yu, He Jiang, Zhide Zhou, and Sicheng Li. 2024. Hetfl: Heterogeneous graph-based software fault localization.IEEE Transactions on Software Engineering50, 11 (2024), 2884–2905. Manuscript submitted to ACM On the Role of Fault Localization Context for LLM-Based Program Repair 29
2024
- [5]
-
[6]
Zhiyu Fan, Xiang Gao, Martin Mirchev, Abhik Roychoudhury, and Shin Hwei Tan. 2023. Automated repair of programs from large language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1469–1481
2023
- [7]
-
[8]
Luca Gazzola, Daniela Micucci, and Leonardo Mariani. 2018. Automatic software repair: A survey. InProceedings of the 40th International Conference on Software Engineering. 1219–1219
2018
- [9]
-
[10]
Anbang Guo, Xiaoguang Mao, Deheng Yang, and Shangwen Wang. 2018. An empirical study on the effect of dynamic slicing on automated program repair efficiency. In2018 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 554–558
2018
- [11]
-
[12]
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. 2019. Codesearchnet challenge: Evaluating the state of semantic code search.arXiv preprint arXiv:1909.09436(2019)
work page internal anchor Pith review arXiv 2019
-
[13]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
James A Jones, Mary Jean Harrold, and John Stasko. 2002. Visualization of test information to assist fault localization. InProceedings of the 24th international conference on Software engineering. 467–477
2002
-
[15]
Anil Koyuncu, Kui Liu, Tegawendé F Bissyandé, Dongsun Kim, Martin Monperrus, Jacques Klein, and Yves Le Traon. 2019. iFixR: Bug report driven program repair. InProceedings of the 2019 27th ACM joint meeting on european software engineering conference and symposium on the foundations of software engineering. 314–325
2019
-
[16]
Claire Le Goues, ThanhVu Nguyen, Stephanie Forrest, and Westley Weimer. 2011. Genprog: A generic method for automatic software repair.Ieee transactions on software engineering38, 1 (2011), 54–72
2011
-
[17]
Zheng Li, Xue Bai, Haifeng Wang, and Yong Liu. 2020. IRBFL: an information retrieval based fault localization approach. In2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC). IEEE, 991–996
2020
-
[18]
Kui Liu, Anil Koyuncu, Tegawendé F Bissyandé, Dongsun Kim, Jacques Klein, and Yves Le Traon. 2019. You cannot fix what you cannot find! an investigation of fault localization bias in benchmarking automated program repair systems. In2019 12th IEEE conference on software testing, validation and verification (ICST). IEEE, 102–113
2019
-
[19]
Kui Liu, Li Li, Anil Koyuncu, Dongsun Kim, Zhe Liu, Jacques Klein, and Tegawendé F Bissyandé. 2021. A critical review on the evaluation of automated program repair systems.Journal of Systems and Software171 (2021), 110817
2021
-
[20]
Fan Long and Martin Rinard. 2015. Staged program repair with condition synthesis. InProceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. 166–178
2015
-
[21]
Xiaoguang Mao, Yan Lei, Ziying Dai, Yuhua Qi, and Chengsong Wang. 2014. Slice-based statistical fault localization.Journal of Systems and Software 89 (2014), 51–62
2014
-
[22]
Sergey Mechtaev, Jooyong Yi, and Abhik Roychoudhury. 2016. Angelix: Scalable multiline program patch synthesis via symbolic analysis. In Proceedings of the 38th international conference on software engineering. 691–701
2016
-
[23]
Ali Mesbah, Andrew Rice, Emily Johnston, Nick Glorioso, and Edward Aftandilian. 2019. Deepdelta: learning to repair compilation errors. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 925–936
2019
-
[24]
Martin Monperrus. 2018. Automatic software repair: A bibliography.ACM Computing Surveys (CSUR)51, 1 (2018), 1–24
2018
-
[25]
Hoang Duong Thien Nguyen, Dawei Qi, Abhik Roychoudhury, and Satish Chandra. 2013. Semfix: Program repair via semantic analysis. In2013 35th International Conference on Software Engineering (ICSE). IEEE, 772–781
2013
-
[26]
Julian Aron Prenner and Romain Robbes. 2025. Simple Fault Localization Using Execution Traces. In2025 IEEE/ACM International Workshop on Automated Program Repair (APR). IEEE, 48–55
2025
-
[27]
Yuhua Qi, Xiaoguang Mao, Yan Lei, Ziying Dai, and Chengsong Wang. 2014. The strength of random search on automated program repair. In Proceedings of the 36th international conference on software engineering. 254–265
2014
- [28]
-
[29]
Ezekiel Soremekun, Lukas Kirschner, Marcel Böhme, and Andreas Zeller. 2021. Locating faults with program slicing: an empirical analysis.Empirical Software Engineering26, 3 (2021), 51
2021
-
[30]
Michele Tufano, Cody Watson, Gabriele Bavota, Massimiliano Di Penta, Martin White, and Denys Poshyvanyk. 2019. An empirical study on learning bug-fixing patches in the wild via neural machine translation.ACM Transactions on Software Engineering and Methodology (TOSEM)28, 4 (2019), 1–29. Manuscript submitted to ACM 30 Melika Sepidband, Hung Viet Pham, and ...
2019
- [31]
-
[32]
Tian Wang, Qiang Fang, Meng Chi, Jianming Shen, Xuebing Zhang, and Dandan Shan. 2024. Entity clustering-based meta-learning for link prediction in evolutionary fault diagnosis event graphs: T. Wang et al.Applied Intelligence54, 21 (2024), 10525–10540
2024
-
[33]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2024. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741(2024)
work page internal anchor Pith review arXiv 2024
-
[34]
Westley Weimer, ThanhVu Nguyen, Claire Le Goues, and Stephanie Forrest. 2009. Automatically finding patches using genetic programming. In 2009 IEEE 31st International Conference on Software Engineering. IEEE, 364–374
2009
-
[35]
W Eric Wong, Vidroha Debroy, Ruizhi Gao, and Yihao Li. 2013. The DStar method for effective software fault localization.IEEE Transactions on Reliability63, 1 (2013), 290–308
2013
-
[36]
W Eric Wong, Ruizhi Gao, Yihao Li, Rui Abreu, and Franz Wotawa. 2016. A survey on software fault localization.IEEE Transactions on Software Engineering42, 8 (2016), 707–740
2016
-
[37]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2024. Agentless: Demystifying llm-based software engineering agents.arXiv preprint arXiv:2407.01489(2024)
work page internal anchor Pith review arXiv 2024
-
[38]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated program repair in the era of large pre-trained language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1482–1494
2023
-
[39]
Deheng Yang, Yuhua Qi, and Xiaoguang Mao. 2017. An empirical study on the usage of fault localization in automated program repair. In2017 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 504–508
2017
-
[40]
Deheng Yang, Yuhua Qi, Xiaoguang Mao, and Yan Lei. 2021. Evaluating the usage of fault localization in automated program repair: an empirical study.Frontiers of Computer Science15, 1 (2021), 151202
2021
-
[41]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
2022
- [42]
-
[43]
Xiangyu Zhang, Neelam Gupta, and Rajiv Gupta. 2007. A study of effectiveness of dynamic slicing in locating real faults.Empirical Software Engineering12, 2 (2007), 143–160
2007
-
[44]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Autocoderover: Autonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1592–1604
2024
-
[45]
Jian Zhou, Hongyu Zhang, and David Lo. 2012. Where should the bugs be fixed? more accurate information retrieval-based bug localization based on bug reports. In2012 34th International conference on software engineering (ICSE). IEEE, 14–24. Manuscript submitted to ACM
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.