Recognition: 2 theorem links
· Lean TheoremThinking Diffusion: Penalize and Guide Visual-Grounded Reasoning in Diffusion Multimodal Language Models
Pith reviewed 2026-05-10 19:01 UTC · model grok-4.3
The pith
Diffusion multimodal language models reason better when penalized for generating final answers too early and guided to rely more on visual inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
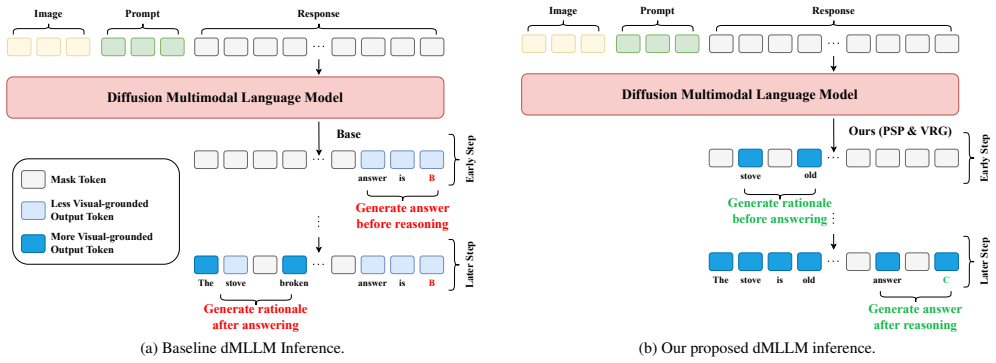
dMLLMs using chain-of-thought reasoning often generate the final answer token at a very early timestep and show minimal dependency on visual prompts in initial timesteps, producing premature answers without sufficient visual grounding. Position and Step Penalty penalizes tokens in later positions during early timesteps to delay this and encourage progressive reasoning across steps. Visual Reasoning Guidance amplifies visual grounding signals during generation. These adjustments raise accuracy by up to 7.5 percent while delivering more than 3x speedup compared to using four times as many diffusion steps, and they apply across various dMLLMs without retraining.
What carries the argument
Position and Step Penalty (PSP) that discourages late-position tokens early on, paired with Visual Reasoning Guidance (VRG) that strengthens visual input influence during the diffusion steps
Load-bearing premise
That the premature final-answer generation and weak early visual dependency are the main causes of degraded performance, and that PSP and VRG will correct them without creating new failure modes.
What would settle it
Measure the timestep when the final answer token appears and the accuracy on a visual reasoning benchmark both with and without PSP and VRG applied to the same dMLLM.
Figures










read the original abstract
Diffusion large language models (dLLMs) are emerging as promising alternatives to autoregressive (AR) LLMs. Recently, this paradigm has been extended to multimodal tasks, leading to the development of diffusion multimodal large language models (dMLLMs). These models are expected to retain the reasoning capabilities of LLMs while enabling faster inference through parallel generation. However, when combined with Chain-of-Thought (CoT) reasoning, dMLLMs exhibit two critical issues. First, we observe that dMLLMs often generate the final answer token at a very early timestep. This trend indicates that the model determines the answer before sufficient reasoning, leading to degraded reasoning performance. Second, during the initial timesteps, dMLLMs show minimal dependency on visual prompts, exhibiting a fundamentally different pattern of visual information utilization compared to AR vision-language models. In summary, these findings indicate that dMLLMs tend to generate premature final answers without sufficiently grounding on visual inputs. To address these limitations, we propose Position and Step Penalty (PSP) and Visual Reasoning Guidance (VRG). PSP penalizes tokens in later positions during early timesteps, delaying premature answer generation and encouraging progressive reasoning across timesteps. VRG, inspired by classifier-free guidance, amplifies visual grounding signals to enhance the model's alignment with visual evidence. Extensive experiments across various dMLLMs demonstrate that our method achieves up to 7.5% higher accuracy while delivering more than 3x speedup compared to reasoning with four times more diffusion steps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies two issues in diffusion multimodal large language models (dMLLMs) when performing Chain-of-Thought reasoning: premature generation of final-answer tokens at early timesteps and minimal dependency on visual inputs during initial diffusion steps. It proposes Position and Step Penalty (PSP) to penalize later-position tokens in early timesteps, thereby delaying answer generation, and Visual Reasoning Guidance (VRG), which amplifies visual conditioning signals in a classifier-free-guidance style. The authors report that these interventions produce up to 7.5% higher accuracy and more than 3x speedup relative to running four times as many diffusion steps, across multiple dMLLMs.
Significance. If the reported gains are reproducible and causally attributable to the proposed mechanisms, the work would supply a lightweight, training-free technique for aligning the parallel generation dynamics of diffusion models with the sequential requirements of visual reasoning. This could narrow the performance gap between dMLLMs and autoregressive vision-language models on tasks that demand progressive grounding.
major comments (2)
- Abstract: the central performance claims (7.5% accuracy lift and >3x speedup) are stated without any reference to the evaluation datasets, baseline models, number of diffusion steps in the comparison, statistical tests, or ablation controls, rendering it impossible to assess whether the data support the attribution to PSP and VRG.
- Proposed Method and Experiments: the argument treats the observed premature-answer and low-visual-dependency patterns as root causes whose correction improves reasoning, yet no controlled intervention (e.g., artificially inducing early final tokens or ablating visual signals while holding other factors fixed) is described to establish causality; gains could arise from incidental changes to the diffusion trajectory.
minor comments (2)
- Abstract: the phrase 'various dMLLMs' is used without naming the concrete models or citing their source papers, which hinders reproducibility assessment.
- Abstract: the speedup comparison is made against 'reasoning with four times more diffusion steps,' but the baseline step count and whether total compute is held constant are not specified.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [—] Abstract: the central performance claims (7.5% accuracy lift and >3x speedup) are stated without any reference to the evaluation datasets, baseline models, number of diffusion steps in the comparison, statistical tests, or ablation controls, rendering it impossible to assess whether the data support the attribution to PSP and VRG.
Authors: We agree that the abstract, in its current concise form, does not reference specific datasets, baseline models, diffusion step counts, statistical tests, or ablation controls. The full manuscript's Experiments section provides these details, including evaluations on visual reasoning benchmarks, multiple dMLLMs, comparisons to 4x diffusion steps, and ablation results. To address this, we will revise the abstract to briefly note the key evaluation settings and datasets while preserving its high-level summary, thereby improving the reader's ability to assess the claims. revision: yes
-
Referee: [—] Proposed Method and Experiments: the argument treats the observed premature-answer and low-visual-dependency patterns as root causes whose correction improves reasoning, yet no controlled intervention (e.g., artificially inducing early final tokens or ablating visual signals while holding other factors fixed) is described to establish causality; gains could arise from incidental changes to the diffusion trajectory.
Authors: The manuscript first documents the premature answer generation and weak visual dependency through analysis of dMLLM behavior, then introduces PSP and VRG as targeted remedies, with ablations showing their individual contributions to accuracy and efficiency gains. We did not perform artificial interventions such as forcing early final tokens, as these could introduce non-natural artifacts. We will revise the manuscript to include expanded discussion explicitly connecting the mechanisms to the observed improvements and additional trajectory analysis with/without the interventions. This will strengthen the causal link while remaining faithful to the natural model dynamics. revision: partial
Circularity Check
No significant circularity; methods are heuristic responses to observed patterns
full rationale
The paper first reports two empirical generation behaviors in dMLLMs (early final-answer tokens and weak initial visual conditioning) via direct observation of model outputs. It then introduces PSP (position/step penalties) and VRG (visual guidance) as targeted interventions to alter those behaviors. These proposals are not derived from equations that reduce to the observations by construction, nor from fitted parameters renamed as predictions, nor from self-citations that bear the central claim. Performance gains are asserted via external benchmark experiments rather than by algebraic identity with the input patterns. No self-definitional loops, uniqueness theorems, or ansatz smuggling appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption dMLLMs exhibit premature answer generation and low visual dependency in early timesteps
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Men- sch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
-
[2]
Qiguang Chen, Libo Qin, Jin Zhang, Zhi Chen, Xiao Xu, and Wanxiang Che. M3 cot: A novel benchmark for multi- domain multi-step multi-modal chain-of-thought.arXiv preprint arXiv:2405.16473, 2024. 4, 6
-
[3]
How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.Science China Information Sciences, 67(12):220101,
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhang- wei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.Science China Information Sciences, 67(12):220101,
-
[4]
Zixu Cheng, Jian Hu, Ziquan Liu, Chenyang Si, Wei Li, and Shaogang Gong. V-star: Benchmarking video- llms on video spatio-temporal reasoning.arXiv preprint arXiv:2503.11495, 2025. 6
-
[5]
H., Doucet, A., Strudel, R., Dyer, C., Durkan, C., et al
Sander Dieleman, Laurent Sartran, Arman Roshannai, Niko- lay Savinov, Yaroslav Ganin, Pierre H Richemond, Arnaud Doucet, Robin Strudel, Chris Dyer, Conor Durkan, et al. Continuous diffusion for categorical data.arXiv preprint arXiv:2211.15089, 2022. 2
-
[6]
Multi-modal hal- lucination control by visual information grounding
Alessandro Favero, Luca Zancato, Matthew Trager, Sid- dharth Choudhary, Pramuditha Perera, Alessandro Achille, Ashwin Swaminathan, and Stefano Soatto. Multi-modal hal- lucination control by visual information grounding. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14303–14312, 2024. 1, 4
2024
-
[7]
Interleaved-modal chain-of-thought
Jun Gao, Yongqi Li, Ziqiang Cao, and Wenjie Li. Interleaved-modal chain-of-thought. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19520–19529, 2025. 3
2025
-
[8]
Shansan Gong, Mukai Li, Jiangtao Feng, Zhiyong Wu, and LingPeng Kong. Diffuseq: Sequence to sequence text generation with diffusion models.arXiv preprint arXiv:2210.08933, 2022. 2
-
[9]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Zemin Huang, Yuhang Wang, Zhiyang Chen, and Guo-Jun Qi. Don’t settle too early: Self-reflective remasking for dif- fusion language models.arXiv preprint arXiv:2509.23653,
-
[11]
Towards mitigating llm hallucination via self reflection
Ziwei Ji, Tiezheng Yu, Yan Xu, Nayeon Lee, Etsuko Ishii, and Pascale Fung. Towards mitigating llm hallucination via self reflection. InFindings of the Association for Computa- tional Linguistics: EMNLP 2023, pages 1827–1843, 2023. 3
2023
-
[12]
Devils in middle layers of large vision- language models: Interpreting, detecting and mitigating ob- ject hallucinations via attention lens
Zhangqi Jiang, Junkai Chen, Beier Zhu, Tingjin Luo, Yankun Shen, and Xu Yang. Devils in middle layers of large vision- language models: Interpreting, detecting and mitigating ob- ject hallucinations via attention lens. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 25004–25014, 2025. 1
2025
-
[13]
Mingi Jung, Saehyung Lee, Eunji Kim, and Sungroh Yoon. Visual attention never fades: Selective progressive attention recalibration for detailed image captioning in multimodal large language models.arXiv preprint arXiv:2502.01419,
-
[14]
Llava-med: Training a large language- and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564,
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language- and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564,
-
[15]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 1
2023
-
[16]
Shufan Li, Konstantinos Kallidromitis, Hritik Bansal, Akash Gokul, Yusuke Kato, Kazuki Kozuka, Jason Kuen, Zhe Lin, Kai-Wei Chang, and Aditya Grover. Lavida: A large diffu- sion language model for multimodal understanding.arXiv preprint arXiv:2505.16839, 2025. 1, 6
-
[17]
Diffusion-lm improves control- lable text generation.Advances in neural information pro- cessing systems, 35:4328–4343, 2022
Xiang Li, John Thickstun, Ishaan Gulrajani, Percy S Liang, and Tatsunori B Hashimoto. Diffusion-lm improves control- lable text generation.Advances in neural information pro- cessing systems, 35:4328–4343, 2022. 2
2022
-
[18]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 4
2024
-
[19]
Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vi- sion, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vi- sion, pages 216–233. Springer, 2024. 6
2024
-
[20]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distri- bution, 2024.URL https://arxiv. org/abs/2310.16834. 2
work page internal anchor Pith review arXiv 2024
-
[22]
Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in Neural Information Processing Systems, 35:2507–2521,
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in Neural Information Processing Systems, 35:2507–2521,
-
[23]
Self- checkgpt: Zero-resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. Self- checkgpt: Zero-resource black-box hallucination detection for generative large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 9004–9017, 2023. 3
2023
-
[24]
Compositional chain-of-thought prompting for large multimodal models
Chancharik Mitra, Brandon Huang, Trevor Darrell, and Roei Herzig. Compositional chain-of-thought prompting for large multimodal models. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 14420–14431, 2024. 1, 3, 6
2024
-
[25]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025. 1, 2
work page internal anchor Pith review arXiv 2025
-
[26]
Liangming Pan, Michael Saxon, Wenda Xu, Deepak Nathani, Xinyi Wang, and William Yang Wang. Automat- ically correcting large language models: Surveying the land- scape of diverse self-correction strategies.arXiv preprint arXiv:2308.03188, 2023. 3
-
[27]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents.arXiv preprint arXiv:2204.06125, 1 (2):3, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2
2022
-
[29]
Simple and effective masked dif- fusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
Subham Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked dif- fusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024. 2
2024
-
[30]
The diffusion duality.arXiv preprint arXiv:2506.10892, 2025
Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin Chiu, and V olodymyr Kuleshov. The diffusion duality.arXiv preprint arXiv:2506.10892, 2025. 3
-
[31]
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuo- fan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Advancing multi-modal language models with a com- prehensive dataset and benchmark for chain-of-thought rea- soning.Advances in Neural Information Processing Systems, 37:8612–8642, 2024. 3
2024
-
[32]
Llm-check: Investigating detection of hallucinations in large language models.Advances in Neural Information Process- ing Systems, 37:34188–34216, 2024
Gaurang Sriramanan, Siddhant Bharti, Vinu Sankar Sadasi- van, Shoumik Saha, Priyatham Kattakinda, and Soheil Feizi. Llm-check: Investigating detection of hallucinations in large language models.Advances in Neural Information Process- ing Systems, 37:34188–34216, 2024. 3
2024
-
[33]
arXiv preprint arXiv:2503.00307 , year=
Guanghan Wang, Yair Schiff, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Remasking discrete diffu- sion models with inference-time scaling.arXiv preprint arXiv:2503.00307, 2025. 3
-
[34]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reason- ing in language models.arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Mul- timodal chain-of-thought reasoning: A comprehensive survey,
Yaoting Wang, Shengqiong Wu, Yuecheng Zhang, Shuicheng Yan, Ziwei Liu, Jiebo Luo, and Hao Fei. Multimodal chain-of-thought reasoning: A comprehensive survey.arXiv preprint arXiv:2503.12605, 2025. 3
-
[37]
Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022. 3
2022
-
[38]
arXiv preprint arXiv:2505.22618 , year=
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding.arXiv preprint arXiv:2505.22618, 2025. 3
-
[39]
Llava-cot: Let vision language models reason step-by-step
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2087– 2098, 2025. 1, 3
2087
-
[40]
Mmada: Multimodal large diffusion language models.arXiv preprint arXiv:2505.15809,
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang. Mmada: Mul- timodal large diffusion language models.arXiv preprint arXiv:2505.15809, 2025. 1, 6
-
[41]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025. 1, 2
work page internal anchor Pith review arXiv 2025
-
[42]
Zebin You, Shen Nie, Xiaolu Zhang, Jun Hu, Jun Zhou, Zhiwu Lu, Ji-Rong Wen, and Chongxuan Li. Llada-v: Large language diffusion models with visual instruction tuning. arXiv preprint arXiv:2505.16933, 2025. 1
-
[43]
Dimple: Discrete diffusion multimodal large language model with parallel decoding
Runpeng Yu, Xinyin Ma, and Xinchao Wang. Dimple: Dis- crete diffusion multimodal large language model with paral- lel decoding.arXiv preprint arXiv:2505.16990, 2025. 1
-
[44]
Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 46(8):5625–5644, 2024
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 46(8):5625–5644, 2024. 1
2024
-
[45]
Improve vision language model chain-of- thought reasoning
Ruohong Zhang, Bowen Zhang, Yanghao Li, Haotian Zhang, Zhiqing Sun, Zhe Gan, Yinfei Yang, Ruoming Pang, and Yiming Yang. Improve vision language model chain-of- thought reasoning. InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1631–1662, 2025. 3
2025
-
[46]
Automatic chain of thought prompting in large language models,
Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. Automatic chain of thought prompting in large language models.arXiv preprint arXiv:2210.03493, 2022. 3
-
[47]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Multimodal chain-of- thought reasoning in language models.arXiv preprint arXiv:2302.00923, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[48]
Cot-vla: Visual chain-of-thought rea- soning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought rea- soning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025. 1, 3
2025
-
[49]
Ddcot: Duty-distinct chain-of-thought prompting for multimodal reasoning in language models.Advances in Neu- ral Information Processing Systems, 36:5168–5191, 2023
Ge Zheng, Bin Yang, Jiajin Tang, Hong-Yu Zhou, and Sibei Yang. Ddcot: Duty-distinct chain-of-thought prompting for multimodal reasoning in language models.Advances in Neu- ral Information Processing Systems, 36:5168–5191, 2023. 3, 6 Thinking Diffusion: Penalize and Guide Visual-Grounded Reasoning in Diffusion Multimodal Language Models Supplementary Mater...
2023
-
[50]
Fol- lowing LaViDa and MMaDa, we adopt the think prompt to encourage structured, step-by-step reasoning during gen- eration
Prompting Details This section provides additional details about our prompt- ing used for diffusion-based multimodal reasoning. Fol- lowing LaViDa and MMaDa, we adopt the think prompt to encourage structured, step-by-step reasoning during gen- eration. The think prompt guides the model to first produce intermediate reasoning before generating the final an...
-
[51]
Additional Analysis In this subsection, we conduct additional experiments on MMaDa
Additional Results 8.1. Additional Analysis In this subsection, we conduct additional experiments on MMaDa. The results corresponding to Observation 1 and Observation 2 are presented in Figure 8 and Figure 9, re- spectively. As shown in Figure 8, MMaDa exhibits a clear Early Answer Generation, similar to what we observe in LaViDa. The model frequently gen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.