Recognition: no theorem link
Market-Bench: Benchmarking Large Language Models on Economic and Trade Competition
Pith reviewed 2026-05-10 18:43 UTC · model grok-4.3
The pith
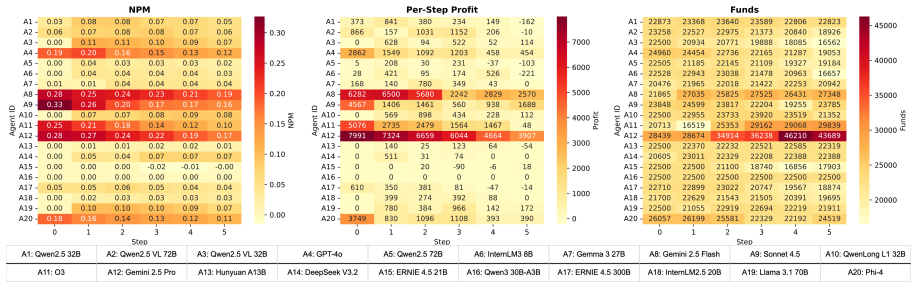
Market-Bench reveals that only a small subset of LLMs consistently achieve capital appreciation in simulated economic competition while most hover at break-even.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
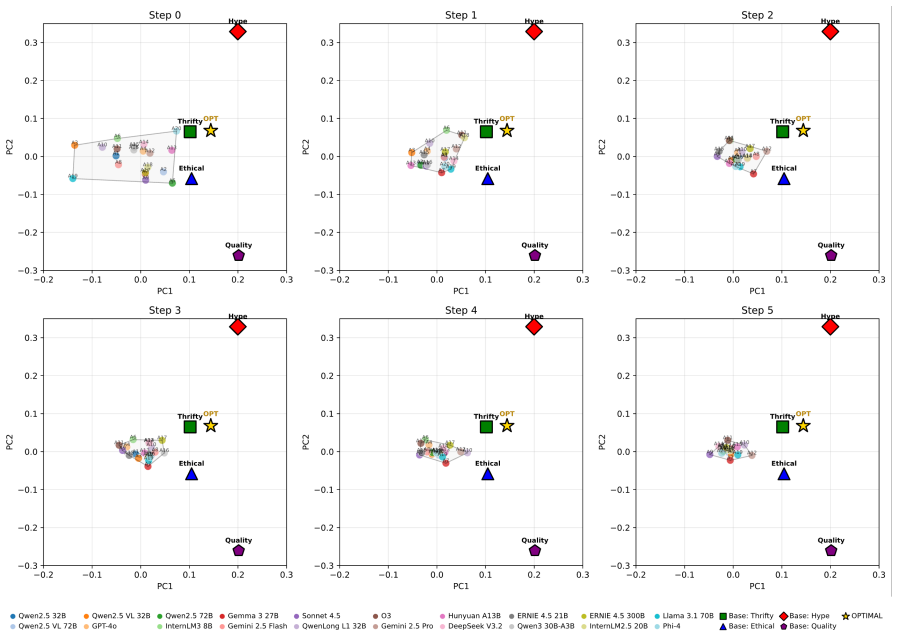
Benchmarking twenty open- and closed-source LLM agents inside the multi-agent supply chain model shows significant performance disparities and a winner-take-most phenomenon: only a small subset of LLM retailers consistently achieve capital appreciation, while many remain near the break-even point despite comparable semantic matching scores on their marketing output.
What carries the argument
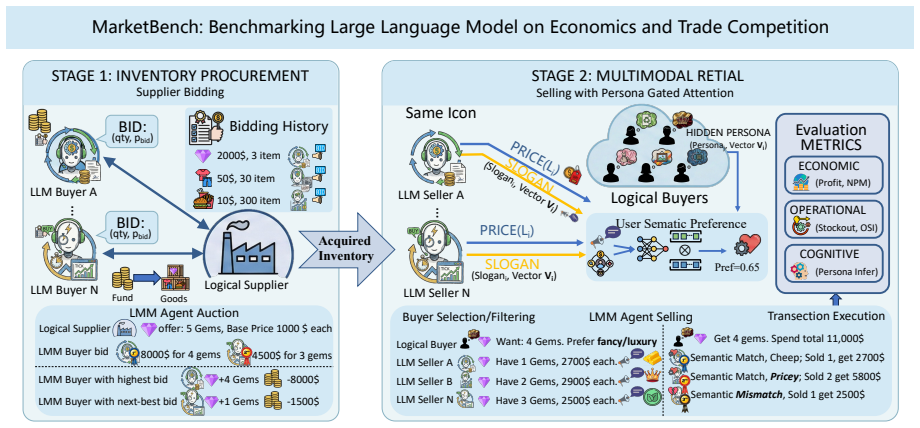
The configurable multi-agent supply chain economic model in which LLMs serve as retailer agents that bid in budget-constrained procurement auctions and then set retail prices plus slogans delivered through a role-based attention mechanism to simulated buyers.
If this is right
- Only a small subset of current LLMs can reliably grow capital when placed in competitive procurement and retail settings.
- Many LLMs produce marketing text with similar semantic quality yet fail to convert that into sustained profits or sales volume.
- Complete trajectory logs of bids, prices, and balance sheets enable repeatable economic, operational, and semantic scoring.
- The benchmark supplies a controlled testbed for observing how language models interact inside competitive markets.
Where Pith is reading between the lines
- The observed gaps may reflect differences in how models handle multi-step planning under uncertainty rather than language generation alone.
- Extending the simulation to include repeated rounds or larger numbers of agents could expose whether the winner-take-most pattern persists or stabilizes.
- The benchmark could serve as an evaluation tool for selecting or fine-tuning LLMs intended for business or trading applications.
- Differences in performance might be traceable to variations in training data volume on economic or numerical reasoning tasks.
Load-bearing premise
The auction rules, retail attention mechanism, and buyer behavior built into the supply chain model capture the essential dynamics of real economic and trade competition.
What would settle it
Running the same twenty LLMs in a materially different market model with altered auction formats or buyer preferences and finding that the same models no longer show the winner-take-most pattern would indicate the disparities are artifacts of the specific simulation rather than general LLM economic capability.
Figures



read the original abstract
The ability of large language models (LLMs) to manage and acquire economic resources remains unclear. In this paper, we introduce \textbf{Market-Bench}, a comprehensive benchmark that evaluates the capabilities of LLMs in economically-relevant tasks through economic and trade competition. Specifically, we construct a configurable multi-agent supply chain economic model where LLMs act as retailer agents responsible for procuring and retailing merchandise. In the \textbf{procurement} stage, LLMs bid for limited inventory in budget-constrained auctions. In the \textbf{retail} stage, LLMs set retail prices, generate marketing slogans, and provide them to buyers through a role-based attention mechanism for purchase. Market-Bench logs complete trajectories of bids, prices, slogans, sales, and balance-sheet states, enabling automatic evaluation with economic, operational, and semantic metrics. Benchmarking on 20 open- and closed-source LLM agents reveals significant performance disparities and winner-take-most phenomenon, \textit{i.e.}, only a small subset of LLM retailers can consistently achieve capital appreciation, while many hover around the break-even point despite similar semantic matching scores. Market-Bench provides a reproducible testbed for studying how LLMs interact in competitive markets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Market-Bench, a benchmark for LLMs in economic tasks via a configurable multi-agent supply chain model. LLMs act as retailers that bid in budget-constrained auctions during procurement and set prices plus marketing slogans in retail, routed to buyers via a role-based attention mechanism. Full trajectories of bids, prices, sales, and balance sheets are logged for automatic evaluation using economic, operational, and semantic metrics. Experiments on 20 open- and closed-source LLMs report significant performance disparities and a winner-take-most pattern, with only a small subset achieving consistent capital appreciation while most hover near break-even despite comparable semantic scores.
Significance. If the reported disparities prove robust, Market-Bench supplies a reproducible, trajectory-logging testbed for probing LLM strategic reasoning in competitive markets, a capability that is increasingly relevant for autonomous agents. The combination of external economic metrics (capital appreciation, sales) with semantic evaluation and the absence of parameter-fitting to a target outcome are strengths that distinguish it from purely synthetic benchmarks.
major comments (3)
- [§4 and §5] §4 (Experimental Setup) and §5 (Results): No number of independent runs, statistical controls, or variance estimates are reported for the capital-appreciation disparities or winner-take-most pattern. This is load-bearing for the central claim, as the abstract asserts 'consistent' outperformance without evidence that the ordering is stable across random seeds or initial conditions.
- [§3] §3 (Model Description): The buyer purchase rule that converts role-based attention scores into actual sales probabilities is not specified (e.g., softmax temperature, threshold, or noise model). Because the retail stage directly determines revenue and capital trajectories, this omission prevents assessment of whether the observed LLM ranking is driven by the attention mechanism's particular functional form rather than LLM reasoning.
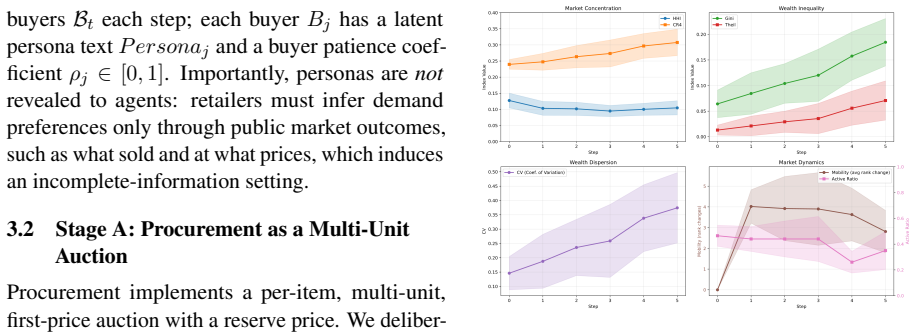
- [§5] §5 (Results): No sensitivity sweeps or alternative configurations are presented for key parameters such as inventory scarcity in the procurement auctions or attention weighting in retail. The skeptic concern is therefore unaddressed: the winner-take-most pattern could be an artifact of the chosen scarcity level or attention bias rather than a general property of LLM economic behavior.
minor comments (2)
- [Abstract and §4] The abstract states that 'many hover around the break-even point despite similar semantic matching scores' but the precise definition and computation of semantic matching (e.g., embedding model, similarity threshold) is not given in the metrics subsection; a short clarifying sentence would improve reproducibility.
- [§4] Table or appendix listing the exact 20 LLMs (including versions and API endpoints) is missing; this is a minor but necessary detail for a benchmarking paper.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help improve the rigor and clarity of the Market-Bench manuscript. We address each major comment point by point below and will incorporate the suggested revisions in the next version.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Experimental Setup) and §5 (Results): No number of independent runs, statistical controls, or variance estimates are reported for the capital-appreciation disparities or winner-take-most pattern. This is load-bearing for the central claim, as the abstract asserts 'consistent' outperformance without evidence that the ordering is stable across random seeds or initial conditions.
Authors: We agree that the absence of reported independent runs, statistical controls, and variance estimates limits the strength of the central claims. We will revise §4 to explicitly document the experimental protocol, including the number of independent runs performed with different random seeds, and add variance estimates, standard errors, and basic statistical comparisons to the results presentation in §5. These additions will directly support the stability of the observed performance ordering and winner-take-most pattern. revision: yes
-
Referee: [§3] §3 (Model Description): The buyer purchase rule that converts role-based attention scores into actual sales probabilities is not specified (e.g., softmax temperature, threshold, or noise model). Because the retail stage directly determines revenue and capital trajectories, this omission prevents assessment of whether the observed LLM ranking is driven by the attention mechanism's particular functional form rather than LLM reasoning.
Authors: We acknowledge this omission in the model description. We will add a complete specification of the buyer purchase rule in the revised §3, detailing the exact conversion from role-based attention scores to sales probabilities (including the functional form, temperature parameter, any thresholds, and noise model). This will allow readers to evaluate the contribution of the attention mechanism versus LLM reasoning. revision: yes
-
Referee: [§5] §5 (Results): No sensitivity sweeps or alternative configurations are presented for key parameters such as inventory scarcity in the procurement auctions or attention weighting in retail. The skeptic concern is therefore unaddressed: the winner-take-most pattern could be an artifact of the chosen scarcity level or attention bias rather than a general property of LLM economic behavior.
Authors: We agree that sensitivity analysis is required to address concerns about parameter-specific artifacts. We will add a new subsection to §5 containing sensitivity sweeps over inventory scarcity levels in the procurement auctions and attention weighting parameters in the retail stage. These experiments will demonstrate whether the winner-take-most pattern persists across reasonable variations, thereby supporting its generality as a property of LLM economic behavior. revision: yes
Circularity Check
Empirical benchmark with no self-referential derivations or fitted predictions
full rationale
The paper constructs a configurable multi-agent supply chain model and reports empirical outcomes from running 20 LLMs as retailer agents, including observed capital appreciation disparities and a winner-take-most pattern. No mathematical derivations, equations, or first-principles claims are present that reduce these results to quantities defined by the authors' own fitted parameters, self-citations, or ansatzes. The model rules (auctions, attention mechanism) are explicitly configurable inputs, and success metrics (capital appreciation, sales) are external economic quantities rather than quantities the paper fits to match its own predictions. This is a standard empirical benchmark setup with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
role-based attention mechanism
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Predicting Decisions of AI Agents from Limited Interaction through Text-Tabular Modeling
A tabular foundation model with LLM-as-Observer features predicts AI agent decisions in controlled games, outperforming baselines by 4 AUC points and 14% lower error at K=16 interactions.
Reference graph
Works this paper leans on
-
[1]
Got slogan? guidelines for creating effective slogans.Business Horizons, 50(5):415–422. Lu Liu, Huiyu Duan, Qiang Hu, Liu Yang, Chunlei Cai, Tianxiao Ye, Huayu Liu, Xiaoyun Zhang, and Guangtao Zhai. 2024. F-bench: Rethinking human preference evaluation metrics for benchmarking face generation, customization, and restoration.arXiv preprint arXiv:2412.13155...
-
[2]
Alympics: Language agents meet game theory.arXiv preprint arXiv:2311.03220, 2023
Alympics: Llm agents meet game theory – exploring strategic decision-making with ai agents. arXiv preprint arXiv:2311.03220. OpenAI. 2024. GPT-4o system card.arXiv preprint arXiv:2410.21276. Joon Sung Park, Joseph C O’Brien, Carrie J Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S Bern- stein. 2023. Generative agents: Interactive simulacra of hu...
-
[3]
Agentsociety: Large-scale simulation of llm-driven generative agents advances understand- ing of human behaviors and society.arXiv preprint arXiv:2502.08691. David Simchi-Levi, Konstantina Mellou, Ishai Men- ache, and Jeevan Pathuri. 2025. Large language models for supply chain decisions.arXiv preprint arXiv:2507.21502. Statista. 2024. Artificial intellig...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8580–8622, Vienna, Austria
Multiagentbench: Evaluating the collabora- tion and competition of llm agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8580–8622, Vienna, Austria. Association for Computational Linguistics. A Simulation Algorithm The complete simulation loop for Market-Bench proceeds as follo...
-
[5]
2.For each stept= 0,
Initialize: Set Fundsi ←K init, Invi,x ←0 for all agentsi∈ Aand itemsx∈ X. 2.For each stept= 0, . . . , T−1: (a) Prepare supplier offersO S(t). (b)Stage A (Procurement): • For each bidding round r= 1, . . . , Rmax: • Build bidding state with previous round results. • Each agent i submits bid bi via LLM call (in parallel). • Validate budget constraints; re...
-
[6]
bids": {
Return: Logged trajectories and final metrics. A.1 Bid Settlement Procedure For each itemx, bids are sorted by price descending with random tie-breaking. The available quantity Qx is allocated greedily to highest bidders above the reserve priceP base(x): ai,x = min(qi,x,remaining) ifp bid i,x ≥P base(x) (10) B LLM Agent Prompts B.1 Procurement Stage Promp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.