Recognition: no theorem link
Predicting Decisions of AI Agents from Limited Interaction through Text-Tabular Modeling
Pith reviewed 2026-05-13 05:05 UTC · model grok-4.3
The pith
A text-tabular model with LLM hidden states as features predicts unfamiliar AI agents' decisions from a small number of past interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Formulating counterpart prediction as a target-adaptive text-tabular task enables effective adaptation to specific agents. Training on 13 frontier-LLM agents and testing on 91 held-out scaffolded agents, the full model outperforms direct LLM-as-Predictor prompting and game-plus-text baselines. Within the tabular model, Observer features improve response-prediction AUC by about 4 points across both tasks and reduce bargaining offer-prediction error by 14 percent at K=16. These gains demonstrate that hidden LLM representations expose decision-relevant signals that direct prompting does not surface.
What carries the argument
LLM-as-Observer: a small frozen LLM that reads the current decision-time state and dialogue, discards its generated answer, and supplies its hidden state as an additional decision-oriented feature inside a tabular foundation model that also encodes game-state features and LLM text representations.
If this is right
- Observer features add predictive value beyond structured game state and raw text representations.
- The same tabular architecture works for both discrete response prediction and continuous offer prediction.
- Performance improves as the number of adaptation examples K increases up to at least 16.
- Direct prompting of an LLM to act as a predictor is inferior to embedding its hidden states into a tabular model.
Where Pith is reading between the lines
- The method could be applied to predict actions of commercial AI assistants in procurement or customer-service settings if their interaction logs are available.
- If the same hidden-state signals appear in human decision data, the framework might transfer to modeling human counterparts from short interaction histories.
- Agents could be designed to obscure their internal states specifically to defeat this style of observer-based prediction.
Load-bearing premise
Controlled bargaining and negotiation games with scaffolded agents capture the decision-making patterns of real-world AI agents whose prompts, control logic, and rule-based fallbacks remain hidden.
What would settle it
Run the trained model on agents whose prompts and fallback rules are not constructed via the same scaffolding procedure used in the study, then measure whether AUC and offer-error gains disappear.
Figures
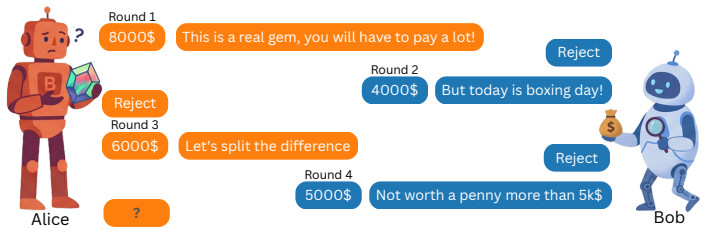


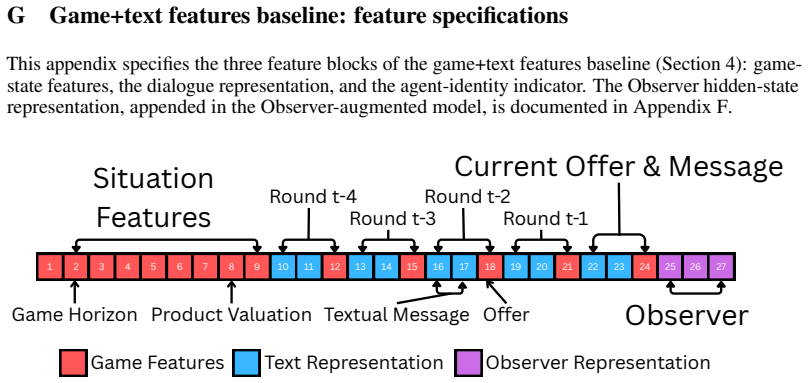
read the original abstract
AI agents negotiate and transact in natural language with unfamiliar counterparts: a buyer bot facing an unknown seller, or a procurement assistant negotiating with a supplier. In such interactions, the counterpart's LLM, prompts, control logic, and rule-based fallbacks are hidden, while each decision can have monetary consequences. We ask whether an agent can predict an unfamiliar counterpart's next decision from a few interactions. To avoid real-world logging confounds, we study this problem in controlled bargaining and negotiation games, formulating it as target-adaptive text-tabular prediction: each decision point is a table row combining structured game state, offer history, and dialogue, while $K$ previous games of the same target agent, i.e., the counterpart being modeled, are provided in the prompt as labeled adaptation examples. Our model is built on a tabular foundation model that represents rows using game-state features and LLM-based text representations, and adds LLM-as-Observer as an additional representation: a small frozen LLM reads the decision-time state and dialogue; its answer is discarded, and its hidden state becomes a decision-oriented feature, making the LLM an encoder rather than a direct few-shot predictor. Training on 13 frontier-LLM agents and testing on 91 held-out scaffolded agents, the full model outperforms direct LLM-as-Predictor prompting and game+text features baselines. Within this tabular model, Observer features contribute beyond the other feature schemes: at $K=16$, they improve response-prediction AUC by about 4 points across both tasks and reduce bargaining offer-prediction error by 14%. These results show that formulating counterpart prediction as a target-adaptive text-tabular task enables effective adaptation, and that hidden LLM representations expose decision-relevant signals that direct prompting does not surface.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes formulating prediction of unfamiliar AI agents' decisions in bargaining and negotiation games as a target-adaptive text-tabular task. A tabular foundation model is trained on 13 frontier-LLM agents using game-state features, text representations, and LLM-as-Observer hidden states (with K prior games as labeled adaptation examples in the prompt); it is evaluated on 91 held-out scaffolded agents. The full model outperforms direct LLM-as-Predictor prompting and game+text baselines, with Observer features adding ~4 AUC points to response prediction and reducing offer-prediction error by 14% at K=16.
Significance. If the empirical gains hold, the work would contribute to multi-agent systems by showing that hidden LLM representations can surface decision-relevant signals beyond direct prompting or structured features alone. Credit is due for the clean separation of the frozen LLM as an encoder (rather than few-shot predictor), the target-adaptive formulation, and the held-out agent split that avoids obvious circularity.
major comments (2)
- [Abstract] Abstract: the reported gains (approximately 4 AUC points and 14% error reduction at K=16) are presented without statistical significance tests, error bars, details on the 13+91 agent split, data exclusion criteria, or controls for confounds. These omissions make it impossible to assess whether the central performance claims are robust.
- [Abstract and Evaluation section] Abstract and Evaluation section: the quantitative results rest on testing against 91 scaffolded agents whose explicit control logic is known by construction. This setup may allow Observer features to exploit deterministic regularities that would not exist for frontier LLMs whose prompts, internal states, and rule-based fallbacks remain hidden—the motivating use case. The paper acknowledges the controlled setting “to avoid real-world logging confounds,” yet presents the gains as evidence for the general problem; this mismatch is load-bearing for the claimed applicability.
minor comments (2)
- [Methods] Clarify in the methods how the K adaptation examples are exactly formatted and whether any leakage from the target agent's identity occurs through the tabular features.
- [Experimental Setup] Add explicit definitions or a table for all feature schemes (game, text, Observer) and baselines to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported gains (approximately 4 AUC points and 14% error reduction at K=16) are presented without statistical significance tests, error bars, details on the 13+91 agent split, data exclusion criteria, or controls for confounds. These omissions make it impossible to assess whether the central performance claims are robust.
Authors: We agree that these details are necessary for assessing robustness. In the revised manuscript, we will add statistical significance tests (e.g., paired tests across multiple random seeds) for the reported AUC and error improvements, include error bars (standard deviation over runs) in all quantitative results, provide a full description of the 13+91 agent split including how the scaffolded agents were generated and any exclusion criteria, and discuss controls for confounds such as game parameterization and agent diversity. These additions will be incorporated into both the abstract and the evaluation section. revision: yes
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: the quantitative results rest on testing against 91 scaffolded agents whose explicit control logic is known by construction. This setup may allow Observer features to exploit deterministic regularities that would not exist for frontier LLMs whose prompts, internal states, and rule-based fallbacks remain hidden—the motivating use case. The paper acknowledges the controlled setting “to avoid real-world logging confounds,” yet presents the gains as evidence for the general problem; this mismatch is load-bearing for the claimed applicability.
Authors: We acknowledge the gap between the controlled scaffolded setting and fully opaque frontier LLMs. The scaffolded agents were explicitly designed to replicate observed decision patterns from frontier LLMs in the same games, enabling isolation of modeling effects without logging confounds. We will revise the abstract and evaluation section to more precisely frame the results as evidence for the target-adaptive formulation and the value of Observer features within controlled approximations of the motivating scenario. We will also expand the limitations discussion to explicitly note that deterministic regularities may be more exploitable here than in hidden-state cases, and outline future directions such as proxy evaluations on additional LLM variants. revision: partial
Circularity Check
No circularity: empirical train/test split on held-out agents with frozen encoder
full rationale
The paper's core claim is an empirical result: a tabular model trained on interaction data from 13 frontier-LLM agents is evaluated on 91 held-out scaffolded agents, with performance gains attributed to Observer features extracted from a frozen LLM. No equations, derivations, or first-principles steps are presented that reduce predictions to fitted parameters by construction. The adaptation examples are explicitly labeled data from the target agent, the Observer LLM is frozen and not trained on the prediction task, and the test agents are disjoint from training. This setup contains no self-definitional loops, fitted-input-as-prediction, or load-bearing self-citations; the reported AUC and error improvements are standard held-out evaluation metrics.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Hidden states from a frozen LLM reading decision-time state and dialogue contain predictive signals for the agent's next action that are not accessible via direct prompting.
- domain assumption Controlled bargaining and negotiation games with scaffolded agents provide a valid proxy for real-world interactions with hidden LLM prompts and logic.
Reference graph
Works this paper leans on
-
[1]
Cooperation, competition, and maliciousness: LLM-stakeholders interactive negotiation
Sahar Abdelnabi, Amr Gomaa, Sarath Sivaprasad, Lea Schönherr, and Mario Fritz. Cooperation, competition, and maliciousness: LLM-stakeholders interactive negotiation. InAdvances in Neural Information Processing Systems: Datasets and Benchmarks Track, volume 37, 2024
work page 2024
-
[2]
Stefano V Albrecht and Subramanian Ramamoorthy. A game-theoretic model and best-response learning method for ad hoc coordination in multiagent systems. InProceedings of the 12th International Conference on Autonomous Agents and Multiagent Systems, pages 1155–1156, 2013
work page 2013
-
[3]
Stefano V Albrecht and Peter Stone. Autonomous agents modelling other agents: A compre- hensive survey and open problems.Artificial Intelligence, 258:66–95, 2018
work page 2018
-
[4]
Belief and truth in hypothesised behaviours.Artificial Intelligence, 235:63–94, 2016
Stefano V Albrecht, Jacob W Crandall, and Subramanian Ramamoorthy. Belief and truth in hypothesised behaviours.Artificial Intelligence, 235:63–94, 2016
work page 2016
-
[5]
Project Deal: A Claude-run marketplace experiment
Anthropic. Project Deal: A Claude-run marketplace experiment. Anthropic research blog, 2026. https://www.anthropic.com/features/project-deal
work page 2026
-
[6]
TabSTAR: A tabular foundation model for tabular data with text fields
Alan Arazi, Eilam Shapira, and Roi Reichart. TabSTAR: A tabular foundation model for tabular data with text fields. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=FrXHdcTEzE
work page 2025
-
[7]
MulTaBench: Benchmarking Multimodal Tabular Learning with Text and Image
Alan Arazi, Eilam Shapira, Shoham Grunblat, Mor Ventura, Elad Hoffer, Gioia Blayer, David Holzmüller, Lennart Purucker, Gaël Varoquaux, Frank Hutter, and Roi Reichart. MulTaBench: Benchmarking multimodal tabular learning with text and image.arXiv preprint arXiv:2605.10616, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Tim Baarslag, Mark J. C. Hendrikx, Koen V . Hindriks, and Catholijn M. Jonker. Learning about the opponent in automated bilateral negotiation: A comprehensive survey of opponent modeling techniques.Autonomous Agents and Multi-Agent Systems, 30(5):849–898, 2016. doi: 10.1007/s10458-015-9309-1
-
[9]
Steffen Backmann, David Guzman Piedrahita, Emanuel Tewolde, Rada Mihalcea, Bernhard Schölkopf, and Zhijing Jin. When ethics and payoffs diverge: LLM agents in morally charged social dilemmas.arXiv preprint arXiv:2505.19212, 2025
-
[10]
ElecTwit: A framework for studying persuasion in multi-agent social systems
Michael Bao. ElecTwit: A framework for studying persuasion in multi-agent social systems. arXiv preprint arXiv:2601.00994, 2026
-
[11]
Probing classifiers: Promises, shortcomings, and advances
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1):207–219, 2022. doi: 10.1162/coli_a_00422
-
[12]
How well can LLMs negotiate? NegotiationArena platform and analysis
Federico Bianchi, Patrick John Chia, Mert Yuksekgonul, Jacopo Tagliabue, Dan Jurafsky, and James Zou. How well can LLMs negotiate? NegotiationArena platform and analysis. InProceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 3935–3951. PMLR, 2024. 10
work page 2024
-
[13]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems 33 (NeurIPS 2020), volume 33, pages 1877–1901, 2020
work page 2020
-
[14]
Grounding strategic conversation: Using negotiation dialogues to predict trades in a win-lose game
Anaïs Cadilhac, Nicholas Asher, Farah Benamara, and Alex Lascarides. Grounding strategic conversation: Using negotiation dialogues to predict trades in a win-lose game. InProceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 357–368, 2013
work page 2013
-
[15]
Gian Maria Campedelli, Nicolò Penzo, Massimo Stefan, Roberto Dessì, Marco Guerini, Bruno Lepri, and Jacopo Staiano. I want to break free! persuasion and anti-social behavior of LLMs in multi-agent settings with social hierarchy.arXiv preprint arXiv:2410.07109, 2024
-
[16]
Opponent modeling in negotiation dialogues by related data adaptation
Kushal Chawla, Gale Lucas, Jonathan May, and Jonathan Gratch. Opponent modeling in negotiation dialogues by related data adaptation. InFindings of the Association for Computa- tional Linguistics: NAACL 2022, pages 661–674, Seattle, United States, 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.findings-naacl.50
-
[17]
Dong Chen, Kaian Chen, Zhaojian Li, Tianshu Chu, Rui Yao, Feng Qiu, and Kaixiang Lin. PowerNet: Multi-agent deep reinforcement learning for scalable powergrid control.IEEE Transactions on Power Systems, 37(2):1587–1599, 2022
work page 2022
-
[18]
Jiangjie Chen, Siyu Yuan, Rong Ye, Bodhisattwa Prasad Majumder, and Kyle Richardson. Put your money where your mouth is: Evaluating strategic planning and execution of LLM agents in an auction arena.arXiv preprint arXiv:2310.05746, 2023
-
[19]
Robert M. Coehoorn and Nicholas R. Jennings. Learning on opponent’s preferences to make effective multi-issue negotiation trade-offs. InProceedings of the 6th International Conference on Electronic Commerce, pages 59–68, 2004
work page 2004
-
[20]
What you can cram into a single $&!#* vector: Probing sentence embeddings for linguistic properties
Alexis Conneau, German Kruszewski, Guillaume Lample, Loïc Barrault, and Marco Baroni. What you can cram into a single $&!#* vector: Probing sentence embeddings for linguistic properties. InProceedings of the 56th Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 2126–2136, Melbourne, Australia, 2018. Associat...
-
[21]
Scalable multiagent driving policies for reducing traffic congestion
Jiaxun Cui, William Macke, Harel Yedidsion, Aastha Goyal, Daniel Urieli, and Peter Stone. Scalable multiagent driving policies for reducing traffic congestion. InProceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), 2021
work page 2021
-
[22]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, and Zhifang Sui. A survey on in-context learning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1107–1128, Miami, Florida, USA, 2024. Association for Computational Linguistics....
-
[23]
Attention graph for multi-robot social navigation with deep reinforcement learning
Erwan Escudie, Laetitia Matignon, and Jacques Saraydaryan. Attention graph for multi-robot social navigation with deep reinforcement learning. InProceedings of the 23rd International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), 2024. Extended Abstract
work page 2024
-
[24]
Nicholas Goldowsky-Dill, Bilal Chughtai, Stefan Heimersheim, and Marius Hobbhahn
Sara Fish, Yannai A. Gonczarowski, and Ran I. Shorrer. Algorithmic collusion by large language models.arXiv preprint arXiv:2404.00806, 2024
-
[25]
Inside-Out: Hidden factual knowledge in LLMs
Zorik Gekhman, Eyal Ben David, Hadas Orgad, Eran Ofek, Yonatan Belinkov, Idan Szpektor, Jonathan Herzig, and Roi Reichart. Inside-Out: Hidden factual knowledge in LLMs. In Conference on Language Modeling, 2025
work page 2025
-
[26]
Piotr J Gmytrasiewicz and Prashant Doshi. A framework for sequential planning in multi-agent settings.Journal of Artificial Intelligence Research, 24:49–79, 2005
work page 2005
-
[27]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Chawla, Olaf Wiest, and Xiangliang Zhang
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V . Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: A survey of progress and challenges. InProceedings of the 33rd International Joint Conference on Artificial Intelligence, pages 8048–8057, 2024. doi: 10.24963/ijcai.2024/890
-
[29]
Decoupling strategy and generation in negotiation dialogues
He He, Derek Chen, Anusha Balakrishnan, and Percy Liang. Decoupling strategy and generation in negotiation dialogues. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2333–2343, Brussels, Belgium, 2018. Association for Computational Linguistics
work page 2018
-
[30]
Mourad Heddaya, Solomon Dworkin, Chenhao Tan, Rob V oigt, and Alexander Zentefis. Lan- guage of bargaining. InProceedings of the 61st Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 13161–13185. Association for Computational Linguistics, 2023
work page 2023
-
[31]
John Hewitt and Christopher D. Manning. A structural probe for finding syntax in word representations. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4129–4138, Minneapolis, Minnesota, 2019. Association for Computation...
-
[32]
TabPFN: A transformer that solves small tabular classification problems in a second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. TabPFN: A transformer that solves small tabular classification problems in a second. InThe Eleventh International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[33]
Accurate predictions on small data with a tabular foundation model.Nature, 637:319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637:319–326, 2025
work page 2025
-
[34]
BERT has more to offer: BERT layers combination yields better sentence embeddings
MohammadSaleh Hosseini, Munawara Munia, and Latifur Khan. BERT has more to offer: BERT layers combination yields better sentence embeddings. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 15419–15431, 2023
work page 2023
-
[35]
Seth Karten, Wenzhe Li, Zihan Ding, Samuel Kleiner, Yu Bai, and Chi Jin. LLM economist: Large population models and mechanism design in multi-agent generative simulacra.arXiv preprint arXiv:2507.15815, 2025
-
[36]
CARTE: Pretraining and transfer for tabular learning
Myung Jun Kim, Leo Grinsztajn, and Gael Varoquaux. CARTE: Pretraining and transfer for tabular learning. InProceedings of the 41st International Conference on Machine Learning, pages 23843–23866, 2024
work page 2024
-
[37]
LLM embeddings for deep learning on tabular data.arXiv preprint arXiv:2502.11596, 2025
Boshko Koloski, Andrei Margeloiu, Xiangjian Jiang, Blaž Škrlj, Nikola Simidjievski, and Mateja Jamnik. LLM embeddings for deep learning on tabular data.arXiv preprint arXiv:2502.11596, 2025
-
[38]
Deuksin Kwon, Emily Weiss, Tara Kulshrestha, Kushal Chawla, Gale Lucas, and Jonathan Gratch. Are LLMs effective negotiators? systematic evaluation of the multifaceted capabilities of LLMs in negotiation dialogues. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 5391–5413, 2024
work page 2024
-
[39]
De- tecting winning arguments with large language models and persuasion strategies
Tiziano Labruna, Arkadiusz Modzelewski, Giorgio Satta, and Giovanni Da San Martino. De- tecting winning arguments with large language models and persuasion strategies. InFindings of the Association for Computational Linguistics: EACL 2026, pages 1888–1915, Rabat, Morocco,
work page 2026
-
[40]
doi: 10.18653/v1/2026.findings-eacl.97
Association for Computational Linguistics. doi: 10.18653/v1/2026.findings-eacl.97
-
[41]
Emergence of linguistic communication from referential games with symbolic and pixel input
Angeliki Lazaridou, Alexander Peysakhovich, and Marco Baroni. Emergence of linguistic communication from referential games with symbolic and pixel input. InProceedings of the 6th International Conference on Learning Representations (ICLR), 2018
work page 2018
-
[42]
Theory of mind for multi-agent collaboration via large language models
Huao Li, Yu Chong, Simon Stepputtis, Joseph Campbell, Dana Hughes, Charles Lewis, and Katia Sycara. Theory of mind for multi-agent collaboration via large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 180–192, 2023. 12
work page 2023
-
[43]
Spontaneous giving and calculated greed in language models
Yuxuan Li and Hirokazu Shirado. Spontaneous giving and calculated greed in language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5271–5286, 2025
work page 2025
-
[44]
Communication enables cooperation in LLM agents: A comparison with curriculum-based approaches
Hachem Madmoun and Salem Lahlou. Communication enables cooperation in LLM agents: A comparison with curriculum-based approaches. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2: Short Papers), pages 307–321, Rabat, Morocco, 2026. Association for Computational Linguistics. doi: 10.1865...
-
[45]
Reuth Mirsky, Ignacio Carlucho, Arrasy Rahman, Elliot Fosong, William Macke, Mohan Sridharan, Peter Stone, and Stefano V . Albrecht. A survey of ad hoc teamwork research. In Multi-Agent Systems. EUMAS 2022, volume 13442 ofLecture Notes in Computer Science, pages 275–293. Springer, 2022. doi: 10.1007/978-3-031-20614-6_16
-
[46]
Towards benchmarking foundation models for tabular data with text
Martin Mráz, Breenda Das, Anshul Gupta, Lennart Purucker, and Frank Hutter. Towards benchmarking foundation models for tabular data with text. InFoundation Models for Structured Data Workshop at ICML, 2025
work page 2025
-
[47]
Adaptive theory of mind for LLM-based multi-agent coordination
Chunjiang Mu, Ya Zeng, Qiaosheng Zhang, Kun Shao, Chen Chu, Hao Guo, Danyang Jia, Zhen Wang, and Shuyue Hu. Adaptive theory of mind for LLM-based multi-agent coordination. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 29608–29616,
-
[48]
doi: 10.1609/aaai.v40i35.40204
-
[49]
Samer B Nashed and Shlomo Zilberstein. A survey of opponent modeling in adversarial domains.Journal of Artificial Intelligence Research, 73:277–327, 2022
work page 2022
-
[50]
Learn- ing theory of mind via dynamic traits attribution
Dung Nguyen, Phuoc Nguyen, Hung Le, Kien Do, Svetha Venkatesh, and Truyen Tran. Learn- ing theory of mind via dynamic traits attribution. InProceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, pages 954–962, 2022
work page 2022
-
[51]
Memory- augmented theory of mind network
Dung Nguyen, Phuoc Nguyen, Hung Le, Kien Do, Svetha Venkatesh, and Truyen Tran. Memory- augmented theory of mind network. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 11630–11637, 2023. doi: 10.1609/aaai.v37i10.26374
-
[52]
LLMs know more than they show: On the intrinsic representation of LLM hallucinations
Hadas Orgad, Michael Toker, Zorik Gekhman, Roi Reichart, Idan Szpektor, Hadas Kotek, and Yonatan Belinkov. LLMs know more than they show: On the intrinsic representation of LLM hallucinations. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[53]
Deep contextualized word representations
Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2227–2237, New Orleans, Louisiana, 2018. Associatio...
work page 2018
-
[54]
Priyanshu Priya, Rishikant Chigrupaatii, Mauajama Firdaus, and Asif Ekbal. GENTEEL- NEGOTIATOR: LLM-enhanced mixture-of-expert-based reinforcement learning approach for polite negotiation dialogue. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25010–25018, 2025
work page 2025
-
[55]
TabICL: A tabular foundation model for in-context learning on large data
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICL: A tabular foundation model for in-context learning on large data. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 50817–50847. PMLR, 2025
work page 2025
-
[56]
Neil Rabinowitz, Frank Perbet, Francis Song, Chiyuan Zhang, S. M. Ali Eslami, and Matthew Botvinick. Machine theory of mind. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 4218–4227. PMLR, 2018
work page 2018
-
[57]
Ribeiro, Gonçalo Rodrigues, Alberto Sardinha, and Francisco S
João G. Ribeiro, Gonçalo Rodrigues, Alberto Sardinha, and Francisco S. Melo. TEAMSTER: Model-based reinforcement learning for ad hoc teamwork.Artificial Intelligence, 324:104013,
-
[58]
doi: 10.1016/j.artint.2023.104013. 13
-
[59]
The agentic economy.arXiv preprint arXiv:2505.15799, 2025
David M. Rothschild, Markus Mobius, Jake M. Hofman, Eleanor W. Dillon, Daniel G. Goldstein, Nicole Immorlica, Sonia Jaffe, Brendan Lucier, Aleksandrs Slivkins, and Matthew V ogel. The agentic economy.arXiv preprint arXiv:2505.15799, 2025
-
[60]
Perfect equilibrium in a bargaining model.Econometrica, 50(1):97–109, 1982
Ariel Rubinstein. Perfect equilibrium in a bargaining model.Econometrica, 50(1):97–109, 1982
work page 1982
-
[61]
Eilam Shapira, Omer Madmon, Roi Reichart, and Moshe Tennenholtz. Can LLMs replace economic choice prediction labs? The case of language-based persuasion games.arXiv preprint arXiv:2401.17435, 2024
-
[62]
Eilam Shapira, Omer Madmon, Itamar Reinman, Samuel Joseph Amouyal, Roi Reichart, and Moshe Tennenholtz. GLEE: A unified framework and benchmark for language-based economic environments.arXiv preprint arXiv:2410.05254, 2024
-
[63]
Human choice prediction in language-based persuasion games: Simulation-based off-policy evaluation
Eilam Shapira, Omer Madmon, Reut Apel, Moshe Tennenholtz, and Roi Reichart. Human choice prediction in language-based persuasion games: Simulation-based off-policy evaluation. Transactions of the Association for Computational Linguistics, 13:980–1006, 2025
work page 2025
-
[64]
arXiv preprint arXiv:2603.17218 , year=
Eilam Shapira, Moshe Tennenholtz, and Roi Reichart. Alignment makes language models normative, not descriptive.arXiv preprint arXiv:2603.17218, 2026
-
[65]
Xingjian Shi, Jonas Mueller, Nick Erickson, Mu Li, and Alexander J. Smola. Benchmarking multimodal AutoML for tabular data with text fields. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, volume 1, 2021
work page 2021
-
[66]
Layer by layer: Uncovering hidden representations in language models
Oscar Skean, Md Rifat Arefin, Dan Zhao, Niket Nikul Patel, Jalal Naghiyev, Yann LeCun, and Ravid Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models. In Proceedings of the 42nd International Conference on Machine Learning, pages 55854–55875, 2025
work page 2025
-
[67]
Kaminka, Sarit Kraus, and Jeffrey S
Peter Stone, Gal A. Kaminka, Sarit Kraus, and Jeffrey S. Rosenschein. Ad hoc autonomous agent teams: Collaboration without pre-coordination. InProceedings of the AAAI Conference on Artificial Intelligence, volume 24, pages 1504–1509, 2010. doi: 10.1609/aaai.v24i1.7529
-
[68]
Learning multiagent communication with backpropagation
Sainbayar Sukhbaatar, Arthur Szlam, and Rob Fergus. Learning multiagent communication with backpropagation. InAdvances in Neural Information Processing Systems 29 (NIPS), 2016
work page 2016
-
[69]
Systematic biases in LLM simulations of debates
Amir Taubenfeld, Yaniv Dover, Roi Reichart, and Ariel Goldstein. Systematic biases in LLM simulations of debates. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 251–267, 2024
work page 2024
-
[70]
BERT Rediscovers the Classical NLP Pipeline
Ian Tenney, Dipanjan Das, and Ellie Pavlick. BERT rediscovers the classical NLP pipeline. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4593–4601, 2019. doi: 10.18653/v1/P19-1452
-
[71]
Caroline Wang, Arrasy Rahman, Ishan Durugkar, Elad Liebman, and Peter Stone. N-agent ad hoc teamwork. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[72]
Multi-agent reinforcement learning for market making: Competition without collusion
Ziyi Wang, Carmine Ventre, and Maria Polukarov. Multi-agent reinforcement learning for market making: Competition without collusion. InProceedings of the 6th ACM International Conference on AI in Finance (ICAIF), 2025
work page 2025
-
[73]
Yusen Wu, Yiran Liu, and Xiaotie Deng. MALLES: A multi-agent LLMs-based economic sandbox with consumer preference alignment.arXiv preprint arXiv:2603.17694, 2026
-
[74]
Measuring bargaining abilities of LLMs: A benchmark and a buyer-enhancement method
Tian Xia, Zhiwei He, Tong Ren, Yibo Miao, Zhuosheng Zhang, Yang Yang, and Rui Wang. Measuring bargaining abilities of LLMs: A benchmark and a buyer-enhancement method. In Findings of the Association for Computational Linguistics: ACL 2024, pages 3579–3602, 2024
work page 2024
-
[75]
Towards dynamic theory of mind: Evaluating LLM adaptation to temporal evolution of human states
Yang Xiao, Jiashuo Wang, Qiancheng Xu, Changhe Song, Chunpu Xu, Yi Cheng, Wenjie Li, and Pengfei Liu. Towards dynamic theory of mind: Evaluating LLM adaptation to temporal evolution of human states. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 24036–24057, 2025. 14
work page 2025
-
[76]
Sixiong Xie, Zhuofan Shi, Haiyang Shen, Yun Ma, Gang Huang, and Xiang Jing. M3-BENCH: Process-aware evaluation of LLM agents’ social behaviors in mixed-motive games.arXiv preprint arXiv:2601.08462, 2026
-
[77]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Improving dialog systems for negotia- tion with personality modeling
Runzhe Yang, Jingxiao Chen, and Karthik Narasimhan. Improving dialog systems for negotia- tion with personality modeling. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Lan- guage Processing (Volume 1: Long Papers), pages 681–693. Association for Computationa...
work page 2021
-
[79]
Zhining Zhang, Chuanyang Jin, Mung Yao Jia, and Tianmin Shu. AutoToM: Automated bayesian inverse planning and model discovery for open-ended theory of mind.arXiv preprint arXiv:2502.15676, 2025
-
[80]
Market-Bench: Benchmarking Large Language Models on Economic and Trade Competition
Yushuo Zheng, Huiyu Duan, Zicheng Zhang, Yucheng Zhu, Xiongkuo Min, and Guangtao Zhai. Market-Bench: Benchmarking large language models on economic and trade competition. arXiv preprint arXiv:2604.05523, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.