Recognition: 1 theorem link
· Lean TheoremControllable Singing Style Conversion with Boundary-Aware Information Bottleneck
Pith reviewed 2026-05-10 18:47 UTC · model grok-4.3
The pith
A boundary-aware Whisper bottleneck enables top naturalness in singing style conversion with limited data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
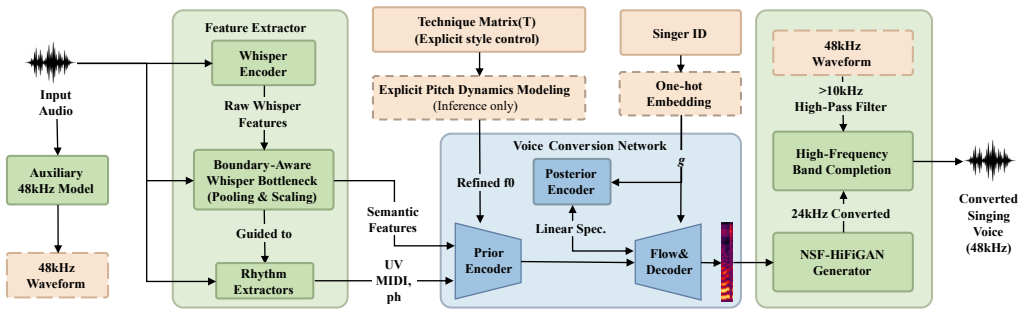
The authors establish that pooling phoneme-span representations inside a boundary-aware Whisper bottleneck suppresses residual source style while preserving linguistic content, and that pairing this with an explicit frame-level technique matrix plus targeted F0 processing and a perceptually motivated high-frequency band completion strategy produces the best naturalness among SVCC2025 submissions while using significantly less extra singing data than competitors.
What carries the argument
The boundary-aware Whisper bottleneck that pools phoneme-span representations to suppress residual source style while preserving linguistic content.
If this is right
- Stable and distinct dynamic style rendering follows from the explicit frame-level technique matrix together with targeted F0 processing at inference time.
- Data scarcity is overcome without overfitting by the perceptually motivated high-frequency band completion that draws on an auxiliary 48 kHz SVC model.
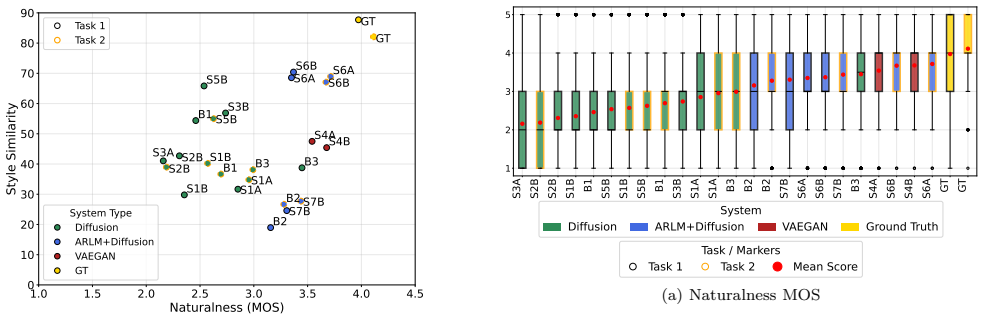
- Best-in-challenge naturalness is achieved while speaker similarity and technique control remain competitive.
- The full pipeline succeeds with markedly less extra singing data than other top systems.
Where Pith is reading between the lines
- The same boundary-aware pooling idea could be tested on speech-to-speech or music style transfer tasks where content-style disentanglement is needed.
- Perceptually guided spectrum completion may reduce the data requirements of other audio generation models beyond singing.
- Frame-level explicit control matrices could be explored for precise technique editing in music production tools.
- Whether the method extends to out-of-domain conversions remains open and could be checked with cross-dataset listening tests.
Load-bearing premise
Phoneme-boundary pooling removes source style information without distorting linguistic content or introducing artifacts.
What would settle it
Blind listening tests in which listeners can still identify the original singer's style traits above chance level, or objective metrics showing persistent style leakage after conversion.
Figures


read the original abstract
This paper presents the submission of the S4 team to the Singing Voice Conversion Challenge 2025 (SVCC2025)-a novel singing style conversion system that advances fine-grained style conversion and control within in-domain settings. To address the critical challenges of style leakage, dynamic rendering, and high-fidelity generation with limited data, we introduce three key innovations: a boundary-aware Whisper bottleneck that pools phoneme-span representations to suppress residual source style while preserving linguistic content; an explicit frame-level technique matrix, enhanced by targeted F0 processing during inference, for stable and distinct dynamic style rendering; and a perceptually motivated high-frequency band completion strategy that leverages an auxiliary standard 48kHz SVC model to augment the high-frequency spectrum, thereby overcoming data scarcity without overfitting. In the official SVCC2025 subjective evaluation, our system achieves the best naturalness performance among all submissions while maintaining competitive results in speaker similarity and technique control, despite using significantly less extra singing data than other top-performing systems. Audio samples are available online.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a singing style conversion system for the SVCC2025 challenge. It introduces three innovations: a boundary-aware Whisper bottleneck that pools phoneme-span representations to reduce source style leakage while retaining linguistic content; a frame-level technique matrix with targeted F0 processing for dynamic style control; and a high-frequency band completion method that augments spectra using an auxiliary 48 kHz SVC model. The central claim is that the system achieved the best naturalness scores in the official subjective listening tests while remaining competitive in speaker similarity and technique control, despite using significantly less extra singing data than other top entries.
Significance. If the data-efficiency claim and the causal contribution of the proposed mechanisms can be verified, the work would offer a practical advance in controllable singing voice conversion under data constraints. Participation in an official challenge provides an independent subjective benchmark, which is a strength, but the absence of supporting objective metrics and ablations limits the ability to generalize the result beyond this specific evaluation.
major comments (3)
- [High-frequency band completion strategy] High-frequency band completion strategy: The manuscript does not report the singing-specific training data, corpus size, or parameter count for the auxiliary 48 kHz SVC model. This information is required to substantiate the claim of using 'significantly less extra singing data' than competitors; any substantial singing data used for the auxiliary model would directly weaken the data-efficiency interpretation of the top naturalness result.
- [Boundary-aware Whisper bottleneck] Boundary-aware Whisper bottleneck: No objective style-leakage metrics (e.g., F0 correlation, timbre classifier accuracy, or prosody similarity scores on converted outputs) are provided to confirm that phoneme-span pooling suppresses residual source style rather than simply averaging representations. Without such evidence, the mechanism's role in the observed naturalness improvement cannot be isolated from the other components or the auxiliary model.
- [Experimental results] Experimental results: The paper reports only the official subjective challenge scores and supplies neither ablation studies nor objective metrics (such as MCD, F0 RMSE, or technique classification accuracy) to quantify the individual contributions of the three innovations. This makes it difficult to attribute the best naturalness performance specifically to the proposed boundary-aware bottleneck and technique matrix.
minor comments (1)
- [Abstract] The abstract refers to 'in-domain settings' without defining the term or clarifying how the proposed system operates within versus outside those settings relative to the SVCC2025 task.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our SVCC2025 submission. We address each major comment below with clarifications and commit to revisions that strengthen the presentation of our data usage and evaluation without altering the core claims or results.
read point-by-point responses
-
Referee: [High-frequency band completion strategy] High-frequency band completion strategy: The manuscript does not report the singing-specific training data, corpus size, or parameter count for the auxiliary 48 kHz SVC model. This information is required to substantiate the claim of using 'significantly less extra singing data' than competitors; any substantial singing data used for the auxiliary model would directly weaken the data-efficiency interpretation of the top naturalness result.
Authors: We appreciate this observation. The auxiliary 48 kHz SVC model was trained on exactly the same limited in-domain singing data used for the primary system, augmented only by publicly available non-singing speech corpora to model high-frequency content. No additional singing-specific data was introduced. We will revise the manuscript to report the precise corpus sizes, training details, and parameter count of the auxiliary model, thereby substantiating the data-efficiency claim. revision: yes
-
Referee: [Boundary-aware Whisper bottleneck] Boundary-aware Whisper bottleneck: No objective style-leakage metrics (e.g., F0 correlation, timbre classifier accuracy, or prosody similarity scores on converted outputs) are provided to confirm that phoneme-span pooling suppresses residual source style rather than simply averaging representations. Without such evidence, the mechanism's role in the observed naturalness improvement cannot be isolated from the other components or the auxiliary model.
Authors: We acknowledge that objective style-leakage metrics were not included in the original submission. The phoneme-span pooling mechanism is intended to suppress frame-level source style variations while preserving linguistic content. Although the top naturalness scores offer supporting evidence, we agree that explicit metrics would strengthen the argument. We will add objective style-leakage metrics, including F0 correlation and timbre similarity scores, to the revised manuscript. revision: yes
-
Referee: [Experimental results] Experimental results: The paper reports only the official subjective challenge scores and supplies neither ablation studies nor objective metrics (such as MCD, F0 RMSE, or technique classification accuracy) to quantify the individual contributions of the three innovations. This makes it difficult to attribute the best naturalness performance specifically to the proposed boundary-aware bottleneck and technique matrix.
Authors: As a challenge submission, the primary results are the official subjective scores, which provide an independent benchmark. We focused on these due to the evaluation protocol and manuscript constraints. We will incorporate additional objective metrics (MCD, F0 RMSE, technique classification accuracy) and targeted ablations for the boundary-aware bottleneck and technique matrix in the revised version to better isolate component contributions. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical system architecture consisting of three stated innovations (boundary-aware Whisper bottleneck, frame-level technique matrix with F0 processing, and auxiliary high-frequency completion) and reports performance from an external SVCC2025 challenge evaluation. No mathematical derivations, predictions, or equations are present that reduce claimed results to fitted parameters, self-definitions, or self-citation chains by construction. The subjective scores are independent of the internal design choices, and the paper is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearboundary-aware Whisper bottleneck that pools phoneme-span representations to suppress residual source style while preserving linguistic content; an explicit frame-level technique matrix... high-frequency band completion strategy
Reference graph
Works this paper leans on
-
[1]
Y. Zhang, H. Xue, H. Li, L. Xie, T. Guo, R. Zhang, and C. Gong, “Visinger 2: High-fidelity end-to-end singing voice synthesis enhanced by digital signal processing synthesizer,” arXiv preprint arXiv:2211.02903, 2022
-
[2]
Diffsvc: A diffusion probabilistic model for singing voice conversion,
S. Liu, Y. Cao, D. Su, and H. Meng, “Diffsvc: A diffusion probabilistic model for singing voice conversion,” in 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2021, pp. 741–748
2021
-
[3]
L. P. Violeta, X. Zhang, J. Shi, Y. Yasuda, W.-C. Huang, Z. Wu, and T. Toda, “The singing voice conversion challenge 2025: From singer identity conversion to singing style conversion,” arXiv preprint arXiv:2509.15629, 2025
-
[4]
Z. Wang, X. Xia, C. Huang, and L. Xie, “S ˆ2 voice: Style-aware autoregressive modeling with enhanced conditioning for singing style conversion,” arXiv preprint arXiv:2601.13629, 2026
-
[5]
Stylesinger: Style transfer for out-of- domain singing voice synthesis,
Y. Zhang, R. Huang, R. Li, J. He, Y. Xia, F. Chen, X. Duan, B. Huai, and Z. Zhao, “Stylesinger: Style transfer for out-of- domain singing voice synthesis,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 17, 2024, pp. 19 597–19 605
2024
-
[6]
Singgan: Generative adversarial network for high- fidelity singing voice generation,
R. Huang, C. Cui, F. Chen, Y. Ren, J. Liu, Z. Zhao, B. Huai, and Z. Wang, “Singgan: Generative adversarial network for high- fidelity singing voice generation,” in Proceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 2525– 2535
2022
-
[7]
Audiobox: Unified audio generation with natural language prompts
A. Vyas, B. Shi, M. Le, A. Tjandra, Y.-C. Wu, B. Guo, J. Zhang, X. Zhang, R. Adkins, W. Ngan et al., “Audiobox: Unified audio generation with natural language prompts,” arXiv preprint arXiv:2312.15821, 2023
-
[8]
Gtsinger: A global multi-technique singing corpus with realistic music scores for all singing tasks,
Y. Zhang, C. Pan, W. Guo, R. Li, Z. Zhu, J. Wang, W. Xu, J. Lu, Z. Hong, C. Wang et al., “Gtsinger: A global multi-technique singing corpus with realistic music scores for all singing tasks,” Advances in Neural Information Processing Systems, vol. 37, pp. 1117–1140, 2024
2024
-
[9]
Tcsinger: Zero-shot singing voice synthesis with style transfer and multi-level style control,
Y. Zhang, Z. Jiang, R. Li, C. Pan, J. He, R. Huang, C. Wang, and Z. Zhao, “Tcsinger: Zero-shot singing voice synthesis with style transfer and multi-level style control,” arXiv preprint arXiv:2409.15977, 2024
-
[10]
D. Zhang, Y. Sun, P. Li, Y. Liu, H. Lin, H. Xu, X. Mu, L. Lin, W. Yan, N. Yang et al., “Pointcot: A multi-modal benchmark for explicit 3d geometric reasoning,” arXiv preprint arXiv:2602.23945, 2026
-
[11]
Not all queries need deep thought: Coficot for adaptive coarse-to-fine stateful refinement,
D. Zhang, H. Lin, Y. Sun, P. Wang, Q. Wang, N. Yang, and J. Zhu, “Not all queries need deep thought: Coficot for adaptive coarse-to-fine stateful refinement,” arXiv preprint arXiv:2603.08251, 2026
-
[12]
Cmhanet: A cross-modal hybrid attention network for point cloud registration,
D. Zhang, Y. Wang, Y. Sun, H. Xu, P. Fan, and J. Zhu, “Cmhanet: A cross-modal hybrid attention network for point cloud registration,” Neurocomputing, p. 133318, 2026
2026
-
[13]
Igasa: Integrated geometry-aware and skip-attention modules for enhanced point cloud registration,
D. Zhang, J. Zhu, S. Li, W. Yan, H. Xu, P. Fan, and H. Lu, “Igasa: Integrated geometry-aware and skip-attention modules for enhanced point cloud registration,” IEEE Transactions on Circuits and Systems for Video Technology, 2026
2026
-
[14]
Hubert: Self-supervised speech rep- resentation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y.-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “Hubert: Self-supervised speech rep- resentation learning by masked prediction of hidden units,” IEEE/ACM transactions on audio, speech, and language pro- cessing, vol. 29, pp. 3451–3460, 2021
2021
-
[15]
Contentvec: An im- proved self-supervised speech representation by disentangling speakers,
K. Qian, Y. Zhang, H. Gao, J. Ni, C.-I. Lai, D. Cox, M. Hasegawa-Johnson, and S. Chang, “Contentvec: An im- proved self-supervised speech representation by disentangling speakers,” in International conference on machine learning. PMLR, 2022, pp. 18 003–18 017
2022
-
[16]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
C. Wang, S. Chen, Y. Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y. Liu, H. Wang, J. Li et al., “Neural codec language mod- els are zero-shot text to speech synthesizers,” arXiv preprint arXiv:2301.02111, 2023
work page internal anchor Pith review arXiv 2023
-
[17]
Zero-shot voice conversion via self- supervised prosody representation learning,
S. Wang and D. Borth, “Zero-shot voice conversion via self- supervised prosody representation learning,” in 2022 Interna- tional Joint Conference on Neural Networks (IJCNN). IEEE, 2022, pp. 01–08
2022
-
[18]
Lm-vc: Zero- shot voice conversion via speech generation based on language models,
Z. Wang, Y. Chen, L. Xie, Q. Tian, and Y. Wang, “Lm-vc: Zero- shot voice conversion via speech generation based on language models,” IEEE Signal Processing Letters, vol. 30, pp. 1157– 1161, 2023
2023
-
[19]
X. Zhang, X. Zhang, K. Peng, Z. Tang, V. Manohar, Y. Liu, J. Hwang, D. Li, Y. Wang, J. Chan et al., “Vevo: Controllable zero-shot voice imitation with self-supervised disentanglement,” arXiv preprint arXiv:2502.07243, 2025
-
[20]
arXiv preprint arXiv:2403.03100 , year=
Z. Ju, Y. Wang, K. Shen, X. Tan, D. Xin, D. Yang, Y. Liu, Y. Leng, K. Song, S. Tang et al., “Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,” arXiv preprint arXiv:2403.03100, 2024
-
[21]
Matcha-tts: A fast tts architecture with conditional flow matching,
S. Mehta, R. Tu, J. Beskow, É. Székely, and G. E. Henter, “Matcha-tts: A fast tts architecture with conditional flow matching,” in ICASSP 2024-2024 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 11 341–11 345
2024
-
[22]
Serenade: A singing style conversion framework based on audio infilling,
L. P. Violeta, W.-C. Huang, and T. Toda, “Serenade: A singing style conversion framework based on audio infilling,” arXiv preprint arXiv:2503.12388, 2025
-
[23]
Ascot: An adaptive self-correction chain-of-thought method for late-stage fragility in llms,
D. Zhang, N. Yang, J. Zhu, J. Yang, M. Xin, and B. Tian, “Ascot: An adaptive self-correction chain-of-thought method for late-stage fragility in llms,” arXiv preprint arXiv:2508.05282, 2025
-
[24]
D. Zhang, Y. Sun, C. Tan, W. Yan, N. Yang, J. Zhu, and H. Zhang, “Chain-of-thought compression should not be blind: V-skip for efficient multimodal reasoning via dual-path anchor- ing,” arXiv preprint arXiv:2601.13879, 2026
-
[25]
Soundstream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,” IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 30, pp. 495–507, 2021
2021
-
[26]
P. Anastassiou, J. Chen, J. Chen, Y. Chen, Z. Chen, Z. Chen, J. Cong, L. Deng, C. Ding, L. Gao et al., “Seed-tts: A family of high-quality versatile speech generation models,” arXiv preprint arXiv:2406.02430, 2024
-
[27]
Maskgct: Zero-shot text-to-speech with masked generative codec transformer
Y. Wang, H. Zhan, L. Liu, R. Zeng, H. Guo, J. Zheng, Q. Zhang, X. Zhang, S. Zhang, and Z. Wu, “Maskgct: Zero-shot text- to-speech with masked generative codec transformer,” arXiv preprint arXiv:2409.00750, 2024
-
[28]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Du, Y. Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y. Yang, C. Gao, H. Wang et al., “Cosyvoice 2: Scalable streaming speech synthesis with large language models,” arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review arXiv 2024
-
[29]
Towards controllable speech synthesis in the era of large language models: A systematic survey,
T. Xie, Y. Rong, P. Zhang, W. Wang, and L. Liu, “Towards controllable speech synthesis in the era of large language models: A systematic survey,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 764–791
2025
-
[30]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar et al., “Llama: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Vevo2: Bridging controllable speech and singing voice generation via unified prosody learning,
X. Zhang, J. Zhang, Y. Wang, C. Wang, Y. Chen, D. Jia, Z. Chen, and Z. Wu, “Vevo2: Bridging controllable speech and singing voice generation via unified prosody learning,” arXiv e-prints, pp. arXiv–2508, 2025
2025
-
[32]
The singing voice conversion challenge 2023,
W.-C. Huang, L. P. Violeta, S. Liu, J. Shi, and T. Toda, “The singing voice conversion challenge 2023,” in 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2023, pp. 1–8
2023
-
[33]
Syki-svc: Advancing singing voice conversion with post- processing innovations and an open-source professional testset,
Y. Zhou, W. Wang, H. Ding, J. Xu, J. Zhu, X. Gao, and S. Li, “Syki-svc: Advancing singing voice conversion with post- processing innovations and an open-source professional testset,” in ICASSP 2025-2025 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[34]
Vits-based singing voice conversion system with dspgan post-processing for svcc2023,
Y. Zhou, M. Chen, Y. Lei, J. Zhu, and W. Zhao, “Vits-based singing voice conversion system with dspgan post-processing for svcc2023,” in 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2023, pp. 1–8
2023
-
[35]
Dspgan: A gan-based universal vocoder for high-fidelity tts by time-frequency domain supervision from dsp,
K. Song, Y. Zhang, Y. Lei, J. Cong, H. Li, L. Xie, G. He, and J. Bai, “Dspgan: A gan-based universal vocoder for high-fidelity tts by time-frequency domain supervision from dsp,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[36]
Rmvpe: A robust model for vocal pitch estimation in polyphonic music,
H. Wei, X. Cao, T. Dan, and Y. Chen, “Rmvpe: A robust model for vocal pitch estimation in polyphonic music,” arXiv preprint arXiv:2306.15412, 2023
-
[37]
Singing voice synthesis with vibrato modeling and latent energy representation,
Y. Song, W. Song, W. Zhang, Z. Zhang, D. Zeng, Z. Liu, and Y. Yu, “Singing voice synthesis with vibrato modeling and latent energy representation,” in 2022 IEEE 24th International Workshop on Multimedia Signal Processing (MMSP). IEEE, 2022, pp. 1–6
2022
-
[38]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” in International conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[39]
Wenet 2.0: More productive end-to- end speech recognition toolkit,
B. Zhang, D. Wu, Z. Peng, X. Song, Z. Yao, H. Lv, L. Xie, C. Yang, F. Pan, and J. Niu, “Wenet 2.0: More produc- tive end-to-end speech recognition toolkit,” arXiv preprint arXiv:2203.15455, 2022
-
[40]
Montreal forced aligner: Trainable text-speech align- ment using kaldi
M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Son- deregger, “Montreal forced aligner: Trainable text-speech align- ment using kaldi. ” in Interspeech, vol. 2017, 2017, pp. 498–502
2017
-
[41]
Vibrato learning in multi-singer singing voice synthesis,
R. Liu, X. Wen, C. Lu, L. Song, and J. S. Sung, “Vibrato learning in multi-singer singing voice synthesis,” in 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2021, pp. 773–779
2021
-
[42]
Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,” Ad- vances in neural information processing systems, vol. 33, pp. 17 022–17 033, 2020
2020
-
[43]
arXiv preprint arXiv:2303.00332 , year=
H. Wang, S. Zheng, Y. Chen, L. Cheng, and Q. Chen, “Cam++: A fast and efficient network for speaker verification using context-aware masking,” arXiv preprint arXiv:2303.00332, 2023
-
[44]
Singmos-pro: An comprehensive benchmark for singing quality assessment
Y. Tang, L. Liu, W. Feng, Y. Zhao, J. Han, Y. Yu, J. Shi, and Q. Jin, “Singmos-pro: An comprehensive benchmark for singing quality assessment,” arXiv preprint arXiv:2510.01812, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.