Recognition: 2 theorem links
· Lean TheoremExperience Transfer for Multimodal LLM Agents in Minecraft Game
Pith reviewed 2026-05-10 18:25 UTC · model grok-4.3
The pith
Echo enables multimodal LLM agents to transfer experience across Minecraft tasks by decomposing knowledge into five dimensions, yielding 1.3x to 1.7x faster object unlocking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
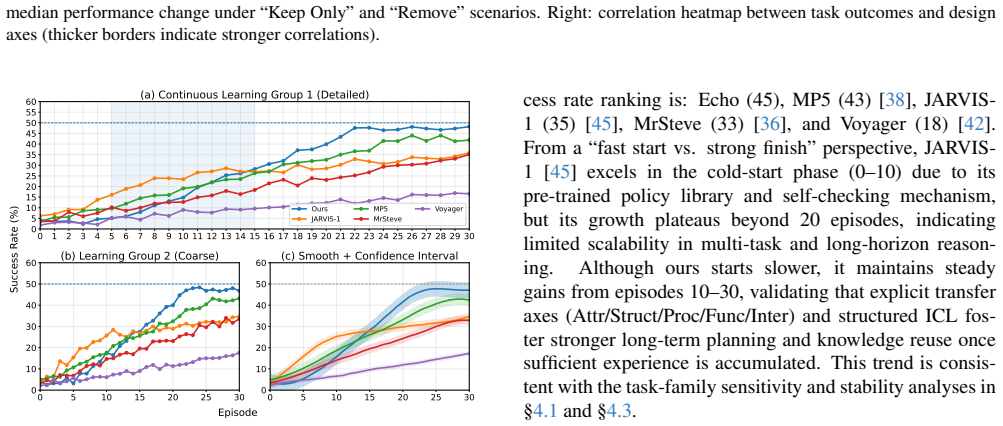
Echo is a transfer-oriented memory framework that decomposes reusable knowledge into five dimensions: structure, attribute, process, function, and interaction. This allows the agent to identify recurring patterns shared across different tasks and infer what prior experience remains applicable in new situations. Building on this formulation, Echo leverages In-Context Analogy Learning to retrieve relevant experiences and adapt them to unseen tasks through contextual examples. In Minecraft experiments under a from-scratch learning setting, Echo achieves a 1.3x to 1.7x speed-up on object-unlocking tasks and exhibits a burst-like chain-unlocking phenomenon, rapidly unlocking multiple similar item
What carries the argument
The Echo framework, which decomposes reusable knowledge into five dimensions to enable In-Context Analogy Learning that retrieves and adapts prior experiences to new tasks.
Load-bearing premise
Reusable knowledge from past interactions can be reliably broken down into the five dimensions and that in-context analogy learning will correctly identify and adapt the relevant parts to new tasks without errors.
What would settle it
Running the Minecraft object-unlocking experiments with Echo but removing the five-dimension decomposition and In-Context Analogy Learning, then checking whether the speed-up and chain-unlocking effects disappear.
Figures








read the original abstract
Multimodal LLM agents operating in complex game environments must continually reuse past experience to solve new tasks efficiently. In this work, we propose Echo, a transfer-oriented memory framework that enables agents to derive actionable knowledge from prior interactions rather than treating memory as a passive repository of static records. To make transfer explicit, Echo decomposes reusable knowledge into five dimensions: structure, attribute, process, function, and interaction. This formulation allows the agent to identify recurring patterns shared across different tasks and infer what prior experience remains applicable in new situations. Building on this formulation, Echo leverages In-Context Analogy Learning (ICAL) to retrieve relevant experiences and adapt them to unseen tasks through contextual examples. Experiments in Minecraft show that, under a from-scratch learning setting, Echo achieves a 1.3x to 1.7x speed-up on object-unlocking tasks. Moreover, Echo exhibits a burst-like chain-unlocking phenomenon, rapidly unlocking multiple similar items within a short time interval after acquiring transferable experience. These results suggest that experience transfer is a promising direction for improving the efficiency and adaptability of multimodal LLM agents in complex interactive environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Echo, a transfer-oriented memory framework for multimodal LLM agents in Minecraft. It decomposes reusable knowledge from prior interactions into five explicit dimensions (structure, attribute, process, function, interaction) and applies In-Context Analogy Learning (ICAL) to retrieve and adapt relevant experiences to new tasks. The central empirical claims are a 1.3x–1.7x speedup on object-unlocking tasks under from-scratch learning and the emergence of a burst-like chain-unlocking phenomenon after acquiring transferable experience.
Significance. If the reported speedups and chain-unlocking behavior are shown to be robust and specifically attributable to the proposed decomposition and ICAL mechanism, the work would advance memory design for LLM agents by replacing passive record-keeping with structured, analogy-driven transfer. The five-dimensional formulation offers an interpretable alternative to opaque memory modules and could inform efficiency improvements in partially observable environments. The paper's explicit focus on reusable units rather than end-to-end fine-tuning is a constructive step.
major comments (2)
- [Abstract] Abstract: The claims of 1.3x–1.7x speedup and burst-like chain-unlocking are presented without any information on trial counts, baseline agents, statistical tests, variance across runs, or controls for task ordering and exploration. This omission is load-bearing because the central contribution is the empirical demonstration that the five-dimensional decomposition plus ICAL produces measurable transfer gains rather than baseline exploration effects.
- [Framework and Experiments] Framework and Experiments sections: The manuscript assumes the five-dimensional decomposition (structure, attribute, process, function, interaction) yields reliably reusable units that ICAL can map without substantial errors or hallucinations, yet provides no quantitative error rates, failure-case analysis, or ablation that removes the decomposition step. In a high-dimensional POMDP such as Minecraft, even modest adaptation mistakes would compound; without these diagnostics the attribution of the observed efficiency gains to experience transfer remains unverified.
minor comments (1)
- [Abstract] Abstract: The term 'from-scratch learning setting' is used without a concise definition or pointer to the precise experimental protocol (e.g., whether the agent begins with an empty memory or with generic pre-training).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The comments highlight important areas for strengthening the empirical presentation and validation of the framework. We address each point below and will incorporate the suggested changes in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of 1.3x–1.7x speedup and burst-like chain-unlocking are presented without any information on trial counts, baseline agents, statistical tests, variance across runs, or controls for task ordering and exploration. This omission is load-bearing because the central contribution is the empirical demonstration that the five-dimensional decomposition plus ICAL produces measurable transfer gains rather than baseline exploration effects.
Authors: We agree that the abstract should include more details on the experimental protocol to make the claims self-contained. The full Experiments section already specifies the evaluation protocol (multiple independent runs, baseline agents without Echo, and controls for task ordering), but these were not summarized in the abstract. In the revision we will add a concise statement noting that results are averaged over 5 runs per condition, include variance measures, reference the baseline comparisons, and note that the speedups are statistically significant relative to from-scratch exploration controls. This will clarify that the reported gains are attributable to the transfer mechanism rather than generic exploration. revision: yes
-
Referee: [Framework and Experiments] Framework and Experiments sections: The manuscript assumes the five-dimensional decomposition (structure, attribute, process, function, interaction) yields reliably reusable units that ICAL can map without substantial errors or hallucinations, yet provides no quantitative error rates, failure-case analysis, or ablation that removes the decomposition step. In a high-dimensional POMDP such as Minecraft, even modest adaptation mistakes would compound; without these diagnostics the attribution of the observed efficiency gains to experience transfer remains unverified.
Authors: We acknowledge that the current manuscript does not provide quantitative error rates for the decomposition step or an explicit ablation that isolates the five-dimensional structure from the rest of the ICAL pipeline. While the overall performance improvements and the emergence of chain-unlocking behavior are consistent with successful transfer, we agree that direct diagnostics are needed to rule out compounding adaptation errors. In the revised version we will add (1) a failure-case analysis with representative examples of decomposition and analogy-mapping errors together with their observed frequency, and (2) an ablation comparing full Echo against a control variant that uses unstructured memory retrieval without the five-dimensional decomposition. These additions will strengthen the causal link between the proposed decomposition and the measured efficiency gains. revision: yes
Circularity Check
No circularity: purely empirical proposal with no derivations or self-referential fits
full rationale
The paper introduces Echo as an empirical memory framework for LLM agents in Minecraft. It defines a five-dimensional decomposition (structure, attribute, process, function, interaction) and ICAL as design choices, then reports experimental speed-ups (1.3x-1.7x) and burst-unlocking behavior. No equations, no fitted parameters renamed as predictions, no self-citations invoked as load-bearing uniqueness theorems, and no ansatzes or renamings of known results. All claims rest on external Minecraft experiments that are independently falsifiable. The derivation chain is therefore self-contained with no reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can perform effective in-context analogy learning from retrieved examples to adapt prior experiences
invented entities (1)
-
Echo framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearEcho decomposes reusable knowledge into five dimensions: structure, attribute, process, function, and interaction... leverages In-Context Analogy Learning (ICAL) to retrieve relevant experiences and adapt them to unseen tasks
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearfive explicit transfer dimensions—Structural, Attribute, Procedural, Functional, and Interaction
Forward citations
Cited by 3 Pith papers
-
Weak-Link Optimization for Multi-Agent Reasoning and Collaboration
WORC improves multi-agent LLM reasoning to 82.2% average accuracy by predicting and compensating for the weakest agent via targeted extra sampling rather than uniform reinforcement.
-
From Similarity to Structure: Training-free LLM Context Compression with Hybrid Graph Priors
A hybrid graph-based training-free framework for LLM context compression matches strong baselines and shows larger gains on long-document benchmarks.
-
CAP-CoT: Cycle Adversarial Prompt for Improving Chain of Thoughts in LLM Reasoning
CAP-CoT uses iterative adversarial prompt cycles to improve CoT accuracy, stability, and robustness across six benchmarks and four LLM backbones.
Reference graph
Works this paper leans on
-
[1]
Compositional foun- dation models for hierarchical planning.Conference on Neu- ral Information Processing Systems (NeurIPS), 36:22304– 22325, 2023
Anurag Ajay, Seungwook Han, Yilun Du, Shuang Li, Abhi Gupta, Tommi Jaakkola, Josh Tenenbaum, Leslie Kaelbling, Akash Srivastava, and Pulkit Agrawal. Compositional foun- dation models for hierarchical planning.Conference on Neu- ral Information Processing Systems (NeurIPS), 36:22304– 22325, 2023. 2
2023
-
[2]
Flamingo: a visual language model for few-shot learning.Conference on Neural Information Processing Systems (NeurIPS), 35: 23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Men- sch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Conference on Neural Information Processing Systems (NeurIPS), 35: 23716–23736, 2022. 3
2022
-
[3]
Self-rag: Learning to retrieve, generate, and critique through self-reflection.International Confer- ence on Learning Representations (ICLR), 2024
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Han- naneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection.International Confer- ence on Learning Representations (ICLR), 2024. 3
2024
-
[4]
Video pretraining (vpt): Learning to act by watching unlabeled online videos.Conference on Neu- ral Information Processing Systems (NeurIPS), 35:24639– 24654, 2022
Bowen Baker, Ilge Akkaya, Peter Zhokov, Joost Huizinga, Jie Tang, Adrien Ecoffet, Brandon Houghton, Raul Sampe- dro, and Jeff Clune. Video pretraining (vpt): Learning to act by watching unlabeled online videos.Conference on Neu- ral Information Processing Systems (NeurIPS), 35:24639– 24654, 2022. 3
2022
-
[5]
Lan- guage models are few-shot learners.Conference on Neural Information Processing Systems (NeurIPS), 33:1877–1901,
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Lan- guage models are few-shot learners.Conference on Neural Information Processing Systems (NeurIPS), 33:1877–1901,
1901
-
[6]
Open-world multi-task control through goal-aware representation learning and adaptive horizon prediction
Shaofei Cai, Zihao Wang, Xiaojian Ma, Anji Liu, and Yitao Liang. Open-world multi-task control through goal-aware representation learning and adaptive horizon prediction. In Conference on Computer Vision and Pattern Recognition (CVPR), pages 13734–13744, 2023. 3
2023
-
[7]
Groot: Learning to follow instructions by watching gameplay videos
Shaofei Cai, Bowei Zhang, Zihao Wang, Xiaojian Ma, Anji Liu, and Yitao Liang. Groot: Learning to follow instructions by watching gameplay videos. InThe Twelfth International Conference on Learning Representations, 2023. 2, 3
2023
-
[8]
Groot-2: Weakly su- pervised multi-modal instruction following agents
Shaofei Cai, Bowei Zhang, Zihao Wang, Haowei Lin, Xiao- jian Ma, Anji Liu, and Yitao Liang. Groot-2: Weakly su- pervised multi-modal instruction following agents. InThe Thirteenth International Conference on Learning Represen- tations, 2024. 3
2024
-
[9]
Causalmace: Causality empowered multi-agents in minecraft cooperative tasks
Qi Chai, Zhang Zheng, Junlong Ren, Deheng Ye, Zichuan Lin, and Hao Wang. Causalmace: Causality empowered multi-agents in minecraft cooperative tasks. InConfer- ence on Empirical Methods in Natural Language Processing (EMNLP), pages 14410–14426, 2025. 3
2025
-
[10]
Dense x retrieval: What retrieval granularity should we use? InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 15159–15177, 2024
Tong Chen, Hongwei Wang, Sihao Chen, Wenhao Yu, Kaixin Ma, Xinran Zhao, Hongming Zhang, and Dong Yu. Dense x retrieval: What retrieval granularity should we use? InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 15159–15177, 2024. 3
2024
-
[11]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, et al. A survey on in-context learning. InConfer- ence on Empirical Methods in Natural Language Processing (EMNLP), pages 1107–1128, 2024. 3
2024
-
[12]
Villageragent: A graph-based multi-agent framework for coordinating complex task dependencies in minecraft
Yubo Dong, Xukun Zhu, Zhengzhe Pan, Linchao Zhu, and Yi Yang. Villageragent: A graph-based multi-agent framework for coordinating complex task dependencies in minecraft. InAnnual Meeting of the Association for Compu- tational Linguistics (ACL), pages 16290–16314, 2024. 3
2024
-
[13]
Palm-e: an embodied multimodal language model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: an embodied multimodal language model. InICML (Interna- tional Conference on Machine Learning), pages 8469–8488,
-
[14]
Minedojo: Build- ing open-ended embodied agents with internet-scale knowl- edge.Conference on Neural Information Processing Systems (NeurIPS), 35:18343–18362, 2022
Linxi Fan, Guanzhi Wang, Yunfan Jiang, Ajay Mandlekar, Yuncong Yang, Haoyi Zhu, Andrew Tang, De-An Huang, Yuke Zhu, and Anima Anandkumar. Minedojo: Build- ing open-ended embodied agents with internet-scale knowl- edge.Conference on Neural Information Processing Systems (NeurIPS), 35:18343–18362, 2022. 3
2022
-
[15]
Llama-rider: Spurring large language models to explore the open world
Yicheng Feng, Yuxuan Wang, Jiazheng Liu, Sipeng Zheng, and Zongqing Lu. Llama-rider: Spurring large language models to explore the open world. InConference of the North American Chapter of the Association for Computational Lin- guistics (NAACL), pages 4705–4724, 2024. 3
2024
-
[16]
Vistawise: Building cost-effective agent with cross-modal knowledge graph for minecraft
Honghao Fu, Junlong Ren, Qi Chai, Deheng Ye, Yujun Cai, and Hao Wang. Vistawise: Building cost-effective agent with cross-modal knowledge graph for minecraft. InEMNLP (Conference on Empirical Methods in Natural Language Processing), 2025. 2, 3
2025
-
[17]
Minerl: a large-scale dataset of minecraft demonstrations
William H Guss, Brandon Houghton, Nicholay Topin, Phillip Wang, Cayden Codel, Manuela Veloso, and Ruslan Salakhutdinov. Minerl: a large-scale dataset of minecraft demonstrations. InInternational Joint Conference on Artifi- cial Intelligence (IJCAI), pages 2442–2448, 2019. 3
2019
-
[18]
Instruction induction: From few examples to natural language task descriptions
Or Honovich, Uri Shaham, Samuel Bowman, and Omer Levy. Instruction induction: From few examples to natural language task descriptions. InAnnual Meeting of the Asso- ciation for Computational Linguistics (ACL), pages 1935– 1952, 2023. 3
1935
-
[19]
In-context analogical reasoning with pre-trained lan- guage models
Xiaoyang Hu, Shane Storks, Richard L Lewis, and Joyce Chai. In-context analogical reasoning with pre-trained lan- guage models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023. 2, 3
2023
-
[20]
A survey on hal- lucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Infor- mation Systems (TIS), 43(2):1–55, 2025
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hal- lucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Infor- mation Systems (TIS), 43(2):1–55, 2025. 3
2025
-
[21]
Atlas: Few-shot learning with retrieval augmented language mod- els.Journal of Machine Learning Research (JMLR), 24 (251):1–43, 2023
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hos- seini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Ar- mand Joulin, Sebastian Riedel, and Edouard Grave. Atlas: Few-shot learning with retrieval augmented language mod- els.Journal of Machine Learning Research (JMLR), 24 (251):1–43, 2023. 3
2023
-
[22]
Hyuhng Joon Kim, Hyunsoo Cho, Junyeob Kim, Taeuk Kim, Kang Min Yoo, and Sang-goo Lee. Self-generated in-context 9 learning: Leveraging auto-regressive language models as a demonstration generator.arXiv preprint arXiv:2206.08082,
-
[23]
Jonathan Leung, Yongjie Wang, and Zhiqi Shen. Knowledge retrieval in llm gaming: A shift from entity-centric to goal- oriented graphs.arXiv preprint arXiv:2505.18607, 2025. 2
-
[24]
Auto mc-reward: Automated dense reward design with large language models for minecraft
Hao Li, Xue Yang, Zhaokai Wang, Xizhou Zhu, Jie Zhou, Yu Qiao, Xiaogang Wang, Hongsheng Li, Lewei Lu, and Jifeng Dai. Auto mc-reward: Automated dense reward design with large language models for minecraft. InConference on Com- puter Vision and Pattern Recognition (CVPR), pages 16426– 16435, 2024. 3
2024
-
[25]
Optimus-1: Hybrid mul- timodal memory empowered agents excel in long-horizon tasks.Conference on Neural Information Processing Sys- tems (NeurIPS), 37:49881–49913, 2024
Zaijing Li, Yuquan Xie, Rui Shao, Gongwei Chen, Dong- mei Jiang, and Liqiang Nie. Optimus-1: Hybrid mul- timodal memory empowered agents excel in long-horizon tasks.Conference on Neural Information Processing Sys- tems (NeurIPS), 37:49881–49913, 2024. 2, 3
2024
-
[26]
Optimus-2: Multimodal minecraft agent with goal-observation-action conditioned policy
Zaijing Li, Yuquan Xie, Rui Shao, Gongwei Chen, Dongmei Jiang, and Liqiang Nie. Optimus-2: Multimodal minecraft agent with goal-observation-action conditioned policy. In Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 3
2025
-
[27]
What makes good in- context examples for gpt-3? InDeep Learning Inside Out Workshop (DeeLIO), pages 100–114, 2022
Jiachang Liu, Dinghan Shen, Yizhe Zhang, William B Dolan, Lawrence Carin, and Weizhu Chen. What makes good in- context examples for gpt-3? InDeep Learning Inside Out Workshop (DeeLIO), pages 100–114, 2022. 3
2022
-
[28]
In- context vectors: Making in context learning more effective and controllable through latent space steering
Sheng Liu, Haotian Ye, Lei Xing, and James Y Zou. In- context vectors: Making in context learning more effective and controllable through latent space steering. InInter- national Conference on Machine Learning (ICML), pages 32287–32307, 2024. 3
2024
-
[29]
Rl-gpt: Integrat- ing reinforcement learning and code-as-policy.Conference on Neural Information Processing Systems (NeurIPS), 37: 28430–28459, 2024
Shaoteng Liu, Haoqi Yuan, Minda Hu, Yanwei Li, Yukang Chen, Shu Liu, Zongqing Lu, and Jiaya Jia. Rl-gpt: Integrat- ing reinforcement learning and code-as-policy.Conference on Neural Information Processing Systems (NeurIPS), 37: 28430–28459, 2024. 3
2024
-
[30]
Odyssey: Empowering minecraft agents with open- world skills
Shunyu Liu, Yaoru Li, Kongcheng Zhang, Zhenyu Cui, Wenkai Fang, Yuxuan Zheng, Tongya Zheng, and Mingli Song. Odyssey: Empowering minecraft agents with open- world skills. InProceedings of the Thirty-Fourth Interna- tional Joint Conference on Artificial Intelligence, 2025. 3
2025
-
[31]
Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitiv- ity
Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitiv- ity. InAnnual Meeting of the Association for Computational Linguistics (ACL), pages 8086–8098, 2022. 3
2022
-
[32]
Gate: Graph-based adaptive tool evolution across diverse tasks.arXiv preprint arXiv:2502.14848, 2025
Jianwen Luo, Yiming Huang, Jinxiang Meng, Fangyu Lei, Shizhu He, Xiao Liu, Shanshan Jiang, Bin Dong, Jun Zhao, and Kang Liu. Gate: Graph-based adaptive tool evolution across diverse tasks.arXiv preprint arXiv:2502.14848, 2025. 2
-
[33]
Query rewriting in retrieval-augmented large language models
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. Query rewriting in retrieval-augmented large language models. InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 5303–5315, 2023. 3
2023
-
[34]
Nicola Messina, Giuseppe Amato, Andrea Esuli, Fabrizio Falchi, Claudio Gennaro, and St ´ephane Marchand-Maillet. Fine-grained visual textual alignment for cross-modal re- trieval using transformer encoders.ACM Transactions on Multimedia Computing, Communications, and Applications (ACM TOMM), 17(4):1–23, 2021. 2
2021
-
[35]
Embodied large language models en- able robots to complete complex tasks in unpredictable envi- ronments.Nature Machine Intelligence, 2025
Ruaridh Mon-Williams, Gen Li, Ran Long, Wenqian Du, and Christopher G Lucas. Embodied large language models en- able robots to complete complex tasks in unpredictable envi- ronments.Nature Machine Intelligence, 2025. 8
2025
-
[36]
Mrsteve: Instruction-following agents in minecraft with what-where- when memory
Junyeong Park, Junmo Cho, and Sungjin Ahn. Mrsteve: Instruction-following agents in minecraft with what-where- when memory. InInternational Conference on Learning Representations (ICLR), 2025. Poster. 2, 3, 4, 6, 7
2025
-
[37]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InUIST (ACM Symposium on User Interface Software and Technology), 2023. 2
2023
-
[38]
Mp5: A multi-modal open-ended embodied system in minecraft via active perception
Yiran Qin, Enshen Zhou, Qichang Liu, Zhenfei Yin, Lu Sheng, Ruimao Zhang, Yu Qiao, and Jing Shao. Mp5: A multi-modal open-ended embodied system in minecraft via active perception. InConference on Computer Vision and Pattern Recognition (CVPR), 2024. 2, 3, 6, 7, 8
2024
-
[39]
Learn- ing to retrieve prompts for in-context learning
Ohad Rubin, Jonathan Herzig, and Jonathan Berant. Learn- ing to retrieve prompts for in-context learning. InNAACL (Conference of the North American Chapter of the Asso- ciation for Computational Linguistics), pages 2655–2671,
-
[40]
Re- gal: Refactoring programs to discover generalizable abstrac- tions
Elias Stengel-Eskin, Archiki Prasad, and Mohit Bansal. Re- gal: Refactoring programs to discover generalizable abstrac- tions. InInternational Conference on Machine Learning (ICML), pages 46605–46624. PMLR, 2024. 3
2024
-
[41]
Craft an iron sword: Dynamically generating interactive game char- acters by prompting large language models tuned on code
Ryan V olum, Sudha Rao, Michael Xu, Gabriel Des- Garennes, Chris Brockett, Benjamin Van Durme, Olivia Deng, Akanksha Malhotra, and William B Dolan. Craft an iron sword: Dynamically generating interactive game char- acters by prompting large language models tuned on code. InWordplay 2022 workshop, 2022
2022
-
[42]
V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Re- search, 2024
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandku- mar. V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Re- search, 2024. 2, 3, 5, 6, 7, 8
2024
-
[43]
Xinyi Wang, Wanrong Zhu, Michael Saxon, Mark Steyvers, and William Yang Wang. Large language models are latent variable models: Explaining and finding good demonstra- tions for in-context learning.Conference on Neural Informa- tion Processing Systems (NeurIPS), 36:15614–15638, 2023. 3
2023
-
[44]
Describe, explain, plan and se- lect: interactive planning with large language models enables open-world multi-task agents
Zihao Wang, Shaofei Cai, Guanzhou Chen, Anji Liu, Xi- aojian Ma, and Yitao Liang. Describe, explain, plan and se- lect: interactive planning with large language models enables open-world multi-task agents. InConference on Neural In- formation Processing Systems (NeurIPS), 2023. 1, 2
2023
-
[45]
Jarvis-1: Open-world multi-task agents with memory- 10 augmented multimodal language models.IEEE Transac- tions on Pattern Analysis and Machine Intelligence (IEEE TPAMI), 2024
Zihao Wang, Shaofei Cai, Anji Liu, Yonggang Jin, Jin- bing Hou, Bowei Zhang, Haowei Lin, Zhaofeng He, Zi- long Zheng, Yaodong Yang, Xiaojian Ma, and Yitao Liang. Jarvis-1: Open-world multi-task agents with memory- 10 augmented multimodal language models.IEEE Transac- tions on Pattern Analysis and Machine Intelligence (IEEE TPAMI), 2024. 1, 2, 3, 5, 6, 7, 8
2024
-
[46]
Zihao Wang, Shaofei Cai, Zhancun Mu, Haowei Lin, Ceyao Zhang, Xuejie Liu, Qing Li, Anji Liu, Xiaojian Shawn Ma, and Yitao Liang. Omnijarvis: Unified vision-language- action tokenization enables open-world instruction following agents.Conference on Neural Information Processing Sys- tems (NeurIPS), 37:73278–73308, 2024. 3
2024
-
[47]
Not all demonstration examples are equally beneficial: Reweighting demonstration examples for in-context learning
Zhe Yang, Damai Dai, Peiyi Wang, and Zhifang Sui. Not all demonstration examples are equally beneficial: Reweighting demonstration examples for in-context learning. InConfer- ence on Empirical Methods in Natural Language Processing (EMNLP), pages 13209–13221, 2023. 3
2023
-
[48]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2022. 2, 3
2022
-
[49]
Coca: Contrastive captioners are image-text foundation models.Transactions on Machine Learning Research, 2022
Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mo- jtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models.Transactions on Machine Learning Research, 2022. 3
2022
-
[50]
ADAM: An embodied causal agent in open-world environments
Shu Yu and Chaochao Lu. ADAM: An embodied causal agent in open-world environments. InInternational Confer- ence on Learning Representations (ICLR), 2025. 3
2025
-
[51]
Text summarization via global structure aware- ness
Jiaquan Zhang, Chaoning Zhang, Shuxu Chen, Yibei Liu, Chenghao Li, Qigan Sun, Shuai Yuan, Fachrina Dewi Pus- pitasari, Dongshen Han, Guoqing Wang, Sung-Ho Bae, and Yang Yang. Text summarization via global structure aware- ness. InInternational Conference on Learning Representa- tions (ICLR), 2026. Poster. 2
2026
-
[52]
Learning global hypothesis space for enhancing syn- ergistic reasoning chain
Jiaquan Zhang, Chaoning Zhang, Shuxu Chen, Xudong Wang, Zhenzhen Huang, Pengcheng Zheng, Shuai Yuan, Sheng Zheng, Qigan Sun, Jie Zou, Lik-Hang Lee, and Yang Yang. Learning global hypothesis space for enhancing syn- ergistic reasoning chain. InInternational Conference on Learning Representations (ICLR), 2026. Poster
2026
-
[53]
Toward energy-efficient spike-based deep reinforce- ment learning with temporal coding.IEEE Computational Intelligence Magazine, 20(2):45–57, 2025
Malu Zhang, Shuai Wang, Jibin Wu, Wenjie Wei, Dehao Zhang, Zijian Zhou, Siying Wang, Fan Zhang, and Yang Yang. Toward energy-efficient spike-based deep reinforce- ment learning with temporal coding.IEEE Computational Intelligence Magazine, 20(2):45–57, 2025. 3
2025
-
[54]
Active example selection for in-context learning
Yiming Zhang, Shi Feng, and Chenhao Tan. Active example selection for in-context learning. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Pro- cessing, 2022. 3
2022
-
[55]
See and think: Embodied agent in virtual environment
Zhonghan Zhao, Wenhao Chai, Xuan Wang, Boyi Li, Shengyu Hao, Shidong Cao, Tian Ye, and Gaoang Wang. See and think: Embodied agent in virtual environment. In European Conference on Computer Vision (ECCV), pages 187–204. Springer, 2024. 3
2024
-
[56]
Hierarchical auto-organizing system for open-ended multi-agent naviga- tion
Zhonghan Zhao, Kewei Chen, Dongxu Guo, Wenhao Chai, Tian Ye, Yanting Zhang, and Gaoang Wang. Hierarchical auto-organizing system for open-ended multi-agent naviga- tion. InInternational Conference on Learning Representa- tions (ICLR), Workshop on Large Language Model (LLM) Agents, 2024
2024
-
[57]
LLaV A-FA: Learning fourier approximation for compressing large mul- timodal models
Pengcheng Zheng, Chaoning Zhang, Jiarong Mo, GuoHui Li, Jiaquan Zhang, Jiahao Zhang, Sihan Cao, Sheng Zheng, Caiyan Qin, Guoqing Wang, and Yang Yang. LLaV A-FA: Learning fourier approximation for compressing large mul- timodal models. InInternational Conference on Learning Representations (ICLR), 2026. Poster. 3
2026
-
[58]
Steve-eye: Equipping llm-based embodied agents with visual perception in open worlds
Sipeng Zheng, Jiazheng Liu, Yicheng Feng, and Zongqing Lu. Steve-eye: Equipping llm-based embodied agents with visual perception in open worlds. InInternational Confer- ence on Learning Representations (ICLR), 2024. 2, 3
2024
-
[59]
Mcu: An evaluation framework for open-ended game agents
Xinyue Zheng, Haowei Lin, Kaichen He, Zihao Wang, Qiang Fu, Haobo Fu, Zilong Zheng, and Yitao Liang. Mcu: An evaluation framework for open-ended game agents. InIn- ternational Conference on Machine Learning (ICML), 2025. 3
2025
-
[60]
Large lan- guage models are human-level prompt engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large lan- guage models are human-level prompt engineers. InInter- national Conference on Learning Representations (ICLR),
-
[61]
Xizhou Zhu, Yuntao Chen, Hao Tian, Chenxin Tao, Wei- jie Su, Chenyu Yang, Gao Huang, Bin Li, Lewei Lu, Xiao- gang Wang, et al. Ghost in the minecraft: Generally capable agents for open-world environments via large language mod- els with text-based knowledge and memory.arXiv preprint arXiv:2305.17144, 2023. 2 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.