Recognition: unknown
CAP-CoT: Cycle Adversarial Prompt for Improving Chain of Thoughts in LLM Reasoning
Pith reviewed 2026-05-08 08:07 UTC · model grok-4.3
The pith
CAP-CoT improves chain-of-thought accuracy and stability by cycling between correct and deliberately flawed reasoning chains to refine prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By closing an optimization loop in which an adversarial challenger constructs targeted flawed chains, a feedback agent extracts step-level contrasts, and both the solver and challenger prompts are updated in opposite directions, the system produces a more reliable solver prompt after only two or three cycles.
What carries the argument
The cycle adversarial prompt optimization loop, in which a forward solver, an adversarial challenger that generates plausible flawed chains via targeted error strategies, and a feedback agent that produces step-aligned contrastive feedback jointly update each other's prompts.
If this is right
- Reasoning accuracy rises on six standard benchmarks when tested on four different LLM backbones.
- Answer variability across independent runs of the same problem drops.
- The final solver prompt becomes more robust to small changes in the original task statement.
- The gains appear after only two or three cycles of the optimization loop.
- The adversarial component stays focused on logical task errors rather than safety or injection attacks.
Where Pith is reading between the lines
- The same contrastive cycle could be applied to other structured output formats such as code generation or multi-step planning.
- Automating prompt refinement this way might reduce the manual trial-and-error cost of deploying chain-of-thought on new domains.
- Running more than three cycles or adding richer error-strategy libraries might produce additional stability on longer problems.
- Pairing the method with a small set of human-written examples could compound the reduction in run-to-run variance.
Load-bearing premise
The adversarial challenger must be able to build flawed chains that expose real logical gaps in the solver without introducing new systematic biases that the feedback agent cannot remove.
What would settle it
A controlled experiment on a fresh set of multi-step problems in which accuracy and answer consistency show no improvement after three full cycles relative to a fixed baseline prompt would falsify the central claim.
Figures



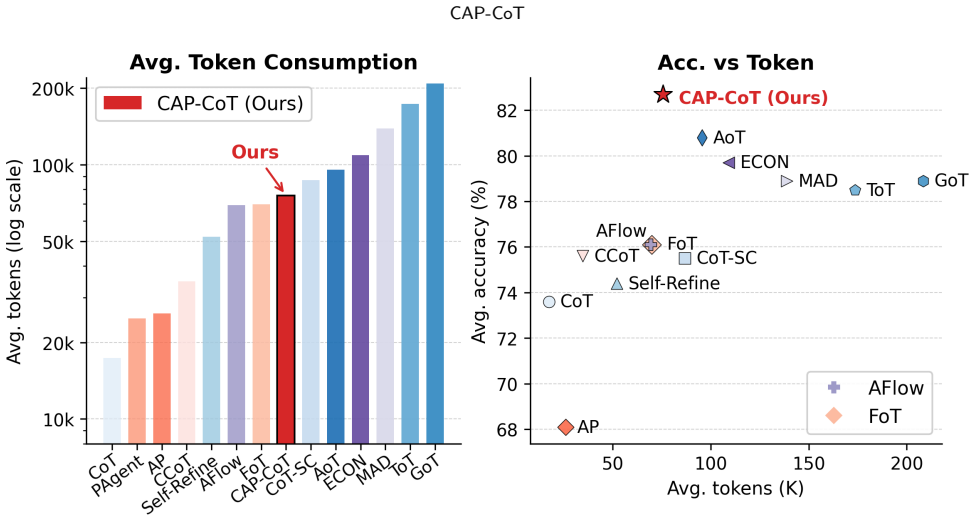
read the original abstract
Chain-of-Thought (CoT) prompting has emerged as a simple and effective way to elicit step-by-step solutions from large language models (LLMs). However, CoT reasoning can be unstable across runs on long, multi-step problems, leading to inconsistent answers for unchanged task. Most prior work focuses on improving the forward reasoning chain within a single pass, with less attention to iterative and contrastive correction. To address this gap, we propose CAP-CoT, a Cycle Adversarial Prompt optimization framework designed to improve both CoT reasoning accuracy and stability of a single deployed solver. In each cycle, a forward solver generates candidate reasoning chains, an adversarial challenger constructs plausible but deliberately flawed chains using targeted error strategies, and a feedback agent contrasts the two chains and produces step-aligned structured feedback. This feedback closes the optimization loop in two directions, including updating the solver prompt based on errors exposed by the challenger, and updating the challenger prompt to generate increasingly targeted errors in subsequent cycles. Unlike safety-oriented adversarial prompting such as jailbreak or prompt-injection attacks, our adversarial component is task-semantic and aims to expose logical vulnerabilities in reasoning chains. Experiments across six benchmarks and four LLM backbones demonstrate that within two to three adversarial prompt optimization cycles, CAP-CoT consistently reduces variability across runs while improving reasoning accuracy and robustness to prompt perturbations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CAP-CoT, a Cycle Adversarial Prompt optimization framework for enhancing Chain-of-Thought reasoning in large language models. The method iterates between a solver generating CoT chains, an adversarial challenger producing deliberately flawed chains via targeted error strategies, and a feedback agent that contrasts them to generate structured feedback. This feedback updates the prompts for both the solver and the challenger over 2-3 cycles. The paper claims that this process improves reasoning accuracy, reduces variability across runs, and enhances robustness to prompt perturbations, as demonstrated in experiments on six benchmarks using four different LLM backbones.
Significance. If the empirical results hold under rigorous scrutiny, the work could be significant for the field of LLM reasoning. It introduces an iterative, contrastive adversarial approach to prompt optimization that targets logical vulnerabilities in CoT without requiring model fine-tuning. This could provide a practical way to stabilize and improve multi-step reasoning in deployed LLMs. The cycle structure and dual prompt updates are innovative aspects that build on existing adversarial prompting techniques but apply them to semantic reasoning tasks.
major comments (3)
- [Abstract] Abstract: The abstract asserts that CAP-CoT 'consistently reduces variability across runs while improving reasoning accuracy and robustness' across six benchmarks and four backbones within 2-3 cycles, but provides no quantitative metrics, error bars, statistical tests, or ablation results. This absence makes it impossible to evaluate the effect sizes or reliability of the claimed gains, which are central to the paper's contribution.
- [Method] Method section: The description of the adversarial challenger constructing 'plausible but deliberately flawed chains using targeted error strategies' lacks detail on how these strategies are chosen, whether they are hand-crafted or LLM-generated, and how they are validated to represent genuine logical vulnerabilities rather than narrow or biased error classes. Without this, it is unclear if the feedback loop strengthens general reasoning or merely adapts to the challenger's specific flaws, directly impacting the robustness claims.
- [Experiments] Experiments section: The experiments claim improvements in robustness to prompt perturbations, but without specifying the perturbation types, number of runs for variability assessment, or controls for the adversarial error distribution, it is difficult to rule out overfitting to the challenger's generated flaws rather than achieving genuine generalization.
minor comments (2)
- [Abstract] Abstract: The distinction from safety-oriented adversarial prompting (jailbreaks, prompt-injection) is useful but should include at least one citation to related work for context.
- [Method] The terms 'forward solver', 'adversarial challenger', and 'feedback agent' would benefit from an early diagram or pseudocode in the method section to clarify the cycle flow.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments identify important areas for improving clarity, particularly around quantitative reporting, methodological details, and experimental controls. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that CAP-CoT 'consistently reduces variability across runs while improving reasoning accuracy and robustness' across six benchmarks and four backbones within 2-3 cycles, but provides no quantitative metrics, error bars, statistical tests, or ablation results. This absence makes it impossible to evaluate the effect sizes or reliability of the claimed gains, which are central to the paper's contribution.
Authors: We agree that including key quantitative metrics in the abstract would better convey the effect sizes and reliability of the results. In the revised manuscript, we will update the abstract to report specific average accuracy gains (e.g., +X% across benchmarks), reductions in standard deviation for variability, and mention of statistical significance testing where performed, while maintaining conciseness. revision: yes
-
Referee: [Method] Method section: The description of the adversarial challenger constructing 'plausible but deliberately flawed chains using targeted error strategies' lacks detail on how these strategies are chosen, whether they are hand-crafted or LLM-generated, and how they are validated to represent genuine logical vulnerabilities rather than narrow or biased error classes. Without this, it is unclear if the feedback loop strengthens general reasoning or merely adapts to the challenger's specific flaws, directly impacting the robustness claims.
Authors: We acknowledge the need for greater detail on the error strategy construction. The targeted error strategies combine a fixed taxonomy of hand-crafted logical error types (e.g., arithmetic miscalculations, invalid assumptions, omitted steps, and causal inversions) with LLM-generated instantiations conditioned on those templates. In revision, we will expand the method section to fully describe the taxonomy, the selection and application process, and validation via manual review of a random sample of generated flaws to confirm they align with common reasoning vulnerabilities observed in CoT outputs. This will help demonstrate that the loop targets general logical issues. revision: yes
-
Referee: [Experiments] Experiments section: The experiments claim improvements in robustness to prompt perturbations, but without specifying the perturbation types, number of runs for variability assessment, or controls for the adversarial error distribution, it is difficult to rule out overfitting to the challenger's generated flaws rather than achieving genuine generalization.
Authors: We agree that additional experimental details are necessary to support the robustness and generalization claims. In the revised experiments section, we will specify the perturbation types (synonym substitution, syntactic rephrasing, and token-level noise), confirm that variability metrics are computed over 10 independent runs per configuration, and describe controls including comparisons to non-adversarial baselines and evaluation on held-out error categories not used during challenger prompt updates. We will also add relevant ablations to address potential overfitting concerns. revision: yes
Circularity Check
Empirical iterative prompt optimization with no mathematical derivation or self-referential fitting
full rationale
The paper presents CAP-CoT as a cycle-based adversarial prompt framework consisting of a solver, challenger, and feedback agent that iteratively update prompts over 2-3 cycles. All central claims rest on external experimental validation across six benchmarks and four LLM backbones, with no equations, parameters fitted to subsets of data, or derivations that reduce to inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked in the method description. The approach is a self-contained engineering proposal whose success is measured against independent benchmarks rather than internal consistency alone.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can generate both correct and deliberately flawed but plausible reasoning chains when prompted appropriately.
invented entities (2)
-
Adversarial challenger agent
no independent evidence
-
Feedback agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Longbench:Abilingual,multitask benchmark for long context understanding, in: ACL (1), pp
Bai, Y., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., Du, Z., Liu, X.,Zeng,A.,Hou,L.,etal.,2024. Longbench:Abilingual,multitask benchmark for long context understanding, in: ACL (1), pp. 3119– 3137
2024
-
[2]
Graph of thoughts: Solving elaborate problems with large language models, in: Proceedings of the AAAI conference on artificial intelligence, pp
Besta,M.,Blach,N.,Kubicek,A.,Gerstenberger,R.,Podstawski,M., Gianinazzi, L., Gajda, J., Lehmann, T., Niewiadomski, H., Nyczyk, P., et al., 2024. Graph of thoughts: Solving elaborate problems with large language models, in: Proceedings of the AAAI conference on artificial intelligence, pp. 17682–17690
2024
-
[3]
Forest-of-thought: Scaling test-time compute for enhancing llm reasoning, in: Forty- second International Conference on Machine Learning
Bi,Z.,Han,K.,Liu,C.,Tang,Y.,Wang,Y.,2025. Forest-of-thought: Scaling test-time compute for enhancing llm reasoning, in: Forty- second International Conference on Machine Learning
2025
-
[4]
Premiseordermatters in reasoning with large language models, in: Proceedings of the 41st International Conference on Machine Learning, pp
Chen,X.,Chi,R.A.,Wang,X.,Zhou,D.,2024. Premiseordermatters in reasoning with large language models, in: Proceedings of the 41st International Conference on Machine Learning, pp. 6596–6620
2024
-
[5]
Contrastive chain-of-thought prompting
Chia, Y.K., Chen, G., Tuan, L.A., Poria, S., Bing, L., 2023. Contrastive chain-of-thought prompting. arXiv preprint arXiv:2311.09277
-
[6]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al., 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review arXiv 2021
-
[7]
Emergentcomplexity andzero-shottransfer via unsupervised environment design
Dennis, M., Jaques, N., Vinitsky, E., Bayen, A., Russell, S., Critch, A.,Levine, S.,2020. Emergentcomplexity andzero-shottransfer via unsupervised environment design. Advances in neural information processing systems 33, 13049–13061
2020
-
[8]
26847–26858
Guo,J.,Chen,X.,Xia,Q.,Wang,Z.,Ou,J.,Qin,L.,Yao,S.,Tian,W., 2025.Hash-rag:bridgingdeephashingwithretrieverforefficient,fine retrieval and augmented generation, in: Findings of the Association for Computational Linguistics: ACL 2025, pp. 26847–26858
2025
-
[9]
Query-based adversarial prompt generation
Hayase, J., Borevković, E., Carlini, N., Tramèr, F., Nasr, M., 2024. Query-based adversarial prompt generation. Advances in Neural Information Processing Systems 37, 128260–128279
2024
-
[10]
Measuring mathematical problem solving with the math dataset, in: Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J., 2021. Measuring mathematical problem solving with the math dataset, in: Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)
2021
-
[11]
Alias-freegenerativeadversarialnetworks,in:Proc
Karras,T.,Aittala,M.,Laine,S.,Härkönen,E.,Hellsten,J.,Lehtinen, J.,Aila,T.,2021. Alias-freegenerativeadversarialnetworks,in:Proc. NeurIPS
2021
-
[12]
Debating with more persuasive llms leads to more truthful answers, in: International Conference on Machine Learning, PMLR
Khan, A., Hughes, J., Valentine, D., Ruis, L., Sachan, K., Radhakr- ishnan, A., Grefenstette, E., Bowman, S.R., Rocktäschel, T., Perez, E., 2024. Debating with more persuasive llms leads to more truthful answers, in: International Conference on Machine Learning, PMLR. pp. 23662–23733. Shuxu Chen et al.:Preprint submitted to ElsevierPage 11 of 13 CAP-CoT
2024
-
[13]
Supervised contrastive learning
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., Maschinot, A., Liu, C., Krishnan, D., 2020. Supervised contrastive learning. Advances in neural information processing systems 33, 18661–18673
2020
-
[14]
Large language models are zero-shot reasoners
Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y., 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems 35, 22199–22213
2022
-
[15]
Experience Transfer for Multimodal LLM Agents in Minecraft Game
Li,C.,Liu,J.,Zhang,S.,Jian,H.,Ni,H.,Lee,L.H.,Bae,S.H.,Wang, G., Yang, Y., Zhang, C., 2026a. Experience transfer for multimodal llm agents in minecraft game. arXiv preprint arXiv:2604.05533
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
InFindings of the Association for Computational Linguistics: ACL 2025, pages 26847–26858
Li, Y., Lan, T., Qi, Z., 2026b. When right meets wrong: Bilateral context conditioning with reward-confidence correction for grpo. arXiv preprint arXiv:2603.13134
-
[17]
Zebralogic:Onthescalinglimitsofllms for logical reasoning, in: Forty-second International Conference on Machine Learning
Lin, B.Y., Le Bras, R., Richardson, K., Sabharwal, A., Poovendran, R.,Clark,P.,Choi,Y.,2025. Zebralogic:Onthescalinglimitsofllms for logical reasoning, in: Forty-second International Conference on Machine Learning
2025
-
[18]
Promptoptimizationwithhumanfeedback,in:ICML2024Workshop on Models of Human Feedback for AI Alignment
Lin, X., Dai, Z., Verma, A., Ng, S.K., Jaillet, P., Low, B.K.H., 2024. Promptoptimizationwithhumanfeedback,in:ICML2024Workshop on Models of Human Feedback for AI Alignment
2024
-
[19]
Deductive verification of chain-of-thought reasoning
Ling, Z., Fang, Y., Li, X., Huang, Z., Lee, M., Memisevic, R., Su, H., 2023. Deductive verification of chain-of-thought reasoning. Ad- vances in Neural Information Processing Systems 36, 36407–36433
2023
-
[20]
Prompt Injection attack against LLM-integrated Applications
Liu, Y., Deng, G., Li, Y., Wang, K., Wang, Z., Wang, X., Zhang, T., Liu, Y., Wang, H., Zheng, Y., et al., 2023. Prompt injection attack againstllm-integratedapplications. arXivpreprintarXiv:2306.05499
work page internal anchor Pith review arXiv 2023
-
[21]
Self- refine: Iterative refinement with self-feedback
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y., et al., 2023. Self- refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems 36, 46534–46594
2023
-
[22]
Harmbench: A stan- dardizedevaluationframeworkforautomatedredteamingandrobust refusal, in: International Conference on Machine Learning, PMLR
Mazeika, M., Phan, L., Yin, X., Zou, A., Wang, Z., Mu, N., Sakhaee, E., Li, N., Basart, S., Li, B., et al., 2024. Harmbench: A stan- dardizedevaluationframeworkforautomatedredteamingandrobust refusal, in: International Conference on Machine Learning, PMLR. pp. 35181–35224
2024
-
[23]
Ou, J., Guo, J., Jiang, S., Wang, Z., Qin, L., Yao, S., Tian, W., 2025. Acceleratingadaptiveretrievalaugmentedgenerationviainstruction- driven representation reduction of retrieval overlaps, in: Findings of the Association for Computational Linguistics: ACL 2025, pp. 26983–27000
2025
-
[24]
Training language models to follow instructions with human feedback
Ouyang,L.,Wu,J.,Jiang,X.,Almeida,D.,Wainwright,C.,Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al., 2022. Training language models to follow instructions with human feedback. Ad- vances in neural information processing systems 35, 27730–27744
2022
-
[25]
Advprompter:Fastadaptiveadversarialpromptingforllms,in:Forty- second International Conference on Machine Learning
Paulus, A., Zharmagambetov, A., Guo, C., Amos, B., Tian, Y., 2025. Advprompter:Fastadaptiveadversarialpromptingforllms,in:Forty- second International Conference on Machine Learning
2025
-
[26]
Red teaming language models with language models, in: Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp
Perez,E.,Huang,S.,Song,F.,Cai,T.,Ring,R.,Aslanides,J.,Glaese, A., McAleese, N., Irving, G., 2022. Red teaming language models with language models, in: Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 3419–3448
2022
-
[27]
Rainbow teaming: Open-ended generation of diverse adversarial prompts
Samvelyan, M., Raparthy, S.C., Lupu, A., Hambro, E., Markosyan, A.H., Bhatt, M., Mao, Y., Jiang, M., Parker-Holder, J., Foerster, J., et al., 2024. Rainbow teaming: Open-ended generation of diverse adversarial prompts. Advances in Neural Information Processing Systems 37, 69747–69786
2024
-
[28]
Reflexion: Language agents with verbal reinforcement learning
Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., Yao, S., 2023. Reflexion: Language agents with verbal reinforcement learning. Ad- vances in Neural Information Processing Systems 36, 8634–8652
2023
-
[29]
Challenging big-bench tasks and whether chain-of-thought can solve them, in: ACL (Findings)
Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q.V., Chi, E.H., Zhou, D., et al., 2023. Challenging big-bench tasks and whether chain-of-thought can solve them, in: ACL (Findings)
2023
-
[30]
Atom of thoughts for markov llm test-time scaling
Teng, F., Yu, Z., Shi, Q., Zhang, J., Wu, C., Luo, Y., 2025. Atom of thoughts for markov llm test-time scaling. CoRR
2025
-
[31]
Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting
Turpin, M., Michael, J., Perez, E., Bowman, S., 2023. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. Advances in Neural Information Processing Systems 36, 74952–74965
2023
-
[32]
Wang, B., Min, S., Deng, X., Shen, J., Wu, Y., Zettlemoyer, L., Sun, H., 2023a. Towards understanding chain-of-thought prompting: An empirical study of what matters, in: Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pp. 2717–2739
-
[33]
Wang,C.,Zhang,Y.,Wang,W.,Zhao,X.,Feng,F.,He,X.,Chua,T.S.,
-
[34]
Think-while-generating: On-the-fly reasoning for personalized long-form generation,
Think-while-generating:On-the-flyreasoningforpersonalized long-form generation. arXiv preprint arXiv:2512.06690
-
[35]
Self-consistencyimproveschainof thoughtreasoninginlanguagemodels,in:TheEleventhInternational Conference on Learning Representations
Wang, X., Wei, J., Schuurmans, D., Le, Q.V., Chi, E.H., Narang, S., Chowdhery,A.,Zhou,D.,2023b. Self-consistencyimproveschainof thoughtreasoninginlanguagemodels,in:TheEleventhInternational Conference on Learning Representations
-
[36]
Transforming External Knowledge into Triplets for Enhanced Retrieval in RAG of LLMs
Wang, X., Zhang, C., Sun, Q., Huang, Z., Lu, C., Zheng, S., Ma, Z., Qin, C., Yang, Y., Shen, H., 2026. Transforming external knowledge into triplets for enhanced retrieval in rag of llms. arXiv preprint arXiv:2604.12610
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Chain-of-thought prompting elicits reasoning in large language models
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al., 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35, 24824–24837
2022
-
[38]
Self-polish: Enhance reasoning in large language models via problem refinement, in: Findings of the Association for Computational Linguistics: EMNLP 2023, pp
Xi,Z.,Jin,S.,Zhou,Y.,Zheng,R.,Gao,S.,Liu,J.,Gui,T.,Zhang,Q., Huang, X.J., 2023. Self-polish: Enhance reasoning in large language models via problem refinement, in: Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 11383–11406
2023
-
[39]
Generat- ing adversarial examples with adversarial networks, in: Proceedings of the 27th International Joint Conference on Artificial Intelligence, pp
Xiao,C.,Li,B.,Zhu,J.Y.,He,W.,Liu,M.,Song,D.,2018. Generat- ing adversarial examples with adversarial networks, in: Proceedings of the 27th International Joint Conference on Artificial Intelligence, pp. 3905–3911
2018
-
[40]
Large language models as optimizers, in: The Twelfth International Conference on Learning Representations
Yang, C., Wang, X., Lu, Y., Liu, H., Le, Q.V., Zhou, D., Chen, X., 2024. Large language models as optimizers, in: The Twelfth International Conference on Learning Representations
2024
-
[41]
Yang, M., Huang, E., Zhang, L., Surdeanu, M., Wang, W.Y., Pan, L., 2025a. How is llm reasoning distracted by irrelevant context? an analysis using a controlled benchmark, in: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 13340–13358
2025
-
[42]
Minimiz- ing hallucinations and communication costs: Adversarial debate and voting mechanisms in llm-based multi-agents
Yang, Y., Ma, Y., Feng, H., Cheng, Y., Han, Z., 2025b. Minimiz- ing hallucinations and communication costs: Adversarial debate and voting mechanisms in llm-based multi-agents. Applied Sciences 15, 3676
-
[43]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering, in: Proceedings of the 2018 Confer- ence on Empirical Methods in Natural Language Processing, pp
Yang,Z.,Qi,P.,Zhang,S.,Bengio,Y.,Cohen,W.,Salakhutdinov,R., Manning, C.D., 2018. Hotpotqa: A dataset for diverse, explainable multi-hop question answering, in: Proceedings of the 2018 Confer- ence on Empirical Methods in Natural Language Processing, pp. 2369–2380
2018
-
[44]
Tree of thoughts: Deliberate problem solving withlargelanguagemodels
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T., Cao, Y., Narasimhan, K., 2023. Tree of thoughts: Deliberate problem solving withlargelanguagemodels. Advancesinneuralinformationprocess- ing systems 36, 11809–11822
2023
-
[45]
Yao, Y., Cen, Z., Li, M., Han, W., Zhang, Y., Liu, E., Liu, Z., Gan, C., Zhao, D., 2025. Your language model may think too rigidly: Achieving reasoning consistency with symmetry-enhanced training. arXiv preprint arXiv:2502.17800
-
[46]
Large language models as analogical reasoners, in: The Twelfth International Conference on Learning Representations
Yasunaga, M., Chen, X., Li, Y., Pasupat, P., Leskovec, J., Liang, P., Chi, E.H., Zhou, D., 2024. Large language models as analogical reasoners, in: The Twelfth International Conference on Learning Representations
2024
-
[47]
From debate to equilibrium: Belief-driven multi-agent llm reasoning via bayesiannashequilibrium,in:Forty-secondInternationalConference on Machine Learning
Yi, X., Zhou, Z., Cao, C., Niu, Q., Liu, T., Han, B., 2025a. From debate to equilibrium: Belief-driven multi-agent llm reasoning via bayesiannashequilibrium,in:Forty-secondInternationalConference on Machine Learning
-
[48]
From debate to equilibrium: Belief-driven multi-agent llm reasoning via bayesiannashequilibrium,in:Forty-secondInternationalConference on Machine Learning
Yi, X., Zhou, Z., Cao, C., Niu, Q., Liu, T., Han, B., 2025b. From debate to equilibrium: Belief-driven multi-agent llm reasoning via bayesiannashequilibrium,in:Forty-secondInternationalConference on Machine Learning. Shuxu Chen et al.:Preprint submitted to ElsevierPage 12 of 13 CAP-CoT
-
[49]
TDA-RC: Task-Driven Alignment for Knowledge-Based Reasoning Chains in Large Language Models
Zhang,J.,Sun,Q.,Zhang,C.,Wang,X.,Huang,Z.,Zhou,Y.,Zheng, P., lok Andy Tai, C., Bae, S.H., Ma, Z., Qin, C., Guo, J., Yang, Y., Shen, H., 2026a. Tda-rc: Task-driven alignment for knowledge- based reasoning chains in large language models. arXiv preprint arXiv:2604.04942
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Aflow:Automatingagen- tic workflow generation, in: The Thirteenth International Conference on Learning Representations
Zhang,J.,Xiang,J.,Yu,Z.,Teng,F.,Chen,X.H.,Chen,J.,Zhuge,M., Cheng,X.,Hong,S.,Wang,J.,etal.,2025a. Aflow:Automatingagen- tic workflow generation, in: The Thirteenth International Conference on Learning Representations
-
[51]
Lightweight LLM Agent Memory with Small Language Models
Zhang, J., Zhang, C., Chen, S., Huang, Z., Zheng, P., Wang, Z., Guo, P., Mo, F., Bae, S.H., Zou, J., Wei, J., Yang, Y., 2026b. Lightweight llm agent memory with small language models. arXiv preprint arXiv:2604.07798
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Text summariza- tion via global structure awareness, in: The Fourteenth International Conference on Learning Representations
Zhang, J., Zhang, C., Chen, S., Liu, Y., Li, C., Sun, Q., Yuan, S., Puspitasari, F.D., Han, D., Wang, G., et al., 2026c. Text summariza- tion via global structure awareness, in: The Fourteenth International Conference on Learning Representations
-
[53]
Learning global hypothesis space for enhancing synergistic reasoning chain, in: The Fourteenth International Conference on Learning Representations
Zhang, J., Zhang, C., Chen, S., Wang, X., Huang, Z., Zheng, P., Yuan, S., Zheng, S., Sun, Q., Zou, J., et al., 2026d. Learning global hypothesis space for enhancing synergistic reasoning chain, in: The Fourteenth International Conference on Learning Representations
-
[54]
Spike-driven lightweight large language model with evolutionary computation
Zhang, M., Wei, W., Zhou, Z., Liu, W., Zhang, J., Belatreche, A., Yang, Y., 2025b. Spike-driven lightweight large language model with evolutionary computation. IEEE Transactions on Evolutionary Computation , 1–1doi:10.1109/TEVC.2025.3606613
-
[55]
Mmlu-cf: A contamination-free multi-task language understanding benchmark
Zhao, Q., Huang, Y., Lv, T., Cui, L., Sun, Q., Mao, S., Zhang, X., Xin, Y., Yin, Q., Li, S., et al., 2024. Mmlu-cf: A contamination-free multi-task language understanding benchmark. CoRR
2024
-
[56]
Llava-fa: Learning fourier approximation for compressing large multimodal models
Zheng, P., Zhang, C., Mo, J.H., Li, G., Zhang, J., Zhang, J., Cao, S., Zheng, S., Qin, C., Wang, G., Yang, Y., 2026. Llava-fa: Learning fourier approximation for compressing large multimodal models. arXiv preprint arXiv:2602.00135
-
[57]
Lookinwardto exploreoutward:Learningtemperaturepolicyfromllminternalstates via hierarchical rl
Zhou,Y.,Li,Y.,Cheng,D.,Fan,H.,Cheng,Y.,2026. Lookinwardto exploreoutward:Learningtemperaturepolicyfromllminternalstates via hierarchical rl. arXiv preprint arXiv:2602.13035
-
[58]
Unpaired image-to- imagetranslationusingcycle-consistentadversarialnetworks,in:Pro- ceedings of the IEEE International Conference on Computer Vision, pp
Zhu, J.Y., Park, T., Isola, P., Efros, A.A., 2017. Unpaired image-to- imagetranslationusingcycle-consistentadversarialnetworks,in:Pro- ceedings of the IEEE International Conference on Computer Vision, pp. 2223–2232. Shuxu Chen et al.:Preprint submitted to ElsevierPage 13 of 13
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.