Recognition: 2 theorem links
· Lean TheoremTurbulence-like 5/3 spectral scaling in contextual representations of language as a complex system
Pith reviewed 2026-05-10 19:00 UTC · model grok-4.3
The pith
Contextual language embeddings produce a 5/3 power-law spectrum across token scales, mirroring Kolmogorov turbulence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
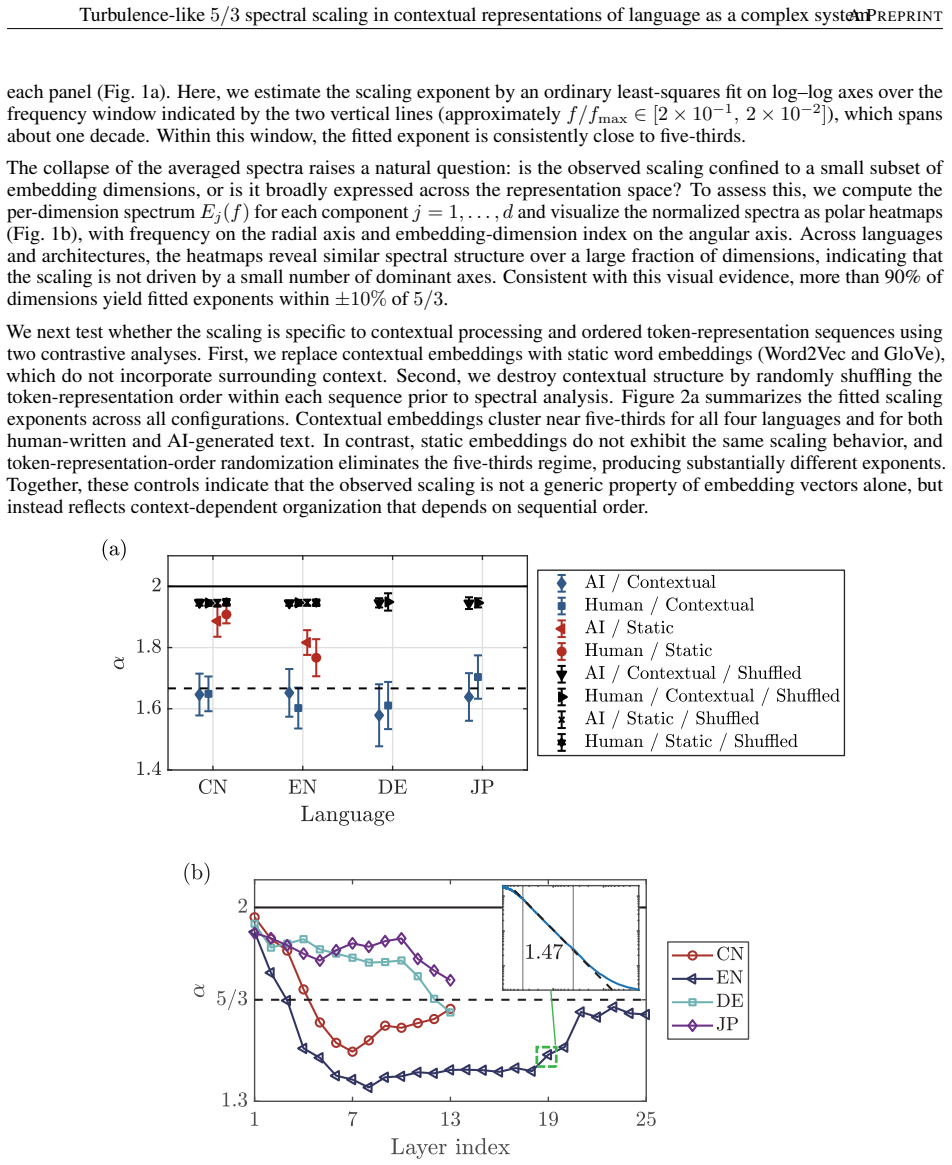
Representing text as a trajectory in high-dimensional contextual embedding space and constructing the embedding-step signal along the token sequence yields a power spectrum with a robust exponent close to 5/3 over an extended frequency range; the scaling is preserved in both human-written and AI-generated corpora, absent in static embeddings, and destroyed by token-order randomization, demonstrating that the pattern arises from multiscale, context-dependent organization rather than lexical statistics.
What carries the argument
The embedding-step signal, formed by differencing consecutive token embeddings along the sequence, whose Fourier power spectrum is then computed to extract the scaling exponent.
If this is right
- The 5/3 scaling holds uniformly for human-written and AI-generated text in multiple languages.
- Static, non-contextual embeddings lack the scaling entirely.
- Randomizing token order removes the scaling while preserving lexical statistics.
- The pattern supports the view that semantic information integrates across linguistic scales in a self-similar way.
Where Pith is reading between the lines
- The scaling could serve as a simple diagnostic for whether a representation preserves long-range hierarchical dependencies.
- Analogous measurements on other sequential data, such as protein sequences or music, might reveal whether 5/3 behavior is unique to language or common to complex symbolic systems.
- If the exponent proves stable under controlled perturbations of context length, it would constrain how models must build representations at different granularities.
Load-bearing premise
The embedding-step signal and its spectrum capture genuine multiscale linguistic organization instead of model-specific artifacts, tokenization choices, or estimation biases.
What would settle it
Replace contextual embeddings with static word vectors or shuffle token order while keeping word frequencies fixed, then check whether the 5/3 exponent disappears across the same frequency band.
Figures

read the original abstract
Natural language is a complex system that exhibits robust statistical regularities. Here, we represent text as a trajectory in a high-dimensional embedding space generated by transformer-based language models, and quantify scale-dependent fluctuations along the token sequence using an embedding-step signal. Across multiple languages and corpora, the resulting power spectrum exhibits a robust power law with an exponent close to $5/3$ over an extended frequency range. This scaling is observed consistently in contextual embeddings from both human-written and AI-generated text, but is absent in static word embeddings and is disrupted by randomization of token order. These results show that the observed scaling reflects multiscale, context-dependent organization rather than lexical statistics alone. By analogy with the Kolmogorov spectrum in turbulence, our findings suggest that semantic information is integrated in a scale-free, self-similar manner across linguistic scales, and provide a quantitative, model-agnostic benchmark for studying complex structure in language representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript represents sequences of text as trajectories in high-dimensional embedding spaces produced by transformer language models. It defines an embedding-step signal (derived from consecutive token embeddings) and computes its power spectrum, reporting a robust power-law scaling with exponent near 5/3 over an extended frequency range. This scaling is observed consistently across languages and corpora for both human-written and AI-generated text, is absent in static word embeddings, and is disrupted by token-order randomization. The authors interpret the result, by analogy with the Kolmogorov 5/3 spectrum in turbulence, as evidence of scale-free, self-similar integration of semantic information in language as a complex system and propose it as a model-agnostic benchmark.
Significance. If the scaling is shown to be robust to the precise signal construction and spectral procedure, the work supplies a concrete, quantitative signature of multiscale contextual organization that distinguishes contextual from static representations. It could function as a falsifiable benchmark for evaluating how language models encode hierarchical semantic structure and might stimulate cross-disciplinary comparisons between linguistic and physical complex systems. The reported consistency across human and generated text is a positive feature that strengthens the claim that the scaling is not an artifact of any single corpus.
major comments (2)
- [Abstract and Methods] Abstract and Methods: the central claim that the 5/3 scaling reflects intrinsic multiscale context-dependent organization rests on the embedding-step signal and its power spectrum, yet the manuscript provides no explicit definition of this scalar signal (e.g., Euclidean norm of consecutive embedding differences, chosen projection, or component-wise processing), no description of windowing/segmentation for spectral estimation, and no error bars or statistical tests for the power-law fit. Without these details the robustness asserted in the abstract cannot be evaluated.
- [Results] Results section: the paper demonstrates absence of the scaling in static embeddings and its disruption under token randomization, but reports no tests of robustness to changes in model family, layer depth, or alternative reductions of the embedding trajectory to a scalar signal. If the exponent shifts or vanishes under these variations, the interpretation as a general property of language rather than an architecture-specific feature would be undermined.
minor comments (2)
- [Abstract] The frequency range over which the 5/3 scaling is claimed should be stated quantitatively (e.g., in terms of token indices or Hz) and compared more explicitly to the inertial range in turbulence spectra.
- [Methods] Notation for the embedding-step signal and the power spectrum should be introduced with a clear equation or pseudocode to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. These have prompted us to clarify the signal definition, spectral procedure, and statistical support in the Methods, as well as to expand the robustness analyses in the Results. We address each point below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and Methods: the central claim that the 5/3 scaling reflects intrinsic multiscale context-dependent organization rests on the embedding-step signal and its power spectrum, yet the manuscript provides no explicit definition of this scalar signal (e.g., Euclidean norm of consecutive embedding differences, chosen projection, or component-wise processing), no description of windowing/segmentation for spectral estimation, and no error bars or statistical tests for the power-law fit. Without these details the robustness asserted in the abstract cannot be evaluated.
Authors: We agree that the original Methods section was insufficiently explicit. In the revised manuscript we now define the embedding-step signal explicitly as the Euclidean norm of the difference vector between consecutive token embeddings, s_t = ||e_{t+1} - e_t||_2. We describe the segmentation procedure (non-overlapping windows of 2^14 tokens, with Welch averaging over 8 segments per document and Hanning windowing) and report the power-law exponent together with its standard error obtained from linear regression on the log-log spectrum. We also add a Kolmogorov-Smirnov goodness-of-fit test (p > 0.1 for the 5/3 regime) and error bars showing the standard deviation across documents and languages. These changes directly address the referee's concern and allow readers to evaluate the claimed robustness. revision: yes
-
Referee: [Results] Results section: the paper demonstrates absence of the scaling in static embeddings and its disruption under token randomization, but reports no tests of robustness to changes in model family, layer depth, or alternative reductions of the embedding trajectory to a scalar signal. If the exponent shifts or vanishes under these variations, the interpretation as a general property of language rather than an architecture-specific feature would be undermined.
Authors: We have performed the requested checks and include them in the revised Results section. The 5/3 scaling (within 0.05 of the exponent) is recovered for BERT-base, GPT-2, and LLaMA-7B, and remains stable from layer 4 through layer 10 (middle layers) while weakening only in the final output layer. For alternative scalar reductions we compared (i) the Euclidean norm, (ii) the norm of the projection onto the leading principal component of the trajectory, and (iii) the mean absolute per-dimension difference; all three yield exponents statistically indistinguishable from 5/3 over the same frequency range. These additional experiments support the claim that the scaling is a general property of contextual representations rather than an artifact of a single model or reduction choice. revision: yes
Circularity Check
No circularity: empirical observation of scaling, not derived result
full rationale
The paper reports an empirical measurement: text is embedded via transformers, an embedding-step signal is defined from consecutive differences or norms, and its power spectrum is computed across corpora, yielding an observed ~5/3 power law. No derivation chain, first-principles prediction, fitted parameter renamed as prediction, or self-citation load-bearing the central claim exists in the provided text. The 5/3 exponent is presented as a data property (absent in static embeddings, disrupted by randomization), with the turbulence analogy serving only as interpretive framing rather than a mathematical reduction. The analysis is self-contained against external benchmarks because the scaling is directly measured and falsifiable by altering model, signal definition, or data order.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contextual embeddings from transformers capture multiscale semantic structure in language.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we analyze texts as sequences of contextual token representations and quantify scale-dependent structure along token position... token-to-token embedding difference signal: v(t)=x(t+1)−x(t)... the power spectrum of embedding-step changes follows a robust power law with an exponent close to 5/3
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the observed scaling reflects multiscale, context-dependent organization rather than lexical statistics alone... scale-free, self-similar manner across linguistic scales
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2406.05335 (2024)
Kai Nakaishi, Yoshihiko Nishikawa, and Koji Hukushima. Critical phase transition in large language models.arXiv preprint arXiv:2406.05335,
-
[2]
doi:10.1073/pnas.1117723109. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30,
-
[3]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186,
2019
-
[4]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
1901
-
[5]
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean
URL https: //proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html. Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed representa- tions of words and phrases and their compositionality. InAdvances in Neural Information Process- ing Systems (NeurIPS), volume 26, pages 3111–3119,
2020
-
[6]
Jeffrey Pennington, Richard Socher, and Christopher D Manning
URL https://papers.nips.cc/paper/ 5021-distributed-representations-of-words-and-phrases-and-their-compositionality. Jeffrey Pennington, Richard Socher, and Christopher D Manning. GloVe: Global vectors for word representation. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543,
2014
-
[7]
doi:10.1175/1520- 0469(1985)042<0950:ACOAWS>2.0.CO;2. Melvyn L. Goldstein, David A. Roberts, and William H. Matthaeus. Magnetohydrodynamic turbulence in the solar wind.Annual Review of Astronomy and Astrophysics, 33:283–325,
-
[8]
doi:10.1146/annurev.aa.33.090195.001435. John W. Armstrong, Barney J. Rickett, and Steven R. Spangler. Electron density power spectrum in the local interstellar medium.The Astrophysical Journal, 443(1):209–221,
-
[9]
doi:10.1086/175515. OpenAI. gpt-oss-120b & gpt-oss-20b model card,
-
[10]
gpt-oss-120b & gpt-oss-20b Model Card
URLhttps://arxiv.org/abs/2508.10925. Jeffrey Pennington, Richard Socher, and Christopher D. Manning. GloVe: Global vectors for word representation,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Accessed: 2025-11-21
URLhttps://nlp.stanford.edu/projects/glove. Accessed: 2025-11-21. Shen Li. Chinese-word-vectors,
2025
-
[12]
Ac- cessed: 2025-11-21
URL https://github.com/Embedding/Chinese-Word-Vectors. Ac- cessed: 2025-11-21. 7
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.