Recognition: 2 theorem links
· Lean TheoremEchoAgent: Towards Reliable Echocardiography Interpretation with "Eyes","Hands" and "Minds"
Pith reviewed 2026-05-10 19:47 UTC · model grok-4.3
The pith
EchoAgent coordinates eyes, hands, and minds in one agentic system to interpret echocardiography videos with up to 80 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
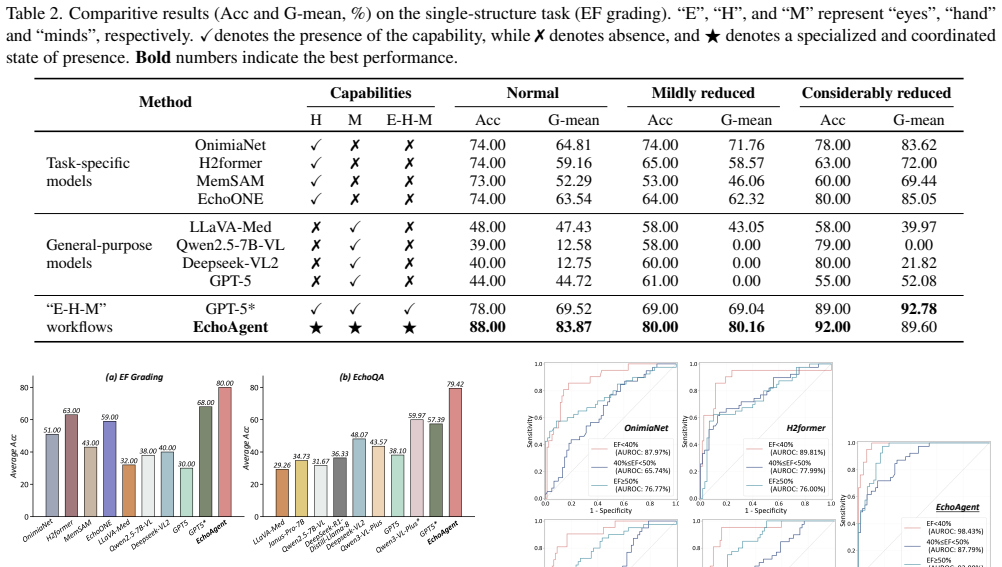
EchoAgent is an agentic system for end-to-end echocardiography interpretation that achieves a fully coordinated eyes-hands-minds workflow. An expertise-driven cognition engine assimilates guidelines into a structured knowledge base. A hierarchical collaboration toolkit parses echo video streams, identifies cardiac views, performs anatomical segmentation, and conducts quantitative measurements. An orchestrated reasoning hub then integrates the multimodal evidence with the knowledge base to generate explainable inferences. On the CAMUS and MIMIC-EchoQA datasets the system reaches overall accuracy up to 80 percent while performing the full sequence of learning, observing, operating, and 1reason
What carries the argument
The agentic architecture built from an expertise-driven cognition engine, a hierarchical collaboration toolkit, and an orchestrated reasoning hub that together enable a single system to learn guidelines, observe videos, operate measurements, and reason about findings.
If this is right
- Optimal performance on diverse structure analyses across 48 echocardiographic views and 14 cardiac regions
- A single system performs the full sequence of learning guidelines, observing videos, operating measurements, and reasoning like an echocardiologist
- Explainable inferences produced by integrating perceived multimodal evidence with the structured knowledge base
- Coverage of both standard and less common views without requiring separate task-specific models
- Direct applicability to end-to-end interpretation pipelines in clinical echocardiography
Where Pith is reading between the lines
- Deployment in hospitals could reduce inter-observer variability in measurements by providing consistent quantitative outputs across different operators
- The modular design might be adapted to other ultrasound modalities that also require simultaneous visual analysis, measurement, and domain knowledge
- Real-time clinical use would likely surface new failure modes around video quality and patient motion not captured in the current offline datasets
- Adding a feedback mechanism that lets clinicians correct outputs could allow the knowledge base to improve iteratively without full retraining
Load-bearing premise
The three main components can be combined without introducing errors or hallucinations when the system processes real-world clinical echo videos outside the two tested datasets.
What would settle it
Running EchoAgent on a fresh collection of clinical echocardiography videos from multiple sites and checking whether accuracy stays above 70 percent while all generated explanations remain free of factual contradictions with the video content.
Figures




read the original abstract
Reliable interpretation of echocardiography (Echo) is crucial for assessing cardiac function, which demands clinicians to synchronously orchestrate multiple capabilities, including visual observation (eyes), manual measurement (hands), and expert knowledge learning and reasoning (minds). While current task-specific deep-learning approaches and multimodal large language models have demonstrated promise in assisting Echo analysis through automated segmentation or reasoning, they remain focused on restricted skills, i.e., eyes-hands or eyes-minds, thereby limiting clinical reliability and utility. To address these issues, we propose EchoAgent, an agentic system tailored for end-to-end Echo interpretation, which achieves a fully coordinated eyes-hands-minds workflow that learns, observes, operates, and reasons like a cardiac sonographer. First, we introduce an expertise-driven cognition engine where our agent can automatically assimilate credible Echo guidelines into a structured knowledge base, thus constructing an Echo-customized mind. Second, we devise a hierarchical collaboration toolkit to endow EchoAgent with eyes-hands, which can automatically parse Echo video streams, identify cardiac views, perform anatomical segmentation, and quantitative measurement. Third, we integrate the perceived multimodal evidence with the exclusive knowledge base into an orchestrated reasoning hub to conduct explainable inferences. We evaluate EchoAgent on CAMUS and MIMIC-EchoQA datasets, which cover 48 distinct echocardiographic views spanning 14 cardiac anatomical regions. Experimental results show that EchoAgent achieves optimal performance across diverse structure analyses, yielding overall accuracy of up to 80.00%. Importantly, EchoAgent empowers a single system with abilities to learn, observe, operate and reason like an echocardiologist, which holds great promise for reliable Echo interpretation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EchoAgent, an agentic system for end-to-end echocardiography interpretation that coordinates visual observation (eyes), quantitative measurement (hands), and expert knowledge reasoning (minds). It introduces an expertise-driven cognition engine to assimilate guidelines into a knowledge base, a hierarchical collaboration toolkit for view parsing, anatomical segmentation, and measurements from video streams, and an orchestrated reasoning hub to integrate multimodal evidence for explainable inferences. Evaluation on the CAMUS and MIMIC-EchoQA datasets (covering 48 views across 14 cardiac regions) reports up to 80% overall accuracy, with component ablations and qualitative examples provided.
Significance. If the performance claims hold under rigorous controls, the work is significant for demonstrating a unified agentic architecture that integrates perception, action, and reasoning in medical imaging, addressing limitations of task-specific models. The methods details on guideline assimilation, view parsing, segmentation, and orchestrated inference, along with ablations, provide concrete support for the integration approach. The stress-test concern about error-free integration on real-world data beyond the two datasets does not appear to invalidate the headline results on the evaluated data, though broader generalizability testing would strengthen the claims.
minor comments (3)
- [Abstract] Abstract: The claim of 'optimal performance across diverse structure analyses' and 'overall accuracy of up to 80.00%' would be strengthened by briefly noting the key baselines compared against and whether statistical tests were applied.
- [Results] Results: Include error bars, standard deviations, or p-values for the accuracy metrics and ablation studies to allow assessment of variability and significance of improvements.
- The manuscript would benefit from a dedicated limitations section addressing potential failure modes in view identification or measurement on low-quality clinical videos.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of EchoAgent and the recommendation for minor revision. We appreciate the recognition that the unified agentic architecture integrating perception, action, and reasoning addresses key limitations of task-specific models in echocardiography interpretation, and that the methods details and ablations provide concrete support.
Circularity Check
No significant circularity; empirical system description
full rationale
The paper describes an agentic AI system (EchoAgent) for echocardiography analysis with no equations, derivations, or first-principles predictions. Claims rest on empirical accuracy (up to 80%) measured on external datasets CAMUS and MIMIC-EchoQA covering 48 views, plus component ablations. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that reduce the central result to its own inputs by construction. The architecture (cognition engine, collaboration toolkit, reasoning hub) is presented as an engineering integration whose validity is tested externally rather than assumed by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Credible Echo guidelines can be automatically assimilated into a structured knowledge base without loss of clinical validity.
invented entities (1)
-
EchoAgent
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
expertise-driven cognition engine ... hierarchical collaboration toolkit ... orchestrated reasoning hub ... 48 distinct echocardiographic views
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
J-cost, golden ratio, 8-tick period, three spatial dimensions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Ahmadi, M
N. Ahmadi, M. Y . Tsang, A. N. Gu, T. S. M. Tsang, and P. Abolmaesumi. Transformer-based spatio-temporal analysis for classification of aortic stenosis severity from echocardio- graphy cine series.IEEE Transactions on Medical Imaging, 43(1):366–376, 2024. 2
2024
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 1, 3, 5, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wen- bin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. corr, abs/2502.13923, 2025. doi: 10.48550.arXiv preprint ARXIV .2502.13923, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
The unified medical language system (umls): integrating biomedical terminology.Nucleic acids research, 32(suppl 1):D267–D270, 2004
Olivier Bodenreider. The unified medical language system (umls): integrating biomedical terminology.Nucleic acids research, 32(suppl 1):D267–D270, 2004. 3
2004
-
[7]
Foundation versus domain-specific models for left ventricular segmenta- tion on cardiac ultrasound.npj Digital Medicine, 8(1):341,
Chieh-Ju Chao, Yunqi Richard Gu, Wasan Kumar, Tiange Xiang, Lalith Appari, Justin Wu, Juan M Farina, Rachael Wraith, Jiwoon Jeong, Reza Arsanjani, et al. Foundation versus domain-specific models for left ventricular segmenta- tion on cardiac ultrasound.npj Digital Medicine, 8(1):341,
-
[8]
Multi-modal medical diagnosis via large-small model collaboration
Wanyi Chen, Zihua Zhao, Jiangchao Yao, Ya Zhang, Jia- jun Bu, and Haishuai Wang. Multi-modal medical diagnosis via large-small model collaboration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 30763–30773, 2025. 3
2025
-
[9]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus- pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811,
work page internal anchor Pith review arXiv
-
[10]
Vision–language foundation model for echocardiogram interpretation.Nature Medicine, 30(5): 1481–1488, 2024
Matthew Christensen, Milos Vukadinovic, Neal Yuan, and David Ouyang. Vision–language foundation model for echocardiogram interpretation.Nature Medicine, 30(5): 1481–1488, 2024. 2
2024
-
[11]
Matin Daghyani, Lyuyang Wang, Nima Hashemi, Bassant Medhat, Baraa Abdelsamad, Eros Rojas Velez, XiaoXiao Li, Michael Y . C. Tsang, Christina Luong, Teresa S. M. Tsang, and Purang Abolmaesumi. Echoagent: Guideline-centric reasoning agent for echocardiography measurement and in- terpretation, 2025. 3
2025
-
[12]
Memsam: Taming segment anything model for echocardiog- raphy video segmentation
Xiaolong Deng, Huisi Wu, Runhao Zeng, and Jing Qin. Memsam: Taming segment anything model for echocardiog- raphy video segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9622–9631, 2024. 1, 2, 6
2024
-
[13]
Medrax: Medical reasoning agent for chest x-ray, 2025
Adibvafa Fallahpour, Jun Ma, Alif Munim, Hongwei Lyu, and Bo Wang. Medrax: Medical reasoning agent for chest x-ray.arXiv preprint arXiv:2502.02673, 2025. 2, 3
-
[14]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, Haofen Wang, et al. Retrieval-augmented generation for large lan- guage models: A survey.arXiv preprint arXiv:2312.10997, 2(1):32, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Diastolic dysfunction: a comparison of 2025 ase, 2024 bse and 2022 eacvi guidelines, 2025
Julia Grapsa, Edgar Argulian, and Otto A Smiseth. Diastolic dysfunction: a comparison of 2025 ase, 2024 bse and 2022 eacvi guidelines, 2025. 3
2025
-
[16]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning ca- pability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
H2former: An efficient hierarchical hybrid transformer for medical image segmentation.IEEE Trans- actions on Medical Imaging, 42(9):2763–2775, 2023
Along He, Kai Wang, Tao Li, Chengkun Du, Shuang Xia, and Huazhu Fu. H2former: An efficient hierarchical hybrid transformer for medical image segmentation.IEEE Trans- actions on Medical Imaging, 42(9):2763–2775, 2023. 1, 2, 6
2023
-
[18]
Paul A Heidenreich, Biykem Bozkurt, David Aguilar, Larry A Allen, Joni J Byun, Monica M Colvin, Anita Deswal, Mark H Drazner, Shannon M Dunlay, Linda R Ev- ers, et al. 2022 aha/acc/hfsa guideline for the management of heart failure: executive summary: a report of the american college of cardiology/american heart association joint com- mittee on clinical p...
2022
-
[19]
Com- plete ai-enabled echocardiography interpretation with multi- task deep learning.JAMA, 334(4):306–318, 2025
Gregory Holste, Evangelos K Oikonomou, M ´arton Tokodi, Attila Kov´acs, Zhangyang Wang, and Rohan Khera. Com- plete ai-enabled echocardiography interpretation with multi- task deep learning.JAMA, 334(4):306–318, 2025. 1
2025
-
[20]
Echoone: segmenting multiple echocar- diography planes in one model
Jiongtong Hu, Wufeng Xue, Jun Cheng, Yingying Liu, Wei Zhuo, and Dong Ni. Echoone: segmenting multiple echocar- diography planes in one model. InProceedings of the computer vision and pattern recognition conference, pages 5207–5216, 2025. 1, 2, 6
2025
-
[21]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Usfm: A universal ultrasound foun- dation model generalized to tasks and organs towards label efficient image analysis.Medical image analysis, 96:103202,
Jing Jiao, Jin Zhou, Xiaokang Li, Menghua Xia, Yi Huang, Lihong Huang, Na Wang, Xiaofan Zhang, Shichong Zhou, Yuanyuan Wang, et al. Usfm: A universal ultrasound foun- dation model generalized to tasks and organs towards label efficient image analysis.Medical image analysis, 96:103202,
-
[23]
Automatic apical view clas- 9 sification of echocardiograms using a discriminative learning dictionary.Medical image analysis, 36:15–21, 2017
Hanan Khamis, Grigoriy Zurakhov, Vered Azar, Adi Raz, Zvi Friedman, and Dan Adam. Automatic apical view clas- 9 sification of echocardiograms using a discriminative learning dictionary.Medical image analysis, 36:15–21, 2017. 2
2017
-
[24]
Roberto M Lang, Luigi P Badano, Victor Mor-Avi, Jonathan Afilalo, Anderson Armstrong, Laura Ernande, Frank A Flachskampf, Elyse Foster, Steven A Goldstein, Tatiana Kuznetsova, et al. Recommendations for cardiac cham- ber quantification by echocardiography in adults: an update from the american society of echocardiography and the euro- pean association of ...
2015
-
[25]
Deep learning for segmentation using an open large-scale dataset in 2d echocardiography.IEEE transac- tions on medical imaging, 38(9):2198–2210, 2019
Sarah Leclerc, Erik Smistad, Joao Pedrosa, Andreas Østvik, Frederic Cervenansky, Florian Espinosa, Torvald Espeland, Erik Andreas Rye Berg, Pierre-Marc Jodoin, Thomas Gre- nier, et al. Deep learning for segmentation using an open large-scale dataset in 2d echocardiography.IEEE transac- tions on medical imaging, 38(9):2198–2210, 2019. 2, 5
2019
-
[26]
Llava-med: Training a large language- and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564,
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language- and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564,
-
[27]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Q-part: quasi- periodic adaptive regression with test-time training for pedi- atric left ventricular ejection fraction regression
Jie Liu, Tiexin Qin, Hui Liu, Yilei Shi, Lichao Mou, Xiao Xi- ang Zhu, Shiqi Wang, and Haoliang Li. Q-part: quasi- periodic adaptive regression with test-time training for pedi- atric left ventricular ejection fraction regression. InProceed- ings of the Computer Vision and Pattern Recognition Con- ference, pages 15560–15569, 2025. 2
2025
-
[29]
Writing Committee Members, Catherine M Otto, Rick A Nishimura, Robert O Bonow, Blase A Carabello, John P Erwin III, Federico Gentile, Hani Jneid, Eric V Krieger, Michael Mack, et al. 2020 acc/aha guideline for the man- agement of patients with valvular heart disease: a report of the american college of cardiology/american heart associa- tion joint committ...
2020
-
[30]
Cross-dimensional transfer learning in medical image segmentation with deep learning.Medical image analysis, 88:102868, 2023
Hicham Messaoudi, Ahror Belaid, Douraied Ben Salem, and Pierre-Henri Conze. Cross-dimensional transfer learning in medical image segmentation with deep learning.Medical image analysis, 88:102868, 2023. 1, 2, 6
2023
-
[31]
Sherif F Nagueh, Danita Y Sanborn, Jae K Oh, Bonita An- derson, Kristen Billick, Genevieve Derumeaux, Allan Klein, Konstantinos Koulogiannis, Carol Mitchell, Amil Shah, et al. Recommendations for the evaluation of left ventricular dias- tolic function by echocardiography and for heart failure with preserved ejection fraction diagnosis: an update from the ...
2025
-
[32]
Vila-m3: Enhancing vision- language models with medical expert knowledge
Vishwesh Nath, Wenqi Li, Dong Yang, Andriy Myronenko, Mingxin Zheng, Yao Lu, Zhijian Liu, Hongxu Yin, Yee Man Law, Yucheng Tang, et al. Vila-m3: Enhancing vision- language models with medical expert knowledge. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 14788–14798, 2025. 2, 3
2025
-
[33]
Echocardiography segmentation with enforced temporal consistency.IEEE transactions on medi- cal imaging, 41(10):2867–2878, 2022
Nathan Painchaud, Nicolas Duchateau, Olivier Bernard, and Pierre-Marc Jodoin. Echocardiography segmentation with enforced temporal consistency.IEEE transactions on medi- cal imaging, 41(10):2867–2878, 2022. 2
2022
-
[34]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. 1, 3, 6, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Echoviewclip: Advancing video quality control through high-performance view recog- nition of echocardiography
Shanshan Song, Yi Qin, Honglong Yang, Taoran Huang, Hongwen Fei, and Xiaomeng Li. Echoviewclip: Advancing video quality control through high-performance view recog- nition of echocardiography. InInternational Conference on Medical Image Computing and Computer-Assisted Interven- tion, pages 181–191. Springer, 2025. 2
2025
-
[36]
Cynthia C Taub, Raymond F Stainback, Theodore Abraham, Daniel Forsha, Enrique Garcia-Sayan, Jeffrey C Hill, Judy Hung, Carol Mitchell, Vera H Rigolin, Vandana Sachdev, et al. Guidelines for the standardization of adult echocar- diography reporting: recommendations from the american society of echocardiography.Journal of the American Soci- ety of Echocardi...
2025
-
[37]
Mimic-iv-echo-ext-mimicechoqa: A benchmark dataset for echocardiogram-based visual ques- tion answering.PhysioNet
Rahul Thapa, Andrew Li, Qingyang Wu, Bryan He, Yuki Sahashi, Christina Binder-Rodriguez, Angela Zhang, David Ouyang, and James Zou. Mimic-iv-echo-ext-mimicechoqa: A benchmark dataset for echocardiogram-based visual ques- tion answering.PhysioNet. 5
-
[38]
Creating large language model applications utilizing langchain: A primer on developing llm apps fast
Oguzhan Topsakal and Tahir Cetin Akinci. Creating large language model applications utilizing langchain: A primer on developing llm apps fast. InInternational conference on applied engineering and natural sciences, pages 1050–1056,
-
[39]
Heart disease and stroke statistics–2017 update
AS Update. Heart disease and stroke statistics–2017 update. Circulation, 135(e146-e603):1, 2017. 1
2017
-
[40]
Comprehensive echocardiogram evalua- tion with view primed vision language ai.Nature, pages 1–3,
Milos Vukadinovic, I-Min Chiu, Xiu Tang, Neal Yuan, Tien- Yu Chen, Paul Cheng, Debiao Li, Susan Cheng, Bryan He, and David Ouyang. Comprehensive echocardiogram evalua- tion with view primed vision language ai.Nature, pages 1–3,
-
[41]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 1, 2, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Ziyue Wang, Junde Wu, Linghan Cai, Chang Han Low, Xihong Yang, Qiaxuan Li, and Yueming Jin. Medagent- pro: Towards evidence-based multi-modal medical diag- nosis via reasoning agentic workflow.arXiv preprint arXiv:2503.18968, 2025. 2
-
[43]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of- experts vision-language models for advanced multimodal understanding.arXiv preprint arXiv:2412.10302, 2024. 2, 6, 7
work page internal anchor Pith review arXiv 2024
-
[44]
Cardiacnet: Learning to reconstruct ab- 10 normalities for cardiac disease assessment from echocardio- gram videos
Jiewen Yang, Yiqun Lin, Bin Pu, Jiarong Guo, Xiaowei Xu, and Xiaomeng Li. Cardiacnet: Learning to reconstruct ab- 10 normalities for cardiac disease assessment from echocardio- gram videos. InEuropean Conference on Computer Vision, pages 293–311. Springer, 2024. 2
2024
-
[45]
Fully automated echocardiogram interpretation in clini- cal practice: feasibility and diagnostic accuracy.Circulation, 138(16):1623–1635, 2018
Jeffrey Zhang, Sravani Gajjala, Pulkit Agrawal, Geoffrey H Tison, Laura A Hallock, Lauren Beussink-Nelson, Mats H Lassen, Eugene Fan, Mandar A Aras, ChaRandle Jordan, et al. Fully automated echocardiogram interpretation in clini- cal practice: feasibility and diagnostic accuracy.Circulation, 138(16):1623–1635, 2018. 2
2018
-
[46]
Bridging multi-level gaps: Bidirectional reciprocal cycle framework for text-guided label-efficient segmentation in echocardiography.Medical Image Analysis, 102:103536, 2025
Zhenxuan Zhang, Heye Zhang, Tieyong Zeng, Guang Yang, Zhenquan Shi, and Zhifan Gao. Bridging multi-level gaps: Bidirectional reciprocal cycle framework for text-guided label-efficient segmentation in echocardiography.Medical Image Analysis, 102:103536, 2025. 2 11
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.