Recognition: no theorem link
EpiBench: Benchmarking Multi-turn Research Workflows for Multimodal Agents
Pith reviewed 2026-05-10 18:26 UTC · model grok-4.3
The pith
EpiBench reveals that even top multimodal agents score only 29.23 percent on hard multi-turn research tasks requiring cross-paper evidence integration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EpiBench instantiates short research workflows where agents must navigate across papers over multiple turns, align evidence from figures and tables, and apply accumulated evidence in memory to answer objective questions that require cross-paper comparisons and multi-figure integration. It supplies a process-level evaluation framework for detailed testing and diagnosis. Results establish that even the leading model achieves only 29.23 percent accuracy on the hard split.
What carries the argument
EpiBench, an episodic multi-turn multimodal benchmark that instantiates short research workflows and supplies process-level evaluation.
If this is right
- Agents must develop better mechanisms for maintaining and reusing evidence across successive turns rather than resetting context each time.
- Process-level evaluation can isolate failures in proactive search versus failures in evidence alignment or memory use.
- Benchmarks focused on verifiable, objective outputs can support development of agents for reproducible research assistance.
- Current multimodal models require substantial advances to handle sustained, multi-evidence research workflows effectively.
Where Pith is reading between the lines
- Success on EpiBench could serve as a stepping stone toward agents that reliably assist with literature synthesis in live scientific projects.
- The emphasis on figures and tables suggests that vision-language capabilities will become a bottleneck for research agents as tasks grow more complex.
- Extending EpiBench to longer episodes or open-ended hypothesis generation would test whether the observed gaps persist beyond short workflows.
Load-bearing premise
The constructed tasks and questions in EpiBench faithfully capture the multi-turn, proactive search and cross-paper evidence integration that occur in actual scientific research workflows.
What would settle it
A controlled comparison in which models that score highly on EpiBench are tested on real, unscripted literature-review tasks involving novel papers and see whether their success rates align with benchmark performance.
Figures


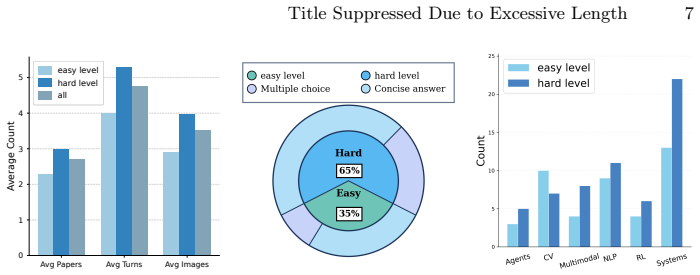
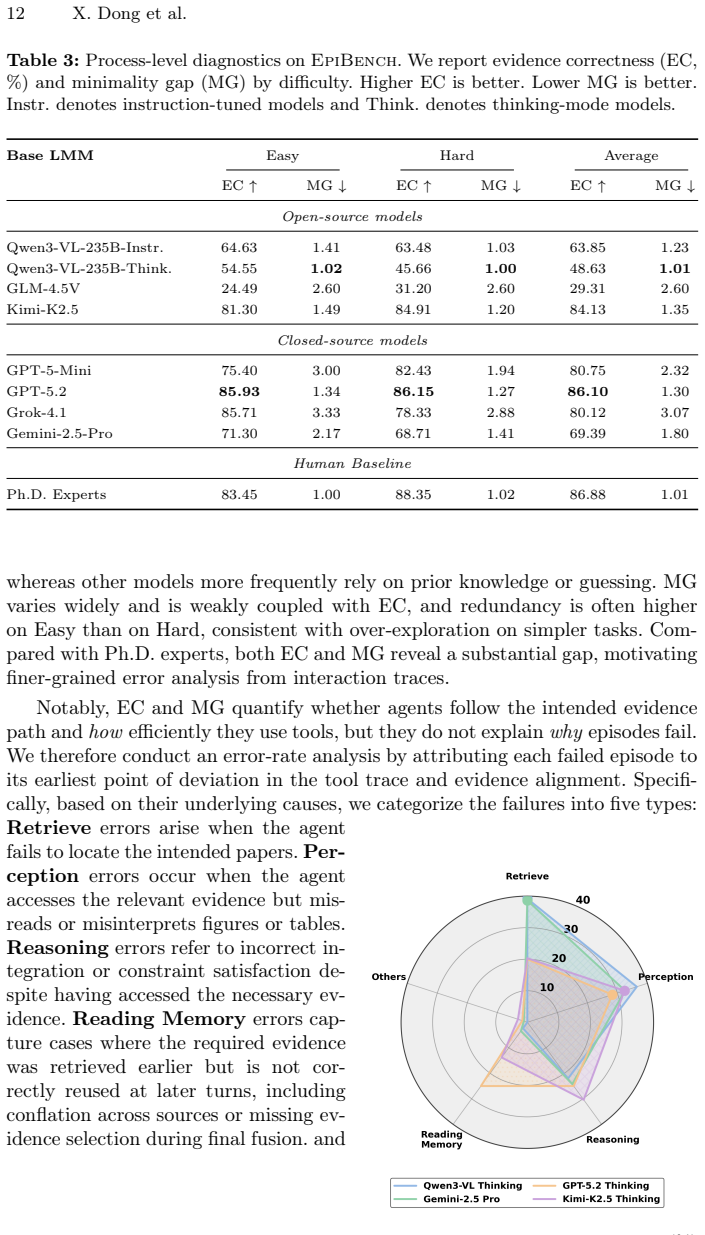

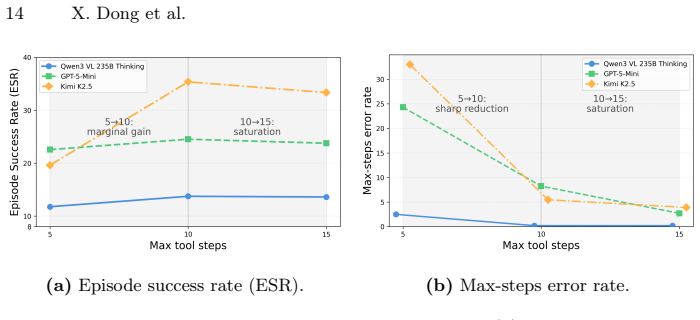



read the original abstract
Scientific research follows multi-turn, multi-step workflows that require proactively searching the literature, consulting figures and tables, and integrating evidence across papers to align experimental settings and support reproducible conclusions. This joint capability is not systematically assessed in existing benchmarks, which largely under-evaluate proactive search, multi-evidence integration and sustained evidence use over time. In this work, we introduce EpiBench, an episodic multi-turn multimodal benchmark that instantiates short research workflows. Given a research task, agents must navigate across papers over multiple turns, align evidence from figures and tables, and use the accumulated evidence in the memory to answer objective questions that require cross paper comparisons and multi-figure integration. EpiBench introduces a process-level evaluation framework for fine-grained testing and diagnosis of research agents. Our experiments show that even the leading model achieves an accuracy of only 29.23% on the hard split, indicating substantial room for improvement in multi-turn, multi-evidence research workflows, providing an evaluation platform for verifiable and reproducible research agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EpiBench, an episodic multi-turn multimodal benchmark for evaluating agents on short scientific research workflows. Given a research task, agents must proactively navigate across papers, align evidence from figures and tables, accumulate evidence in memory, and answer objective questions requiring cross-paper comparisons and multi-figure integration. The central result is that even the leading model reaches only 29.23% accuracy on the hard split; the work also contributes a process-level evaluation framework for fine-grained diagnosis of agent capabilities.
Significance. If the benchmark tasks are faithful to real research workflows, EpiBench supplies a much-needed platform for measuring and improving multi-turn, multi-evidence capabilities that existing benchmarks largely omit. The process-level evaluation framework is a clear strength, enabling diagnosis beyond final-answer accuracy and supporting reproducible development of research agents. The reported performance gap supplies a concrete, falsifiable target for future work.
minor comments (3)
- [Abstract] Abstract: the 29.23% figure is presented without any accompanying information on benchmark scale (number of episodes, papers, or questions); adding one sentence on dataset size would improve immediate readability.
- The process-level metrics are introduced but their exact aggregation into the reported accuracy is not shown in a single equation or table; a small clarifying diagram or pseudocode block would reduce ambiguity.
- Figure captions should explicitly state which process-level dimensions (e.g., navigation, evidence alignment, memory use) are visualized in each panel.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of EpiBench, its significance for evaluating multi-turn multimodal research agents, and the recommendation of minor revision. The referee's summary correctly reflects the benchmark's focus on episodic workflows, cross-paper evidence integration, and the process-level evaluation framework. No specific major comments were provided in the report.
Circularity Check
No significant circularity; empirical benchmark with independent evaluation
full rationale
The paper introduces EpiBench as a new episodic multi-turn multimodal benchmark for research agent workflows, describing task construction, evidence alignment, memory accumulation, and process-level evaluation in detail. It reports experimental accuracies (e.g., 29.23% on the hard split) without any derivation chain, fitted parameters renamed as predictions, self-definitional equations, uniqueness theorems, or ansatzes smuggled via self-citation. The central claim rests on direct measurement against the constructed benchmark, which is externally falsifiable and self-contained against external model evaluations. No load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scientific research follows multi-turn, multi-step workflows that require proactively searching the literature, consulting figures and tables, and integrating evidence across papers.
invented entities (1)
-
EpiBench
no independent evidence
Forward citations
Cited by 1 Pith paper
-
TRACER: Verifiable Generative Provenance for Multimodal Tool-Using Agents
TRACER attaches verifiable sentence-level provenance records to multimodal agent outputs using tool-turn alignment and semantic relations, yielding 78.23% answer accuracy and fewer tool calls than baselines on TRACE-Bench.
Reference graph
Works this paper leans on
-
[1]
arxiv.https://arxiv.org/, accessed: 2026-02-27
2026
-
[2]
Openreview.https://openreview.net/, accessed: 2026-02-27
2026
-
[3]
Bai, S., Cai, Y., Chen, R., et al.: Qwen3-vl technical report (2025),https://arxiv. org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Chen, Z., Geng, X., Wang, X., Jiang, Y., Zhang, Z., Xie, P., Tu, K.: Efficient multimodal planning agent for visual question-answering (2026),https://arxiv. org/abs/2601.20676
-
[5]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Helmholz, W.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities (2025),https://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
DuckDuckGo: Duckduckgo search engine.https://duckduckgo.com/(2026), ac- cessed: 2026-03-03
2026
-
[7]
Google for Developers: Custom search json api: Use rest to invoke the api.https: //developers.google.com/custom-search/v1/using_rest, accessed 2026-03-02
2026
- [8]
- [9]
- [10]
-
[11]
Li, S., Tajbakhsh, N.: Scigraphqa: A large-scale synthetic multi-turn question- answering dataset for scientific graphs (2023)
2023
-
[12]
Liu, Z., Li, J., Zhuang, Y., Liu, Q., Shen, S., Ouyang, J., Cheng, M., Wang, S.: am- elo: A stable framework for arena-based llm evaluation (2025),https://arxiv. org/abs/2505.03475
-
[13]
Liu, Z., Chu, T., Zang, Y., Wei, X., Dong, X., Zhang, P., Liang, Z., Xiong, Y., Qiao, Y., Lin, D., Wang, J.: Mmdu: A multi-turn multi-image dialog understanding benchmark and instruction-tuning dataset for lvlms (2024),https://arxiv.org/ abs/2406.11833 16 X. Dong et al
- [14]
-
[15]
AI Tools for Automating Systematic Literature Reviews
Mikriukov, A., Senokosov, A., Succi, G., Tormasov, A., Plaksin, Y., Trofimova, E., Sitnikov, V.: Ai tools for automating systematic literature reviews. In: Pro- ceedings of the 2025 International Conference on Software Engineering and Com- puter Applications. p. 25–30. SECA ’25, Association for Computing Machin- ery, New York, NY, USA (2025).https://doi.o...
- [16]
-
[17]
OpenAI: Introducing gpt-5.2.https://openai.com/index/introducing-gpt-5- 2/(2025), accessed: 2026-03-05
2025
-
[18]
Pramanick, S., Chellappa, R., Venugopalan, S.: Spiqa: A dataset for multimodal question answering on scientific papers (2025),https://arxiv.org/abs/2407. 09413
2025
-
[19]
Qin, Y., Liang, S., Ye, Y., Zhu, K., Yan, L., Lu, Y., Lin, Y., Cong, X., Tang, X., Qian, B., Zhao, S., Hong, L., Tian, R., Xie, R., Zhou, J., Gerstein, M., Li, D., Liu, Z., Sun, M.: Toolllm: Facilitating large language models to master 16000+ real-world apis (2023),https://arxiv.org/abs/2307.16789
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [20]
-
[21]
Roucher, A., del Moral, A.V., Wolf, T., von Werra, L., Kaunismäki, E.: ‘smo- lagents‘: a smol library to build great agentic systems.https://github.com/ huggingface/smolagents(2025)
2025
-
[22]
In: Oh, A., Naumann, T., Glober- son, A., Saenko, K., Hardt, M., Levine, S
Schick, T., Dwivedi-Yu, J., Dessi, R., Raileanu, R., Lomeli, M., Hambro, E., Zettlemoyer, L., Cancedda, N., Scialom, T.: Toolformer: Language mod- els can teach themselves to use tools. In: Oh, A., Naumann, T., Glober- son, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Infor- mation Processing Systems. vol. 36, pp. 68539–68551. Curran As...
2023
-
[23]
Shabtay, N., Polo, F.M., Doveh, S., Lin, W., Mirza, M.J., Chosen, L., Yurochkin, M., Sun, Y., Arbelle, A., Karlinsky, L., Giryes, R.: Livexiv – a multi-modal live benchmark based on arxiv papers content (2025),https://arxiv.org/abs/2410. 10783
2025
-
[24]
Singh, A., Fry, A., Perelman, A., et al.: Openai gpt-5 system card (2025),https: //arxiv.org/abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Smolyansky, E.: Announcing connected papers — a visual tool for researchers to find and explore academic papers.https://medium.com/connectedpapers/ announcing- connected- papers- a- visual- tool- for- researchers- to- find- and-explore-academic-papers-89146a54c7d4(Jun 2020), accessed: 2026-02-27
2020
- [26]
-
[27]
Team, K., Bai, T., Bai, Y., et al.: Kimi k2.5: Visual agentic intelligence (2026), https://arxiv.org/abs/2602.02276 Title Suppressed Due to Excessive Length 17
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Team, V., Hong, W., Yu, W., et al.: Glm-4.5v and glm-4.1v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning (2026),https: //arxiv.org/abs/2507.01006
work page internal anchor Pith review arXiv 2026
- [29]
-
[30]
Wang, B., Xu, C., Zhao, X., Ouyang, L., Wu, F., Zhao, Z., Xu, R., Liu, K., Qu, Y., Shang, F., Zhang, B., Wei, L., Sui, Z., Li, W., Shi, B., Qiao, Y., Lin, D., He, C.: Mineru: An open-source solution for precise document content extraction (2024), https://arxiv.org/abs/2409.18839
- [31]
-
[32]
Wang, Z., Xia, M., He, L., Chen, H., Liu, Y., Zhu, R., Liang, K., Wu, X., Liu, H., Malladi, S., Chevalier, A., Arora, S., Chen, D.: Charxiv: Charting gaps in realistic chart understanding in multimodal llms (2024),https://arxiv.org/abs/2406. 18521
2024
-
[33]
xAI: Grok 4.1.https://x.ai/news/grok-4-1(Nov 2025), accessed: 2026-03-05
2025
- [34]
-
[35]
In: The Eleventh Interna- tional Conference on Learning Representations (2023),https://openreview.net/ forum?id=WE_vluYUL-X
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K.R., Cao, Y.: React: Synergizing reasoning and acting in language models. In: The Eleventh Interna- tional Conference on Learning Representations (2023),https://openreview.net/ forum?id=WE_vluYUL-X
2023
-
[36]
Zeng, Y., Huang, W., Fang, Z., Chen, S., Shen, Y., Cai, Y., Wang, X., Yin, Z., Chen, L., Chen, Z., Huang, S., Zhao, Y., Tang, X., Hu, Y., Torr, P., Ouyang, W., Cao, S.: Vision-deepresearch benchmark: Rethinking visual and textual search for multimodal large language models (2026),https://arxiv.org/abs/2602.02185 18 X. Dong et al. Supplementary Material Th...
-
[37]
Identify what information is needed and check whether it is already available
-
[38]
If it is not available, retrieve it efficiently through search, download, or extraction tools
-
[39]
ABC" for the first sub-question and
Analyze the collected evidence and answer the question based on the retrieved sources. [Best Practices] - Do not rely on prior knowledge. Use tools to retrieve evidence. - Do not call final_answer in the same response as any other tool. It should be used alone only after all reasoning and tool calls are complete. - If the paper identifier is already known...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.