Recognition: no theorem link
TRACER: Verifiable Generative Provenance for Multimodal Tool-Using Agents
Pith reviewed 2026-05-12 04:25 UTC · model grok-4.3
The pith
Multimodal tool agents become verifiable by generating a provenance record for every answer sentence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
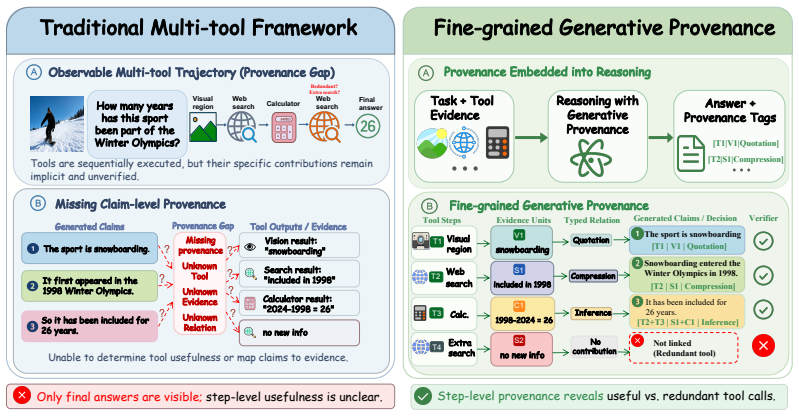
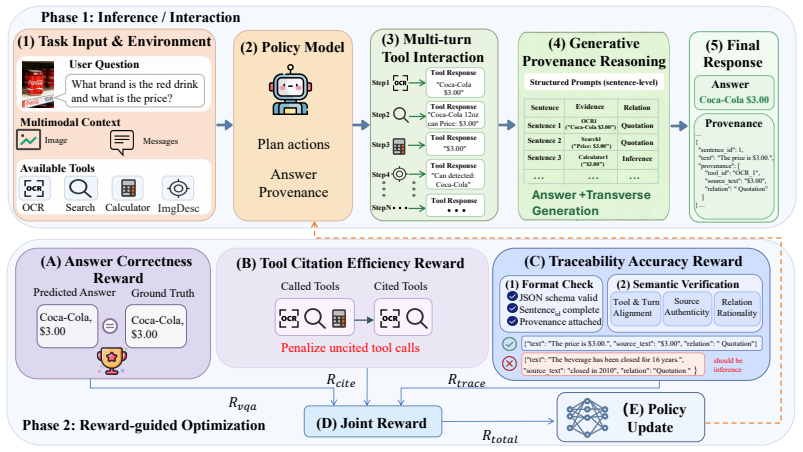
TRACER generates each answer sentence together with a structured provenance record that identifies the supporting tool turn, evidence unit, and semantic support relation from the set of Quotation, Compression, and Inference. The framework verifies these records through schema checking, tool-turn alignment, source authenticity, and relation rationality, converting verified provenance into traceability constraints and local credit signals for reinforcement learning.
What carries the argument
The provenance record, a structured annotation per sentence linking it to a specific tool turn, evidence unit, and one of three support relations (Quotation, Compression, Inference), which is generated and verified to enforce grounded reasoning.
If this is right
- Agents produce answers where unsupported claims can be identified and corrected via the provenance structure.
- Reinforcement learning uses local credit from provenance instead of only final answer rewards.
- Total tool calls decrease because provenance awareness discourages redundant or unhelpful tool uses.
- Traceability allows for post-hoc auditing of how evidence was used in the reasoning process.
Where Pith is reading between the lines
- This method could be applied to text-only agents to improve chain-of-thought traceability.
- Provenance records might enable more efficient human oversight by highlighting questionable inferences.
- Future agent benchmarks could incorporate provenance accuracy as a core metric alongside answer correctness.
Load-bearing premise
The base model can generate provenance records that accurately reflect the support relations without introducing errors that evade the verification checks.
What would settle it
A manual audit of generated answers and their provenance records on a held-out set of trajectories, checking whether the stated support relations correctly match the tool outputs and logical derivation.
Figures



read the original abstract
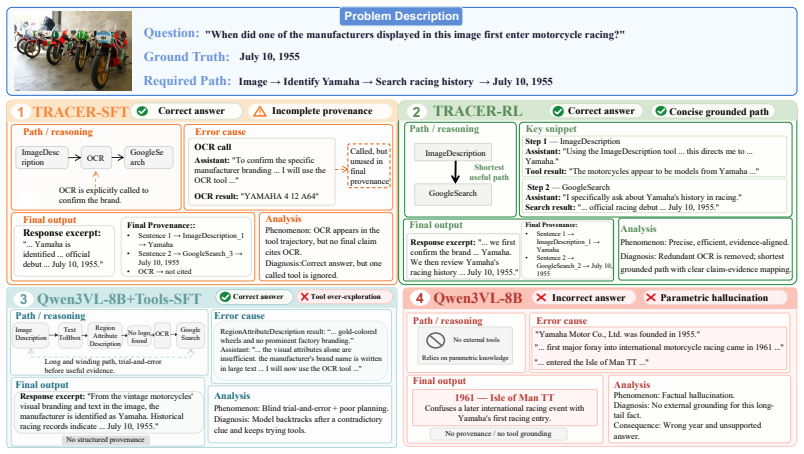
Multimodal large language models increasingly solve vision-centric tasks by calling external tools for visual inspection, OCR, retrieval, calculation, and multi-step reasoning. Current tool-using agents usually expose the executed tool trajectory and the final answer, but they rarely specify which tool observation supports each generated claim. We call this missing claim-level dependency structure the provenance gap. The gap makes tool use hard to verify and hard to optimize, because useful evidence, redundant exploration, and unsupported reasoning are mixed in the same trajectory. We introduce TRACER, a framework for verifiable generative provenance in multimodal tool-using agents. Instead of adding citations after generation, TRACER generates each answer sentence together with a structured provenance record that identifies the supporting tool turn, evidence unit, and semantic support relation. Its relation space contains Quotation, Compression, and Inference, covering direct reuse, faithful condensation, and grounded derivation. TRACER verifies each record through schema checking, tool-turn alignment, source authenticity, and relation rationality, and then converts verified provenance into traceability constraints and provenance-derived local credit for reinforcement learning. We further construct TRACE-Bench, a benchmark for sentence-level provenance reconstruction from coarse multimodal tool trajectories. On TRACE-Bench, simply adding tools often introduces noise. With Qwen3-VL-8B, TRACER reaches 78.23% answer accuracy and 95.72% summary accuracy, outperforming the strongest closed-source tool-augmented baseline by 23.80 percentage points. Compared with tool-only supervised fine-tuning, it also reduces total test-set tool calls from 4949 to 3486. These results show that reliable multimodal tool reasoning depends on provenance-aware use of observations, not on more tool calls alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TRACER, a framework for verifiable generative provenance in multimodal tool-using agents. Instead of exposing only tool trajectories and final answers, TRACER generates each answer sentence together with a structured provenance record identifying the supporting tool turn, evidence unit, and semantic support relation (Quotation, Compression, or Inference). Records are verified through schema checking, tool-turn alignment, source authenticity, and relation rationality; verified provenance is converted into traceability constraints and local credit signals for reinforcement learning. The authors also release TRACE-Bench for sentence-level provenance reconstruction from coarse multimodal trajectories. Experiments with Qwen3-VL-8B report 78.23% answer accuracy and 95.72% summary accuracy (outperforming the strongest closed-source baseline by 23.80 points) while reducing total tool calls from 4949 to 3486.
Significance. If the results hold, the work directly targets the provenance gap in tool-augmented multimodal agents, offering a mechanism to make claim-level evidence dependencies explicit, verifiable, and usable for optimization. The introduction of TRACE-Bench as a dedicated benchmark for provenance reconstruction is a constructive contribution that could support future work on reliable agent reasoning.
major comments (2)
- [Abstract] Abstract: The reported accuracy lift (78.23%) and tool-call reduction are presented without quantitative false-negative rates for the verification pipeline (schema checking, tool-turn alignment, source authenticity, relation rationality) or an ablation that removes the verification step. This information is required to attribute performance gains to reliable provenance-aware observation use rather than to the structured output format or the RL objective itself.
- [TRACE-Bench evaluation] The central claim that reliable multimodal tool reasoning depends on provenance-aware use of observations (rather than more tool calls) rests on the assumption that generated provenance records are sufficiently accurate for RL credit assignment. The manuscript provides no error analysis on TRACE-Bench for provenance generation accuracy, no false-negative rates on verification failures, and no ablation isolating the verification component, leaving the causal attribution unsupported.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The points raised regarding the verification pipeline and evaluation rigor are well-taken, and we will revise the paper to incorporate the requested analyses and ablations. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported accuracy lift (78.23%) and tool-call reduction are presented without quantitative false-negative rates for the verification pipeline (schema checking, tool-turn alignment, source authenticity, relation rationality) or an ablation that removes the verification step. This information is required to attribute performance gains to reliable provenance-aware observation use rather than to the structured output format or the RL objective itself.
Authors: We agree that the current manuscript lacks explicit false-negative rates for the verification modules and an ablation isolating verification. In the revision we will add a new subsection reporting precision, recall, and false-negative rates for each verification component (schema checking, tool-turn alignment, source authenticity, relation rationality) evaluated on TRACE-Bench. We will also include an ablation that disables verification while retaining structured provenance generation and the RL objective, allowing direct attribution of gains to verified provenance rather than format or optimization alone. revision: yes
-
Referee: [TRACE-Bench evaluation] The central claim that reliable multimodal tool reasoning depends on provenance-aware use of observations (rather than more tool calls) rests on the assumption that generated provenance records are sufficiently accurate for RL credit assignment. The manuscript provides no error analysis on TRACE-Bench for provenance generation accuracy, no false-negative rates on verification failures, and no ablation isolating the verification component, leaving the causal attribution unsupported.
Authors: We acknowledge this gap in the current evaluation. The revised manuscript will expand the TRACE-Bench section with a full error analysis of provenance generation accuracy (exact-match rates on tool turn, evidence unit, and relation type) plus a breakdown of verification failure modes and their frequencies. The ablation study outlined above will isolate the verification component. These additions will supply the missing empirical support for the accuracy of records used in RL credit assignment and thereby substantiate the central claim. revision: yes
Circularity Check
No circularity: framework, verification pipeline, and benchmark are independent contributions evaluated on held-out trajectories.
full rationale
The paper defines TRACER as a generative provenance framework with explicit verification steps (schema checking, tool-turn alignment, source authenticity, relation rationality) and converts verified records into RL constraints. TRACE-Bench is constructed separately for sentence-level provenance reconstruction. Reported metrics (78.23% answer accuracy, 95.72% summary accuracy, tool-call reduction) are empirical results on held-out test trajectories with no equations, fitted parameters, or self-citations that reduce any claimed prediction or uniqueness to the inputs by construction. The central claim that provenance-aware observation use drives performance (rather than tool-call volume) rests on this external evaluation rather than definitional equivalence or self-referential justification.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three-relation space (Quotation, Compression, Inference) is sufficient to capture all relevant semantic support relations between generated sentences and tool observations.
invented entities (1)
-
Structured provenance record
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The revolution of multimodal large language models: A survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, and Rita Cucchiara. The revolution of multimodal large language models: A survey. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13590–13618, 2024
work page 2024
-
[2]
A survey of multimodel large language models
Zijing Liang, Yanjie Xu, Yifan Hong, Penghui Shang, Qi Wang, Qiang Fu, and Ke Liu. A survey of multimodel large language models. InProceedings of the 3rd international conference on computer, artificial intelligence and control engineering, pages 405–409, 2024
work page 2024
-
[3]
Shezheng Song, Xiaopeng Li, Shasha Li, Shan Zhao, Jie Yu, Jun Ma, Xiaoguang Mao, Weimin Zhang, and Meng Wang. How to bridge the gap between modalities: Survey on multimodal large language model.IEEE Transactions on Knowledge and Data Engineering (TKDE), 37(9):5311–5329, 2025
work page 2025
-
[4]
Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning. InSecond Conference on Language Modeling (COLM), 2025
work page 2025
-
[5]
Mmsearch-r1: Incentivizing lmms to search.arXiv preprint arXiv:2506.20670, 2025
Jinming Wu, Zihao Deng, Wei Li, Yiding Liu, Bo You, Bo Li, Zejun Ma, and Ziwei Liu. Mmsearch-r1: Incentivizing lmms to search.arXiv preprint arXiv:2506.20670, 2025
-
[6]
Xinyu Geng, Peng Xia, Zhen Zhang, Xinyu Wang, Qiuchen Wang, Ruixue Ding, Chenxi Wang, Jialong Wu, Kuan Li, Yida Zhao, Huifeng Yin, Yong Jiang, Pengjun Xie, Fei Huang, Huaxiu Yao, Yi R. Fung, and Jingren Zhou. Webwatcher: Breaking new frontiers of vision-language deep research agent. InThe Fourteenth International Conference on Learning Representations (IC...
work page 2026
-
[7]
Wenxuan Huang, Yu Zeng, Qiuchen Wang, Zhen Fang, Shaosheng Cao, Zheng Chu, Qingyu Yin, Shuang Chen, Zhenfei Yin, Lin Chen, et al. Vision-deepresearch: Incentivizing deepresearch capability in multimodal large language models.arXiv preprint arXiv:2601.22060, 2026
-
[8]
Deepeyesv2: Toward agentic multimodal model
Jack Hong, Chenxiao Zhao, ChengLIn Zhu, Weiheng Lu, Guohai Xu, and XingYu. Deepeyesv2: Toward agentic multimodal model. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[9]
arXiv preprint arXiv:2511.19900 , year=
Jiaqi Liu, Kaiwen Xiong, Peng Xia, Yiyang Zhou, Haonian Ji, Lu Feng, Siwei Han, Mingyu Ding, and Huaxiu Yao. Agent0-vl: Exploring self-evolving agent for tool-integrated vision- language reasoning.arXiv preprint arXiv:2511.19900, 2025
-
[10]
Reagent-v: A reward-driven multi-agent framework for video understanding
Yiyang Zhou, Yangfan He, Yaofeng Su, Siwei Han, Joel Jang, Gedas Bertasius, Mohit Bansal, and Huaxiu Yao. Reagent-v: A reward-driven multi-agent framework for video understanding. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2026
work page 2026
-
[11]
Act Wisely: Cultivating Meta-Cognitive Tool Use in Agentic Multimodal Models
Shilin Yan, Jintao Tong, Hongwei Xue, Xiaojun Tang, Yangyang Wang, Kunyu Shi, Guannan Zhang, Ruixuan Li, and Yixiong Zou. Act wisely: Cultivating meta-cognitive tool use in agentic multimodal models.arXiv preprint arXiv:2604.08545, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Towards Long-horizon Agentic Multimodal Search
Yifan Du, Zikang Liu, Jinbiao Peng, Jie Wu, Junyi Li, Jinyang Li, Wayne Xin Zhao, and Ji-Rong Wen. Towards long-horizon agentic multimodal search.arXiv preprint arXiv:2604.12890, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
MTA-Agent: An Open Recipe for Multimodal Deep Search Agents
Xiangyu Peng, Can Qin, An Yan, Xinyi Yang, Zeyuan Chen, Ran Xu, and Chien-Sheng Wu. Mta-agent: An open recipe for multimodal deep search agents.arXiv preprint arXiv:2604.06376, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
POINTS-Seeker: Towards Training a Multimodal Agentic Search Model from Scratch
Yikun Liu, Yuan Liu, Le Tian, Xiao Zhou, Jiangchao Yao, Yanfeng Wang, and Weidi Xie. Points-seeker: Towards training a multimodal agentic search model from scratch.arXiv preprint arXiv:2604.14029, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Search-MM: Benchmarking multimodal agentic RAG with structured reasoning chains
Xuying Ning, Dongqi Fu, Tianxin Wei, Mengting Ai, Jiaru Zou, Ting-Wei Li, and Jingrui He. Search-MM: Benchmarking multimodal agentic RAG with structured reasoning chains. In NeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling, 2025
work page 2025
-
[16]
Yu Zeng, Wenxuan Huang, Zhen Fang, Shuang Chen, Yufan Shen, Yishuo Cai, Xiaoman Wang, Zhenfei Yin, Lin Chen, Zehui Chen, et al. Vision-deepresearch benchmark: Rethinking visual and textual search for multimodal large language models.arXiv preprint arXiv:2602.02185, 2026
-
[17]
Zhaochen Su, Jincheng Gao, Hangyu Guo, Zhenhua Liu, Lueyang Zhang, Xinyu Geng, Shijue Huang, Peng Xia, Guanyu Jiang, Cheng Wang, et al. Agentvista: Evaluating multimodal agents in ultra-challenging realistic visual scenarios.arXiv preprint arXiv:2602.23166, 2026
-
[18]
EpiBench: Benchmarking Multi-turn Research Workflows for Multimodal Agents
Xuan Dong, Huanyang Zheng, Tianhao Niu, Zhe Han, Pengzhan Li, Bofei Liu, Zhengyang Liu, Guancheng Li, Qingfu Zhu, and Wanxiang Che. Epibench: Benchmarking multi-turn research workflows for multimodal agents.arXiv preprint arXiv:2604.05557, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Junnan Zhu, Min Xiao, Yining Wang, Feifei Zhai, Yu Zhou, and Chengqing Zong. TROVE: A challenge for fine-grained text provenance via source sentence tracing and relationship classification. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), pages 11755–11771, 2025
work page 2025
-
[20]
GenProve: Learning to Generate Text with Fine-Grained Provenance
Jingxuan Wei, Xingyue Wang, Yanghaoyu Liao, Jie Dong, Yuchen Liu, Caijun Jia, Bihui Yu, and Junnan Zhu. Genprove: Learning to generate text with fine-grained provenance.arXiv preprint arXiv:2601.04932, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
arXiv preprint arXiv:2502.10325 , year=
Sanjiban Choudhury. Process reward models for llm agents: Practical framework and directions. arXiv preprint arXiv:2502.10325, 2025
-
[22]
Agentprm: Process reward models for llm agents via step-wise promise and progress
Zhiheng Xi, Chenyang Liao, Guanyu Li, Zhihao Zhang, Wenxiang Chen, Binghai Wang, Senjie Jin, Yuhao Zhou, Jian Guan, Wei Wu, Tao Ji, Tao Gui, Qi Zhang, and Xuanjing Huang. Agentprm: Process reward models for llm agents via step-wise promise and progress. In Proceedings of the ACM Web Conference 2026 (WWW), page 4184–4195, 2026
work page 2026
-
[23]
STeCa: Step-level trajectory calibration for LLM agent learning
Hanlin Wang, Jian Wang, Chak Tou Leong, and Wenjie Li. STeCa: Step-level trajectory calibration for LLM agent learning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 11597–11614, 2025
work page 2025
-
[24]
arXiv preprint arXiv:2505.20732 , year=
Hanlin Wang, Chak Tou Leong, Jiashuo Wang, Jian Wang, and Wenjie Li. Spa-rl: Reinforcing llm agents via stepwise progress attribution.arXiv preprint arXiv:2505.20732, 2025
-
[25]
VinePPO: Refining credit assignment in RL training of LLMs
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. VinePPO: Refining credit assignment in RL training of LLMs. InForty-second International Conference on Machine Learning (ICML), 2025
work page 2025
-
[26]
Zhirui Deng, Zhicheng Dou, Yutao Zhu, Ji-Rong Wen, Ruibin Xiong, Mang Wang, and Weipeng Chen. From novice to expert: Llm agent policy optimization via step-wise reinforcement learning.arXiv preprint arXiv:2411.03817, 2024
-
[27]
Hindsight credit assignment for long-horizon llm agents, 2026
Hui-Ze Tan, Xiao-Wen Yang, Hao Chen, Jie-Jing Shao, Yi Wen, Yuteng Shen, Weihong Luo, Xiku Du, Lan-Zhe Guo, and Yu-Feng Li. Hindsight credit assignment for long-horizon llm agents.arXiv preprint arXiv:2603.08754, 2026
-
[28]
Qiao Liang, Yuke Zhu, Chao Ge, Lei Yang, Ying Shen, Bo Zheng, and Sheng Guo. Learning from the irrecoverable: Error-localized policy optimization for tool-integrated llm reasoning. arXiv preprint arXiv:2602.09598, 2026. 11
-
[29]
Empowering Multi-Turn Tool-Integrated Agentic Reasoning with Group Turn Policy Optimization
Yifeng Ding, Hung Le, Songyang Han, Kangrui Ruan, Zhenghui Jin, Varun Kumar, Zijian Wang, and Anoop Deoras. Empowering multi-turn tool-integrated reasoning with group turn policy optimization.arXiv preprint arXiv:2511.14846, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Enhancing LLM-based Search Agents via Contribution Weighted Group Relative Policy Optimization
Junzhe Wang, Zhiheng Xi, Hao Luo, Shihan Dou, Tao Gui, Qi Zhang, et al. Enhancing llm- based search agents via contribution weighted group relative policy optimization.arXiv preprint arXiv:2604.14267, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
SimpleTIR: End-to-end reinforcement learning for multi-turn tool-integrated reasoning
Zhenghai Xue, Longtao Zheng, Qian Liu, Yingru Li, Xiaosen Zheng, Zejun MA, and Bo An. SimpleTIR: End-to-end reinforcement learning for multi-turn tool-integrated reasoning. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[32]
E3-TIR: Enhanced Experience Exploitation for Tool-Integrated Reasoning
Weiyang Guo, Zesheng Shi, Liye Zhao, Jiayuan Ma, Zeen Zhu, Junxian He, Min Zhang, and Jing Li. E3-tir: Enhanced experience exploitation for tool-integrated reasoning.arXiv preprint arXiv:2604.09455, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Toolvqa: A dataset for multi-step reasoning vqa with external tools
Shaofeng Yin, Ting Lei, and Yang Liu. Toolvqa: A dataset for multi-step reasoning vqa with external tools. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4424–4433, 2025
work page 2025
-
[34]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Anthropic. Claude 3.5 sonnet system card. Technical report, Anthropic PBC, 2024. Official technical report describing Claude 3.5 Sonnet capabilities and safety benchmarks. Available at: https://www.anthropic.com/news/claude-3-5-sonnet
work page 2024
-
[36]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
work page 2024
-
[39]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
LLM Xiaomi, Bingquan Xia, Bowen Shen, Dawei Zhu, Di Zhang, Gang Wang, Hailin Zhang, Huaqiu Liu, Jiebao Xiao, Jinhao Dong, et al. Mimo: Unlocking the reasoning potential of language model–from pretraining to posttraining.arXiv preprint arXiv:2505.07608, 2025
-
[41]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. A Limitations and Broader Impacts Limitations.TRACER improves verifiable generative provenance for multimodal tool-using agents, but several limitations remain...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Input Data You will receive structured input data containing: •image_path •context : A sequential multi-tool invocation chain; each step contains name, thought, input, output, etc. •question: The question text. •answer: The final correct answer
-
[43]
First, generate a complete user-facingresponse: It must reasonably and coherently answer the question, forming a closed explanatory loop
-
[44]
Then, split the response into multiple continuous sentences/paragraphs (sentence) to form a sentencelist; eachsentencein the list must have verifiableprovenance. Note: You absolutely do not need, nor are you allowed, to use the following fields (even if they exist in the input): •thought_rethink •thought_question
-
[45]
Output Format (Must be strictly consistent) You can only output the following JSON (no additional explanatory text is allowed): { "role": "assistant", "content": { "response": "...", "sentence": [ { "sentence_id": 1, "text": "...", "provenance": [ { "tool_id": "...", "source_text": "...", "relation": "..." } ] } ] } }
-
[46]
How many years did the author live?
Response Generation Rules (Ensure completeness and rationality) 1.responsemust answer thequestion: • The response must directly address what the question asks (e.g., “How many years did the author live?” must explicitly state the number of years in theresponse). • Theresponsemust contain the literal content of the finalanswer(e.g., “55 years“). 2.Restrict...
-
[47]
• Obtain key supporting facts (e.g., get birth and death years via OCR/search)
Structural requirements for theresponse (Mandatory logical closed loop): The response must contain at least the following logical units (can be expressed in natural language, explicit numbering is not required): 18 • Identify/determine the subject of the question (e.g., identify the author from the image, or determine key entities). • Obtain key supportin...
-
[48]
• Sentences not present in theresponseare not allowed to appear in thesentencelist
Sentence Generation Rules (Split from response) 1.sentencemust be split from theresponse: • The text of all sentences in the sentence list, when concatenated by sentence_id from 1..k (allowed to be connected by spaces or line breaks), must strictly restore the content of theresponse(semantics and expression must be consistent). • Sentences not present in ...
-
[49]
Provenance Rules (Strong constraint, verifiable) Eachsentencemust have at least 1provenance. 1.tool_idnaming rules (Mandatory): •tool_id=<context[i].name>_<i> •istarts from 1 (the first element ofcontextis 1). • Examples:ImageDescription_1,OCR_2,GoogleSearch_3. 2.source_textrules (Most important, must be verifiable): • It must contain enough information t...
-
[50]
• Theresponsemust contain a chain of explanation, not just listthoughts
Consistency Hard Constraints & Prohibitions • The response must look like a real assistant’s answer to a user: natural, coherent, and directly answering the question. • Theresponsemust contain a chain of explanation, not just listthoughts. • The sentence list must be a breakdown of the response, not a mechanical splicing of context.thought. • The provenan...
-
[51]
Task DescriptionYou need to judge whether the provenance provided by the model is completely correctbased on themulti-round tool interaction historyand theprovenance information in the model’s final output, strictly following the 3 rules below
-
[52]
Validation Rules 1.Tool and Round Validation •tool_idformat:ToolName_Number • Number = theN-th time this tool is called(incrementing from 1) • Must be completely consistent with thetool_callorder inmessages 2.Source Authenticity Validation •source_text mustcompletely come fromthe original tool_response result of that specifictool_idround • Fabricated, spl...
-
[53]
•tools: List of available tools
Input Format You will receive a complete JSON containing: •images: Image paths. •tools: List of available tools. •messages: Complete multi-round dialogue of user / model / tool calls / tool returns. •solution: The model’s final output, withsentenceandprovenancetracing
-
[54]
Output Requirements Pleaseonly output the structured judgment result, in the following format: { "overall_correct": true/false, "error_details": [ "Error 1 description", "Error 2 description" ], "sentence_check": [ { "sentence_id": number, "tool_id_correct": true/false, "source_text_correct": true/false, "relation_correct": true/false, "sentence_correct":...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.