Recognition: no theorem link
An Iterative Test-and-Repair Framework for Competitive Code Generation
Pith reviewed 2026-05-10 19:41 UTC · model grok-4.3
The pith
FixAudit lets a single 7B model outperform 32B baselines in competitive code generation by iteratively auditing its own candidates for bugs and repairing them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
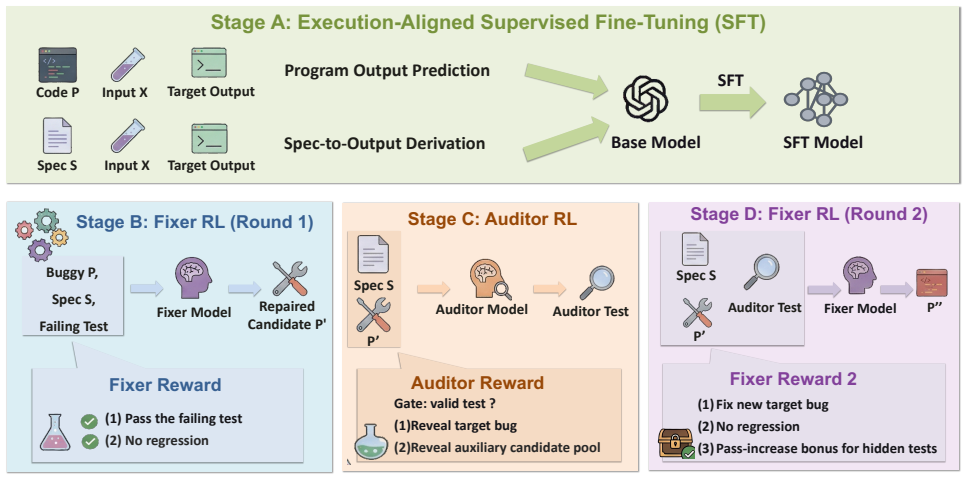
FixAudit approaches competitive code generation from a new perspective: starting from a single initial candidate, it iteratively improves the candidate through a targeted test-and-repair debugging cycle. The framework trains one shared model with two specialized roles through four stages: the Fixer, which repairs the current candidate based on a failing test, and the Auditor, which reads the candidate code to generate new tests that expose its remaining bugs. We evaluate FixAudit on three benchmarks: APPS, CodeContests, and xCodeEval. Applied to a 7B model, the framework surpasses the average performance of the larger 32B baseline within the same model family under the zero-shot setting.
What carries the argument
The iterative Auditor-Fixer cycle on a shared model, where the Auditor inspects candidate code to produce exposing tests and the Fixer edits the code using those failures.
If this is right
- A 7B model using the iterative cycle can exceed the average zero-shot performance of a 32B model in the same family on APPS, CodeContests, and xCodeEval.
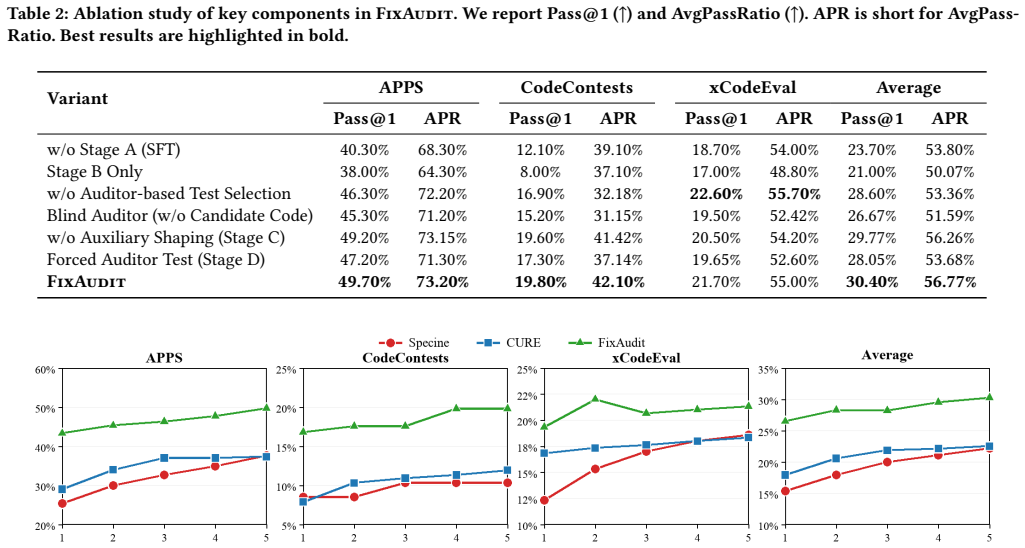
- Pass@1 scores improve 35.1 to 36.8 percent over strong baselines built on the identical 7B base model.
- AvgPassRatio improves between 7.1 and 24.5 percent over the same baselines.
- The model learns to repair existing candidates instead of regenerating every solution from scratch each time.
Where Pith is reading between the lines
- The approach trades model size for inference-time iteration, suggesting smaller models may suffice when self-audit loops are available.
- The same Auditor-Fixer pattern could be tested on non-code generation tasks that benefit from self-correction, such as mathematical proof writing.
- Because the Auditor sees the code, the generated tests may cover edge cases that human-written or description-only tests routinely miss.
Load-bearing premise
The Auditor can read the candidate code and produce tests that expose implementation-specific bugs missed by ordinary test suites, and the repair step then yields genuine fixes rather than overfitting to the model's own tests.
What would settle it
Running the 7B FixAudit model on a fresh competitive-programming benchmark and finding no gain, or a loss, in Pass@1 or AvgPassRatio relative to the 32B baseline from the same family.
Figures


read the original abstract
Large language models (LLMs) have made remarkable progress in code generation, but competitive programming remains a challenge. Recent training-based methods have improved code generation by using reinforcement learning (RL) with execution feedback. The more recent framework CURE further incorporates test generation into the training process, jointly training a Coder and a Tester within a single model. At inference time, the Coder generates many candidate programs, and the Tester generates tests from the problem description. The candidate who passes the most of the generated tests is selected as the final answer. However, CURE has two critical limitations. First, the Tester never reads any candidate code, so its tests often fail to expose implementation-specific bugs. Second, the Coder generates every candidate from scratch and never learns to fix a buggy program based on a failed test. To address these limitations, we propose FixAudit, which approaches competitive code generation from a new perspective: starting from a single initial candidate, it iteratively improves the candidate through a targeted test-and-repair debugging cycle. The framework trains one shared model with two specialized roles through four stages: the Fixer, which repairs the current candidate based on a failing test, and the Auditor, which reads the candidate code to generate new tests that expose its remaining bugs. We evaluate FixAudit on three benchmarks: APPS, CodeContests, and xCodeEval. Applied to a 7B model, the framework surpasses the average performance of the larger 32B baseline within the same model family under the zero-shot setting. Compared to strong baselines built on the same 7B base model, FixAudit improves average Pass@1 by 35.1% to 36.8% and average AvgPassRatio by 7.1% to 24.5%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FixAudit, an iterative test-and-repair framework for competitive code generation with LLMs. It addresses limitations in prior work like CURE by training a single model with specialized Fixer and Auditor roles across four stages: the Auditor generates tests by reading candidate code to expose implementation-specific bugs, and the Fixer learns repairs from failing tests. The approach starts from an initial candidate and iteratively improves it. Evaluations on APPS, CodeContests, and xCodeEval show a 7B model surpassing the average performance of a 32B baseline in the same family under zero-shot settings, with Pass@1 improvements of 35.1% to 36.8% and AvgPassRatio gains of 7.1% to 24.5% over strong same-size baselines.
Significance. If the results hold under rigorous controls, the work demonstrates that code-aware test generation combined with targeted repair can substantially boost smaller LLMs on competitive programming tasks, offering an alternative to model scaling. The shared-model multi-role training and iterative debugging cycle represent a practical advance in training methodologies for code generation, with potential for broader application in software engineering tasks requiring robustness to hidden tests.
major comments (3)
- [Experimental Evaluation] Experimental Evaluation section: The central performance claims (7B surpassing 32B baseline; 35.1–36.8% Pass@1 lift) are reported without details on run variance, number of trials, baseline implementation specifics (e.g., prompting for the 32B model), or statistical tests. This absence directly undermines assessment of whether the gains are robust or reproducible.
- [Training Methodology] Training Methodology (four-stage process): The Auditor reads candidate code to generate tests and the Fixer repairs based on failures, but the manuscript provides no description of data splits, negative sampling, or hold-out mechanisms to prevent the loop from rewarding patterns that pass self-generated tests without improving behavior on the benchmarks' independent hidden suites. This is load-bearing for the generalization claim.
- [Baseline Comparisons] Baseline Comparisons: The zero-shot claim that FixAudit on 7B exceeds the 32B model is central to the significance argument, yet the text lacks explicit controls for equivalent test usage, candidate sampling budgets, or prompt engineering differences between the 7B and 32B evaluations.
minor comments (2)
- [Abstract] Abstract: AvgPassRatio is used in the quantitative claims but is not defined or motivated in the abstract or early sections, which may hinder quick comprehension of the metric's meaning.
- [Introduction] Introduction: The motivation section could more explicitly contrast the proposed iterative cycle against CURE's non-iterative selection to clarify the novelty in the repair loop.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important areas for improving the rigor and reproducibility of our experimental claims. We address each point below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental Evaluation section: The central performance claims (7B surpassing 32B baseline; 35.1–36.8% Pass@1 lift) are reported without details on run variance, number of trials, baseline implementation specifics (e.g., prompting for the 32B model), or statistical tests. This absence directly undermines assessment of whether the gains are robust or reproducible.
Authors: We agree that these details are essential for assessing robustness. In the revised manuscript, we will report standard deviations across multiple independent runs (e.g., 5 seeds), specify the exact number of trials per experiment, provide the precise prompting templates and sampling parameters used for the 32B baseline, and include statistical significance tests (paired t-tests with p-values) comparing FixAudit against baselines. These additions will be placed in the Experimental Evaluation section and its associated tables. revision: yes
-
Referee: [Training Methodology] Training Methodology (four-stage process): The Auditor reads candidate code to generate tests and the Fixer repairs based on failures, but the manuscript provides no description of data splits, negative sampling, or hold-out mechanisms to prevent the loop from rewarding patterns that pass self-generated tests without improving behavior on the benchmarks' independent hidden suites. This is load-bearing for the generalization claim.
Authors: We recognize that explicit safeguards against self-test overfitting are critical. The current training uses benchmark-provided hidden test suites for final evaluation and incorporates negative examples from failed repairs, but the manuscript lacks a dedicated description. We will expand the Training Methodology section to detail the data splits (train/validation/hold-out), negative sampling procedure (sampling incorrect code-test pairs), and hold-out mechanisms that ensure the Auditor's tests are validated against independent suites before use in the loop. This clarification will directly support the generalization claims. revision: yes
-
Referee: [Baseline Comparisons] Baseline Comparisons: The zero-shot claim that FixAudit on 7B exceeds the 32B model is central to the significance argument, yet the text lacks explicit controls for equivalent test usage, candidate sampling budgets, or prompt engineering differences between the 7B and 32B evaluations.
Authors: We agree that fair comparison requires explicit controls. In revision, we will add a dedicated subsection under Baseline Comparisons that specifies: (1) identical test budgets and sampling strategies across models, (2) the exact number of candidates generated per problem for both 7B and 32B, and (3) standardized prompt templates with no additional engineering for the larger model. These controls will be documented to ensure the 7B vs. 32B comparison is equitable under zero-shot conditions. revision: yes
Circularity Check
No circularity; empirical performance on public benchmarks
full rationale
The paper describes a four-stage training process for a shared model with Fixer and Auditor roles, then reports direct empirical metrics (Pass@1, AvgPassRatio) on the public benchmarks APPS, CodeContests, and xCodeEval against external baselines. No equations, fitted parameters, or self-referential definitions appear in the derivation chain. Central claims rest on held-out test-suite execution rather than quantities that reduce to the model's own generated tests by construction. No self-citation load-bearing steps or uniqueness theorems are invoked. This matches the default case of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A single shared model can be effectively trained to perform both code repair and code-aware test generation roles without significant interference.
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. Program Synthesis with Large Language Models.arXiv preprint arXiv:2108.07732(2021). 10
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[3]
Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. 2023. CodeT: Code Generation with Generated Tests.The Eleventh International Conference on Learning Representations(2023)
2023
-
[4]
Junkai Chen, Zhiyuan Pan, Xing Hu, Zhenhao Li, Ge Li, and Xin Xia. 2025. Reasoning runtime behavior of a program with llm: How far are we?. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 1869–1881
2025
-
[6]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. 2024. Teaching Large Language Models to Self-Debug.The Twelfth International Conference on Learning Representations(2024)
2024
-
[8]
Yinghao Chen, Zehao Hu, Chen Zhi, Junxiao Han, Shuiguang Deng, and Jianwei Yin. 2024. ChatUniTest: A Framework for LLM-Based Test Generation. InCom- panion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering. 572–576
2024
-
[9]
Yangruibo Ding, Jinjun Peng, Marcus Min, Gail Kaiser, Junfeng Yang, and Baishakhi Ray. 2024. SemCoder: Training Code Language Models with Compre- hensive Semantics Reasoning.Advances in Neural Information Processing Systems 37 (2024), 60275–60308
2024
-
[10]
Yihong Dong, Xue Jiang, Zhi Jin, and Ge Li. 2024. Self-Collaboration Code Gener- ation via ChatGPT.ACM Transactions on Software Engineering and Methodology 33, 7 (2024), 1–38
2024
-
[11]
Shihan Dou, Yan Liu, Haoxiang Jia, Enyu Zhou, Limao Xiong, Junjie Shan, Caishuang Huang, Xiao Wang, Xiaoran Fan, Zhiheng Xi, et al. 2024. Stepcoder: improving code generation with reinforcement learning from compiler feedback. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 4571–4585
2024
-
[12]
Gordon Fraser and Andrea Arcuri. 2011. EvoSuite: Automatic Test Suite Gen- eration for Object-Oriented Software. InProceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engi- neering. 416–419
2011
- [13]
-
[14]
Alex Gu, Baptiste Rozière, Hugh Leather, Armando Solar-Lezama, Gabriel Syn- naeve, and Sida I Wang. 2024. Cruxeval: A benchmark for code reasoning, understanding and execution.arXiv preprint arXiv:2401.03065(2024)
work page internal anchor Pith review arXiv 2024
-
[15]
Siqi Gu, Chunrong Fang, Quanjun Zhang, Fangyuan Tian, and Zhenyu Chen
-
[16]
TestArt: Improving LLM-Based Unit Test via Co-Evolution of Automated Generation and Repair Iteration.arXiv e-prints(2024)
2024
-
[17]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, Y. K. Li, and et al. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming—The Rise of Code Intelligence. arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Qi Guo, Xiaofei Xie, Shangqing Liu, Ming Hu, Xiaohong Li, and Lei Bu. 2025. Intention is All You Need: Refining Your Code from Your Intention. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society
2025
-
[19]
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. 2021. Measuring Coding Challenge Competence With APPS. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2). https://openreview.net/forum?id=sD...
2021
-
[20]
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
Dong Huang, Qingwen Bu, Jie M. Zhang, Michael Luck, and Heming Cui. 2023. AgentCoder: Multi-Agent-Based Code Generation with Iterative Testing and Optimisation.arXiv preprint arXiv:2312.13010(2023)
work page internal anchor Pith review arXiv 2023
-
[21]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, and et al. 2024. Qwen2.5-Coder Tech- nical Report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Ashraful Islam, Mohammed Eunus Ali, and Md Rizwan Parvez
Md. Ashraful Islam, Mohammed Eunus Ali, and Md Rizwan Parvez. 2024. Map- Coder: Multi-Agent Code Generation for Competitive Problem Solving. InPro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers). 4912–4944
2024
-
[23]
Naman Jain, Skanda Vaidyanath, Arun Iyer, Nagarajan Natarajan, Suresh Parthasarathy, Sriram Rajamani, and Rahul Sharma. 2023. TiCoder: Teaching Code Generation with Test Inspections. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics
2023
-
[24]
Xue Jiang, Yihong Dong, Lecheng Wang, Zheng Fang, Qiwei Shang, Ge Li, Zhi Jin, and Wenpin Jiao. 2024. Self-Planning Code Generation with Large Language Models.ACM Transactions on Software Engineering and Methodology33, 7 (2024), 1–30
2024
-
[25]
Saiful Bari, Xuan Long Do, Weishi Wang, Md Rizwan Parvez, and Shafiq Joty
Mohammad Abdullah Matin Khan, M. Saiful Bari, Xuan Long Do, Weishi Wang, Md Rizwan Parvez, and Shafiq Joty. 2024. XCodeEval: An Execution-Based Large Scale Multilingual Multitask Benchmark for Code Understanding, Genera- tion, Translation and Retrieval. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Lo...
2024
-
[26]
Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven Chu Hong Hoi. 2022. Coderl: Mastering code generation through pretrained models and deep reinforcement learning.Advances in Neural Information Pro- cessing Systems35 (2022), 21314–21328
2022
-
[28]
Dacheng Li, Shiyi Cao, Chengkun Cao, Xiuyu Li, Shangyin Tan, Kurt Keutzer, Jiarong Xing, Joseph E. Gonzalez, and Ion Stoica. 2025. S*: Test Time Scaling for Code Generation.arXiv preprint arXiv:2502.14382(2025)
- [29]
-
[30]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Remi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, and et al
-
[31]
Competition-Level Code Generation with AlphaCode.Science378, 6624 (2022), 1092–1097
2022
-
[32]
Feng Lin, Dong Jae Kim, and Tse-Hsun (Peter) Chen. 2025. SOEN-101: Code Generation by Emulating Software Process Models Using Large Language Model Agents. In2025 IEEE/ACM 46th International Conference on Software Engineering (ICSE)
2025
-
[33]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation.Advances in Neural Information Processing Systems36 (2023), 21558–21572
2023
- [34]
- [35]
-
[36]
Fangwen Mu, Lin Shi, Song Wang, Zhuohao Yu, Binquan Zhang, ChenXue Wang, Shichao Liu, and Qing Wang. 2024. ClarifyGPT: A Framework for Enhancing LLM-Based Code Generation via Requirements Clarification.Proceedings of the ACM on Software Engineering1, FSE (2024), 2332–2354
2024
-
[37]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. 2025. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 20286–20332
2025
-
[38]
Aniyan Ni, Pengcheng Yin, Yu Su, and Xiaodong Yin. 2023. LEVER: Learning to Verify Language-to-Code Generation with Execution. InInternational Conference on Machine Learning
2023
-
[39]
Olausson, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao, and Armando Solar-Lezama
Theo X. Olausson, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao, and Armando Solar-Lezama. 2024. Is Self-Repair a Silver Bullet for Code Generation?. InThe Twelfth International Conference on Learning Representations
2024
-
[40]
OpenAI. 2024. Hello GPT-4o. https://openai.com/index/hello-gpt-4o/
2024
-
[41]
Carlos Pacheco and Michael D. Ernst. 2007. Randoop: Feedback-Directed Random Testing for Java. InCompanion to the 22nd ACM SIGPLAN Conference on Object- Oriented Programming Systems and Applications Companion. 815–816
2007
- [42]
-
[43]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[44]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300(2024). doi:10.48550/arXiv.2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[46]
Jianjian Sheng et al. 2024. veRL: Volcano Engine Reinforcement Learning for LLM. https://github.com/volcengine/verl
2024
-
[47]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, Vol. 36
2023
- [48]
-
[49]
Benjamin Steenhoek, Michele Tufano, Neel Sundaresan, and Alexey Svyatkovskiy
-
[50]
In2024 IEEE/ACM International Workshop on Deep Learning for Testing and Testing for Deep Learning (DeepTest)
Reinforcement Learning from Automatic Feedback for High-Quality Unit Test Generation. In2024 IEEE/ACM International Workshop on Deep Learning for Testing and Testing for Deep Learning (DeepTest)
-
[51]
Qwen Team. 2025. QwQ-32B: Embracing the Power of Reinforcement Learning. https://qwenlm.github.io/blog/qwq-32b/
2025
-
[52]
Zhao Tian and Junjie Chen. 2026. Aligning Requirement for Large Language Model’s Code Generation. In2026 IEEE/ACM 48th International Conference on Software Engineering (ICSE ’26). doi:10.1145/3744916.3764572
-
[53]
Zhao Tian, Junjie Chen, and Xiangyu Zhang. 2025. Fixing Large Language Models’ Specification Misunderstanding for Better Code Generation. In2025 IEEE/ACM 46th International Conference on Software Engineering (ICSE)
2025
- [54]
- [55]
- [56]
-
[57]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.14476 2025
-
[59]
Huan Zhang, Wei Cheng, Yuhan Wu, and Wei Hu. 2024. A Pair Programming Framework for Code Generation via Multi-Plan Exploration and Feedback-Driven Refinement. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1319–1331
2024
- [60]
- [61]
-
[62]
Kechi Zhang, Ge Li, Jia Li, Hu Zhu, and Zhi Jin. 2023. Self-Edit: Fault-Aware Code Editor for Code Generation. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics
2023
-
[63]
Tenenbaum, and Chuang Gan
Shun Zhang, Zhenfang Chen, Yikang Shen, Mingyu Ding, Joshua B. Tenenbaum, and Chuang Gan. 2023. Planning with Large Language Models for Code Genera- tion. InThe Eleventh International Conference on Learning Representations
2023
-
[64]
Li Zhong, Zilong Wang, and Weiyi Shang. 2024. Debug like a Human: A Large Language Model Debugger via Verifying Runtime Execution Step by Step. In Findings of the Association for Computational Linguistics: ACL 2024. 12
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.