Recognition: 1 theorem link
· Lean TheoremEvaluation of Randomization through Style Transfer for Enhanced Domain Generalization
Pith reviewed 2026-05-10 18:50 UTC · model grok-4.3
The pith
Larger pools of diverse artistic styles in style transfer improve domain generalization more than repeating few styles or using complex textures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
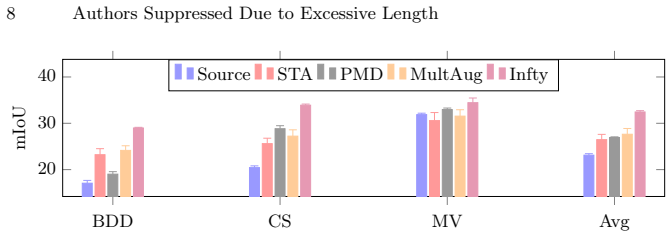
Expanding the style pool in style-transfer augmentation produces larger gains than repeated use of a small set of styles; once the pool is large, texture complexity of the styles no longer matters; and artistic styles drawn from diverse sources outperform styles aligned with the target domain. These three findings are used to construct StyleMixDG, a lightweight augmentation recipe that requires no architectural changes and yields consistent gains over strong baselines on the GTAV-to-real benchmark across BDD100k, Cityscapes, and Mapillary Vistas.
What carries the argument
StyleMixDG, a model-agnostic recipe that mixes training images with styles sampled from a large pool of diverse artistic images.
If this is right
- Training with a large style pool will produce models that generalize better to new real-world domains than training with repeated use of few styles.
- Texture complexity can be deprioritized once style diversity is high enough.
- Artistic style sources should be chosen over domain-aligned sources for augmentation.
- StyleMixDG improves performance on multiple real target datasets without modifying the model or adding losses.
- The same augmentation can be dropped into existing training pipelines for scene understanding tasks.
Where Pith is reading between the lines
- The same emphasis on style diversity could be tested in other augmentation families such as geometric or photometric transforms.
- Because the method adds no parameters, it may combine additively with existing domain-generalization regularizers.
- If the pool-size effect holds, curating larger public style libraries would become a higher-leverage activity than designing new style-transfer networks.
Load-bearing premise
The three tested factors drive most of the performance difference and the resulting recipe will transfer to other datasets and network architectures.
What would settle it
Applying StyleMixDG to a different synthetic-to-real benchmark or backbone and observing no improvement over baselines, or seeing texture complexity regain importance, would falsify the central claims.
Figures



read the original abstract
Deep learning models for computer vision often suffer from poor generalization when deployed in real-world settings, especially when trained on synthetic data due to the well-known Sim2Real gap. Despite the growing popularity of style transfer as a data augmentation strategy for domain generalization, the literature contains unresolved contradictions regarding three key design axes: the diversity of the style pool, the role of texture complexity, and the choice of style source. We present a systematic empirical study that isolates and evaluates each of these factors for driving scene understanding, resolving inconsistencies in prior work. Our findings show that (i) expanding the style pool yields larger gains than repeated augmentation with few styles, (ii) texture complexity has no significant effect when the pool is sufficiently large, and (iii) diverse artistic styles outperform domain-aligned alternatives. Guided by these insights, we derive StyleMixDG (Style-Mixing for Domain Generalization), a lightweight, model-agnostic augmentation recipe that requires no architectural modifications or additional losses. Evaluated on the GTAV $\rightarrow$ {BDD100k, Cityscapes, Mapillary Vistas} benchmark, StyleMixDG demonstrates consistent improvements over strong baselines, confirming that the empirically identified design principles translate into practical gains. The code will be released on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts a systematic empirical study isolating three design factors in style-transfer data augmentation for domain generalization in semantic segmentation: style pool size, texture complexity, and style source. It resolves prior contradictions by showing that larger pools outperform repeated use of few styles, texture complexity loses significance with large pools, and artistic styles beat domain-aligned ones. From these, the authors derive StyleMixDG, a lightweight model-agnostic augmentation recipe, and report consistent gains over baselines on the GTAV to {BDD100k, Cityscapes, Mapillary Vistas} benchmark. Code release is promised.
Significance. If the results hold, the work supplies actionable empirical guidelines for style-transfer augmentation in DG and a simple recipe that avoids architectural changes or extra losses. The explicit isolation of factors and the commitment to code release are strengths that support reproducibility and practical adoption. The findings could help standardize augmentation choices in Sim2Real settings, though their broader impact depends on validation beyond the single benchmark family examined.
major comments (2)
- [Experimental Evaluation] Abstract and Experimental Evaluation: the central claim that the three isolated factors are dominant drivers and that StyleMixDG generalizes relies on results from only the GTAV→real shift family with specific architectures; no results on other domain gaps (adverse weather, sensor variation, or cross-dataset shifts) or additional backbones are shown, leaving the transferability of the design principles unverified.
- [Results and Ablations] Results and Ablations: the assertions of 'consistent improvements' and 'no significant effect' of texture complexity require explicit statistical tests, standard deviations over multiple seeds, and full ablation tables with baseline details; without these, the support for the three findings and the derived recipe cannot be fully assessed.
minor comments (2)
- [Abstract] Abstract: the three key design axes are introduced only through the findings rather than being enumerated upfront, which reduces immediate clarity.
- [Discussion] The manuscript would benefit from a dedicated limitations paragraph discussing the scope of the GTAV benchmark and potential interactions with implementation details of the style-transfer model.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, providing clarifications on our experimental design choices and committing to improvements in statistical reporting and discussion of limitations.
read point-by-point responses
-
Referee: [Experimental Evaluation] Abstract and Experimental Evaluation: the central claim that the three isolated factors are dominant drivers and that StyleMixDG generalizes relies on results from only the GTAV→real shift family with specific architectures; no results on other domain gaps (adverse weather, sensor variation, or cross-dataset shifts) or additional backbones are shown, leaving the transferability of the design principles unverified.
Authors: We appreciate the referee's point on the scope of evaluation. Our work centers on the GTAV→real benchmark family because it is the established and most commonly used setting for studying Sim2Real domain generalization in driving scene semantic segmentation, enabling direct comparisons with prior style-transfer methods and controlled isolation of the three design factors. While we agree that results on additional shifts (e.g., adverse weather or sensor variation) and backbones would further support broader transferability, such extensions fall outside the focused scope of this study, which prioritizes rigorous ablation of style-pool size, texture complexity, and style source. In the revised manuscript we will expand the discussion and limitations sections to explicitly note this scope and outline future validation directions. revision: partial
-
Referee: [Results and Ablations] Results and Ablations: the assertions of 'consistent improvements' and 'no significant effect' of texture complexity require explicit statistical tests, standard deviations over multiple seeds, and full ablation tables with baseline details; without these, the support for the three findings and the derived recipe cannot be fully assessed.
Authors: We agree that stronger statistical support will improve the reliability and assessability of the reported findings. The current version presents mean performance values across the three target datasets, but we will revise the results and ablation sections to include: (i) full tables with all baseline configurations and implementation details, (ii) standard deviations computed over multiple random seeds (at least three), and (iii) explicit statistical significance tests (e.g., paired t-tests) for the key comparisons involving style-pool size and texture complexity. These additions will be incorporated in the revised manuscript. revision: yes
Circularity Check
Purely empirical evaluation with no derivation chain or self-referential reductions
full rationale
The manuscript conducts a systematic empirical study that isolates three design factors (style-pool size, texture complexity, style source) via controlled experiments on the GTAV→real benchmark, reports comparative performance numbers, and assembles an augmentation recipe (StyleMixDG) from the observed rankings. No equations, fitted parameters, uniqueness theorems, or self-citations are invoked as load-bearing steps in any derivation; the central claims rest directly on the reported experimental outcomes rather than reducing to prior inputs by construction. This is the expected non-circular outcome for an ablation-driven empirical paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- style pool size
axioms (1)
- domain assumption Style transfer operations preserve semantic content sufficiently for scene-understanding tasks.
Reference graph
Works this paper leans on
-
[1]
Pattern Recognition 156(2024)
Angarano, S., Martini, M., Salvetti, F., Mazzia, V., Chiaberge, M.: Back-to-bones: Rediscovering the role of backbones in domain generalization. Pattern Recognition 156(2024)
2024
-
[2]
In: ICPR (2021)
Borlino, F.C., D’Innocente, A., Tommasi, T.: Rethinking domain generalization baselines. In: ICPR (2021)
2021
-
[3]
In: ROSENET (2024)
Cakir, D., Arica, N.: Style transfer to enhance data augmentation for facial action unit detection. In: ROSENET (2024)
2024
-
[4]
IEEE TPAMI (2018)
Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: Se- mantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE TPAMI (2018)
2018
-
[5]
Rethinking Atrous Convolution for Semantic Image Segmentation
Chen, L.C., Papandreou, G., Schroff, F., Adam, H.: Rethinking atrous convolution for semantic image segmentation. arXiv preprint:1706.05587 (2017)
work page internal anchor Pith review arXiv 2017
-
[6]
https://github.com/open-mmlab/mmsegmentation (2020)
Contributors, M.: MMSegmentation: Openmmlab semantic segmentation toolbox and benchmark. https://github.com/open-mmlab/mmsegmentation (2020)
2020
-
[7]
In: CVPR (2016)
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: CVPR (2016)
2016
-
[8]
In: CVPR (2009) 12 Authors Suppressed Due to Excessive Length
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: A Large- Scale Hierarchical Image Database. In: CVPR (2009) 12 Authors Suppressed Due to Excessive Length
2009
-
[9]
https://kaggle.com/ competitions/painter-by-numbers (2016), kaggle
small yellow duck, Kan, W.: Painter by numbers. https://kaggle.com/ competitions/painter-by-numbers (2016), kaggle
2016
-
[10]
IJCV (2015)
Everingham, M., Eslami, S.M.A., Van Gool, L., Williams, C.K.I., Winn, J., Zisser- man, A.: The pascal visual object classes challenge: A retrospective. IJCV (2015)
2015
-
[11]
In: CVPR (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
2016
-
[12]
In: CVPR (2021)
Hong, M., Choi, J., Kim, G.: Stylemix: Separating content and style for enhanced data augmentation. In: CVPR (2021)
2021
-
[13]
In: CVPR (2022)
Hoyer, L., Dai, D., Van Gool, L.: Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation. In: CVPR (2022)
2022
-
[14]
In: ICCV (2017)
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: ICCV (2017)
2017
-
[15]
IEEE TVCG (2020)
Jing, Y., Yang, Y., Feng, Z., Ye, J., Yu, Y., Song, M.: Neural style transfer: A review. IEEE TVCG (2020)
2020
-
[16]
In: ICRA (2023)
Kim, N.,Son,T.,Pahk,J.,Lan,C.,Zeng,W.,Kwak,S.:Wedge:web-imageassisted domain generalization for semantic segmentation. In: ICRA (2023)
2023
-
[17]
In: CVPR (2022)
Lee,S.,Seong,H.,Lee,S.,Kim,E.:Wildnet:Learningdomaingeneralizedsemantic segmentation from the wild. In: CVPR (2022)
2022
-
[18]
In: WACV (2023)
Li, Y., Zhang, D., Keuper, M., Khoreva, A.: Intra-source style augmentation for improved domain generalization. In: WACV (2023)
2023
-
[19]
In: ICCV (2017)
Neuhold, G., Ollmann, T., Rota Bulo, S., Kontschieder, P.: The mapillary vistas dataset for semantic understanding of street scenes. In: ICCV (2017)
2017
-
[20]
In: WACV (2024)
Niemeijer, J., Schwonberg, M., Termöhlen, J.A., Schmidt, N.M., Fingscheidt, T.: Generalization by adaptation: Diffusion-based domain extension for domain- generalized semantic segmentation. In: WACV (2024)
2024
-
[21]
In: CVPR (2022)
Peng, D., Lei, Y., Hayat, M., Guo, Y., Li, W.: Semantic-aware domain generalized segmentation. In: CVPR (2022)
2022
-
[22]
IEEE TIP (2021)
Peng,D.,Lei,Y.,Liu,L.,Zhang,P.,Liu,J.:Globalandlocaltexturerandomization for synthetic-to-real semantic segmentation. IEEE TIP (2021)
2021
-
[23]
In: ECCV (2016)
Richter, S.R., Vineet, V., Roth, S., Koltun, V.: Playing for data: Ground truth from computer games. In: ECCV (2016)
2016
-
[24]
arXiv preprint:2006.11207 (2020)
Somavarapu, N., Ma, C.Y., Kira, Z.: Frustratingly simple domain generalization via image stylization. arXiv preprint:2006.11207 (2020)
-
[25]
In: ICML (2021)
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jegou, H.: Training data-efficient image transformers & distillation through attention. In: ICML (2021)
2021
-
[26]
In: ECCV (2018)
Xiao, T., Liu, Y., Zhou, B., Jiang, Y., Sun, J.: Unified perceptual parsing for scene understanding. In: ECCV (2018)
2018
-
[27]
arXiv preprint:2504.10563 (2025)
Yang, Q., Ji, C., Luo, H., Li, P., Ding, Z.: Data augmentation through random style replacement. arXiv preprint:2504.10563 (2025)
-
[28]
In: CVPR (2020)
Yu, F., Chen, H., Wang, X., Xian, W., Chen, Y., Liu, F., Madhavan, V., Darrell, T.: Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In: CVPR (2020)
2020
-
[29]
In: ICCV (2019)
Yue, X., Zhang, Y., Zhao, S., Sangiovanni-Vincentelli, A., Keutzer, K., Gong, B.: Domain randomization and pyramid consistency: Simulation-to-real generalization without accessing target domain data. In: ICCV (2019)
2019
-
[30]
In: IEEE SSCI (2020)
Zhao, W., Queralta, J.P., Westerlund, T.: Sim-to-real transfer in deep reinforce- ment learning for robotics: a survey. In: IEEE SSCI (2020)
2020
-
[31]
Zheng, X., Chalasani, T., Ghosal, K., Lutz, S., Smolic, A.: Stada: Style transfer as data augmentation. In: VISIGRAPP (2019) Evaluation of Randomization through Style Transfer 13 A Implementation Details A.1 Style T ransfer Augmentation We use the style transfer implementation and pre-trained networks from https: //github.com/naoto0804/pytorch-AdaIN. We o...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.