Recognition: no theorem link
YoNER: A New Yor\`ub\'a Multi-domain Named Entity Recognition Dataset
Pith reviewed 2026-05-10 20:03 UTC · model grok-4.3
The pith
A new multi-domain Yorùbá NER dataset shows African-centric models outperform general multilingual ones but cross-domain transfer drops sharply.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
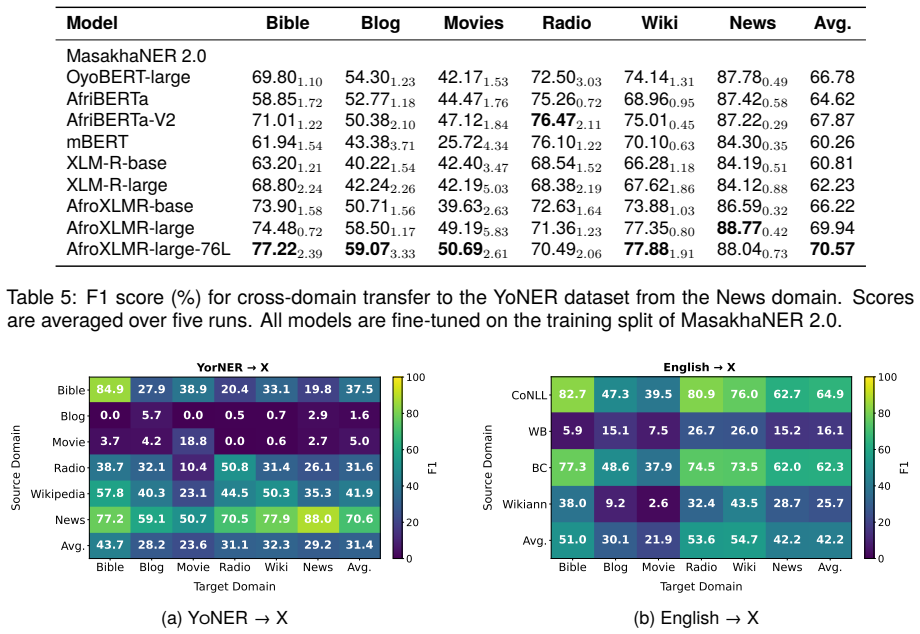
We present YoNER, a new multidomain Yorùbá NER dataset of about 5,000 sentences and 100,000 tokens from Bible, Blogs, Movies, Radio broadcast and Wikipedia domains, manually annotated by native speakers with over 0.70 inter-annotator agreement for PER, ORG and LOC following CoNLL guidelines. Cross-domain benchmarks with MasakhaNER 2.0 show African-centric models outperform general multilingual models for Yorùbá while cross-domain performance drops substantially, particularly for blogs and movie domains, with better transfer between closely related formal domains; OyoBERT is introduced and outperforms multilingual models in in-domain evaluation.
What carries the argument
The YoNER multi-domain corpus together with the OyoBERT Yorùbá-specific language model, which together enable the cross-domain and in-domain benchmarking experiments.
If this is right
- African-centric models should be selected over general multilingual models when performing NER on Yorùbá text.
- Transfer works more reliably between closely related formal domains such as news and Wikipedia than between formal and informal domains.
- Few-shot addition of in-domain YoNER data improves results but does not fully close gaps in cross-lingual English setups.
- Public release of the dataset and OyoBERT models will allow direct reuse for further Yorùbá NLP experiments.
Where Pith is reading between the lines
- Domain-adaptation techniques may be needed to handle the larger performance drops seen in informal domains like blogs and movies.
- The same multi-domain construction approach could be replicated for other low-resource African languages to check whether similar transfer patterns appear.
- OyoBERT could be tested on additional Yorùbá tasks such as part-of-speech tagging or machine translation.
Load-bearing premise
The five chosen domains and 5,000 sentences are representative enough of real Yorùbá usage that the observed performance patterns will hold more broadly.
What would settle it
Annotating and testing a substantially larger Yorùbá NER corpus drawn from additional domains and finding that general multilingual models match or exceed African-centric models in both in-domain and cross-domain accuracy would falsify the reported superiority.
Figures

read the original abstract
Named Entity Recognition (NER) is a foundational NLP task, yet research in Yor\`ub\'a has been constrained by limited and domain-specific resources. Existing resources, such as MasakhaNER (a manually annotated news-domain corpus) and WikiAnn (automatically created from Wikipedia), are valuable but restricted in domain coverage. To address this gap, we present YoNER, a new multidomain Yor\`ub\'a NER dataset that extends entity coverage beyond news and Wikipedia. The dataset comprises about 5,000 sentences and 100,000 tokens collected from five domains including Bible, Blogs, Movies, Radio broadcast and Wikipedia, and annotated with three entity types: Person (PER), Organization (ORG) and Location (LOC), following CoNLL-style guidelines. Annotation was conducted manually by three native Yor\`ub\'a speakers, with an inter-annotator agreement of over 0.70, ensuring high quality and consistency. We benchmark several transformer encoder models using cross-domain experiments with MasakhaNER 2.0, and we also assess the effect of few-shot in-domain data using YoNER and cross-lingual setups with English datasets. Our results show that African-centric models outperform general multilingual models for Yor\`ub\'a, but cross-domain performance drops substantially, particularly for blogs and movie domains. Furthermore, we observed that closely related formal domains, such as news and Wikipedia, transfer more effectively. In addition, we introduce a new Yor\`ub\'a-specific language model (OyoBERT) that outperforms multilingual models in in-domain evaluation. We publicly release the YoNER dataset and pretrained OyoBERT models to support future research on Yor\`ub\'a natural language processing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces YoNER, a new multi-domain Yorùbá NER dataset of ~5,000 sentences and 100k tokens from five domains (Bible, Blogs, Movies, Radio broadcast, Wikipedia), manually annotated by three native speakers for PER, ORG, and LOC entities following CoNLL guidelines with reported aggregate IAA >0.70. It benchmarks transformer models in cross-domain setups with MasakhaNER 2.0, few-shot in-domain, and cross-lingual English experiments, claiming that African-centric models outperform general multilingual models, cross-domain F1 drops substantially (especially blogs/movies), formal domains transfer better, and a new Yorùbá-specific model OyoBERT outperforms multilingual baselines in in-domain evaluation. The dataset and OyoBERT are released publicly.
Significance. If the central claims hold, this work provides a valuable public resource for Yorùbá NLP research by extending beyond news and Wikipedia domains, and demonstrates the utility of language-specific pretraining. The release of both the dataset and OyoBERT models is a concrete strength that supports reproducibility and future work on low-resource African languages.
major comments (2)
- [Annotation] Annotation section: The inter-annotator agreement is reported only as an aggregate value >0.70 with no per-domain breakdown, no per-entity-type scores, and no description of disagreement resolution. This directly undermines the central claim that 'cross-domain performance drops substantially, particularly for blogs and movie domains,' because informal domains are more prone to code-switching, non-standard orthography, and ambiguous spans; without domain-specific IAA evidence, the observed F1 drops cannot be confidently attributed to domain shift rather than annotation noise.
- [Results] Experimental results and benchmarking sections: No error bars, confidence intervals, or standard deviations are provided on any F1 scores, and the abstract (and presumably the methods) gives no details on train/dev/test split sizes or stratification per domain. These omissions are load-bearing for the claims that African-centric models outperform multilingual ones and that OyoBERT is superior in in-domain evaluation, as the magnitude and reliability of the reported differences cannot be assessed.
minor comments (2)
- [Abstract and Dataset Description] The abstract states 'about 5,000 sentences' and '100,000 tokens'; the main text should report exact counts and per-domain statistics for transparency.
- [Introduction] The paper should clarify whether the five domains were chosen to be representative of Yorùbá usage or based on data availability, and include any discussion of potential biases in domain selection.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Annotation] Annotation section: The inter-annotator agreement is reported only as an aggregate value >0.70 with no per-domain breakdown, no per-entity-type scores, and no description of disagreement resolution. This directly undermines the central claim that 'cross-domain performance drops substantially, particularly for blogs and movie domains,' because informal domains are more prone to code-switching, non-standard orthography, and ambiguous spans; without domain-specific IAA evidence, the observed F1 drops cannot be confidently attributed to domain shift rather than annotation noise.
Authors: We agree that domain-specific and entity-type IAA scores, along with details on disagreement resolution, would provide stronger support for attributing performance differences to domain shift rather than annotation quality. We will add a table with per-domain and per-entity IAA breakdowns in the revised annotation section and describe the disagreement resolution process used by the three annotators. This will help substantiate the claims regarding cross-domain drops, especially in blogs and movies. revision: yes
-
Referee: [Results] Experimental results and benchmarking sections: No error bars, confidence intervals, or standard deviations are provided on any F1 scores, and the abstract (and presumably the methods) gives no details on train/dev/test split sizes or stratification per domain. These omissions are load-bearing for the claims that African-centric models outperform multilingual ones and that OyoBERT is superior in in-domain evaluation, as the magnitude and reliability of the reported differences cannot be assessed.
Authors: We acknowledge that reporting variability measures and split details is necessary to assess the reliability of the performance differences. In the revised manuscript, we will include standard deviations (from multiple runs with different seeds) or confidence intervals for all reported F1 scores in the results tables. We will also expand the methods section to specify the exact train/dev/test split sizes per domain and the stratification procedure used. revision: yes
Circularity Check
No circularity: new dataset and model introduction with empirical benchmarks only.
full rationale
The paper presents YoNER as a newly collected and annotated multi-domain NER dataset (5k sentences across Bible, Blogs, Movies, Radio, Wikipedia) and introduces OyoBERT as a new Yorùbá-specific pretrained model. All reported results are direct empirical outcomes from annotation, fine-tuning, and cross-domain evaluation against MasakhaNER 2.0 and English data; no equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The inter-annotator agreement (>0.70) and domain-shift observations are stated as measurements, not derived quantities that loop back to author-defined inputs by construction. This is a standard resource paper whose central claims rest on external data collection rather than internal definitional reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CoNLL-style annotation guidelines for PER/ORG/LOC entities are appropriate and sufficient for Yoruba text.
Reference graph
Works this paper leans on
-
[1]
Introduction Named Entity Recognition (NER) is a foundational NLP task that identifies and classifies named enti- ties (e.g. personal name, organizations, locations) in text with several applications in information ex- traction, question answering, and speech recogni- tion ( Tjong Kim Sang and De Meulder , 2003; Ya- mada et al. , 2020; Caubrière et al. , ...
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[2]
Related Work NER for low-resource languages has recently gained growing attention as the development of multilingual models such as mBERT ( Devlin et al. ,
-
[3]
, 2020) has en- abled effective transfer learning across languages
and XLM-R ( Conneau et al. , 2020) has en- abled effective transfer learning across languages. Traditional NER systems relied heavily on large annotated datasets, which are scarce for most low-resource languages. Multilingual pre-trained language models have helped bridge this gap by transferring knowledge from high-resource lan- guages to creating compet...
2020
-
[4]
Data Collection We compiled Yorùbá texts from five domains, aim- ing for varied style and content
Corpus Curation for YONER 3.1. Data Collection We compiled Yorùbá texts from five domains, aim- ing for varied style and content. We focused on popular domains covered in previous works such as OntoNotes and WikiAnn: Bible, Blog, Radio, Wikipedia, Movie. For the two domains, movies and radio, with which we were less familiar, we collaborated with a Yoruba...
2018
-
[5]
How well does News NER data transfer to diverse do- mains?,
Experimental Setup Given the created YONER dataset, in this section we outline our experimental setup designed to an- swer the research questions posed earlier. 4.1. Cross-Domain Transfer of News NER To address the first research question, “ How well does News NER data transfer to diverse do- mains?,” we trained NER models on data from the News domain and...
2022
-
[6]
We then proceed to ad- dress the research questions outlined earlier
Result and Discussion In this section, we present the results of our exper- iments, beginning with the evaluation of the newly created PLMs for Yorùbá. We then proceed to ad- dress the research questions outlined earlier. 5.1. How well does OyoBERT perform on wide range of tasks? Here, we compared the performance of the newly trained Yorùbá BERT models (Y...
2021
-
[7]
, 2024) covering 11, 20 and 76 languages respectively in- cluding Yorùbá
and AfroXLMR-76L ( Adelani et al. , 2024) covering 11, 20 and 76 languages respectively in- cluding Yorùbá. We evaluated on six representative NLP eval- uation data including SIB-200 ( Adelani et al. ,
2024
-
[8]
(a topic classification dataset to catego- rize sentences), MasakhaNEWS ( Adelani et al. ,
-
[9]
, 2023) (a Twitter sentiment classification dataset), Nolly- Senti ( Shode et al
(a news topic classification to categorize news articles), AfriSenti ( Muhammad et al. , 2023) (a Twitter sentiment classification dataset), Nolly- Senti ( Shode et al. , 2023) (a movie sentiment clas- sification dataset), MasakhaNER ( Adelani et al. ,
2023
-
[10]
(for NER), and MasakhaPOS ( Dione et al. ,
-
[11]
T able 4 shows the average evaluation of Oy- oBERT on six tasks
(for part-of-speech tagging). T able 4 shows the average evaluation of Oy- oBERT on six tasks. First observation is that it outperform the YoBERT with about +3 points, this shows the benefit of more data, specifically synthetic data generated by MT models. Unsur- prisingly, the larger OyoBERT-large achieved bet- ter results than the OyoBERT-base. When com...
-
[12]
Our results show that for both OyoBERT and AfroXLMR-large, the ORG entity type consis- tently has the lowest F1 score
Which entity types do models tend to perform poorly on? To answer this question, we examined the en- tity type F1 scores for the multidomain models described in Section 5.5 and presented in T a- ble 8. Our results show that for both OyoBERT and AfroXLMR-large, the ORG entity type consis- tently has the lowest F1 score. Furthermore, for the Bible and Movie...
-
[13]
Conclusion In this paper, we introduce YONER, a multi-domain human annotated NER dataset Yorùbá that ex- tends entity coverage beyond news and Wikipedia. The dataset comprises about 5,000 sentences and 100,000 tokens collected from five domains including Bible, Blogs, Movies, Radio broadcast, and Wikipedia, and annotating them for person, organization, an...
2021
-
[14]
Three of these domains contain little to no ORG entities due to their nature, and none include DA TE entities
Limitation In this paper, we introduce YONER, a moderately large multi-domain NER dataset covering five do- mains. Three of these domains contain little to no ORG entities due to their nature, and none include DA TE entities. We hope that future work can ex- tend YONER to additional domains and a broader range of entity types. We did not evaluate large la...
-
[15]
Acknowledgment David Adelani acknowledges the funding of Nat- ural Sciences and Engineering Research Council (NSERC) of Canada, IVADO and the Canada First Research Excellence Fund
-
[16]
Bibliographical References David Ifeoluwa Adelani, Jade Abbott, Graham Neubig, Daniel D’souza, Julia Kreutzer, Con- stantine Lignos, Selasi Osei, et al. 2021. Masakhaner: Named entity recognition for african languages. T ransactions of the Asso- ciation for Computational Linguistics , 9:1116– 1131. David Ifeoluwa Adelani, Hannah Liu, Xiaoyu Shen, Nikita V...
-
[17]
No Language Left Behind: Scaling Human-Centered Machine Translation
Where are we in named entity recognition from speech? In Proceedings of the T welfth Lan- guage Resources and Evaluation Conference , pages 4514–4520, Marseille, France. European Language Resources Association. Sarkar Snigdha Sarathi Das, Arzoo Katiyar, Re- becca Passonneau, and Rui Zhang. 2022a. CONT aiNER: Few-shot named entity recogni- tion via contras...
work page internal anchor Pith review arXiv 2021
-
[18]
arXiv preprint arXiv:2412.09587
Openner 1.0: Standardized open-access named entity recognition datasets in 50+ lan- guages. arXiv preprint arXiv:2412.09587 . Sampo Pyysalo, Jenna Kanerva, Antti Virtanen, and Filip Ginter. 2021. WikiBERT models: Deep transfer learning for many languages . In Pro- ceedings of the 23rd Nordic Conference on Com- putational Linguistics (NoDaLiDa) , pages 1–1...
-
[19]
Language Resource References Adelani, David Ifeoluwa and Abbott, Jade and Neu- big, Graham and D’souza, Daniel and Kreutzer, Julia and Lignos, Constantine and Palen-Michel, Chester and Buzaaba, Happy and Rijhwani, Shruti and Ruder, Sebastian and Mayhew, Stephen and Azime, Israel Abebe and Muham- mad, Shamsuddeen H. and Emezue, Chris Chi- nenye and Nakatum...
-
[20]
MIT Press
MasakhaNER: Named Entity Recognition for African Languages . MIT Press. Adelani, David Ifeoluwa and Liu, Hannah and Shen, Xiaoyu and Vassilyev, Nikita and Alabi, Jesujoba O. and Mao, Yanke and Gao, Haonan and Lee, En-Shiun Annie. 2024. SIB-200: A Simple, Inclusive, and Big Evaluation Dataset for T opic Classification in 200+ Languages and Dialects. Associ...
2024
-
[21]
Adapting Pre-trained Language Models to African Languages via Multilingual Adaptive Fine-T uning. Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzmán, Francisco and Grave, Edouard and Ott, Myle and Zettle- moyer, Luke and Stoyanov, Veselin. 2020. Unsu- pervised Cross-lingual Representation Lear...
2020
-
[22]
Associa- tion for Computational Linguistics
Small Data? No Problem! Exploring the Viability of Pretrained Multilingual Language Models for Low-resourced Languages. Associa- tion for Computational Linguistics. Oladipo, Akintunde. 2024. Scaling pre-training data and language models for african languages. University of Waterloo. Wuraola Fisayo Oyewusi, Olubayo Adekanmbi, Ifeoma Okoh, Vitus Onuigwe, Ma...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.