Recognition: no theorem link
Probing Intrinsic Medical Task Relationships: A Contrastive Learning Perspective
Pith reviewed 2026-05-10 19:50 UTC · model grok-4.3
The pith
A contrastive learning framework embeds 30 medical vision tasks from many modalities into one space to reveal their relationships.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
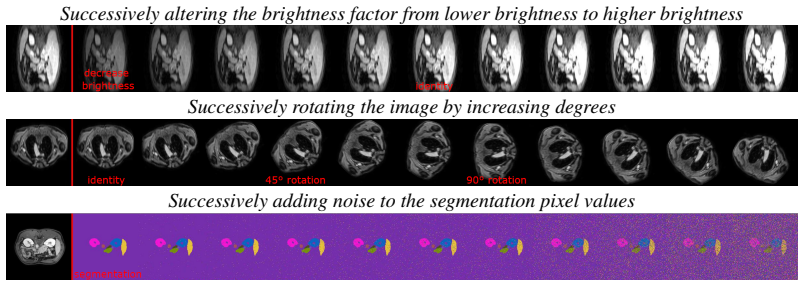
Task-Contrastive Learning (TaCo) maps heterogeneous medical vision tasks from different modalities into a joint embedding space. Analysis of this space shows which tasks are distinctly represented, which blend together, and how iterative alterations to tasks produce corresponding changes in their embedding positions.
What carries the argument
Task-Contrastive Learning (TaCo), a contrastive learning framework that embeds entire tasks rather than individual images into a shared representation space.
If this is right
- Tasks with close embeddings can be treated as related for purposes of multi-task model design.
- Quantitative distances in the space provide a way to measure similarity between tasks defined differently.
- The embedding allows comparison of tasks even when their source images come from unrelated modalities.
- Iterative task changes being visible as shifts suggests the space can track fine differences in task definition.
Where Pith is reading between the lines
- Task embeddings could be used to rank which pairs of tasks would benefit most from joint training.
- The same probing technique might expose task structures in non-medical image domains.
- Blended task groups could motivate creation of hybrid models that handle multiple similar tasks at once.
Load-bearing premise
The contrastive embedding space captures genuine intrinsic relationships among tasks rather than patterns tied to specific datasets or training choices.
What would settle it
Re-training TaCo on a fresh set of medical datasets and obtaining completely different task clusters or alteration patterns would show that the observed relationships depend on the original data choices.
Figures







read the original abstract
While much of the medical computer vision community has focused on advancing performance for specific tasks, the underlying relationships between tasks, i.e., how they relate, overlap, or differ on a representational level, remain largely unexplored. Our work explores these intrinsic relationships between medical vision tasks, specifically, we investigate 30 tasks, such as semantic tasks (e.g., segmentation and detection), image generative tasks (e.g., denoising, inpainting, or colorization), and image transformation tasks (e.g., geometric transformations). Our goal is to probe whether a data-driven representation space can capture an underlying structure of tasks across a variety of 39 datasets from wildly different medical imaging modalities, including computed tomography, magnetic resonance, electron microscopy, X-ray ultrasound and more. By revealing how tasks relate to one another, we aim to provide insights into their fundamental properties and interconnectedness. To this end, we introduce Task-Contrastive Learning (TaCo), a contrastive learning framework designed to embed tasks into a shared representation space. Through TaCo, we map these heterogeneous tasks from different modalities into a joint space and analyze their properties: identifying which tasks are distinctly represented, which blend together, and how iterative alterations to tasks are reflected in the embedding space. Our work provides a foundation for understanding the intrinsic structure of medical vision tasks, offering a deeper understanding of task similarities and their interconnected properties in embedding spaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Task-Contrastive Learning (TaCo), a contrastive learning framework that embeds 30 medical vision tasks (semantic tasks such as segmentation and detection, generative tasks such as denoising and inpainting, and transformation tasks) drawn from 39 datasets across 5+ modalities (CT, MRI, X-ray, ultrasound, electron microscopy) into a shared representation space. The authors use this space to identify which tasks remain distinct, which blend together, and how iterative alterations to tasks appear in the embeddings, with the goal of revealing intrinsic task relationships independent of modality.
Significance. If the joint embedding isolates task-intrinsic semantics rather than dataset or modality artifacts, the work could supply a useful diagnostic for task similarity, transferability, and multi-task design in medical imaging. The contrastive approach to task probing is a fresh angle, but its value hinges on demonstrating that the observed structure is not reducible to training choices or data distribution cues.
major comments (2)
- [Abstract / Methods] Abstract and Methods: the central claim that the TaCo embedding captures 'intrinsic' task relationships across heterogeneous modalities rests on the assumption that positive/negative pairs are formed in a way that forces task semantics to dominate over modality-specific cues (intensity histograms, noise spectra, resolution). No modality-invariant regularization, cross-modality task matching, or ablation that removes dataset identity is described, so the reported clusters and trajectories could be satisfied by non-task factors.
- [Experiments] Experiments: no quantitative validation, ablation, or statistical test is provided to show that the observed clusters reflect true task properties rather than training artifacts. Without such controls (e.g., comparison against a modality-only baseline or permutation test on task labels), the analysis of 'distinct' versus 'blended' tasks remains interpretive.
minor comments (2)
- [Abstract] Abstract: the exact count of tasks is given as 30, yet the listed categories are illustrative; a precise enumeration or table of all tasks would aid reproducibility.
- [Methods] Notation: the contrastive loss formulation and the definition of positive/negative pairs should be stated explicitly with equations to allow readers to assess how pair construction interacts with modality differences.
Simulated Author's Rebuttal
We are grateful to the referee for the detailed and constructive feedback on our work. The comments have helped us identify areas where the manuscript can be strengthened to better support the claims about intrinsic task relationships. We address each major comment below and have made revisions to the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: the central claim that the TaCo embedding captures 'intrinsic' task relationships across heterogeneous modalities rests on the assumption that positive/negative pairs are formed in a way that forces task semantics to dominate over modality-specific cues (intensity histograms, noise spectra, resolution). No modality-invariant regularization, cross-modality task matching, or ablation that removes dataset identity is described, so the reported clusters and trajectories could be satisfied by non-task factors.
Authors: We thank the referee for this observation. In TaCo, positive pairs consist of samples from the same task (drawn from different datasets and modalities where possible), and negative pairs from different tasks. This design aims to prioritize task semantics in the embedding space. While explicit modality-invariant regularization was not included in the original submission, the use of 39 datasets spanning 5+ modalities and the emergence of task-based clusters (e.g., segmentation tasks from CT and MRI grouping together) provide supporting evidence. To rigorously address potential confounds, we have added a new ablation study in the revised manuscript that includes a modality-only baseline and a dataset-identity ablation, demonstrating that task semantics contribute significantly beyond these factors. revision: yes
-
Referee: [Experiments] Experiments: no quantitative validation, ablation, or statistical test is provided to show that the observed clusters reflect true task properties rather than training artifacts. Without such controls (e.g., comparison against a modality-only baseline or permutation test on task labels), the analysis of 'distinct' versus 'blended' tasks remains interpretive.
Authors: We agree that quantitative measures would enhance the interpretability of our findings. The original manuscript focused on qualitative visualizations and trajectory analyses to explore the embedding space. In the revised version, we have incorporated quantitative validations, including a comparison to a modality-only embedding baseline, permutation tests on task labels to assess cluster significance, and statistical measures of task similarity in the embedding space. These additions provide stronger evidence that the observed structures are task-driven rather than artifacts. revision: yes
Circularity Check
No circularity: empirical embedding analysis is not self-referential by construction
full rationale
The paper introduces TaCo as a contrastive framework to embed medical vision tasks from 39 datasets and then performs post-hoc analysis of the resulting space (task clustering, blending, and trajectories under alterations). No equations or self-citations are presented that define task similarity via the contrastive loss itself and then claim the same similarity as an independent discovery. The central claim remains an empirical observation about the learned space rather than a closed mathematical loop. The provided abstract and context contain no load-bearing steps that reduce predictions to fitted inputs or self-definitional constructs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achille, M
A. Achille, M. Lam, R. Tewari, A. Ravichandran, S. Maji, C. C. Fowlkes, S. Soatto, and P. Perona. Task2vec: Task embedding for meta-learning. InProceedings of the IEEE/CVF international conference on computer vision, pages 6430–6439, 2019
2019
-
[2]
Ahmed, S
Z. Ahmed, S. Q. Panhwar, A. Baqai, F. A. Umrani, M. Ahmed, and A. Khan. Deep learning based automated detection of intraretinal cystoid fluid.International Journal of Imaging Systems and Technology, 32(3):902–917, 2022
2022
-
[3]
Al-Dhabyani, M
W. Al-Dhabyani, M. Gomaa, H. Khaled, and A. Fahmy. Dataset of breast ultrasound images. Data in brief, 28:104863, 2020
2020
-
[4]
P. An, S. Xu, S. A. Harmon, E. B. Turkbey, T. H. Sanford, A. Amalou, M. Kassin, N. Varble, M. Blain, V . Anderson, G. Patella, F.and Carrafiello, B. T. Turkbey, and B. J. Wood. Ct images in covid-19 [data set]., 2020
2020
- [5]
-
[6]
Antonelli, A
M. Antonelli, A. Reinke, S. Bakas, K. Farahani, A. Kopp-Schneider, B. A. Landman, G. Litjens, B. Menze, O. Ronneberger, R. M. Summers, et al. The medical segmentation decathlon.Nature communications, 13(1):4128, 2022
2022
-
[7]
Y . Bai, X. Geng, K. Mangalam, A. Bar, A. L. Yuille, T. Darrell, J. Malik, and A. A. Efros. Sequential modeling enables scalable learning for large vision models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22861–22872, 2024. 12
2024
-
[8]
Bakas, H
S. Bakas, H. Akbari, A. Sotiras, M. Bilello, M. Rozycki, J. Kirby, J. Freymann, K. Farahani, and C. Davatzikos. Segmentation labels and radiomic features for the pre-operative scans of the tcga-gbm collection (2017).DOI: https://doi. org/10.7937 K, 9, 2017
2017
-
[9]
Bakas, H
S. Bakas, H. Akbari, A. Sotiras, M. Bilello, M. Rozycki, J. Kirby, J. Freymann, K. Farahani, and C. Davatzikos. Segmentation labels and radiomic features for the pre-operative scans of the tcga-lgg collection [data set]. the cancer imaging archive, 2017
2017
-
[10]
Bakas, H
S. Bakas, H. Akbari, A. Sotiras, M. Bilello, M. Rozycki, J. S. Kirby, J. B. Freymann, K. Farahani, and C. Davatzikos. Advancing the cancer genome atlas glioma mri collections with expert segmentation labels and radiomic features.Scientific data, 4(1):1–13, 2017
2017
-
[11]
S. Bakas, M. Reyes, A. Jakab, S. Bauer, M. Rempfler, A. Crimi, R. T. Shinohara, C. Berger, S. M. Ha, M. Rozycki, et al. Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the brats challenge. arXiv preprint arXiv:1811.02629, 2018
work page Pith review arXiv 2018
-
[12]
A. Bar, Y . Gandelsman, T. Darrell, A. Globerson, and A. Efros. Visual prompting via image inpainting.Advances in Neural Information Processing Systems, 35:25005–25017, 2022
2022
-
[13]
E. A. Brempong, S. Kornblith, T. Chen, N. Parmar, M. Minderer, and M. Norouzi. Denoising pretraining for semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4175–4186, 2022
2022
-
[14]
Candemir, S
S. Candemir, S. Jaeger, K. Palaniappan, J. P. Musco, R. K. Singh, Z. Xue, A. Karargyris, S. Antani, G. Thoma, and C. J. McDonald. Lung segmentation in chest radiographs using anatomical atlases with nonrigid registration.IEEE transactions on medical imaging, 33(2): 577–590, 2013
2013
-
[15]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PMLR, 2020
2020
-
[16]
X. Chen, H. Fan, R. Girshick, and K. He. Improved baselines with momentum contrastive learning.arXiv preprint arXiv:2003.04297, 2020
work page internal anchor Pith review arXiv 2003
-
[17]
Cherti, R
M. Cherti, R. Beaumont, R. Wightman, M. Wortsman, G. Ilharco, C. Gordon, C. Schuhmann, L. Schmidt, and J. Jitsev. Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2818–2829, 2023
2023
-
[18]
Chopra, R
S. Chopra, R. Hadsell, and Y . LeCun. Learning a similarity metric discriminatively, with application to face verification. In2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05), volume 1, pages 539–546. IEEE, 2005
2005
-
[19]
M. E. Chowdhury, T. Rahman, A. Khandakar, R. Mazhar, M. A. Kadir, Z. B. Mahbub, K. R. Islam, M. S. Khan, A. Iqbal, N. Al Emadi, et al. Can ai help in screening viral and covid-19 pneumonia?Ieee Access, 8:132665–132676, 2020
2020
-
[20]
N. Codella, V . Rotemberg, P. Tschandl, M. E. Celebi, S. Dusza, D. Gutman, B. Helba, A. Kalloo, K. Liopyris, M. Marchetti, et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic).arXiv preprint arXiv:1902.03368, 2019
work page Pith review arXiv 2018
-
[21]
N. C. Codella, D. Gutman, M. E. Celebi, B. Helba, M. A. Marchetti, S. W. Dusza, A. Kalloo, K. Liopyris, N. Mishra, H. Kittler, et al. Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging collaboration (isic). In2018 IEEE 15th international sym...
2017
-
[22]
Czolbe and A
S. Czolbe and A. V . Dalca. Neuralizer: General neuroimage analysis without re-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6217–6230, 2023. 13
2023
-
[23]
Degerli, M
A. Degerli, M. Ahishali, M. Yamac, S. Kiranyaz, M. E. Chowdhury, K. Hameed, T. Hamid, R. Mazhar, and M. Gabbouj. Covid-19 infection map generation and detection from chest x-ray images.Health information science and systems, 9(1):15, 2021
2021
-
[24]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[25]
arXiv preprint arXiv:1605.09782 , year=
J. Donahue, P. Krähenbühl, and T. Darrell. Adversarial feature learning.arXiv preprint arXiv:1605.09782, 2016
-
[26]
Dorent, A
R. Dorent, A. Kujawa, M. Ivory, S. Bakas, N. Rieke, S. Joutard, B. Glocker, J. Cardoso, M. Modat, K. Batmanghelich, et al. Crossmoda 2021 challenge: Benchmark of cross-modality domain adaptation techniques for vestibular schwannoma and cochlea segmentation.Medical Image Analysis, 83:102628, 2023
2021
-
[27]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[28]
Fedorov, M
A. Fedorov, M. Schwier, D. Clunie, C. Herz, S. Pieper, R. Kikinis, C. Tempany, and F. Fennessy. An annotated test-retest collection of prostate multiparametric mri.Scientific data, 5(1):1–13, 2018
2018
-
[29]
Gatidis, T
S. Gatidis, T. Hepp, M. Früh, C. La Fougère, K. Nikolaou, C. Pfannenberg, B. Schölkopf, T. Küstner, C. Cyran, and D. Rubin. A whole-body fdg-pet/ct dataset with manually annotated tumor lesions.Scientific Data, 9(1):601, 2022
2022
-
[30]
Unsupervised representation learning by predicting image rotations
S. Gidaris, P. Singh, and N. Komodakis. Unsupervised representation learning by predicting image rotations.arXiv preprint arXiv:1803.07728, 2018
-
[31]
Z. Gu, S. Yang, J. Liao, J. Huo, and Y . Gao. Analogist: Out-of-the-box visual in-context learning with image diffusion model.ACM Transactions on Graphics (TOG), 43(4):1–15, 2024
2024
- [32]
-
[33]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770– 778, 2016
2016
-
[34]
K. He, X. Chen, S. Xie, Y . Li, P. Dollár, and R. Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[35]
Heinrich, D
L. Heinrich, D. Bennett, D. Ackerman, W. Park, J. Bogovic, N. Eckstein, A. Petruncio, J. Clements, S. Pang, C. S. Xu, et al. Whole-cell organelle segmentation in volume elec- tron microscopy.Nature, 599(7883):141–146, 2021
2021
-
[36]
M. R. Hernandez Petzsche, E. de la Rosa, U. Hanning, R. Wiest, W. Valenzuela, M. Reyes, M. Meyer, S.-L. Liew, F. Kofler, I. Ezhov, et al. Isles 2022: A multi-center magnetic resonance imaging stroke lesion segmentation dataset.Scientific data, 9(1):762, 2022
2022
-
[37]
Hojel, Y
A. Hojel, Y . Bai, T. Darrell, A. Globerson, and A. Bar. Finding visual task vectors. InEuropean Conference on Computer Vision, pages 257–273. Springer, 2025
2025
-
[38]
doi:10.5281/zenodo.5143773 , url =
G. Ilharco, M. Wortsman, R. Wightman, C. Gordon, N. Carlini, R. Taori, A. Dave, V . Shankar, H. Namkoong, J. Miller, H. Hajishirzi, A. Farhadi, and L. Schmidt. Openclip, 2021. URL https://doi.org/10.5281/zenodo.5143773
-
[39]
Jaeger, A
S. Jaeger, A. Karargyris, S. Candemir, L. Folio, J. Siegelman, F. Callaghan, Z. Xue, K. Palaniap- pan, R. K. Singh, S. Antani, et al. Automatic tuberculosis screening using chest radiographs. IEEE transactions on medical imaging, 33(2):233–245, 2013. 14
2013
-
[40]
D. Jha, P. H. Smedsrud, M. A. Riegler, P. Halvorsen, T. De Lange, D. Johansen, and H. D. Johansen. Kvasir-seg: A segmented polyp dataset. InInternational conference on multimedia modeling, pages 451–462. Springer, 2019
2019
- [41]
-
[42]
Khaled et al
R. Khaled et al. Categorized digital database for low energy and subtracted contrast enhanced spectral mammography images.The Cancer Imaging Archive, 2021
2021
-
[43]
Khosla, P
P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y . Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan. Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673, 2020
2020
-
[44]
H. J. Kuijf, J. M. Biesbroek, J. De Bresser, R. Heinen, S. Andermatt, M. Bento, M. Berseth, M. Belyaev, M. J. Cardoso, A. Casamitjana, et al. Standardized assessment of automatic segmentation of white matter hyperintensities and results of the wmh segmentation challenge. IEEE transactions on medical imaging, 38(11):2556–2568, 2019
2019
-
[45]
J. Lu, C. Clark, R. Zellers, R. Mottaghi, and A. Kembhavi. Unified-io: A unified model for vision, language, and multi-modal tasks. InThe Eleventh International Conference on Learning Representations, 2022
2022
-
[46]
J. Ma, Y . Wang, X. An, C. Ge, Z. Yu, J. Chen, Q. Zhu, G. Dong, J. He, Z. He, et al. Toward data-efficient learning: A benchmark for covid-19 ct lung and infection segmentation.Medical physics, 48(3):1197–1210, 2021
2021
-
[47]
J. Ma, Y . He, F. Li, L. Han, C. You, and B. Wang. Segment anything in medical images.Nature Communications, 15(1):654, 2024
2024
-
[48]
J. Ma, R. Xie, S. Ayyadhury, C. Ge, A. Gupta, R. Gupta, S. Gu, Y . Zhang, G. Lee, J. Kim, W. Lou, H. Li, E. Upschulte, T. Dickscheid, J. G. de Almeida, Y . Wang, L. Han, X. Yang, M. Labagnara, V . Gligorovski, M. Scheder, S. J. Rahi, C. Kempster, A. Pollitt, L. Espinosa, T. Mignot, J. M. Middeke, J.-N. Eckardt, W. Li, Z. Li, X. Cai, B. Bai, N. F. Greenwal...
-
[49]
S. Maqbool, A. Riaz, H. Sajid, and O. Hasan. m2caiseg: Semantic segmentation of laparoscopic images using convolutional neural networks.arXiv preprint arXiv:2008.10134, 2020
-
[50]
N. Mayr, W. Yuh, S. Bowen, M. Harkenrider, M. Knopp, E. Lee, E. Leung, S. Lo, W. Small Jr, and H. Wolfson. Cervical cancer—tumor heterogeneity: Serial functional and molecular imaging across the radiation therapy course in advanced cervical cancer (version 1).The Cancer Imaging Archive, 2023
2023
-
[51]
McKinney et al
W. McKinney et al. Data structures for statistical computing in python. InProceedings of the 9th Python in Science Conference, volume 445, pages 51–56. Austin, TX, 2010
2010
-
[52]
B. H. Menze, A. Jakab, S. Bauer, J. Kalpathy-Cramer, K. Farahani, J. Kirby, Y . Burren, N. Porz, J. Slotboom, R. Wiest, et al. The multimodal brain tumor image segmentation benchmark (brats).IEEE transactions on medical imaging, 34(10):1993–2024, 2014
1993
-
[53]
Noroozi and P
M. Noroozi and P. Favaro. Unsupervised learning of visual representations by solving jigsaw puzzles. InEuropean conference on computer vision, pages 69–84. Springer, 2016
2016
-
[54]
A. v. d. Oord, Y . Li, and O. Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[55]
Paszke, S
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala. Pytorch: An imperative style, high-performance deep learning library. InAdvances in Neural Information Processing Syst...
2019
-
[56]
Pathak, P
D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros. Context encoders: Feature learning by inpainting. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2536–2544, 2016
2016
-
[57]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
2011
-
[58]
Pogorelov, K
K. Pogorelov, K. R. Randel, C. Griwodz, S. L. Eskeland, T. de Lange, D. Johansen, C. Spamp- inato, D.-T. Dang-Nguyen, M. Lux, P. T. Schmidt, et al. Kvasir: A multi-class image dataset for computer aided gastrointestinal disease detection. InProceedings of the 8th ACM on Multimedia Systems Conference, pages 164–169, 2017
2017
-
[59]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InICML, 2021
2021
-
[60]
Rahman, A
T. Rahman, A. Khandakar, Y . Qiblawey, A. Tahir, S. Kiranyaz, S. B. A. Kashem, M. T. Islam, S. Al Maadeed, S. M. Zughaier, M. S. Khan, et al. Exploring the effect of image enhancement techniques on covid-19 detection using chest x-ray images.Computers in biology and medicine, 132:104319, 2021
2021
-
[61]
H. R. Roth, Z. Xu, C. Tor-Díez, R. S. Jacob, J. Zember, J. Molto, W. Li, S. Xu, B. Turkbey, E. Turkbey, et al. Rapid artificial intelligence solutions in a pandemic—the covid-19-20 lung ct lesion segmentation challenge.Medical image analysis, 82:102605, 2022
2022
-
[62]
Schuhmann, R
C. Schuhmann, R. Beaumont, R. Vencu, C. W. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman, P. Schramowski, S. R. Kundurthy, K. Crowson, L. Schmidt, R. Kaczmarczyk, and J. Jitsev. LAION-5b: An open large-scale dataset for training next generation image-text models. InThirty-sixth Conference on Neural Information Processing Sys...
2022
-
[63]
A. L. Simpson, M. Antonelli, S. Bakas, M. Bilello, K. Farahani, B. Van Ginneken, A. Kopp- Schneider, B. A. Landman, G. Litjens, B. Menze, et al. A large annotated medical im- age dataset for the development and evaluation of segmentation algorithms.arXiv preprint arXiv:1902.09063, 2019
work page Pith review arXiv 1902
-
[64]
A. M. Tahir, M. E. Chowdhury, A. Khandakar, T. Rahman, Y . Qiblawey, U. Khurshid, S. Ki- ranyaz, N. Ibtehaz, M. S. Rahman, S. Al-Maadeed, et al. Covid-19 infection localization and severity grading from chest x-ray images.Computers in biology and medicine, 139:105002, 2021
2021
- [65]
-
[66]
Tschandl, C
P. Tschandl, C. Rosendahl, and H. Kittler. The ham10000 dataset, a large collection of multi- source dermatoscopic images of common pigmented skin lesions.Scientific data, 5(1):1–9, 2018
2018
-
[67]
T. L. van den Heuvel, D. de Bruijn, C. L. de Korte, and B. v. Ginneken. Automated measurement of fetal head circumference using 2d ultrasound images.PloS one, 13(8):e0200412, 2018
2018
-
[68]
Van der Maaten and G
L. Van der Maaten and G. Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
2008
-
[69]
X. Wang, W. Wang, Y . Cao, C. Shen, and T. Huang. Images speak in images: A generalist painter for in-context visual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6830–6839, 2023
2023
- [70]
-
[71]
Wortsman, G
M. Wortsman, G. Ilharco, J. W. Kim, M. Li, S. Kornblith, R. Roelofs, R. G. Lopes, H. Hajishirzi, A. Farhadi, H. Namkoong, et al. Robust fine-tuning of zero-shot models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7959–7971, 2022
2022
-
[72]
J. Yang, G. Sharp, H. Veeraraghavan, W. Van Elmpt, A. Dekker, T. Lustberg, and M. Gooding. Data from lung ct segmentation challenge (lctsc) (version 3) [data set]., 2017
2017
-
[73]
Yeh, C.-Y
C.-H. Yeh, C.-Y . Hong, Y .-C. Hsu, T.-L. Liu, Y . Chen, and Y . LeCun. Decoupled contrastive learning. InEuropean conference on computer vision, pages 668–684. Springer, 2022
2022
-
[74]
A. R. Zamir, A. Sax, W. Shen, L. J. Guibas, J. Malik, and S. Savarese. Taskonomy: Disentangling task transfer learning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3712–3722, 2018
2018
-
[75]
Zawacki, C
A. Zawacki, C. Wu, G. Shih, J. Elliott, M. Fomitchev, M. Hussain, ParasLakhani, P. Culliton, and S. Bao. Siim-acr pneumothorax segmentation. https://kaggle.com/competitions/ siim-acr-pneumothorax-segmentation, 2019. Kaggle
2019
-
[76]
Zhang, P
R. Zhang, P. Isola, and A. A. Efros. Colorful image colorization. InComputer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceed- ings, Part III 14, pages 649–666. Springer, 2016
2016
-
[77]
X. Zou, J. Yang, H. Zhang, F. Li, L. Li, J. Wang, L. Wang, J. Gao, and Y . J. Lee. Segment everything everywhere all at once.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[78]
D. Zuki´c, A. Vlasák, J. Egger, D. Ho ˇrínek, C. Nimsky, and A. Kolb. Robust detection and segmentation for diagnosis of vertebral diseases using routine mr images. InComputer Graphics Forum, volume 33, pages 190–204. Wiley Online Library, 2014. 17 A Limitations and Future Directions In this work, we make the first step for learning task representations i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.