Recognition: 2 theorem links
· Lean TheoremBeyond the Beep: Scalable Collision Anticipation and Real-Time Explainability with BADAS-2.0
Pith reviewed 2026-05-10 18:29 UTC · model grok-4.3
The pith
BADAS-2.0 improves collision anticipation on rare events by using the prior model to select hard cases for labeling, distills the system into compact edge versions, and adds real-time object-centric explanations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
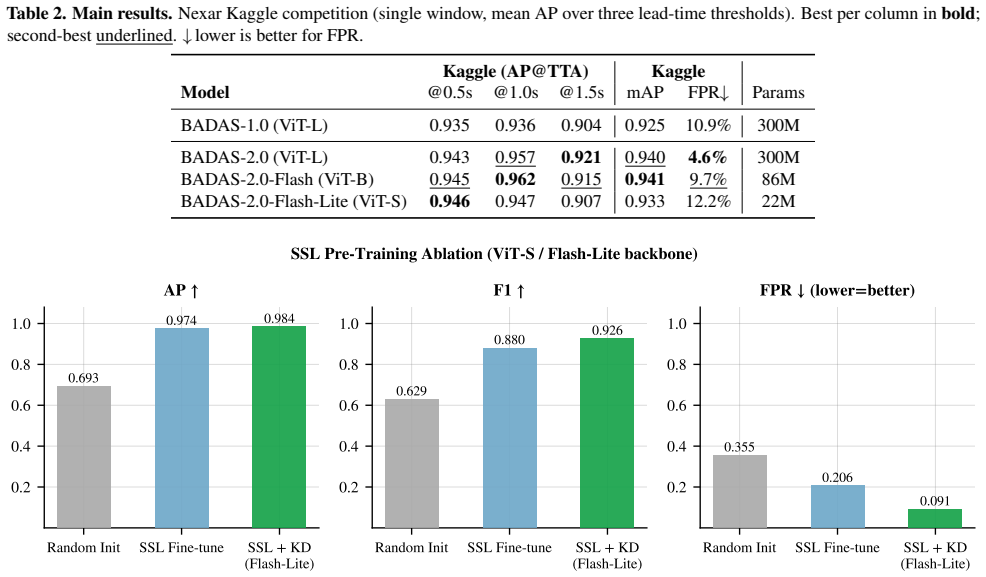
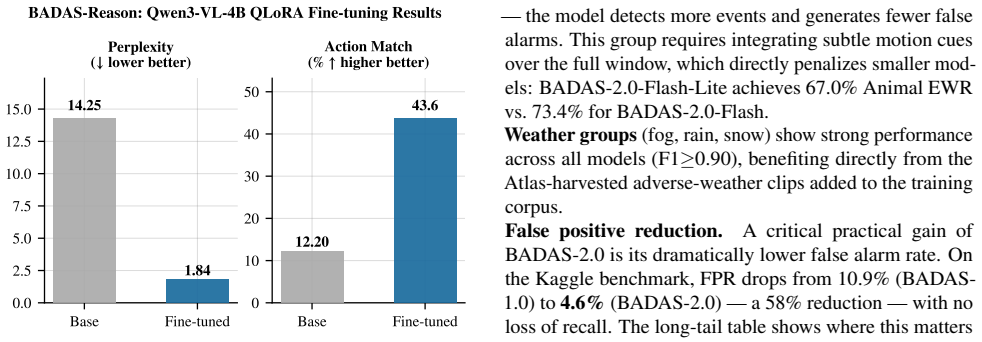
BADAS-2.0 scales collision anticipation by treating the prior version as an active oracle that surfaces high-risk unlabeled drives for targeted annotation, expands the dataset to 178,500 videos, and produces consistent accuracy lifts with the largest gains on the most difficult long-tail subgroups. Domain-specific self-supervised pre-training on 2.25 million driving videos then enables distillation into 86-million and 22-million parameter models that deliver 7-12x speedups at near-parity accuracy. The system further generates real-time object-centric attention heatmaps and feeds the last frame plus heatmap into a vision-language model to produce driver-action predictions and structured text.
What carries the argument
Active-oracle data selection from unlabeled drives combined with domain-specific distillation and object-centric attention heatmaps that feed a vision-language reasoning module.
If this is right
- Expanded long-tail data produces consistent accuracy gains across all subgroups with the biggest lifts on the hardest cases.
- Distilled compact models reach 7-12x faster inference while retaining near-parity accuracy, enabling real-time edge deployment.
- Object-centric attention heatmaps localize the visual evidence for each prediction in real time.
- The vision-language extension generates driver actions and structured textual reasoning from the final frame and heatmap.
Where Pith is reading between the lines
- The oracle-driven labeling loop suggests a general method for bootstrapping better performance on rare events when labeled data are scarce.
- Real-time heatmaps and textual reasoning could be fed directly into driver interfaces to make alerts more actionable.
- The same distillation path may allow other perception models trained on large video corpora to move to resource-limited hardware without large accuracy loss.
Load-bearing premise
The earlier model can reliably surface representative safety-critical scenarios from unlabeled drives without missing important cases or introducing selection bias.
What would settle it
Retraining and re-evaluating on a long-tail benchmark built by random sampling instead of oracle scoring shows the accuracy gains on hard cases disappear or reverse.
Figures





read the original abstract
We present BADAS-2.0, the second generation of our collision anticipation system, building on BADAS-1.0, which showed that fine-tuning V-JEPA2 on large-scale ego-centric dashcam data outperforms both academic baselines and production ADAS systems. BADAS-2.0 advances the state of the art along three axes. (i) Long-tail benchmark and accuracy: We introduce a 10-group long-tail benchmark targeting rare and safety-critical scenarios. To construct it, BADAS-1.0 is used as an active oracle to score millions of unlabeled drives and surface high-risk candidates for annotation. Combined with Nexar's Atlas platform for targeted data collection, this expands the dataset from 40k to 178,500 labeled videos (~2M clips), yielding consistent gains across all subgroups, with the largest improvements on the hardest long-tail cases. (ii) Knowledge distillation to edge: Domain-specific self-supervised pre-training on 2.25M unlabeled driving videos enables distillation into compact models, BADAS-2.0-Flash (86M) and BADAS-2.0-Flash-Lite (22M), achieving 7-12x speedup with near-parity accuracy, enabling real-time edge deployment. (iii) Explainability: BADAS-2.0 produces real-time object-centric attention heatmaps that localize the evidence behind predictions. BADAS-Reason extends this with a vision-language model that consumes the last frame and heatmap to generate driver actions and structured textual reasoning. Inference code and evaluation benchmarks are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents BADAS-2.0, an extension of BADAS-1.0 for collision anticipation from ego-centric dashcam video. It expands the labeled dataset from 40k to 178,500 videos (~2M clips) by using BADAS-1.0 as an active oracle to score millions of unlabeled drives and surface high-risk candidates for annotation, combined with targeted collection via Nexar's Atlas platform. This yields a 10-group long-tail benchmark with reported consistent accuracy gains across subgroups (largest on hardest cases). The work further distills the model via domain-specific self-supervised pre-training on 2.25M unlabeled videos into compact variants BADAS-2.0-Flash (86M params) and Flash-Lite (22M params) achieving 7-12x speedup with near-parity accuracy for edge deployment, and adds real-time explainability via object-centric attention heatmaps plus BADAS-Reason (a VLM generating structured textual reasoning on driver actions from the last frame and heatmap). Public inference code and evaluation benchmarks are released.
Significance. If the empirical claims hold under independent verification, the work provides a scalable pipeline for long-tail collision anticipation with practical edge deployment and built-in explainability, addressing key barriers to real-world ADAS adoption. The public release of code and benchmarks is a clear strength enabling reproducibility and external validation.
major comments (1)
- Dataset construction (Abstract and § on long-tail benchmark): The 178,500-video expansion and 10-group benchmark rely on BADAS-1.0 as oracle to select high-risk unlabeled drives. This introduces a potential selection bias where safety-critical cases that BADAS-1.0 assigns low risk (i.e., its own undetected failure modes) are systematically under-sampled in both training data and the new benchmark. The claim of 'consistent gains across all subgroups' and 'largest improvements on the hardest long-tail cases' therefore requires explicit validation, such as oracle coverage analysis, comparison to independently sampled long-tail data, or hold-out testing on scenarios with low BADAS-1.0 scores.
minor comments (2)
- Abstract: Performance claims ('consistent gains', 'near-parity accuracy', '7-12x speedup') are stated without any numerical values, baselines, or error bars. Adding at least the key metrics (e.g., accuracy deltas per subgroup, exact speedup/accuracy trade-offs) would make the summary self-contained.
- Notation and definitions: The exact criteria and composition of the 10 long-tail subgroups are not detailed in the provided abstract; a table or explicit list would improve clarity for readers evaluating subgroup-specific gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment on dataset construction and potential selection bias below, with planned revisions to strengthen the validation.
read point-by-point responses
-
Referee: Dataset construction (Abstract and § on long-tail benchmark): The 178,500-video expansion and 10-group benchmark rely on BADAS-1.0 as oracle to select high-risk unlabeled drives. This introduces a potential selection bias where safety-critical cases that BADAS-1.0 assigns low risk (i.e., its own undetected failure modes) are systematically under-sampled in both training data and the new benchmark. The claim of 'consistent gains across all subgroups' and 'largest improvements on the hardest long-tail cases' therefore requires explicit validation, such as oracle coverage analysis, comparison to independently sampled long-tail data, or hold-out testing on scenarios with low BADAS-1.0 scores.
Authors: We acknowledge that employing BADAS-1.0 as an active oracle for selecting high-risk candidates from unlabeled drives carries a risk of selection bias, potentially under-sampling scenarios where the oracle itself assigns low risk. This is an inherent aspect of model-guided active learning for long-tail distributions. The pipeline combines this oracle scoring with targeted collection via Nexar's Atlas platform to broaden scenario coverage beyond what the oracle alone would surface. The observed consistent accuracy gains across the 10 subgroups, including the largest improvements on the hardest cases, are measured directly on the resulting benchmark. To provide the requested explicit validation, we will revise the manuscript to include an oracle coverage analysis: this will feature performance breakdowns stratified by BADAS-1.0 risk scores on available hold-out data and a discussion of the selection process limitations. revision: yes
- A full comparison against independently sampled long-tail data (without any oracle involvement) would require new, large-scale data collection efforts outside the scope of the current work.
Circularity Check
No significant circularity; empirical claims on expanded data
full rationale
The paper reports three empirical advances: (1) expansion of labeled data from 40k to 178.5k videos by using BADAS-1.0 to surface candidates for annotation, (2) distillation of a pre-trained model into smaller variants with measured speed/accuracy trade-offs, and (3) addition of attention heatmaps plus a VLM for explainability. No equations, first-principles derivations, or fitted parameters are presented whose outputs reduce to the inputs by construction. The long-tail benchmark and performance gains are externally verifiable via the stated public code and benchmarks. Self-reference to BADAS-1.0 provides continuity but is not load-bearing for the new results, which rest on fresh annotations and measurements rather than tautological re-use of prior outputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- Distilled model sizes =
86M, 22M
- Long-tail dataset scale =
178500, 2250000
axioms (2)
- domain assumption V-JEPA2 fine-tuning on ego-centric dashcam video captures features relevant to collision anticipation
- ad hoc to paper BADAS-1.0 scoring of unlabeled drives surfaces a representative sample of safety-critical long-tail events without systematic bias
invented entities (2)
-
BADAS-2.0-Flash and BADAS-2.0-Flash-Lite
no independent evidence
-
BADAS-Reason
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BADAS-1.0 is used as an active oracle to score millions of unlabeled drives and surface high-risk candidates for annotation... expands the dataset from 40k to 178,500 labeled videos
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Knowledge distillation... SSL pre-training on 2.25M unlabeled driving videos... BADAS-2.0-Flash (86M) and BADAS-2.0-Flash-Lite (22M)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
V-JEPA 2: Self-supervised video models enable under- standing, prediction and planning.arXiv preprint, 2025
Mahmoud Assran, Adrien Bardes, David Fan, Quentin Gar- rido, Russell Howes, Mojtaba Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-JEPA 2: Self-supervised video models enable under- standing, prediction and planning.arXiv preprint, 2025. 1, 2, 3
2025
-
[2]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learn- ing visual representations from video. InarXiv preprint arXiv:2404.08471, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[3]
An- ticipating accidents in dashcam videos
Fu-Hsiang Chan, Yu-Ting Chen, Yu Xiang, and Min Sun. An- ticipating accidents in dashcam videos. InAsian Conference on Computer Vision (ACCV), 2016. 2, 6
2016
-
[4]
QLoRA: Efficient finetuning of quantized LLMs.NeurIPS, 2023
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized LLMs.NeurIPS, 2023. 2, 5
2023
-
[5]
Abductive ego-view accident video un- derstanding for safe driving perception
Jianwu Fang et al. Abductive ego-view accident video un- derstanding for safe driving perception. InCVPR, pages 22030–22040, 2024. 2
2024
-
[6]
DADA: Driver attention prediction in driving accident scenarios.IEEE Transactions on Intelligent Transportation Systems, 23(6):4959–4971, 2021
Jianwu Fang, Dingxin Yan, Jiarun Qiao, Jiahao Xue, and He Yu. DADA: Driver attention prediction in driving accident scenarios.IEEE Transactions on Intelligent Transportation Systems, 23(6):4959–4971, 2021. 2, 6
2021
-
[7]
Roni Goldshmidt, Hamish Scott, Lorenzo Niccolini, Shizhan Zhu, Daniel Moura, and Orly Zvitia. BADAS: Context aware collision prediction using real-world dashcam data.arXiv preprint arXiv:2510.14876, 2025. 1, 2, 6
-
[8]
Gemini: A Family of Highly Capable Multimodal Models
Google DeepMind. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeffrey Dean. Dis- tilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. 2 8
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
M. M. Karim, Yongfu Li, Ruimin Qin, and Zhe Yin. A dynamic spatial-temporal attention network for early antici- pation of traffic accidents.IEEE Transactions on Intelligent Transportation Systems, 23(7):9590–9600, 2022. 2
2022
-
[11]
Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks
Dong-Hyun Lee. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. InICML Workshop on Challenges in Representation Learn- ing, 2013. 2
2013
-
[12]
Vehicle-CV-ADAS
Jason Li. Vehicle-CV-ADAS. 2023. 2
2023
-
[13]
Nexar atlas: Geospatial intelligence platform
Nexar. Nexar atlas: Geospatial intelligence platform. https://nexar-ai.com, 2025. 1, 3
2025
-
[14]
Cosmos-Reason2: A multimodal model for phys- ical and commonsense reasoning.Technical Report, 2025
NVIDIA. Cosmos-Reason2: A multimodal model for phys- ical and commonsense reasoning.Technical Report, 2025. 6
2025
-
[15]
Drivelm: Driving with graph visual question answering,
Chonghao Sima et al. DriveLM: Driving with graph visual question answering.arXiv preprint arXiv:2312.14150, 2023. 2
-
[16]
Anticipating traffic accidents with adaptive loss and large-scale incident DB
Tomoyuki Suzuki, Hirokatsu Kataoka, Yoshimitsu Aoki, and Yutaka Satoh. Anticipating traffic accidents with adaptive loss and large-scale incident DB. InCVPR, pages 3521–3529,
-
[17]
Qwen3-VL: Thinking with images.arXiv preprint, 2025
Qwen Team. Qwen3-VL: Thinking with images.arXiv preprint, 2025. 1, 2, 5
2025
-
[18]
Crandall
Yao Yao, Xin Wang, Mingze Xu, Ziwei Pu, Yuchen Wang, Ella Atkins, and David J. Crandall. DoTA: Unsuper- vised detection of traffic anomaly in driving videos.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):444–459, 2022. 2, 6 9
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.